Observação
O acesso a essa página exige autorização. Você pode tentar entrar ou alterar diretórios.
O acesso a essa página exige autorização. Você pode tentar alterar os diretórios.
APLICA-SE A: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Dica
Data Factory no Microsoft Fabric é a próxima geração de Azure Data Factory, com uma arquitetura mais simples, IA interna e novos recursos. Se você não estiver familiarizado com a integração de dados, comece com Fabric Data Factory. As cargas de trabalho existentes do ADF podem ser atualizadas para Fabric para acessar novos recursos em ciência de dados, análise em tempo real e relatórios.
Neste tutorial, você usará o Azure PowerShell para criar um pipeline do Data Factory que copia dados de um banco de dados SQL Server para o Azure Blob Storage. Você cria e usa um runtime de integração auto-hospedada, o qual move dados entre locais e armazenamentos de dados da nuvem.
Observação
Este artigo não fornece uma introdução detalhada do serviço de Data Factory. Para obter mais informações, consulte Introduction to Azure Data Factory.
Neste tutorial, você executa as seguintes etapas:
- Criar uma fábrica de dados.
- Criar um runtime de integração auto-hospedada.
- Crie serviços vinculados SQL Server e Armazenamento do Azure.
- Crie conjuntos de dados de Blob SQL Server e Azure.
- Criar um pipeline com uma atividade de cópia para mover os dados.
- Iniciar uma execução de pipeline.
- Monitorar a execução de pipeline.
Pré-requisitos
assinatura do Azure
Antes de começar, se você ainda não tiver uma assinatura Azure, criar uma conta gratuita.
Azure funções
Para criar instâncias do Data Factory, a conta de usuário usada para entrar no Azure deve receber uma função Contributor ou Owner ou deve ser um administrador da assinatura do Azure.
Para exibir as permissões que você tem na assinatura, acesse o portal do Azure, selecione seu nome de usuário no canto superior direito e selecione Permissions. Se tiver acesso a várias assinaturas, selecione a que for adequada. Para obter instruções de exemplo sobre como adicionar um usuário a uma função, consulte o artigo Assign Azure roles using the Azure portal.
SQL Server 2014, 2016 e 2017
Neste tutorial, você usará um banco de dados SQL Server como um armazenamento de dados source. O pipeline no data factory criado neste tutorial copia dados desse banco de dados do SQL Server (origem) para um Armazenamento de Blobs do Azure (coletor). Em seguida, crie uma tabela chamada emp em seu banco de dados SQL Server e insira algumas entradas de exemplo na tabela.
Inicie SQL Server Management Studio. Se ainda não estiver instalado no computador, vá para Download SQL Server Management Studio.
Conecte-se à sua instância de SQL Server usando suas credenciais.
Crie um banco de dados de exemplo. No modo de exibição de árvore, clique com o botão direito do mouse em Bancos de Dados e selecione Novo Banco de Dados.
Na janela Novo Banco de Dados, digite um nome para o banco de dados e selecione OK.
Para criar a tabela emp e inserir alguns dados de exemplo nela, execute o seguinte script de consulta no banco de dados. No modo de exibição de árvore, clique com o botão direito do mouse no banco de dados que você criou e selecione Nova Consulta.
CREATE TABLE dbo.emp ( ID int IDENTITY(1,1) NOT NULL, FirstName varchar(50), LastName varchar(50) ) GO INSERT INTO emp (FirstName, LastName) VALUES ('John', 'Doe') INSERT INTO emp (FirstName, LastName) VALUES ('Jane', 'Doe') GO
conta de Armazenamento do Azure
Neste tutorial, use uma conta de armazenamento do Azure de uso geral (especificamente o Armazenamento de Blobs do Azure) como um armazenamento de dados de destino/coletor. Se você não tiver uma conta de armazenamento Azure de uso geral, consulte Criar uma conta de armazenamento. O pipeline no data factory criado neste tutorial copia dados do banco de dados do SQL Server (origem) para esse Armazenamento de Blobs do Azure (coletor).
