Nota
O acesso a esta página requer autorização. Pode tentar iniciar sessão ou alterar os diretórios.
O acesso a esta página requer autorização. Pode tentar alterar os diretórios.
APLICA-SE A: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Gorjeta
Data Factory em Microsoft Fabric é a próxima geração de Azure Data Factory, com uma arquitetura mais simples, IA incorporada e novas funcionalidades. Se és novo na integração de dados, começa pelo Fabric Data Factory. As cargas de trabalho existentes do ADF podem atualizar para o Fabric para aceder a novas capacidades em ciência de dados, análise em tempo real e relatórios.
Neste tutorial, cria uma fábrica de dados utilizando a interface de utilizador (UI) do Azure Data Factory. O pipeline no Azure Data Factory copia dados de forma segura do armazenamento do Azure Blob para uma Base de Dados SQL do Azure (ambos permitindo acesso apenas a redes selecionadas) utilizando endpoints privados na Azure Data Factory Managed Rede Virtual. O padrão de configuração neste tutorial aplica-se à cópia a partir de um arquivo de dados baseado em ficheiros para um arquivo de dados relacional. Para obter uma lista de armazenamentos de dados suportados como fontes e coletores, consulte a tabela Armazenamentos de dados e formatos suportados. A funcionalidade de endpoints privados está disponível em todos os níveis do Azure Data Factory, pelo que não é necessário um nível específico para os utilizar. Para mais detalhes sobre preços e níveis, consulte a página de preços Azure Data Factory.
Nota
Se és novo no Data Factory, vê Introdução ao Azure Data Factory.
Neste tutorial, vai executar os seguintes passos:
- Criar uma fábrica de dados.
- Criar um pipeline com uma atividade de cópia.
Pré-requisitos
- Subscrição do Azure. Se não tiver uma subscrição Azure, crie uma conta Azure gratuita antes de começar.
- Conta de armazenamento do Azure Utilize o armazenamento de blobs como armazenamento de dados de origem. Se não tiver uma conta de armazenamento, veja Criar uma conta de armazenamento Azure para os passos necessários para criar uma. Certifique-se de que a conta de armazenamento permite o acesso apenas a partir de redes selecionadas.
- Base de Dados SQL do Azure. Pode utilizar a base de dados como um arquivo de dados sink. Se não tiver uma base de dados SQL do Azure, consulte Criar uma base de dados SQL para os passos para criar uma. Verifique se a conta do Banco de dados SQL permite acesso somente de redes selecionadas.
Criar um blob e uma tabela SQL
Agora, prepare seu armazenamento de blob e banco de dados SQL para o tutorial executando as etapas a seguir.
Criar um blob de origem
Abra o Bloco de Notas. Copie o texto seguinte e guarde-o como um ficheiro emp.txt no disco:
FirstName,LastName John,Doe Jane,DoeCrie um contêiner chamado adftutorial em seu armazenamento de blob. Crie uma pasta com o nome input neste contentor. Em seguida, carregue o ficheiro emp.txt para a pasta input. Use o portal Azure ou ferramentas como Explorador de Armazenamento do Azure para realizar estas tarefas.
Criar uma tabela SQL de destino
Utilize o seguinte script SQL para criar a tabela dbo.emp na sua base de dados SQL:
CREATE TABLE dbo.emp
(
ID int IDENTITY(1,1) NOT NULL,
FirstName varchar(50),
LastName varchar(50)
)
GO
CREATE CLUSTERED INDEX IX_emp_ID ON dbo.emp (ID);
Criar uma fábrica de dados
Neste passo, vai criar um Data Factory e iniciar a Interface do Utilizador (IU) do Data Factory para criar um pipeline no Data Factory.
Abre o Microsoft Edge ou o Google Chrome. Atualmente, apenas os navegadores Microsoft Edge e Google Chrome suportam a interface Data Factory.
No menu à esquerda, selecione Criar um recurso>Analytics>Data Factory.
