Nota
O acesso a esta página requer autorização. Pode tentar iniciar sessão ou alterar os diretórios.
O acesso a esta página requer autorização. Pode tentar alterar os diretórios.
APLICA-SE A: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Gorjeta
Data Factory em Microsoft Fabric é a próxima geração de Azure Data Factory, com uma arquitetura mais simples, IA incorporada e novas funcionalidades. Se és novo na integração de dados, começa pelo Fabric Data Factory. As cargas de trabalho existentes do ADF podem atualizar para o Fabric para aceder a novas capacidades em ciência de dados, análise em tempo real e relatórios.
Os fluxos de dados estão disponíveis tanto nos pipelines do Azure Data Factory como no do Azure Synapse Analytics. Este artigo aplica-se ao mapeamento de fluxos de dados. Se você é novo em transformações, consulte o artigo introdutório Transformar dados usando fluxos de dados de mapeamento.
Use a transformação flowlet para executar um flowlet de fluxo de dados de mapeamento criado anteriormente. Para uma visão geral dos flowlets, veja Flowlets no mapeamento do fluxo de dados | Microsoft Docs
Nota
A transformação do flowlet nos pipelines Azure Data Factory e Synapse Analytics está atualmente em pré-visualização pública
Configuração
A transformação flowlet contém as seguintes definições de configuração
Flowlet
Selecione o flowlet para ser executado. Uma vez selecionado o flowlet, será possível mapear as colunas de entrada, se existirem, na aba de mapeamento.
Mapeamento
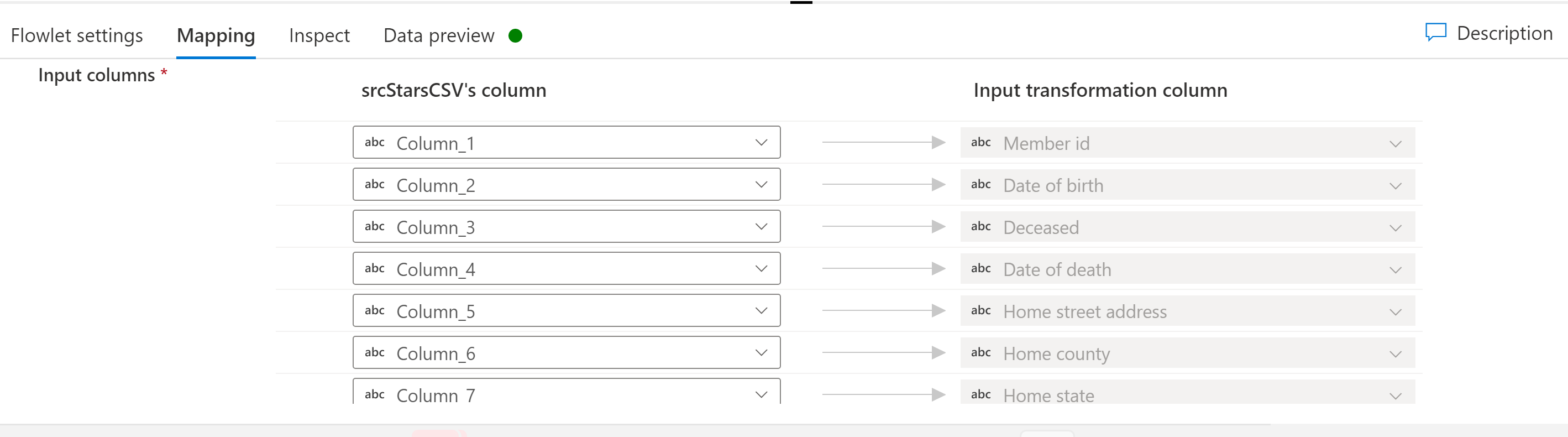
Se o flowlet selecionado tiver colunas de entrada, você poderá mapear colunas do fluxo de entrada para as colunas de entrada esperadas no flowlet. Esse mapeamento de suas colunas de fluxos de dados de mapeamento para o flowlet é o que permite que os flowlets sirvam como trechos reutilizáveis da lógica de fluxo de dados de mapeamento em potencialmente muitos fluxos de dados de mapeamento.
Script de fluxo de dados
Sintaxe
<incomingStream>
<transformation> ~> <transformationName>
<outputStream>
Exemplo
source1 derive(Test = "test") ~> DerivedColumn1
DerivedColumn1 output() ~> output1