Obter o nome da conta de armazenamento e a chave da conta
Você usa o nome e a chave de sua conta de armazenamento Azure neste tutorial. Obtenha o nome e a chave da sua conta de armazenamento fazendo o seguinte:
Entre no portal Azure com seu nome de usuário e senha Azure.
No painel esquerdo, selecione Mais serviços, filtre usando a palavra-chave Armazenamento e selecione Contas de armazenamento.

Na lista de contas de armazenamento, filtre pela sua conta de armazenamento (se necessário) e, em seguida, selecione a sua conta de armazenamento.
Na janela Conta de armazenamento, selecione Chaves de acesso.
Nas caixas Nome da conta de armazenamento e key1, copie os valores e depois cole-os no Bloco de Notas ou outro editor para uso posterior neste tutorial.
Criar o contêiner adftutorial
Nesta seção, você criará um contêiner de blob chamado adftutorial no armazenamento de Blobs Azure.
Na janela Conta de armazenamento, alterne para Visão geral e depois selecione Blobs.
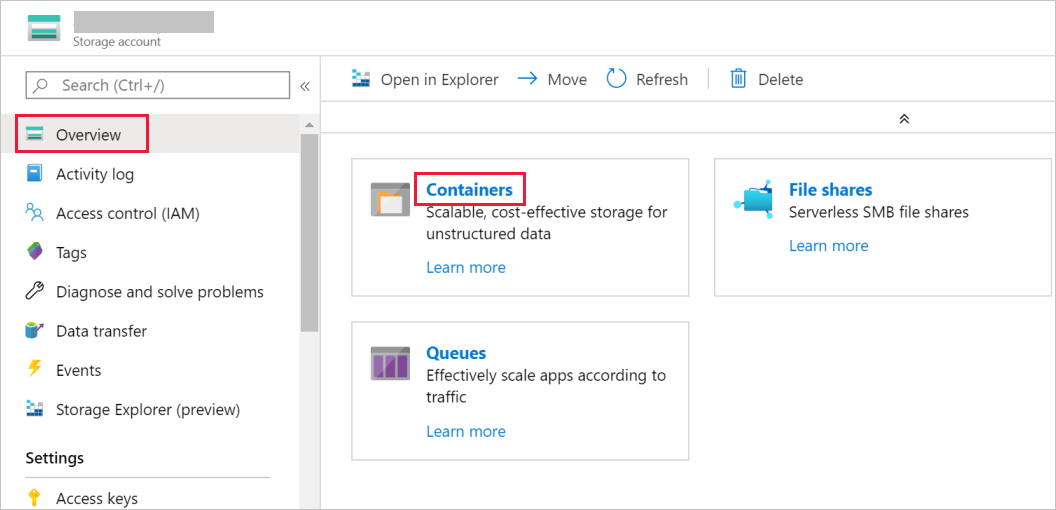
Na janela Serviço Blob, selecione Contêiner.
Na janela Novo contêiner, na caixa Nome, insira adftutorial e depois selecione OK.

Na lista de contêineres, selecione adftutorial.
Mantenha aberta a janela contêiner para adftutorial. Use-a para verificar a saída no final do tutorial. O Data Factory cria automaticamente a pasta de saída nesse contêiner, portanto você não precisa criar uma.
Windows PowerShell
Instalar Azure PowerShell
Observação
Recomendamos que você use o módulo Azure Az PowerShell para interagir com Azure. Para começar, consulte Instalar Azure PowerShell. Para saber como migrar para o módulo do Az PowerShell, consulte Migrate Azure PowerShell do AzureRM para o Az.
Instale a versão mais recente do Azure PowerShell se você ainda não a tiver em seu computador. Para obter instruções detalhadas, consulte Como instalar e configurar Azure PowerShell.
Fazer logon no PowerShell
Inicie o PowerShell em seu computador e mantenha-o aberto até a conclusão deste tutorial de início rápido. Se você fechar e reabrir, será necessário executar esses comandos novamente.