Na página Nova fábrica de dados, em Nome, introduza ADFTutorialDataFactory.
O nome da fábrica de dados Azure deve ser globalmente único. Se você receber uma mensagem de erro sobre o valor do nome, insira um nome diferente para o data factory (por exemplo, seunomeADFTutorialDataFactory). Para obter as regras de nomenclatura dos artefactos do Data Factory, veja Regras de nomenclatura do Data Factory.
Selecione a subscrição do Azure onde quer criar o Data Factory.
Em Grupo de Recursos, efetue um destes passos:
- Selecione Utilizar existente e selecione um grupo de recursos já existente na lista pendente.
- Selecione Criar novo e introduza o nome de um grupo de recursos.
Para saber mais sobre grupos de recursos, veja Use grupos de recursos para gerir os seus Azure recursos.
Em Versão, selecione V2.
Em Localização, selecione uma localização para a fábrica de dados. Apenas as localizações suportadas aparecem na lista suspensa. Os repositórios de dados (por exemplo, Armazenamento do Azure e SQL Database) e os cálculos (por exemplo, Azure HDInsight) usados pela data factory podem estar noutras regiões.
Selecione Criar.
Após a conclusão da criação, você verá o aviso na Central de notificações. Selecione Ir para o recurso para aceder à página do Data Factory.
Selecione Abrir no bloco Open Azure Data Factory Studio para iniciar a IU do Data Factory num separador.
Criar um runtime de integração com o Azure no Data Factory Managed Rede Virtual
Neste passo, cria um runtime de integração com o Azure e ativa o Data Factory Managed Rede Virtual.
