Observação
O acesso a essa página exige autorização. Você pode tentar entrar ou alterar diretórios.
O acesso a essa página exige autorização. Você pode tentar alterar os diretórios.
O artigo explica como usar o PolyBase em um dispositivo PDW (Analytics Platform System) ou APS para consultar dados externos no Hadoop.
Pré-requisitos
O PolyBase é compatível com dois provedores de Hadoop, HDP (Hortonworks Data Platform) e CDH (Cloudera Distributed Hadoop). O Hadoop segue o padrão "Maior.Menor.Versão" para suas novas versões, e todas as versões dentro de uma versão Maior e Menor com suporte são suportadas. Há suporte para os seguintes provedores hadoop:
- Hortonworks HDP 1.3 no Linux/Windows Server
- Hortonworks HDP 2.1 – 2.6 no Linux
- Hortonworks HDP 3.0 – 3.1 no Linux
- Hortonworks HDP 2.1 – 2.3 no Windows Server
- Cloudera CDH 4.3 no Linux
- Cloudera CDH 5.1 – 5.5, 5.9 – 5.13, 5.15 e 5.16 no Linux
Configurar a conectividade do Hadoop
Primeiro, configure o APS para usar seu provedor Hadoop específico.
Execute sp_configure com “conectividade do hadoop” e defina um valor adequado para seu provedor. Para encontrar o valor de seu provedor, consulte Configuração de conectividade do PolyBase.
-- Values map to various external data sources. -- Example: value 7 stands for Hortonworks HDP 2.1 to 2.6 and 3.0 - 3.1 on Linux, -- 2.1 to 2.3 on Windows Server, and Azure Blob Storage sp_configure @configname = 'hadoop connectivity', @configvalue = 7; GO RECONFIGURE GOReinicie a região do APS usando a página Status do Serviço no Gerenciador de Configurações do Dispositivo.
Habilitar a computação de pushdown
Para melhorar o desempenho de consulta, habilite a computação empurrada para seu cluster do Hadoop:
Abra uma conexão de área de trabalho remota com o nó de controle PDW da APS.
Encontre o arquivo
yarn-site.xmlno nó de controle. Normalmente, o caminho é:C:\Program Files\Microsoft SQL Server Parallel Data Warehouse\100\Hadoop\conf\.No computador do Hadoop, localize o arquivo análogo no diretório da configuração do Hadoop. No arquivo, localize e copie o valor da chave
yarn.application.classpathde configuração.No nó de controle, no arquivo
yarn.site.xml, localize a propriedadeyarn.application.classpath. Cole o valor da máquina Hadoop no elemento de propriedade.Para todas as versões do CDH 5.X, você precisará adicionar os
mapreduce.application.classpathparâmetros de configuração ao final doyarn.site.xmlarquivo ou aomapred-site.xmlarquivo. HortonWorks inclui essas configurações dentro dasyarn.application.classpathconfigurações. Para obter exemplos, consulte a configuração do PolyBase.
Exemplo de arquivos XML para valores padrão do cluster CDH 5.X
Yarn-site.xml com configuração yarn.application.classpath e mapreduce.application.classpath.
