Nota
O acesso a esta página requer autorização. Pode tentar iniciar sessão ou alterar os diretórios.
O acesso a esta página requer autorização. Pode tentar alterar os diretórios.
Importante
Este recurso está em versão Beta. Os administradores do espaço de trabalho podem controlar o acesso a esse recurso na página Visualizações . Ver Gerir pré-visualizações Azure Databricks.
O Mosaic AI Vector Search oferece uma avaliação integrada da qualidade da recuperação que mede e compara a relevância de diferentes estratégias de pesquisa nos seus dados. Pode gerar automaticamente consultas de avaliação a partir dos seus documentos, executar múltiplas estratégias de recuperação e gerar um relatório detalhado.
Requisitos
Um índice gerido de pesquisa vetorial Delta Sync. Veja Criar pontos finais e índices de pesquisa vetorial.
Permissões
A tarefa de avaliação e o painel de resultados herdam as permissões do Unity Catalog do índice de pesquisa vetorial. Qualquer utilizador com acesso à consulta ao índice pode iniciar uma execução de avaliação e visualizar o painel de resultados. O utilizador que inicia a execução de avaliação é o proprietário do trabalho, não o dono do índice.
Como funciona a avaliação da eficácia da pesquisa vetorial
A avaliação executa um pipeline de quatro fases sobre os seus dados:
- Gerar consultas: O sistema amostra documentos da sua tabela de origem e utiliza um LLM para gerar consultas de pesquisa realistas. Gera uma mistura de consultas em linguagem natural e consultas por palavras-chave.
- Pesquise entre estratégias: Cada consulta gerada é executada no seu índice utilizando múltiplas estratégias de recuperação, como ANN, híbrida e texto completo. Cada estratégia é também avaliada com e sem o reranker. Esta abordagem compara estratégias lado a lado no mesmo conjunto de consultas. Para mais informações sobre cada estratégia de recuperação, veja Algoritmos de recuperação.
- Relevância da pontuação: Um juiz do LLM avalia cada par de consultas e documentos recuperados numa escala de relevância de 4 pontos.
- Calcular métricas e analisar: O sistema calcula métricas de qualidade de recuperação com intervalos de confiança. Os resultados são armazenados para que possa visualizá-los mais tarde ou compará-los entre diferentes execuções de avaliação.
Iniciar uma execução de avaliação da qualidade da recuperação de dados
Para iniciar o processo, clique em Avaliar a qualidade da pesquisa na página de índice de pesquisa vetorial. Não é necessária qualquer configuração, pois os valores padrão são pré-preenchidos com base nos metadados do seu índice.
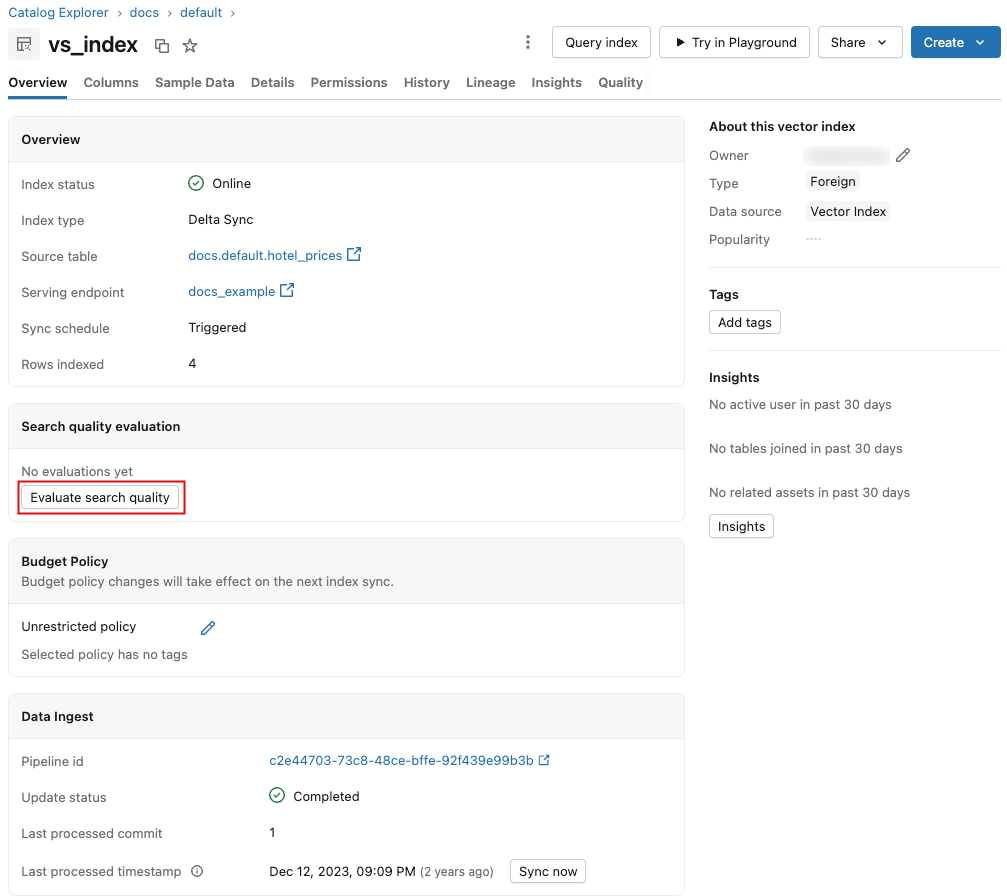
Quando a corrida terminar, clique em Ver resultados para mostrar o painel de resultados. Para uma visão geral do painel de controlo, consulte o painel de Resultados.

Para iniciar uma nova avaliação a qualquer momento, clique em Iniciar nova avaliação.