Execute o seguinte comando e, em seguida, insira o nome de usuário e a senha Azure que você usa para entrar no portal do Azure:
Connect-AzAccountSe você tiver várias assinaturas Azure, execute o comando a seguir para selecionar a assinatura com a qual deseja trabalhar. Substitua SubscriptionId pela ID da assinatura do Azure:
Select-AzSubscription -SubscriptionId "<SubscriptionId>"
Criar uma fábrica de dados (data factory)
Defina uma variável para o nome do grupo de recursos que você usará nos comandos do PowerShell posteriormente. Copie o comando a seguir para o PowerShell, especifique um nome para o grupo de recursos Azure (entre aspas duplas; por exemplo,
"adfrg") e execute o comando.$resourceGroupName = "ADFTutorialResourceGroup"Para criar o grupo de recursos Azure, execute o seguinte comando:
New-AzResourceGroup $resourceGroupName -location 'East US'Se o grupo de recursos já existir, não convém substituí-lo. Atribua um valor diferente para a variável
$resourceGroupNamee execute o comando novamente.Defina uma variável para o nome do data factory que você pode usar nos comandos do PowerShell mais tarde. O nome deve começar com uma letra ou um número e pode conter apenas letras, números e o caractere traço (-).
Importante
Atualize o nome do Data Factory usando um nome globalmente exclusivo. Por exemplo, ADFTutorialFactorySP1127.
$dataFactoryName = "ADFTutorialFactory"Defina uma variável para o local do data factory:
$location = "East US"Para criar o data factory, execute o seguinte cmdlet
Set-AzDataFactoryV2:Set-AzDataFactoryV2 -ResourceGroupName $resourceGroupName -Location $location -Name $dataFactoryName
Observação
- O nome da fábrica de dados deve ser único em todo o mundo. Se você receber o erro a seguir, altere o nome e tente novamente.
The specified data factory name 'ADFv2TutorialDataFactory' is already in use. Data factory names must be globally unique. - Para criar instâncias do Data Factory, a conta de usuário que você usa para entrar no Azure deve ter a função de colaborador ou proprietário ou ser um administrador da assinatura do Azure.
- Para obter uma lista de Azure regiões em que o Data Factory está disponível no momento, selecione as regiões que lhe interessam na página a seguir e expanda Analytics para localizar Data Factory: Produtos disponíveis por região. Os armazenamentos de dados (Armazenamento do Azure, Banco de Dados SQL do Azure e assim por diante) e cálculos (Azure HDInsight e assim por diante) usados pelo data factory podem estar em outras regiões.
Criar um runtime de integração auto-hospedado
Nesta seção, você criará um runtime de integração auto-hospedada e o associará a um computador local com o banco de dados SQL Server. O Integration Runtime auto-hospedado é o componente que copia dados do banco de dados do SQL Server em seu computador para o armazenamento de Blobs do Azure.
Crie uma variável para o nome do Integration Runtime. Use um nome exclusivo e anote o nome. Você o usará posteriormente neste tutorial.
$integrationRuntimeName = "ADFTutorialIR"Criar um runtime de integração auto-hospedada.
Set-AzDataFactoryV2IntegrationRuntime -ResourceGroupName $resourceGroupName -DataFactoryName $dataFactoryName -Name $integrationRuntimeName -Type SelfHosted -Description "selfhosted IR description"Veja o exemplo de saída:
Name : ADFTutorialIR Type : SelfHosted ResourceGroupName : <resourceGroupName> DataFactoryName : <dataFactoryName> Description : selfhosted IR description Id : /subscriptions/<subscription ID>/resourceGroups/<resourceGroupName>/providers/Microsoft.DataFactory/factories/<dataFactoryName>/integrationruntimes/<integrationRuntimeName>Para recuperar o status do Integration Runtime criado, execute o comando a seguir:
Get-AzDataFactoryV2IntegrationRuntime -name $integrationRuntimeName -ResourceGroupName $resourceGroupName -DataFactoryName $dataFactoryName -StatusVeja o exemplo de saída:
State : NeedRegistration Version : CreateTime : 9/10/2019 3:24:09 AM AutoUpdate : On ScheduledUpdateDate : UpdateDelayOffset : LocalTimeZoneOffset : InternalChannelEncryption : Capabilities : {} ServiceUrls : {eu.frontend.clouddatahub.net} Nodes : {} Links : {} Name : <Integration Runtime name> Type : SelfHosted ResourceGroupName : <resourceGroup name> DataFactoryName : <dataFactory name> Description : selfhosted IR description Id : /subscriptions/<subscription ID>/resourceGroups/<resourceGroupName>/providers/Microsoft.DataFactory/factories/<dataFactoryName>/integrationruntimes/<integrationRuntimeName>Para recuperar as chaves de autenticação para registrar o Integration Runtime auto-hospedado com o serviço Data Factory na nuvem, execute o comando a seguir. Copie uma das chaves (excluindo as aspas) para registrar Integration Runtime auto-hospedado instalado em seu computador na próxima etapa.