<?xml version="1.0" encoding="utf-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<!-- Put site-specific property overrides in this file. -->
<configuration>
<property>
<name>yarn.resourcemanager.connect.max-wait.ms</name>
<value>40000</value>
</property>
<property>
<name>yarn.resourcemanager.connect.retry-interval.ms</name>
<value>30000</value>
</property>
<!-- Applications' Configuration-->
<property>
<description>CLASSPATH for YARN applications. A comma-separated list of CLASSPATH entries</description>
<!-- Please set this value to the correct yarn.application.classpath that matches your server side configuration -->
<!-- For example: $HADOOP_CONF_DIR,$HADOOP_COMMON_HOME/share/hadoop/common/*,$HADOOP_COMMON_HOME/share/hadoop/common/lib/*,$HADOOP_HDFS_HOME/share/hadoop/hdfs/*,$HADOOP_HDFS_HOME/share/hadoop/hdfs/lib/*,$HADOOP_YARN_HOME/share/hadoop/yarn/*,$HADOOP_YARN_HOME/share/hadoop/yarn/lib/* -->
<name>yarn.application.classpath</name>
<value>$HADOOP_CLIENT_CONF_DIR,$HADOOP_CONF_DIR,$HADOOP_COMMON_HOME/*,$HADOOP_COMMON_HOME/lib/*,$HADOOP_HDFS_HOME/*,$HADOOP_HDFS_HOME/lib/*,$HADOOP_YARN_HOME/*,$HADOOP_YARN_HOME/lib/,$HADOOP_MAPRED_HOME/*,$HADOOP_MAPRED_HOME/lib/*,$MR2_CLASSPATH*</value>
</property>
<!-- kerberos security information, PLEASE FILL THESE IN ACCORDING TO HADOOP CLUSTER CONFIG
<property>
<name>yarn.resourcemanager.principal</name>
<value></value>
</property>
-->
</configuration>
Se você optar por dividir as duas definições de configuração no mapred-site.xml e yarn-site.xml, os arquivos serão os seguintes:
Para yarn-site.xml:
<?xml version="1.0" encoding="utf-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<!-- Put site-specific property overrides in this file. -->
<configuration>
<property>
<name>yarn.resourcemanager.connect.max-wait.ms</name>
<value>40000</value>
</property>
<property>
<name>yarn.resourcemanager.connect.retry-interval.ms</name>
<value>30000</value>
</property>
<!-- Applications' Configuration-->
<property>
<description>CLASSPATH for YARN applications. A comma-separated list of CLASSPATH entries</description>
<!-- Please set this value to the correct yarn.application.classpath that matches your server side configuration -->
<!-- For example: $HADOOP_CONF_DIR,$HADOOP_COMMON_HOME/share/hadoop/common/*,$HADOOP_COMMON_HOME/share/hadoop/common/lib/*,$HADOOP_HDFS_HOME/share/hadoop/hdfs/*,$HADOOP_HDFS_HOME/share/hadoop/hdfs/lib/*,$HADOOP_YARN_HOME/share/hadoop/yarn/*,$HADOOP_YARN_HOME/share/hadoop/yarn/lib/* -->
<name>yarn.application.classpath</name>
<value>$HADOOP_CLIENT_CONF_DIR,$HADOOP_CONF_DIR,$HADOOP_COMMON_HOME/*,$HADOOP_COMMON_HOME/lib/*,$HADOOP_HDFS_HOME/*,$HADOOP_HDFS_HOME/lib/*,$HADOOP_YARN_HOME/*,$HADOOP_YARN_HOME/lib/*</value>
</property>
<!-- kerberos security information, PLEASE FILL THESE IN ACCORDING TO HADOOP CLUSTER CONFIG
<property>
<name>yarn.resourcemanager.principal</name>
<value></value>
</property>
-->
</configuration>
Para mapred-site.xml:
Observe a propriedade mapreduce.application.classpath. No CDH 5.x, você encontrará os valores de configuração na mesma convenção de nomenclatura no Ambari.