Painel de resultados
O painel apresenta os resultados das execuções de avaliação. Utilize o menu suspenso 'Selecionar Corrida' para selecionar a corrida a mostrar.

No topo do painel encontram-se 3 indicadores de resumo: a melhor pontuação de DCG@10 em todos os tipos de consultas, o tipo de consulta recomendado que a alcançou e o número de consultas avaliadas.
Veja Porque a Databricks recomenda DCG@10.
Por baixo dos indicadores de resumo, o painel mostra um gráfico de barras que compara as pontuações DCG@10 para cada tipo de consulta, com e sem utilizar o reclassificador. Ao lado do gráfico de barras há duas tabelas que mostram DCG@10 e a relevância média para cada tipo de consulta, com e sem o reclassificador.
Segue-se um gráfico de linhas que mostra como a relevância média varia entre as posições dos resultados para cada tipo de consulta.
O dashboard apresenta também as consultas com melhor e pior desempenho por pontuação média de relevância, uma tabela comparando o desempenho base e do reclassificador para cada tipo de consulta, uma tabela de consultas falhadas (consultas em que o resultado do top-1 foi pontuado 0 (irrelevante)) e um gráfico de linhas que mostra uma métrica selecionada através das execuções de avaliação ao longo do tempo, por métrica de consulta.
Pontuação de relevância
A avaliação da qualidade da recuperação utiliza um LLM-as-judge para pontuar cada par de consulta e documento recuperado numa escala de relevância graduada de 4 pontos:
| Score | Etiqueta | Descrição | Exemplo |
|---|---|---|---|
| 3 | Altamente relevante | O documento responde diretamente à pergunta ou fornece exatamente a informação procurada | Consulta: "como calculo a área de um retângulo?" O documento explica a fórmula comprimento × largura |
| 2 | Relevante | O documento está relacionado e fornece informações úteis, mas pode não responder totalmente à questão | Consulta: "onde está o número de roteamento num cheque?" O documento diz "impresso na parte inferior de um cheque" (parcialmente completo) |
| 1 | Parcialmente relevante | O documento menciona o tema, mas não fornece informações úteis para a consulta | Consulta: "como calcular a área de um retângulo?" O documento discute a área dos retângulos apenas em termos gerais |
| 0 | Não relevante | O documento não está relacionado com a consulta, ou a linguagem do documento não corresponde à linguagem da consulta | Consulta em inglês O documento responde corretamente, mas em francês |
Comparada com uma escala binária relevante/não relevante, a escala graduada capta distinções importantes. Por exemplo, um documento que responde diretamente a uma pergunta (pontuação 3) é significativamente diferente de um que apenas toca no tema (pontuação 1). Esta granularidade reflete-se nas métricas, particularmente na DCG, que valoriza mais os resultados de maior qualidade.