No portal Data Factory, vá a Gerir e selecione Novo para criar um novo tempo de execução de integração Azure.

Na página Configuração do tempo de execução de integração, escolha qual tempo de execução de integração criar com base nas capacidades necessárias. Neste tutorial, selecione Azure, Auto-Hospedado e depois clique em Continue.
Selecione Azure e depois clique em Continue para criar um runtime de integração Azure.

Em Configuração de rede virtual (Pré-visualização), selecione Ativar.
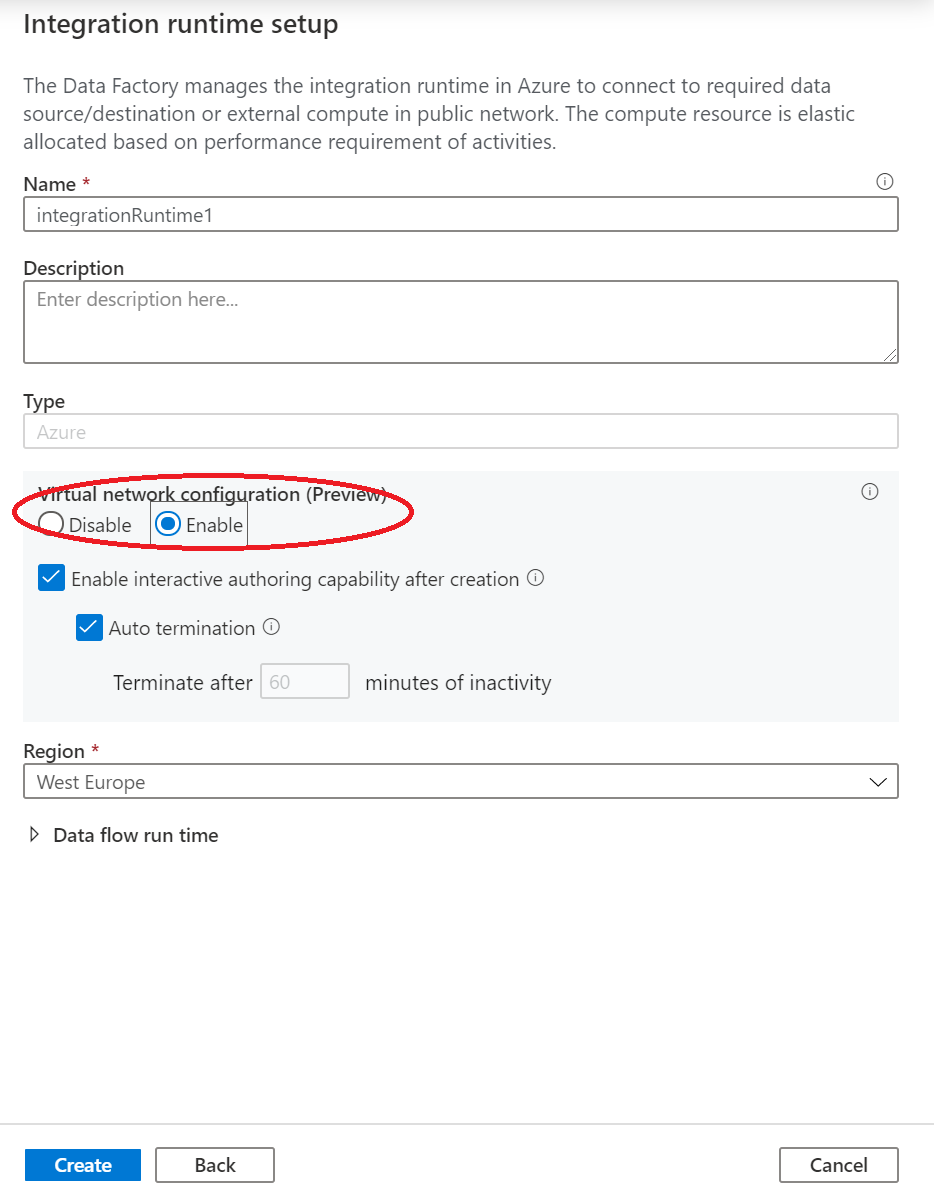
Selecione Criar.
Criar um pipeline
Neste passo, vai criar um pipeline com uma atividade de cópia na fábrica de dados. A atividade de cópia copia os dados do Armazenamento Blob para a Base de Dados SQL. No Tutorial de início rápido, seguiu os passos abaixo para criar um pipeline:
- Criar o serviço associado.
- Criar os conjuntos de dados de entrada e saída.
- Criar um pipeline.
Neste tutorial, você começa criando um pipeline. Em seguida, vai criar serviços ligados e conjuntos de dados quando forem necessários para configurar o pipeline.
Na página inicial, selecione Orquestrar.
No painel de propriedades do pipeline, digite CopyPipeline para o nome do pipeline.
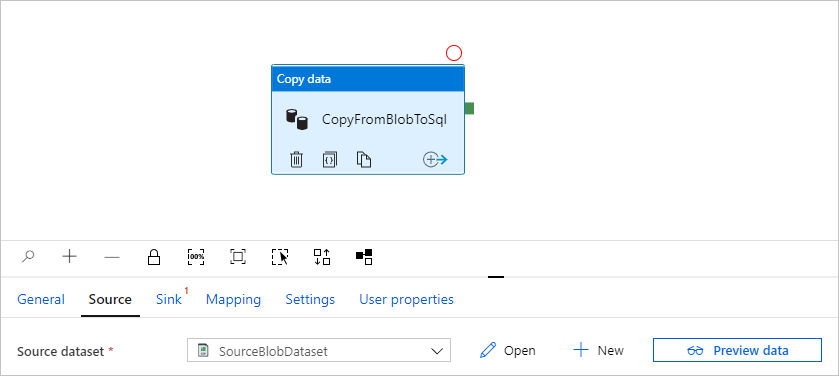
Na caixa de ferramentas Atividades, expanda a categoria Mover e Transformar e arraste a atividade Copiar dados da caixa de ferramentas para a superfície do projetista de pipelines. Digite CopyFromBlobToSql para o nome.