Get-AzDataFactoryV2IntegrationRuntimeKey -Name $integrationRuntimeName -DataFactoryName $dataFactoryName -ResourceGroupName $resourceGroupName | ConvertTo-JsonVeja o exemplo de saída:
{ "AuthKey1": "IR@0000000000-0000-0000-0000-000000000000@xy0@xy@xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx=", "AuthKey2": "IR@0000000000-0000-0000-0000-000000000000@xy0@xy@yyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyy=" }
Instalar o runtime de integração
Baixe Azure Data Factory Integration Runtime em um computador de Windows local e execute a instalação.
No assistente Bem-vindo ao Assistente de Configuração do Microsoft Integration Runtime, selecione Avançar.
Na janela Contrato de Licença do Usuário Final, aceite os termos e o contrato de licença e selecione Avançar.
No janela Pasta de Destino, selecione Avançar.
Na janela Pronto para instalar o Microsoft Integration Runtime, selecione Instalar.
No assistente Concluir a Configuração do Microsoft Integration Runtime, selecione Concluir.
Na janela Registrar Integration Runtime (auto-hospedado) , cole a chave que você salvou na seção anterior e selecione Registrar.
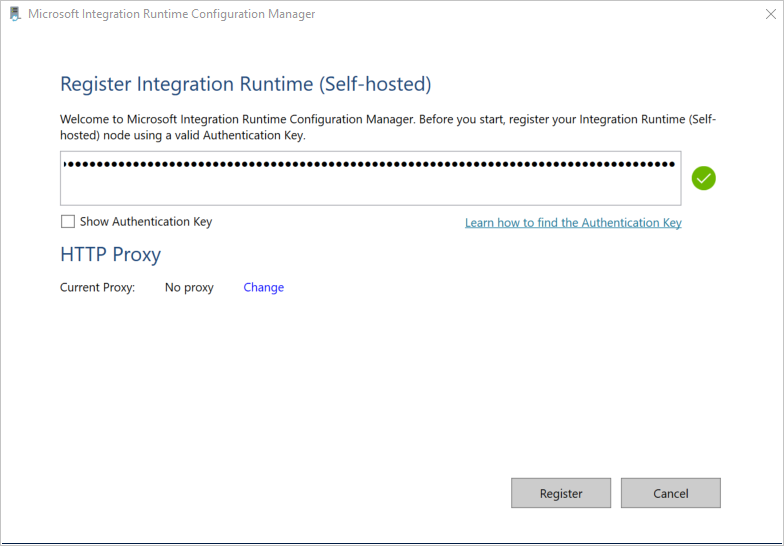
Na janela New Integration Runtime (Self-hosted) Node, selecione Concluir.
