Nota
O acesso a esta página requer autorização. Pode tentar iniciar sessão ou alterar os diretórios.
O acesso a esta página requer autorização. Pode tentar alterar os diretórios.
APLICA-SE A: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Gorjeta
Data Factory em Microsoft Fabric é a próxima geração de Azure Data Factory, com uma arquitetura mais simples, IA incorporada e novas funcionalidades. Se és novo na integração de dados, começa pelo Fabric Data Factory. As cargas de trabalho existentes do ADF podem atualizar para o Fabric para aceder a novas capacidades em ciência de dados, análise em tempo real e relatórios.
Os fluxos de dados estão disponíveis tanto nos pipelines do Azure Data Factory como no do Azure Synapse Analytics. Este artigo aplica-se ao mapeamento de fluxos de dados. Se você é novo em transformações, consulte o artigo introdutório Transformar dados usando fluxos de dados de mapeamento.
Depois de concluir a transformação dos dados, escreva-os em um armazenamento de destino usando a transformação de sink. Cada fluxo de dados requer pelo menos uma transformação de saída, mas pode-se gravar em tantas saídas quanto forem necessárias para concluir o fluxo de transformação. Para gravar em coletores adicionais, crie novos fluxos por meio de novas ramificações e divisões condicionais.
Cada transformação de coletor está associada a exatamente um objeto de conjunto de dados ou serviço vinculado. A transformação do coletor determina a forma e o local dos dados nos quais você deseja gravar.
Conjuntos de dados embutidos
Ao criar uma transformação de coletor, escolha se as informações do coletor são definidas dentro de um objeto de conjunto de dados ou dentro da transformação do coletor. A maioria dos formatos está disponível em apenas um ou outro. Para saber como usar um conector específico, consulte o documento do conector apropriado.
Quando um formato é suportado tanto em linha como num objeto de conjunto de dados, há benefícios para cada um. Os objetos de conjunto de dados são entidades reutilizáveis que podem ser usadas em outros fluxos de dados e atividades, como Copiar. Essas entidades reutilizáveis são especialmente úteis quando você usa um esquema protegido. Os conjuntos de dados não são baseados no Spark. Ocasionalmente, talvez seja necessário substituir determinadas configurações ou projeção de esquema na transformação do coletor.
Os conjuntos de dados embutidos são recomendados quando você usa esquemas flexíveis, instâncias de coletor únicas ou coletores parametrizados. Se o coletor for fortemente parametrizado, os conjuntos de dados embutidos permitirão que você não crie um objeto "fictício". Os conjuntos de dados embutidos são baseados no Spark e suas propriedades são nativas do fluxo de dados.
Para usar um conjunto de dados embutido, selecione o formato desejado no seletor Tipo de coletor . Em vez de selecionar um conjunto de dados de coletor, selecione o serviço vinculado ao qual deseja se conectar.
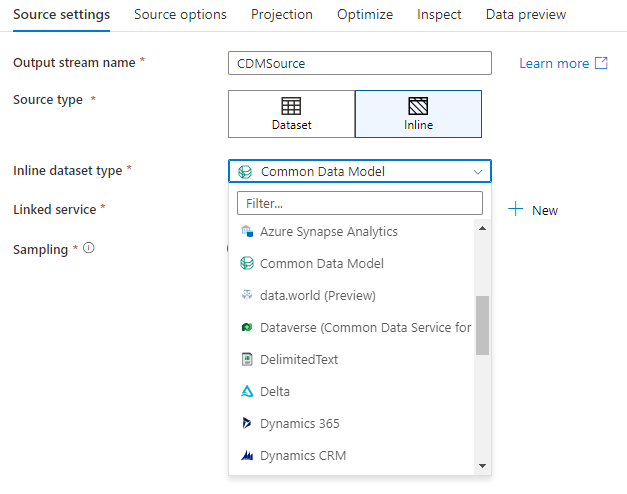
Base de dados do espaço de trabalho (apenas para espaços de trabalho Synapse)
Ao utilizar fluxos de dados nos espaços de trabalho do Azure Synapse, terá uma opção adicional para integrar os seus dados diretamente num tipo de base de dados que esteja dentro do seu espaço de trabalho Synapse. Tal reduzirá a necessidade de adicionar serviços ou conjuntos de dados ligados a essas bases de dados. As bases de dados criadas através dos modelos de base de dados Azure Synapse também estão acessíveis quando seleciona Workspace DB.