Configurar uma origem
Gorjeta
Neste tutorial, você usa a chave de conta como o tipo de autenticação para seu armazenamento de dados de origem. Você também pode escolher outros métodos de autenticação suportados, como SAS URI,Principal de Serviço e Identidade Gerenciada se necessário. Para mais informações, consulte as secções correspondentes em Copiar e transformar dados no armazenamento Azure Blob usando Azure Data Factory.
Para armazenar segredos para armazenamentos de dados de forma segura, recomendamos também que utilize o Azure Key Vault. Para mais informações e ilustrações, consulte Armazenar credenciais em Azure Key Vault.
Criar um conjunto de dados de origem e um serviço vinculado
Vá para o separador Origem. Selecione + Novo para criar um conjunto de dados de origem.
Na caixa de diálogo Novo Conjunto de Dados, selecione Armazenamento de Blobs do Azure e depois selecione Continue. Os dados de origem estão em armazenamento Blob, por isso seleciona Armazenamento de Blobs do Azure para o conjunto de dados de origem.
Na caixa de diálogo Selecionar Formato, selecione o tipo de formato dos seus dados e, em seguida, selecione Continuar.
Na caixa de diálogo Definir Propriedades, digite SourceBlobDataset para Name. Marque a caixa de seleção Primeira linha como cabeçalho. Na caixa de texto Serviço vinculado, selecione + Novo.
Na caixa de diálogo Novo serviço ligado (Armazenamento de Blobs do Azure), introduza AzureStorageLinkedService como Nome e selecione a sua conta de armazenamento na lista Nome da conta de armazenamento.
Certifique-se de ativar autoria interativa. Pode levar cerca de um minuto para ser ativado.
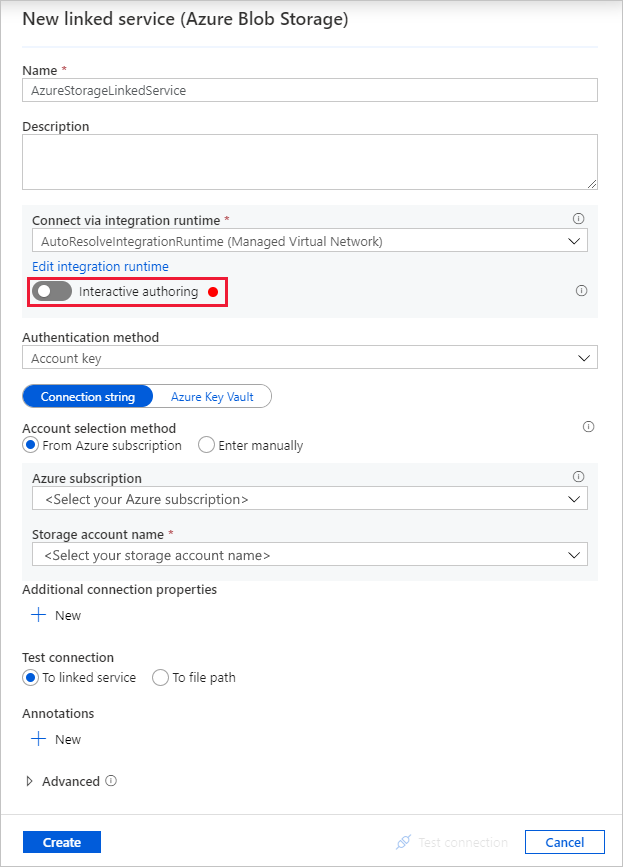
Selecione Testar ligação. Ele deve falhar quando a conta de armazenamento permite o acesso somente de redes selecionadas e requer que o Data Factory crie um ponto de extremidade privado para ele que deve ser aprovado antes de usá-lo. Na mensagem de erro, você verá um link para criar um ponto de extremidade privado que você pode seguir para criar um ponto de extremidade privado gerenciado. Uma alternativa é ir diretamente para a guia Gerenciar e seguir as instruções na próxima seção para criar um ponto de extremidade privado gerenciado.
