Nota
O acesso a esta página requer autorização. Pode tentar iniciar sessão ou alterar os diretórios.
O acesso a esta página requer autorização. Pode tentar alterar os diretórios.
Azure
Manter a consistência dos dados em sistemas distribuídos coordenando uma sequência de transações locais entre múltiplos serviços. Cada serviço executa a sua operação e desencadeia o passo seguinte através de eventos ou mensagens. Se um passo falhar, uma série de transações compensatórias desfaz as alterações feitas pelos passos concluídos.
Contexto e problema
Uma transação representa uma unidade de trabalho, que pode incluir várias operações. Dentro de uma transação, um evento refere-se a uma alteração de estado que afeta uma entidade. Um comando encapsula todas as informações necessárias para executar uma ação ou acionar um evento subsequente.
As transações devem aderir aos princípios de atomicidade, consistência, isolamento e durabilidade (ACID).
- Atomicidade: Todas as operações são bem-sucedidas ou nenhuma operação é bem-sucedida.
- Consistência: Transições de dados de um estado válido para outro estado válido.
- Isolamento: As transações simultâneas produzem os mesmos resultados que as transações sequenciais.
- Durabilidade: As alterações persistem depois de serem cometidas, mesmo quando ocorrem falhas.
Em um único serviço, as transações seguem os princípios ACID porque operam dentro de um único banco de dados. No entanto, pode ser mais complexo alcançar a conformidade ACID em vários serviços.
Desafios em arquiteturas de microsserviços
As arquiteturas de microsserviços normalmente atribuem um banco de dados dedicado a cadade microsserviços. Esta abordagem oferece vários benefícios:
- Cada serviço encapsula seus próprios dados.
- Cada serviço pode usar a tecnologia de banco de dados mais adequada e esquema para suas necessidades específicas.
- Os bancos de dados de cada serviço podem ser dimensionados de forma independente.
- As falhas em um serviço são isoladas de outros serviços.
Apesar dessas vantagens, essa arquitetura complica a consistência de dados entre serviços. Garantias de banco de dados tradicionais, como o ACID, não são diretamente aplicáveis a vários armazenamentos de dados gerenciados independentemente. Devido a essas limitações, arquiteturas que dependem de comunicação entre processos, ou modelos de transação tradicionais, como protocolo de confirmação de duas fases, geralmente são mais adequadas para o padrão Saga.
Solução
O padrão Saga gerencia transações dividindo-as em uma sequência de transações locais.

Cada transação local:
- Conclui o seu trabalho de forma atómica num único serviço.
- Atualiza o banco de dados do serviço.
- Inicia a próxima transação através de um evento ou mensagem.
Se uma transação local falhar, a saga executa uma série de transações de compensação para reverter as alterações que as transações locais anteriores fizeram.
Conceitos-chave no padrão Saga
As operações compensáveis podem ser desfeitas ou compensadas por outras operações com o efeito contrário. Se uma etapa da saga falhar, as transações compensatórias desfazem as alterações que as transações compensáveis fizeram.
Transações Pivot servem de ponto de não retorno na saga. Depois que uma transação pivot é bem-sucedida, as transações compensáveis não são mais relevantes. Todas as ações subsequentes devem ser concluídas para que o sistema atinja um estado final consistente. Uma transação pivot pode assumir diferentes papéis, dependendo do fluxo da saga:
Transações irreversíveis ou não compensáveis não podem ser desfeitas ou repetidas.
O limite entre reversível e confirmado significa que a transação pivô pode ser a última transação anulável, ou compensável. Ou pode ser a primeira operação que pode ser repetida na saga.
Transações repetíveis seguem a transação pivô. As transações passíveis de repetição são idempotentes e ajudam a garantir que a saga possa atingir o seu estado final, mesmo que ocorram falhas temporárias. Eles ajudam a saga a alcançar um estado consistente.