Nota
O conector da base de dados Azure Synapse Workspace está atualmente em pré-visualização pública e só pode funcionar com bases de dados Spark Lake neste momento

Tipos de lavatório suportados
O mapeamento do fluxo de dados segue uma abordagem de extração, carregamento e transformação (ELT) e funciona com conjuntos de dados staging que estão todos em Azure. Atualmente, os seguintes conjuntos de dados podem ser usados em uma transformação de coletor.
Gorjeta
O lavatório pode ter um formato diferente da fonte. Esta é uma etapa de como você pode transformar de um formato para outro. Por exemplo, de um CSV para uma pia de parquet. Talvez seja necessário fazer algumas transformações no fluxo de dados entre a origem e o coletor para que isso funcione corretamente. (Por exemplo, o Parquet tem requisitos de cabeçalho mais específicos do que o CSV.)
| Conector | Formato | Conjunto de dados/em linha |
|---|---|---|
| Armazenamento de Blobs do Azure |
Avro Texto delimitado Delta; JSON ORC Parquet |
✓/✓ ✓/✓ -/✓ ✓/✓ ✓/✓ ✓/✓ |
| Azure Cosmos DB para NoSQL | ✓/- | |
| Azure Data Lake Storage Gen1 |
Avro Texto delimitado JSON ORC Parquet |
✓/- ✓/- ✓/- ✓/✓ ✓/- |
| Azure Data Lake Storage Gen2 |
Avro Common Data Model Texto delimitado Delta; JSON ORC Parquet |
✓/✓ -/✓ ✓/✓ -/✓ ✓/✓ ✓/✓ ✓/✓ |
| Base de Dados do Azure para MySQL | ✓/✓ | |
| Base de Dados do Azure para PostgreSQL | ✓/✓ | |
| Azure Data Explorer | ✓/✓ | |
| Base de Dados SQL do Azure | ✓/✓ | |
| Azure SQL Managed Instance | ✓/- | |
| Azure Synapse Analytics | ✓/- | |
| Dataverse | ✓/✓ | |
| Dynamics 365 | ✓/✓ | |
| Dynamics CRM | ✓/✓ | |
| Fabric Lakehouse | ✓/✓ | |
| SFTP |
Avro Texto delimitado JSON ORC Parquet |
✓/✓ ✓/✓ ✓/✓ ✓/✓ ✓/✓ |
| Flocos de neve | ✓/✓ | |
| SQL Server | ✓/✓ |
As configurações específicas desses conectores estão localizadas na guia Configurações . Exemplos de script de fluxo de dados e informações sobre essas configurações estão localizados na documentação do conector.
O serviço tem acesso a mais de 90 conectores nativos. Para gravar dados nessas outras fontes a partir do seu fluxo de dados, use a Atividade de cópia para carregar esses dados de um coletor suportado.
Configurações do coletor
Depois de adicionar um sink, configure através do separador Sink. Aqui, pode selecionar ou criar o conjunto de dados ao qual o seu sink escreve. Os valores de desenvolvimento para parâmetros de conjunto de dados podem ser configurados nas Configurações de depuração. (O modo de depuração deve estar ativado.)
O vídeo a seguir explica várias opções diferentes de coletor para tipos de arquivo delimitados por texto.

Desvio de esquema: desvio de esquema é a capacidade do serviço de lidar nativamente com esquemas flexíveis em seus fluxos de dados sem a necessidade de definir explicitamente as alterações de coluna. Habilite Permitir desvio de esquema para escrever colunas adicionais além do que está definido no esquema de dados do destino.
Validar esquema: Se validar esquema estiver selecionado, o fluxo de dados falhará se alguma coluna na projeção de destino não for encontrada no repositório de destino ou se os tipos de dados não corresponderem. Use essa configuração para impor que o esquema do coletor atenda ao contrato de sua projeção definida. É útil em cenários de coletor de banco de dados para sinalizar que os nomes ou tipos de coluna foram alterados.
Receptáculo de cache
Um destino de cache refere-se a quando um fluxo de dados grava dados no cache do Spark em vez de em um armazenamento de dados. No mapeamento de fluxos de dados, pode fazer referência a esses dados dentro do mesmo fluxo muitas vezes usando uma consulta de cache. Isso é útil quando você deseja fazer referência a dados como parte de uma expressão, mas não deseja unir explicitamente as colunas a ela. Exemplos comuns em que um coletor de cache pode ajudar são procurar um valor máximo em um armazenamento de dados e fazer a correspondência de códigos de erro com um banco de dados de mensagens de erro.