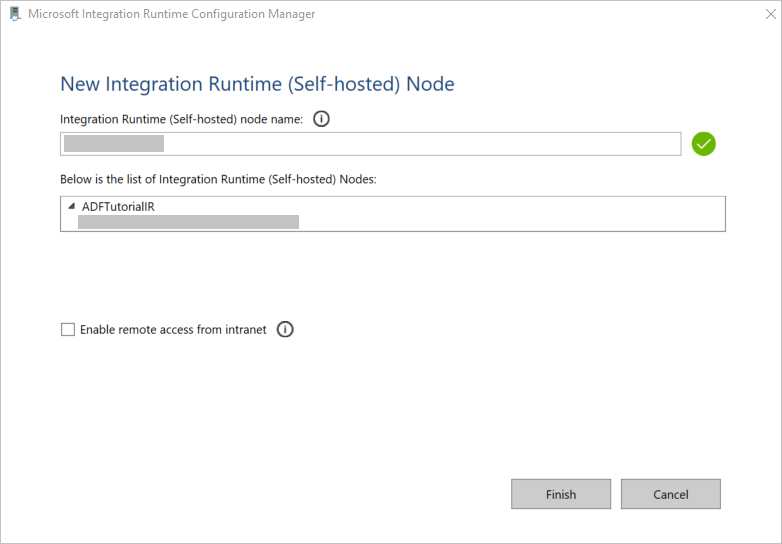
Quando o Integration Runtime auto-hospedado for registrado com êxito, a mensagem a seguir será exibida:

Na janela Registrar Integration Runtime (auto-hospedado) , selecione Iniciar o Gerenciador de Configurações.
Quando o nó estiver conectado ao serviço de nuvem, a mensagem a seguir será exibida:
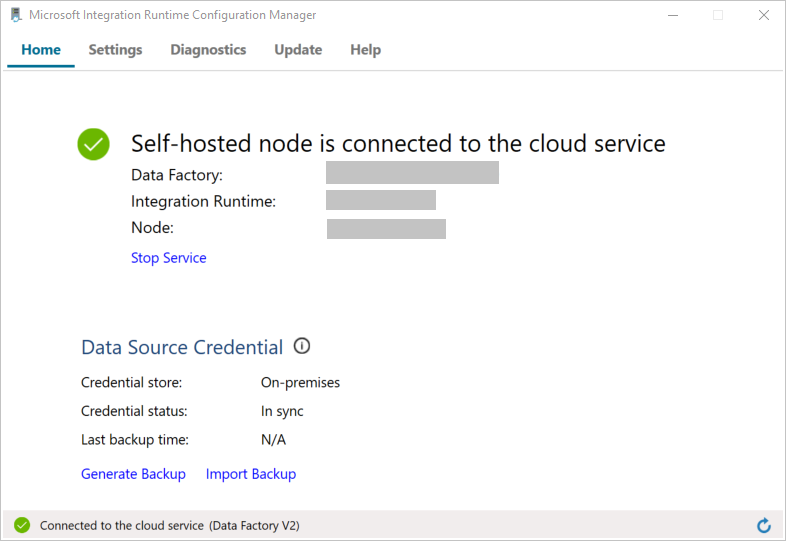
Teste a conectividade com seu banco de dados SQL Server fazendo o seguinte:
a. Na janela Gerenciador de Configurações, alterne para a guia Diagnostics.
b. Na caixa Tipo da fonte de dados, selecione SqlServer.
c. Insira o nome do servidor.
d. Insira o nome do banco de dados.
e. Selecione o modo de autenticação.
f. Insira o nome de usuário.
g. Insira a senha associada ao nome de usuário.
h. Para confirmar se o integration runtime pode se conectar ao SQL Server, selecione Test.

Se a conexão tiver êxito, uma marca de seleção verde será exibida. Caso contrário, você receberá uma mensagem de erro associada à falha. Corrija os problemas e verifique se o runtime de integração pode se conectar à sua instância de SQL Server.
Anote todos os valores anteriores para uso posterior neste tutorial.
Criar serviços vinculados
Para vincular seus armazenamentos de dados e serviços de computação ao data factory, crie serviços vinculados no data factory. Neste tutorial, você vincula sua conta de armazenamento do Azure e à sua instância do SQL Server ao repositório de dados. Os serviços vinculados têm as informações de conexão que o serviço do Data Factory usa no runtime para se conectar a eles.