Abordagens de implementação da Saga
As duas abordagens típicas de implementação da saga são coreografia e orquestração . Cada abordagem tem seu próprio conjunto de desafios e tecnologias para coordenar o fluxo de trabalho.
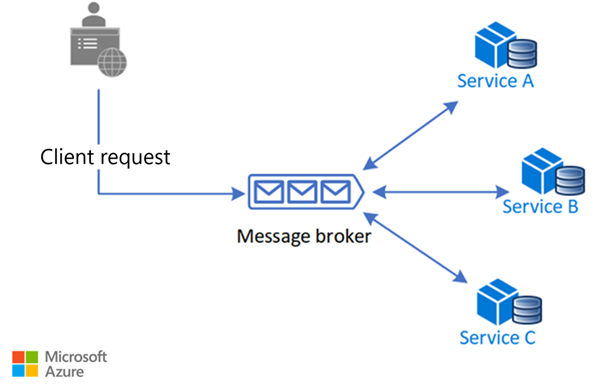
Coreografia
Na abordagem coreográfica, os serviços trocam eventos sem um controlador centralizado. Com a coreografia, cada transação local publica eventos de domínio que acionam transações locais em outros serviços.
| Benefícios da coreografia | Desvantagens da coreografia |
|---|---|
| Bom para fluxos de trabalho simples que têm poucos serviços e não precisam de uma lógica de coordenação. | O fluxo de trabalho pode ser confuso quando você adiciona novas etapas. É difícil rastrear a quais comandos cada participante da saga responde. |
| Nenhum outro serviço é necessário para a coordenação. | Há um risco de dependência cíclica entre os participantes da saga porque eles têm que consumir os comandos uns dos outros. |
| Não introduz um único ponto de falha porque as responsabilidades estão distribuídas pelos participantes da saga. | O teste de integração é difícil porque todos os serviços devem ser executados para simular uma transação. |
Orquestração
Na orquestração, um controlador centralizado, ou orquestrador, lida com todas as transações e diz aos participantes qual operação executar com base nos eventos. O orquestrador executa pedidos da saga, armazena e interpreta os estados de cada tarefa e gere a recuperação de falhas, recorrendo a transações de compensação.

| Benefícios da orquestração | Desvantagens da orquestração |
|---|---|
| Mais adequado para fluxos de trabalho complexos ou quando adiciona novos serviços. | Outra complexidade de projeto requer a implementação de uma lógica de coordenação. |
| Evita dependências cíclicas porque o orquestrador gerencia o fluxo. | Introduz um ponto de falha porque o orquestrador gerencia o fluxo de trabalho completo. |
| Uma separação clara das responsabilidades simplifica a lógica do serviço. |
Problemas e considerações
Considere os seguintes pontos ao decidir como implementar esse padrão:
Mudança no design thinking: Adotar o padrão Saga requer uma mentalidade diferente. Isso exige que você se concentre na coordenação de transações e na consistência de dados em vários microsserviços.
Complexidade da depuração de sagas: A depuração de sagas pode ser complexa, sobretudo à medida que o número de serviços participantes aumenta.
Alterações irreversíveis no banco de dados local: Os dados não podem ser revertidos porque os participantes da saga confirmam alterações em seus respetivos bancos de dados.
Tratamento de falhas transitórias e idempotência: O sistema deve lidar com falhas transitórias de forma eficaz e garantir a idempotência, quando repetir a mesma operação não altera o resultado. Para obter mais informações, consulte Idempotent message processing.
Necessidade de monitorização e seguimento de sagas: Monitorizar e acompanhar o fluxo de trabalho de uma saga são tarefas essenciais para assegurar a supervisão operacional.
Limitações das operações de compensação: As operações de compensação podem nem sempre ter êxito, o que pode deixar o sistema num estado inconsistente.
