Nota
O acesso a esta página requer autorização. Pode tentar iniciar sessão ou alterar os diretórios.
O acesso a esta página requer autorização. Pode tentar alterar os diretórios.
Esta página cobre as opções para recursos de computação para notebooks. Você pode executar um bloco de anotações em um recurso de computação multiuso, computação sem servidor ou, para comandos SQL, pode usar um SQL warehouse, um tipo de computação otimizada para análise SQL. Para mais informações sobre tipos de computação, consulte Computar.
Computação padrão
Nos espaços de trabalho ativados para o Unity Catalog, os novos notebooks usam, por padrão, computação sem servidor. Se não selecionares manualmente um recurso de computação e executares uma célula, o bloco de notas liga-se automaticamente à computação sem servidor.
Cálculo por auto-anexação
Nas definições de programador, pode configurar os notebooks para se ligarem automaticamente a um recurso de computação e iniciar uma sessão quando interagir com o editor:
Clique no ícone do seu utilizador no canto superior esquerdo.
Clique em Configurações.
Clica em Desenvolvedor para aceder às definições do teu programador.
Ative Criar automaticamente sessão na interação do editor para iniciar automaticamente uma sessão de computação durante a interação com o editor. O Databricks utiliza por defeito um recurso de computação baseado nas suas preferências (serverless ou SQL warehouse) e no último recurso de computação utilizado.
OR
Desligue esta definição se não quiser que o portátil se ligue automaticamente e inicie um recurso de computação.
Funcionalidades de assistência de código, incluindo autocompletamento, formatação de código e o depurador, exigem que o caderno esteja ligado a uma sessão de computação ativa. Se o caderno não iniciou uma sessão de computação, então as funcionalidades de assistência ao código ficam inativas.
Computação sem servidor para notebooks
A computação sem servidor permite que você conecte rapidamente seu notebook a recursos de computação sob demanda.
Para anexar à computação sem servidor, clique no menu suspenso de computação no notebook e selecione Serverless.
Consulte Computação sem servidor para notebooks para obter mais informações.
Restauração de sessão automatizada para notebooks sem servidor
A interrupção por inatividade da computação serverless pode levar à perda de trabalho em andamento, como valores de variáveis em Python, nos seus notebooks. Para evitar isto, ativa a restauração automática de sessões para notebooks serverless.
- Clique no seu nome de utilizador no canto superior direito do seu espaço de trabalho e depois clique em Definições na lista suspensa.
- Na barra lateral Configurações, selecione Desenvolvedor.
- Em Recursos experimentais, ative a configuração Restauração de sessão automatizada para cadernos sem servidor.
Ativar esta configuração permite que os Databricks façam snapshots do estado da memória do notebook serverless antes da terminação por inatividade. Quando tu retornas a um caderno após uma desconexão por inatividade, um banner aparece na parte superior da página. Clique em Reconectar para restaurar seu estado de trabalho.
Quando você se reconecta, o Databricks restabelece todo o seu ambiente de trabalho, incluindo:
- Variáveis, funções e definições de classe do Python: O estado do Python é serializado internamente usando pickle/cloudpickle e restaurado em um novo REPL, assim, não é necessário reimportar ou redeclarar.
- DataFrames Spark, vistas em cache e temporárias: Os dados que carregaste, transformaste ou guardaste em cache (incluindo vistas temporárias) são preservados, evitando assim recargas ou recomputações dispendiosas.
- Estado da sessão Spark: As definições de configuração ao nível do Spark, vistas temporárias, modificações de catálogo e funções definidas pelo utilizador (UDFs) são restauradas através da migração da sessão do Spark Connect, por isso não precisa de as reiniciar.
Se o ambiente mudou de forma a tornar a desserialização insegura, por exemplo, versões incompatíveis do Python ou de pacotes, o snapshot é invalidado e o notebook retorna a uma nova sessão.
Armazenamento de dados instantâneos
Os dados snapshot são armazenados no armazenamento padrão do seu espaço de trabalho. O próprio caderno armazena apenas metadados, incluindo um ponteiro com o ID do caderno, um carimbo temporal e informações da sessão. A carga útil de dados não é armazenada no portátil. Os caminhos de blobs são criptografados antes de serem armazenados em atributos do caderno, e os caminhos de snapshots são excluídos da exportação e importação do caderno para evitar restaurar o estado em um espaço de trabalho diferente.
Os snapshots seguem as predefinições TTL do teu armazenamento na cloud (cerca de um mês) e expiram automaticamente. Apagar um notebook também elimina as suas snapshots. A sua conta na cloud incorre em custos de armazenamento como parte do uso padrão do espaço de trabalho. A funcionalidade utiliza serialização de processos em Python em vez de checkpointing ao nível do contentor, que mantém snapshots mais pequenos e rápidos de criar.
Segurança e controlo de acesso
A restauração de instantâneos respeita as permissões do notebook. Restaurar o estado requer a permissão RUN no notebook. Metadados encriptados impedem os utilizadores de obter diretamente blobs de snapshot, e verificações de permissões são aplicadas na restauração.