Para gravar em um coletor de cache, adicione uma transformação de coletor e selecione Cache como o tipo de coletor. Ao contrário de outros tipos de coletor, você não precisa selecionar um conjunto de dados ou serviço vinculado porque não está gravando em um armazenamento externo.
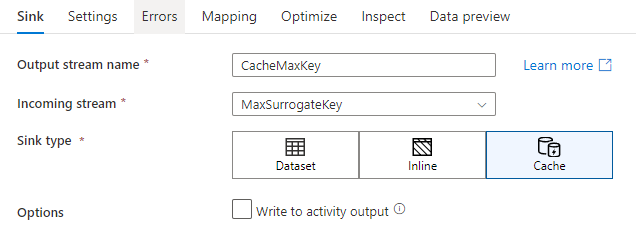
Nas configurações do coletor, você pode, opcionalmente, especificar as colunas de chave do coletor de cache. Eles são usados como condições de correspondência ao usar a lookup() função em uma pesquisa de cache. Se especificar colunas de chave, não poderá usar a função outputs() numa pesquisa de cache. Para saber mais sobre a sintaxe de pesquisa de cache, consulte Pesquisas em cache.
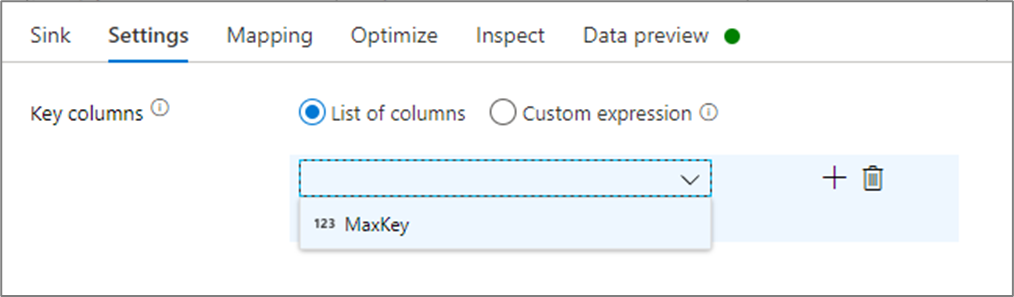
Por exemplo, se eu especificar uma única coluna de chave column1 num coletor de cache chamado cacheExample, chamar cacheExample#lookup() terá um parâmetro que especifica qual linha no coletor de cache deve corresponder. A função gera uma única coluna complexa com subcolunas para cada coluna mapeada.
Nota
Um destino de cache deve estar em um fluxo de dados completamente independente de qualquer transformação que faça referência a ele através de uma consulta de cache. Uma entrada de cache também deve ser a primeira entrada escrita.
Gravar na saída da atividade
O sumidouro de cache pode, opcionalmente, escrever os seus dados na saída da atividade Fluxo de Dados, que podem depois ser usados como entrada para outra atividade no pipeline. Isso permitirá que você passe dados de forma rápida e fácil para fora de sua atividade de fluxo de dados sem a necessidade de persistir os dados em um armazenamento de dados.
Note que a saída do Fluxo de Dados que é injetada diretamente no seu pipeline está limitada a 2MB. Assim, o Fluxo de Dados tentará adicionar o maior número possível de linhas à saída, mantendo-se dentro do limite de 2 MB; portanto, poderá, por vezes, não ver todas as linhas na saída da atividade. Definir "Apenas primeira linha" ao nível de atividade do Fluxo de Dados também ajuda a limitar a saída de dados do Fluxo de Dados, se necessário.
Método de atualização
Para tipos de coletor de banco de dados, a guia Configurações incluirá uma propriedade "Método de atualização". O padrão é inserir, mas também inclui opções de checkbox para atualizar, upsert e excluir. Para utilizar essas opções adicionais, você precisará adicionar uma transformação Alter Row antes do coletor. A linha Alter permitirá definir as condições para cada uma das ações do banco de dados. Se a sua fonte for uma fonte nativa habilitada para CDC, pode definir os métodos de atualização sem uma Linha de Alteração, pois o ADF já está ciente dos marcadores de linha para inserir, atualizar, fazer upsert e eliminar.
Mapeamento de campos
Semelhante a uma transformação select, na guia Mapeamento do coletor, você pode decidir quais colunas de entrada serão gravadas. Por padrão, todas as colunas de entrada, incluindo colunas derivadas, são mapeadas. Esse comportamento é conhecido como mapeamento automático.