Todas as métricas incluem intervalos de confiança de 95% calculados a partir de valores por consulta, para que possa avaliar se as diferenças entre as estratégias são estatisticamente significativas.
Métricas de recuperação
No fundo do painel, pode ver uma métrica selecionada ao longo do tempo. Selecione a métrica a mostrar no menu de seleção Selecionar Métrica.

Esta secção descreve as métricas disponíveis.
DCG@k — Ganho Acumulado Descontado
DCG@10 capta tanto a relevância dos resultados como a sua localização no ranking, utilizando a escala completa de relevância de 0–3. A Databricks recomenda usar DCG@10 como principal métrica para avaliar a qualidade global da recuperação.
- O que mede: A utilidade total dos resultados do top 10, ponderada pela posição. Resultados de classificação mais alta contribuem mais do que os de classificação inferior.
- Como funciona: A pontuação de relevância de cada resultado é ponderada por um desconto logarítmico baseado na sua posição. O primeiro resultado contribui com toda a sua relevância, enquanto resultados de classificação inferior contribuem progressivamente menos.
- Intervalo: 0 ao máximo teórico apresentado na tabela seguinte. Quanto maior é melhor.
Valores teóricos máximos de DCG, se cada resultado receber uma pontuação de 3:
| k | Máximo Teórico DCG |
|---|---|
| 1 | 3.00 |
| 3 | 6.39 |
| 5 | 8.85 |
| 10 | 13.63 |
| 20 | 21.12 |
Para colocar estes números em perspetiva: se todos os 10 resultados tiverem relevância de 2 (numa escala de 0 a 3), DCG@10 é 13,6. Neste cenário, um ganho de 1 ponto DCG@10 é uma melhoria muito significativa (+7% relativa). Pode pensar nisso como mais ou menos um resultado na página a melhorar visivelmente, inclinado para o topo.
NDCG@k — Ganho Acumulado Normalizado e Descontado
- O que mede: Quão bem os resultados estão ordenados em relação à melhor ordem possível. A NDCG normaliza a DCG dividindo-a pela DCG ideal (a DCG se os resultados fossem ordenados por ordem decrescente de relevância).
- Intervalo: 0 a 1. Uma pontuação de 1,0 significa que os resultados estão em ordem perfeita.
- Quando usar: Quando quiser saber se o sistema está a classificar corretamente os resultados, independentemente do número total de documentos relevantes disponíveis. Veja Porque DCG@10 é a métrica principal recomendada para uma comparação detalhada.
Recall@k
- O que mede: A fração de documentos relevantes conhecidos que aparece nos resultados do top-k.
- Intervalo: 0 a 1. Uma pontuação de 1,0 significa que todos os documentos relevantes conhecidos foram recuperados.
- Quando usar: Quando a completude é importante, como em aplicações RAG onde falta um documento relevante significa que o LLM gera uma resposta incompleta.
Precision@k
- O que mede: A fração dos resultados top-k que são relevantes (pontuação >de relevância = 2).
- Intervalo: 0 a 1. Uma pontuação de 1,0 significa que todos os resultados no top k são relevantes.
- Quando usar: Quando a qualidade dos resultados importa mais do que a completude, como nas interfaces de pesquisa onde resultados irrelevantes podem afetar negativamente a confiança do utilizador.
Pontuação média de relevância
- O que mede: A pontuação média de relevância avaliada pelo LLM em todos os pares de consulta e resultado.
- Intervalo: 0 a 3. Quanto maior é melhor.
- Quando usar: Como uma visão geral rápida da qualidade.
Distribuição de relevância
-
O que mede: A percentagem de resultados em cada categoria de relevância:
- %altamente relevante : Resultados com pontuação de 3 (respostas diretas).
- Relevante+%: Resultados com pontuação de 2 ou superior (útil).
- Não relevante %: Resultados com pontuação 0 ou 1 (não útil).
- Quando usar: Para compreender a forma da distribuição de qualidade. Duas estratégias podem ter a mesma pontuação média mas distribuições muito diferentes. Por exemplo, uma distribuição bimodal (muitos 3s e muitos 0s) pode sugerir que um padrão de consulta não está a ser bem recuperado e precisa de atenção.