Limitações
Esta funcionalidade tem limitações e não suporta restaurar o seguinte:
- Estados do Spark com mais de 4 dias
- Estados do Spark maiores que 50 MB
- Dados relacionados a scripts SQL
- Identificadores de arquivo
- Bloqueios e outras primitivas de simultaneidade
- Ligações de rede
Anexar um bloco de notas a um recurso de computação polivalente
Para anexar um caderno a um recurso de computação para todos os fins, necessita-se da permissão PODE ANEXAR A no recurso de computação.
Importante
Enquanto um caderno estiver conectado a um recurso de computação, qualquer usuário com a permissão CAN RUN no caderno tem permissão implícita para acessar o recurso de computação.
Para anexar um notebook a um recurso de computação, clique no seletor de computação na barra de ferramentas do notebook e selecione o recurso no menu suspenso.
O menu mostra uma seleção de armazéns SQL e de computação para todos os fins que você usou recentemente ou está executando no momento.
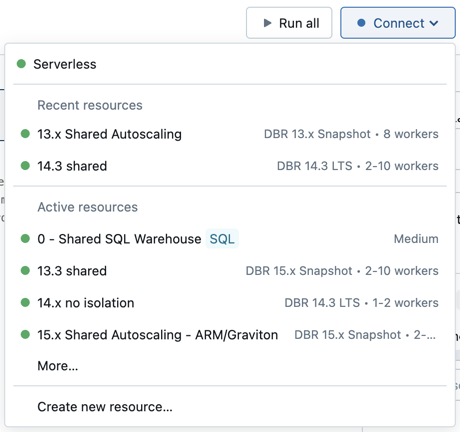
Para selecionar entre todos os cálculos disponíveis, clique em Mais.... Selecione entre os armazéns de computação geral ou SQL disponíveis.

Também pode criar um novo recurso computacional multiusos selecionando Criar novo recurso... no menu suspenso.
Importante
Um bloco de anotações anexado tem as seguintes variáveis do Apache Spark definidas.
| Classe | Nome da variável |
|---|---|
SparkContext |
sc |
SQLContext/HiveContext |
sqlContext |
SparkSession (Spark 2.x) |
spark |
Não crie um SparkSession, SparkContext, ou SQLContext. Fazer isso leva a comportamentos inconsistentes.
Usar um notebook com um SQL warehouse
Quando um notebook está ligado a um armazém SQL, pode executar células SQL e Markdown. Executar uma célula em qualquer outra linguagem (como Python ou R) gera um erro. As células SQL executadas em um SQL warehouse aparecem no histórico de consultas do SQL warehouse. O utilizador que correu uma consulta pode visualizar o perfil da consulta a partir do bloco de notas clicando no tempo decorrido na parte inferior do resultado.
Os cadernos ligados aos armazéns SQL suportam sessões de armazém SQL, onde pode definir variáveis, criar vistas temporárias e manter o estado ao longo de várias execuções de consultas. Podes construir lógica SQL iterativamente sem precisar de executar todas as instruções de uma vez. Consulte O que são sessões do SQL warehouse?.
A execução de um notebook requer um SQL warehouse profissional ou sem servidor. Você deve ter acesso ao espaço de trabalho e ao SQL warehouse.
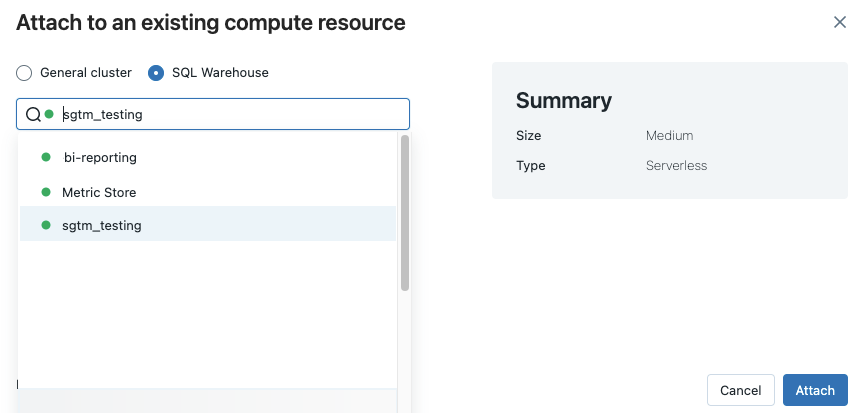
Para anexar um bloco de anotações a um armazém SQL, faça o seguinte:
Clique no seletor de computação na barra de ferramentas do notebook. O menu suspenso mostra os recursos de computação que estão atualmente a correr ou que usaste recentemente. Os armazéns SQL são marcados com
 .
.No menu, selecione um SQL warehouse.
Para ver todos os armazéns SQL disponíveis, selecione Mais... no menu suspenso. É exibida uma caixa de diálogo mostrando os recursos de computação disponíveis para o bloco de anotações. Seleciona SQL Warehouse, seleciona o armazém que queres usar e clica em Anexar.
Você também pode selecionar um SQL warehouse como o recurso de computação para um bloco de anotações SQL ao criar um fluxo de trabalho ou um trabalho agendado.
Limitações do SQL warehouse
Consulte Limitações conhecidas dos cadernos Databricks para mais informações.