Ao desativar o mapeamento automático, você pode adicionar mapeamentos fixos baseados em colunas ou mapeamentos baseados em regras. Com mapeamentos baseados em regras, você pode escrever expressões com correspondência de padrões. O mapeamento fixo mapeia nomes de colunas lógicas e físicas. Para obter mais informações sobre mapeamento baseado em regras, consulte Padrões de coluna no mapeamento de fluxo de dados.
Ordenação de sinks personalizada
Por padrão, os dados são gravados em vários coletores em uma ordem não determinística. O mecanismo de execução grava dados em paralelo à medida que a lógica de transformação é concluída, e a ordem do coletor pode variar a cada execução. Para especificar uma ordem de destino exata, habilite Ordenação de destino personalizada na guia Geral no fluxo de dados. Quando ativado, os coletores são gravados sequencialmente em ordem crescente.

Nota
Ao utilizar pesquisas em cache, certifique-se de que a ordem dos filtros tenha os filtros em cache definidos como 1, o valor mais baixo (ou primeiro) na ordem.
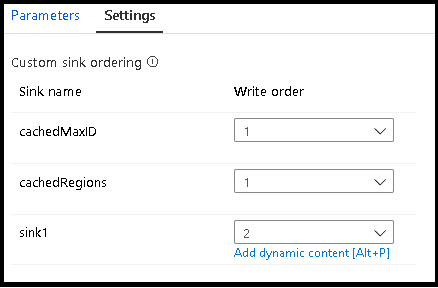
Grupos de lavatórios
Você pode agrupar coletores aplicando o mesmo número de ordem para uma série de coletores. O serviço tratará esses coletores como grupos que podem ser executados em paralelo. As opções para execução paralela aparecerão na atividade de fluxo de dados do pipeline.
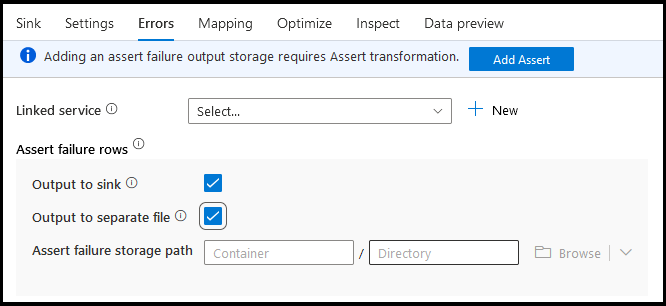
Erros
No separador de erros de sink, é possível configurar a manipulação das linhas de erros para capturar e redirecionar a saída de erros de drivers de bases de dados e asserções falhadas.
Ao gravar em bancos de dados, determinadas linhas de dados podem falhar devido a restrições definidas pelo destino. Por padrão, uma execução de fluxo de dados falhará no primeiro erro que receber. Em determinados conectores, você pode optar por Continuar em caso de erro, permitindo que o fluxo de dados seja concluído mesmo que linhas individuais tenham erros. Atualmente, esta funcionalidade está disponível apenas no Base de Dados SQL do Azure e no Azure Synapse. Para mais informações, consulte gestão de linhas de erro no SQL do Azure DB.
A seguir está um tutorial em vídeo sobre como usar automaticamente o tratamento de linhas de erro de banco de dados na sua transformação de destino.
Para linhas de falha de declaração, você pode usar a transformação Assert upstream em seu fluxo de dados e, em seguida, redirecionar asserções com falha para um arquivo de saída aqui na guia erros de coletor. Você também tem uma opção aqui para ignorar linhas com falhas de asserção e não enviar essas linhas para o armazenamento de dados de destino do coletor.
Pré-visualização de dados no coletor
Ao buscar uma visualização de dados no modo de depuração, nenhum dado será gravado no coletor. Será devolvida uma visualização de como são os dados, mas nada será gravado no seu destino de armazenamento. Para testar a gravação de dados no seu destino, execute um debug do pipeline a partir da interface do pipeline.
Script de fluxo de dados
Exemplo
Abaixo está um exemplo de uma transformação de coletor e seu script de fluxo de dados:
sink(input(
movie as integer,
title as string,
genres as string,
year as integer,
Rating as integer
),
allowSchemaDrift: true,
validateSchema: false,
deletable:false,
insertable:false,
updateable:true,
upsertable:false,
keys:['movie'],
format: 'table',
skipDuplicateMapInputs: true,
skipDuplicateMapOutputs: true,
saveOrder: 1,
errorHandlingOption: 'stopOnFirstError') ~> sink1
Conteúdos relacionados
Agora que você criou seu fluxo de dados, adicione uma atividade de fluxo de dados ao seu pipeline.