<?xml version="1.0"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<!-- Put site-specific property overrides in this file. -->
<configuration xmlns:xi="http://www.w3.org/2001/XInclude">
<property>
<name>mapred.min.split.size</name>
<value>1073741824</value>
</property>
<property>
<name>mapreduce.app-submission.cross-platform</name>
<value>true</value>
</property>
<property>
<name>mapreduce.application.classpath</name>
<value>$HADOOP_MAPRED_HOME/*,$HADOOP_MAPRED_HOME/lib/*,$MR2_CLASSPATH</value>
</property>
<!--kerberos security information, PLEASE FILL THESE IN ACCORDING TO HADOOP CLUSTER CONFIG
<property>
<name>mapreduce.jobhistory.principal</name>
<value></value>
</property>
<property>
<name>mapreduce.jobhistory.address</name>
<value></value>
</property>
-->
</configuration>
Exemplo de arquivos XML para valores padrão do cluster HDP 3.X
Para yarn-site.xml:
<?xml version="1.0" encoding="utf-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<!-- Put site-specific property overrides in this file. -->
<configuration>
<property>
<name>yarn.resourcemanager.connect.max-wait.ms</name>
<value>40000</value>
</property>
<property>
<name>yarn.resourcemanager.connect.retry-interval.ms</name>
<value>30000</value>
</property>
<!-- Applications' Configuration-->
<property>
<description>CLASSPATH for YARN applications. A comma-separated list of CLASSPATH entries</description>
<!-- Please set this value to the correct yarn.application.classpath that matches your server side configuration -->
<!-- For example: $HADOOP_CONF_DIR,$HADOOP_COMMON_HOME/share/hadoop/common/*,$HADOOP_COMMON_HOME/share/hadoop/common/lib/*,$HADOOP_HDFS_HOME/share/hadoop/hdfs/*,$HADOOP_HDFS_HOME/share/hadoop/hdfs/lib/*,$HADOOP_YARN_HOME/share/hadoop/yarn/*,$HADOOP_YARN_HOME/share/hadoop/yarn/lib/* -->
<name>yarn.application.classpath</name>
<value>$HADOOP_CONF_DIR,/usr/hdp/3.1.0.0-78/hadoop/*,/usr/hdp/3.1.0.0-78/hadoop/lib/*,/usr/hdp/current/hadoop-hdfs-client/*,/usr/hdp/current/hadoop-hdfs-client/lib/*,/usr/hdp/current/hadoop-yarn-client/*,/usr/hdp/current/hadoop-yarn-client/lib/*,/usr/hdp/3.1.0.0-78/hadoop-mapreduce/*,/usr/hdp/3.1.0.0-78/hadoop-yarn/*,/usr/hdp/3.1.0.0-78/hadoop-yarn/lib/*,/usr/hdp/3.1.0.0-78/hadoop-mapreduce/lib/*,/usr/hdp/share/hadoop/common/*,/usr/hdp/share/hadoop/common/lib/*,/usr/hdp/share/hadoop/tools/lib/*</value>
</property>
<!-- kerberos security information, PLEASE FILL THESE IN ACCORDING TO HADOOP CLUSTER CONFIG
<property>
<name>yarn.resourcemanager.principal</name>
<value></value>
</property>
-->
</configuration>
Configurar uma tabela externa
Para consultar os dados em sua fonte de dados do Hadoop, você precisa definir uma tabela externa para usar em consultas Transact-SQL. As etapas a seguir descrevem como configurar a tabela externa.
Crie uma chave mestra no banco de dados. É necessário criptografar o segredo da credencial.
CREATE MASTER KEY ENCRYPTION BY PASSWORD = 'S0me!nfo';Crie uma credencial de escopo de banco de dados para clusters Hadoop protegidos por Kerberos.
-- IDENTITY: the Kerberos user name. -- SECRET: the Kerberos password CREATE DATABASE SCOPED CREDENTIAL HadoopUser1 WITH IDENTITY = '<hadoop_user_name>', Secret = '<hadoop_password>';Crie uma fonte de dados externa, usando CREATE EXTERNAL DATA SOURCE.
-- LOCATION (Required) : Hadoop Name Node IP address and port. -- RESOURCE MANAGER LOCATION (Optional): Hadoop Resource Manager location to enable pushdown computation. -- CREDENTIAL (Optional): the database scoped credential, created above. CREATE EXTERNAL DATA SOURCE MyHadoopCluster WITH ( TYPE = HADOOP, LOCATION ='hdfs://10.xxx.xx.xxx:xxxx', RESOURCE_MANAGER_LOCATION = '10.xxx.xx.xxx:xxxx', CREDENTIAL = HadoopUser1 );Crie um formato de arquivo externo com CREATE EXTERNAL FILE FORMAT.
-- FORMAT TYPE: Type of format in Hadoop (DELIMITEDTEXT, RCFILE, ORC, PARQUET). CREATE EXTERNAL FILE FORMAT TextFileFormat WITH ( FORMAT_TYPE = DELIMITEDTEXT, FORMAT_OPTIONS (FIELD_TERMINATOR ='|', USE_TYPE_DEFAULT = TRUE)Crie uma tabela externa que aponta para dados armazenados no Hadoop com CREATE EXTERNAL TABLE. Neste exemplo, os dados externos contêm os dados de sensor do carro.