MRR — Classificação Média Recíproca
- O que mede: Quão rapidamente os utilizadores encontram o primeiro resultado relevante. MRR é a média de 1/classificação entre consultas, onde a classificação é a da primeira resposta relevante (pontuação >= 2).
- Intervalo: 0 a 1. Uma pontuação de 1,0 significa que o primeiro resultado é sempre relevante.
- Quando usar: Quando o resultado principal é mais importante, como nos sistemas de perguntas e respostas.
MAP@k — Precisão Média Ponderada
- O que mede: A qualidade da classificação em todos os resultados relevantes, não apenas no primeiro. O MAP calcula a precisão na posição de cada resultado relevante e depois faz a média.
- Intervalo: 0 a 1. Valores mais elevados indicam que documentos relevantes estão consistentemente classificados perto do topo.
- Quando usar: Quando precisar de um único número que capture a qualidade geral do ranking em todos os documentos relevantes.
Porque DCG@10 é a métrica primária recomendada
DCG@10 fornece a imagem mais completa da qualidade da recuperação para a maioria das aplicações:
- A relevância graduada capta a nuance: métricas binárias como a precisão tratam todos os documentos relevantes de forma igual. Um documento que responde perfeitamente à pergunta (pontuação 3) conta o mesmo que um que menciona vagamente o tema (pontuação 1). O DCG utiliza a escala completa de relevância 0–3, pelo que um resultado pontuado 3 contribui significativamente mais do que um resultado pontuado 1.
- A posição importa: Os utilizadores analisam primeiro os melhores resultados. A DCG aplica um desconto logarítmico, de modo que os resultados na posição 1 contam muito mais do que os resultados na posição 10. O primeiro resultado contribui com a sua pontuação total de relevância, enquanto a contribuição do 10.º resultado é dividida por log₂(11) ≈ 3,46.
- A utilidade absoluta revela o que as métricas normalizadas falham: Considere o exemplo mostrado na tabela seguinte. Ambos os conjuntos de resultados alcançam uma NDCG perfeita de 1,00 porque cada um tem resultados por ordem decrescente ideal. No entanto, o Conjunto de Resultados B entrega quase o dobro do valor total (DCG 8,02 vs 4,26) porque cada resultado é útil. A NDCG não consegue distinguir entre "classificação perfeita de 2 bons resultados entre 3 irrelevantes" e "classificação perfeita de 5 bons resultados." O DCG responde à pergunta: "Quanta informação útil o utilizador obteve realmente?"
Para mais informações sobre DCG e NDCG, veja Ganho cumulativo descontado.
| Results | Posição 1 | Posição 2 | Posição 3 | Posição 4 | Posição 5 | NDCG@5 | DCG@5 |
|---|---|---|---|---|---|---|---|
| Conjunto de resultados A | 3 | 2 | 0 | 0 | 0 | 1,00 | 4.26 |
| Conjunto de resultados B | 3 | 3 | 3 | 2 | 2 | 1,00 | 8.02 |
Nenhuma métrica única conta toda a história. Use o conjunto completo de métricas para uma visão completa e selecione a métrica que melhor corresponde aos requisitos de qualidade da sua aplicação.
Cenários comuns
A tabela seguinte explica padrões comuns de resultados de avaliação, o que significam e como os abordar:
| Padrão | O que significa | Ação sugerida |
|---|---|---|
| Híbrido significativamente melhor do que o ANN | As consultas beneficiam da correspondência de palavras-chave. | Use pesquisa híbrida em produção. |
| Rede Neural Artificial aproximadamente igual a híbrido | As palavras-chave não acrescentam valor aos seus dados. | Qualquer uma das estratégias funciona. ANN é mais simples. |
| Texto completo significativamente melhor do que ANN | Os embeddings podem não captar bem o seu domínio. | Considere afinar o seu modelo de embedding ou usar pesquisa em texto completo. |
| O Reranker melhora significativamente as métricas | O Cross-Encoder oferece uma melhoria significativa na qualidade. | Ativa o reranker caso o orçamento de latência permita. |
| Intervalos de confiança largos | Não há consultas suficientes para uma comparação fiável. | Aumente o número de consultas de avaliação. |
| Todas as estratégias têm uma pontuação baixa | Questões de qualidade ou relevância dos dados. | Consulte o guia de qualidade da recuperação por busca vetorial para um guia passo a passo para melhorar a qualidade da recuperação. |