Nota
A guia Gerenciar pode não estar disponível para todas as instâncias do data factory. Se não o vires, podes aceder a pontos de extremidade privados selecionando Author>Connections>Private Endpoint.
Mantenha a caixa de diálogo aberta e, em seguida, aceda à sua conta de armazenamento.
Siga as instruções nesta seção para aprovar o link privado.
Volte para a caixa de diálogo. Selecione Testar conexão novamente e selecione Criar para implantar o serviço vinculado.
Depois que o serviço vinculado é criado, ele volta para a página Definir propriedades . Junto a Caminho do ficheiro, selecione Procurar.
Vá para a pasta adftutorial/input, selecione o arquivo emp.txt e, em seguida, selecione OK.
Selecione OK. Vai automaticamente para a página do pipeline. Na guia Origem, confirme se SourceBlobDataset está selecionado. Para pré-visualizar os dados nesta página, selecione Pré-visualizar dados.
Criar um ponto final privado gerido
Se você não selecionou o hiperlink quando testou a conexão, siga o caminho. Agora deve criar um ponto de extremidade privado gerido que será ligado ao serviço associado que criou.
Vá para a guia Gerenciar .
Nota
A guia Gerenciar pode não estar disponível para todas as instâncias do Data Factory. Se não os vires, podes aceder a pontos de extremidade privados selecionando Author>Connections>Private Endpoint.
Vá para a seção Pontos de extremidade privados geridos.
Selecione + Novo em Pontos de extremidade privados gerenciados.

Selecione o bloco Armazenamento de Blobs do Azure da lista e selecione Continuar.
Introduza o nome da conta de armazenamento que criou.
Selecione Criar.
Depois de alguns segundos, você verá que o link privado criado precisa de uma aprovação.
Selecione o ponto de extremidade privado que você criou. Você pode ver um hiperlink que o levará a aprovar o ponto de extremidade privado no nível da conta de armazenamento.

Aprovação de um link privado em uma conta de armazenamento
Na conta de armazenamento, vá para Conexões de ponto final privado na secção Configurações.
Marque a caixa de seleção do ponto de extremidade privado que você criou e selecione Aprovar.

Adicione uma descrição e selecione Sim.
Volte para a secção Pontos de extremidade privados geridos da aba Gerir no Data Factory.
Após cerca de um ou dois minutos, você verá a aprovação do seu ponto de extremidade privado aparecer na interface do usuário do Data Factory.
Configurar um coletor
Gorjeta
Neste tutorial, tu usas autenticação SQL como o tipo de autenticação para o armazenamento de dados de destino. Você também pode escolher outros métodos de autenticação suportados, como Principal de Serviço e Identidade Gerenciada, se necessário. Para mais informações, consulte as secções correspondentes em Copiar e transformar dados em Base de Dados SQL do Azure usando Azure Data Factory.
Para armazenar segredos para armazenamentos de dados de forma segura, recomendamos também que utilize o Azure Key Vault. Para mais informações e ilustrações, consulte Armazenar credenciais em Azure Key Vault.
Criar um conjunto de dados de coletor e um serviço vinculado
Vá para o separador Sink e selecione + Novo para criar um conjunto de dados sink.
Na caixa de diálogo Novo Conjunto de Dados, digite SQL na caixa de pesquisa para filtrar os conectores. Selecione Base de Dados SQL do Azure e depois selecione Continue. Neste tutorial, vai copiar dados para uma base de dados SQL.
Na caixa de diálogo Definir Propriedades, digite OutputSqlDataset para Name. Na lista suspensa Serviço vinculado, selecione + Novo. Os conjuntos de dados têm de estar associados a um serviço ligado. O serviço ligado tem a cadeia de ligação que o Data Factory utiliza para se ligar à base de dados SQL em tempo de execução. O conjunto de dados especifica o contentor, a pasta e o ficheiro (opcional) para os quais os dados são copiados.