Criar um serviço vinculado do Armazenamento do Azure (destino/coletor)
Nesta etapa, você vincula sua conta de armazenamento Azure ao data factory.
Crie um arquivo JSON denominado AzureStorageLinkedService.json na pasta C:\ADFv2Tutorial, com o código a seguir. Se a pasta ADFv2Tutorial ainda não existir, crie-a.
Importante
Antes de salvar o arquivo, substitua <accountName> e <accountKey> com o nome e a chave da conta de armazenamento Azure. Você os anotou na seção Pré-requisitos.
{ "name": "AzureStorageLinkedService", "properties": { "annotations": [], "type": "AzureBlobStorage", "typeProperties": { "connectionString": "DefaultEndpointsProtocol=https;AccountName=<accountName>;AccountKey=<accountKey>;EndpointSuffix=core.windows.net" } } }No PowerShell, mude para a pasta C:\ADFv2Tutorial.
Set-Location 'C:\ADFv2Tutorial'Para criar um serviço vinculado, AzureStorageLinkedService, execute o cmdlet
Set-AzDataFactoryV2LinkedServicea seguir:Set-AzDataFactoryV2LinkedService -DataFactoryName $dataFactoryName -ResourceGroupName $ResourceGroupName -Name "AzureStorageLinkedService" -File ".\AzureStorageLinkedService.json"Aqui está uma amostra de saída:
LinkedServiceName : AzureStorageLinkedService ResourceGroupName : <resourceGroup name> DataFactoryName : <dataFactory name> Properties : Microsoft.Azure.Management.DataFactory.Models.AzureBlobStorageLinkedServiceSe você receber um erro "arquivo não encontrado", confirme que o arquivo existe executando o comando
dir. Se o nome do arquivo tiver a extensão .txt (por exemplo, AzureStorageLinkedService.json.txt), remova-a e execute novamente o comando do PowerShell.
Criar e criptografar um serviço vinculado do SQL Server (origem)
Nesta etapa, você vincula sua instância de SQL Server ao data factory.
Crie um arquivo JSON file chamado SqlServerLinkedService.json na pasta C:\ADFv2Tutorial usando o seguinte código:
Importante
Selecione a seção baseada na autenticação que você usa para se conectar ao SQL Server.
Usando a autenticação SQL (sa):
{ "name":"SqlServerLinkedService", "type":"Microsoft.DataFactory/factories/linkedservices", "properties":{ "annotations":[ ], "type":"SqlServer", "typeProperties":{ "connectionString":"integrated security=False;data source=<serverName>;initial catalog=<databaseName>;user id=<userName>;password=<password>" }, "connectVia":{ "referenceName":"<integration runtime name> ", "type":"IntegrationRuntimeReference" } } }Usando autenticação do Windows:
{ "name":"SqlServerLinkedService", "type":"Microsoft.DataFactory/factories/linkedservices", "properties":{ "annotations":[ ], "type":"SqlServer", "typeProperties":{ "connectionString":"integrated security=True;data source=<serverName>;initial catalog=<databaseName>", "userName":"<username> or <domain>\\<username>", "password":{ "type":"SecureString", "value":"<password>" } }, "connectVia":{ "referenceName":"<integration runtime name>", "type":"IntegrationRuntimeReference" } } }Importante
- Selecione a seção baseada na autenticação que você usa para se conectar à sua instância de SQL Server.
- Substitua <integration runtime name> pelo nome do seu runtime de integração.
- Antes de salvar o arquivo, substitua <servername>, <databasename>, <username> e <password> com os valores de sua instância de SQL Server.
- Se precisar usar um caractere de barra invertida (\) na conta de usuário ou no nome do servidor, coloque o caractere de escape (\) antes dele. Por exemplo, use mydomain\\myuser.
Para criptografar os dados confidenciais (nome de usuário, senha e assim por diante), execute o cmdlet
New-AzDataFactoryV2LinkedServiceEncryptedCredential.