Potenciais anomalias de dados em sagas
As anomalias de dados são inconsistências que podem ocorrer quando as sagas operam em vários serviços. Como cada serviço gerencia seus próprios dados, chamados dados de participantes, não há isolamento interno entre os serviços. Essa configuração pode resultar em inconsistências de dados ou problemas de durabilidade, como atualizações parcialmente aplicadas ou conflitos entre serviços. Os problemas típicos incluem:
Atualizações perdidas: Quando uma saga modifica dados sem considerar as alterações feitas por outra saga, isso resulta em atualizações substituídas ou ausentes.
Dirty diz: Quando uma saga ou transação lê dados que outra saga modificou, mas a modificação não está completa.
Leituras difusas, ou não repetíveis: Quando diferentes etapas de uma saga leem dados inconsistentes porque são efetuadas atualizações entre as leituras.
Estratégias para resolver anomalias de dados
Para reduzir ou prevenir estas anomalias, considere as seguintes contramedidas:
Bloqueio semântico: Use bloqueios no nível do aplicativo quando a transação compensável de uma saga usa um semáforo para indicar que uma atualização está em andamento.
Atualizações comutativas: Atualizações de design para que possam ser aplicadas em qualquer ordem e, ao mesmo tempo, produzir o mesmo resultado. Esta abordagem ajuda a reduzir os conflitos entre as sagas.
Visão pessimista: Reordene a sequência da saga para que as atualizações de dados ocorram em transações repetidas para eliminar leituras sujas. Caso contrário, uma saga poderia ler dados sujos, ou alterações não confirmadas, enquanto outra saga simultaneamente executa uma transação compensável para reverter suas atualizações.
Reler valores: Confirme se os dados permanecem inalterados antes de fazer atualizações. Se os dados forem alterados, pare a etapa atual e reinicie a saga conforme necessário.
Arquivos de versão: Mantenha um registro de todas as operações executadas em um registro e certifique-se de que elas sejam executadas na sequência correta para evitar conflitos.
Simultaneidade baseada em risco com base no valor: Escolha dinamicamente o mecanismo de simultaneidade apropriado com base no risco potencial do negócio. Por exemplo, use sagas para atualizações de baixo risco e transações distribuídas para atualizações de alto risco.
Quando usar este padrão
Use este padrão quando:
- Você precisa garantir a consistência dos dados em um sistema distribuído sem acoplamento rígido.
- Você precisa reverter ou compensar se uma das operações na sequência falhar.
Este padrão pode não ser adequado quando:
- As transações estão intimamente ligadas.
- As operações de compensação ocorrem em participantes anteriores.
- Há dependências cíclicas.
Próximo passo
Recursos relacionados
Os seguintes padrões podem ser relevantes quando você implementa esse padrão:
O padrão coreográfico faz com que cada componente do sistema participe do processo de tomada de decisão sobre o fluxo de trabalho de uma transação comercial, em vez de depender de um ponto central de controle.
O padrão Transação de Compensação desfaz o trabalho realizado por uma série de etapas e, eventualmente, define uma operação consistente se uma ou mais etapas falharem. As aplicações alojadas na nuvem que implementam processos empresariais e fluxos de trabalho complexos seguem frequentemente este modelo de consistência eventual.
O padrão Retry permite que uma aplicação trate falhas transitórias quando tenta ligar-se a um serviço ou recurso de rede, ao repetir automaticamente, de forma transparente, a operação que falhou. Este padrão pode melhorar a estabilidade da aplicação.
O padrão de disjuntor lida com falhas cuja recuperação pode demorar um tempo variável, ao ligar-se a um serviço ou recurso remoto. Esse padrão pode melhorar a estabilidade e a resiliência de um aplicativo.
O padrão Health Endpoint Monitoring implementa verificações funcionais numa aplicação, às quais as ferramentas externas podem aceder por meio de pontos finais expostos em intervalos regulares. Esse padrão pode ajudá-lo a verificar se os aplicativos e serviços estão funcionando corretamente.