Na caixa de diálogo Novo serviço ligado (Base de Dados SQL do Azure), siga os seguintes passos:
- Em Name, introduza AzureSqlDatabaseLinkedService.
- Em nome do servidor, selecione a sua instância SQL Server.
- Certifique-se de ativar autoria interativa.
- Em Nome da base de dados, selecione a sua base de dados SQL.
- Em Nome de utilizador, introduza o nome do utilizador.
- Em Palavra-passe, introduza a palavra-passe do utilizador.
- Selecione Testar ligação. Ele deve falhar porque o servidor SQL permite o acesso somente de redes selecionadas e requer que o Data Factory crie um ponto de extremidade privado para ele, que deve ser aprovado antes de usá-lo. Na mensagem de erro, você verá um link para criar um ponto de extremidade privado que você pode seguir para criar um ponto de extremidade privado gerenciado. Uma alternativa é ir para o separador Gerir diretamente e seguir as instruções na próxima seção para criar um ponto de extremidade privado gerido.
- Mantenha a caixa de diálogo aberta e vá para o servidor SQL selecionado.
- Siga as instruções nesta seção para aprovar o link privado.
- Volte para a caixa de diálogo. Selecione Testar conexão novamente e selecione Criar para implantar o serviço vinculado.
Ele vai automaticamente para a caixa de diálogo Definir propriedades . Em Tabela, selecione [dbo].[emp]. Em seguida, selecione OK.
Vá para o separador com o pipeline, e, no conjunto de dados Sink, confirme se OutputSqlDataset está selecionado.

Opcionalmente, você pode mapear o esquema da origem para o esquema correspondente do destino seguindo o mapeamento de esquema na atividade de cópia.
Criar um ponto final privado gerido
Se você não selecionou o hiperlink quando testou a conexão, siga o caminho. Agora deve criar um ponto de extremidade privado gerido que será ligado ao serviço associado que criou.
Vá para a guia Gerenciar .
Vá para a seção Pontos de extremidade privados geridos.
Selecione + Novo em Pontos de extremidade privados gerenciados.
Selecione o bloco Base de Dados SQL do Azure da lista e selecione Continuar.
Digite o nome do servidor SQL selecionado.
Selecione Criar.
Depois de alguns segundos, você verá que o link privado criado precisa de uma aprovação.
Selecione o ponto de extremidade privado que você criou. Você pode ver um hiperlink que o levará a aprovar o endpoint privado no nível do servidor SQL.
Aprovação de um link privado no SQL Server
- No servidor SQL, vá para Conexões de ponto de extremidade privado na seção Configurações .
- Marque a caixa de seleção do ponto de extremidade privado que você criou e selecione Aprovar.
- Adicione uma descrição e selecione Sim.
- Volte para a secção Pontos de Extremidade Privados Geridos da aba Gerir no Data Factory.
- Deverá demorar um ou dois minutos para que a aprovação apareça no seu ponto de extremidade privado.
Debug and publish the pipeline (Depurar e publicar o pipeline)
Pode depurar um pipeline antes de publicar artefactos (serviços ligados, conjuntos de dados e pipeline) na Data Factory ou no seu próprio repositório Git do Repositórios do Azure.
- Para depurar o pipeline, selecione Depurar na barra de ferramentas. Verá o estado da execução do pipeline no separador Saída, na parte inferior da janela.
- Depois que o pipeline puder ser executado com êxito, na barra de ferramentas superior, selecione Publicar tudo. Esta ação publica entidades (conjuntos de dados e pipelines) que você criou no Data Factory.
- Aguarde até ver a notificação Publicação com êxito. Para ver as mensagens de notificação, selecione Mostrar notificações no canto superior direito (botão de sino).
Resumo
O pipeline neste exemplo copia dados do armazenamento Blob para a Base de Dados SQL usando endpoints privados na Data Factory Managed Rede Virtual. Aprendeu a:
- Criar uma fábrica de dados.
- Criar um pipeline com uma atividade de cópia.