-- LOCATION: path to file or directory that contains the data (relative to HDFS root). CREATE EXTERNAL TABLE [dbo].[CarSensor_Data] ( [SensorKey] int NOT NULL, [CustomerKey] int NOT NULL, [GeographyKey] int NULL, [Speed] float NOT NULL, [YearMeasured] int NOT NULL ) WITH (LOCATION='/Demo/', DATA_SOURCE = MyHadoopCluster, FILE_FORMAT = TextFileFormat );Crie estatísticas em uma tabela externa.
CREATE STATISTICS StatsForSensors on CarSensor_Data(CustomerKey, Speed)
Consultas do PolyBase
O PolyBase é adequado para três funções:
- Consultas ad hoc em tabelas externas.
- importar dados.
- exportar dados.
As consultas a seguir fornecem exemplo com os dados de sensor de carro fictícios.
Consultas ad hoc
A consulta ad hoc a seguir integra dados relacionais com dados do Hadoop. Ele seleciona clientes que dirigem mais rápido do que 35 mph, unindo dados estruturados do cliente armazenados no APS com dados de sensor de carro armazenados no Hadoop.
SELECT DISTINCT Insured_Customers.FirstName,Insured_Customers.LastName,
Insured_Customers. YearlyIncome, CarSensor_Data.Speed
FROM Insured_Customers, CarSensor_Data
WHERE Insured_Customers.CustomerKey = CarSensor_Data.CustomerKey and CarSensor_Data.Speed > 35
ORDER BY CarSensor_Data.Speed DESC
OPTION (FORCE EXTERNALPUSHDOWN); -- or OPTION (DISABLE EXTERNALPUSHDOWN)
Importar dados
A consulta a seguir importa dados externos para APS. Este exemplo importa dados de condutores rápidos para o APS, a fim de realizar uma análise mais detalhada. Para melhorar o desempenho, ele utiliza a tecnologia de armazenamento em colunas na APS.
CREATE TABLE Fast_Customers
WITH
(CLUSTERED COLUMNSTORE INDEX, DISTRIBUTION = HASH (CustomerKey))
AS
SELECT DISTINCT
Insured_Customers.CustomerKey, Insured_Customers.FirstName, Insured_Customers.LastName,
Insured_Customers.YearlyIncome, Insured_Customers.MaritalStatus
from Insured_Customers INNER JOIN
(
SELECT * FROM CarSensor_Data where Speed > 35
) AS SensorD
ON Insured_Customers.CustomerKey = SensorD.CustomerKey
Exportar dados
A consulta a seguir exporta dados do APS para o Hadoop. Ele pode ser usado para arquivar dados relacionais no Hadoop enquanto ainda pode consultá-los.
-- Export data: Move old data to Hadoop while keeping it query-able via an external table.
CREATE EXTERNAL TABLE [dbo].[FastCustomers2009]
WITH (
LOCATION='/archive/customer/2009',
DATA_SOURCE = HadoopHDP2,
FILE_FORMAT = TextFileFormat
)
AS
SELECT T.* FROM Insured_Customers T1 JOIN CarSensor_Data T2
ON (T1.CustomerKey = T2.CustomerKey)
WHERE T2.YearMeasured = 2009 and T2.Speed > 40;
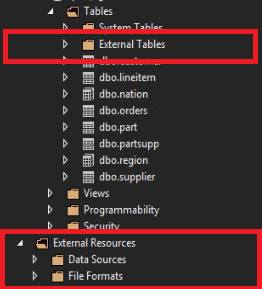
Exibir objetos PolyBase no SSDT
Nas Ferramentas de Dados do SQL Server, as tabelas externas são exibidas em uma pasta separada Tabelas Externas. As fontes de dados externas e os formatos de arquivo externos estão em subpastas em Recursos Externos.
Conteúdo relacionado
- Para configurações de segurança do Hadoop, consulte configurar a segurança do Hadoop.
- Para obter mais informações sobre o PolyBase, consulte o que é o PolyBase?.