Essa criptografia garante que as credenciais sejam criptografadas usando a API de Proteção de Dados (DPAPI). As credenciais criptografadas são armazenadas localmente no nó do ambiente de execução de integração auto-hospedado (computador local). O conteúdo de saída pode ser redirecionado para outro arquivo JSON (nesse caso, encryptedLinkedService.json) que contém credenciais criptografadas.New-AzDataFactoryV2LinkedServiceEncryptedCredential -DataFactoryName $dataFactoryName -ResourceGroupName $ResourceGroupName -IntegrationRuntimeName $integrationRuntimeName -File ".\SQLServerLinkedService.json" > encryptedSQLServerLinkedService.jsonExecute o comando a seguir, o qual cria EncryptedSqlServerLinkedService:
Set-AzDataFactoryV2LinkedService -DataFactoryName $dataFactoryName -ResourceGroupName $ResourceGroupName -Name "EncryptedSqlServerLinkedService" -File ".\encryptedSqlServerLinkedService.json"
Criar conjuntos de dados
Nesta etapa, você cria conjuntos de dados de entrada e saída. Eles representam dados de entrada e saída para a operação de cópia, que copia dados do banco de dados do SQL Server para o Armazenamento de Blobs do Azure.
Criar um conjunto de dados para o banco de dados de SQL Server de origem
Nesta etapa, você define um conjunto de dados que representa dados na instância do banco de dados SQL Server. O conjunto de dados é do tipo SqlServerTable. Ele se refere ao serviço vinculado SQL Server que você criou na etapa anterior. O serviço vinculado tem as informações de conexão que o serviço Data Factory usa para se conectar à sua instância de SQL Server em runtime. Esse conjunto de dados especifica a tabela SQL no banco de dados que contém os dados. Neste tutorial, a tabela emp contém os dados de origem.
Crie um arquivo JSON denominado SqlServerDataset.json na pasta C:\ADFv2Tutorial com o seguinte código:
{ "name":"SqlServerDataset", "properties":{ "linkedServiceName":{ "referenceName":"EncryptedSqlServerLinkedService", "type":"LinkedServiceReference" }, "annotations":[ ], "type":"SqlServerTable", "schema":[ ], "typeProperties":{ "schema":"dbo", "table":"emp" } } }Para criar o conjunto de dados SqlServerDataset, execute o cmdlet
Set-AzDataFactoryV2Dataset.Set-AzDataFactoryV2Dataset -DataFactoryName $dataFactoryName -ResourceGroupName $resourceGroupName -Name "SqlServerDataset" -File ".\SqlServerDataset.json"Veja o exemplo de saída:
DatasetName : SqlServerDataset ResourceGroupName : <resourceGroupName> DataFactoryName : <dataFactoryName> Structure : Properties : Microsoft.Azure.Management.DataFactory.Models.SqlServerTableDataset
Criar um conjunto de dados para o Armazenamento de Blobs do Azure (coletor)
Nesta etapa, você define um conjunto de dados que representa os dados que serão copiados para Azure Armazenamento de Blobs. O conjunto de dados é do tipo AzureBlob. Ele se refere ao serviço vinculado Armazenamento do Azure criado anteriormente neste tutorial.
O serviço vinculado tem as informações de conexão que o Data Factory usa em tempo de execução para se conectar à sua conta de armazenamento do Azure. Esse conjunto de dados especifica a pasta no armazenamento Azure para o qual os dados são copiados do banco de dados SQL Server. Neste tutorial, a pasta é adftutorial/fromonprem, em que adftutorial é o contêiner de blob e fromonprem é a pasta.
Crie um arquivo JSON denominado AzureBlobDataset.json na pasta C:\ADFv2Tutorial com o seguinte código:
{ "name":"AzureBlobDataset", "properties":{ "linkedServiceName":{ "referenceName":"AzureStorageLinkedService", "type":"LinkedServiceReference" }, "annotations":[ ], "type":"DelimitedText", "typeProperties":{ "location":{ "type":"AzureBlobStorageLocation", "folderPath":"fromonprem", "container":"adftutorial" }, "columnDelimiter":",", "escapeChar":"\\", "quoteChar":"\"" }, "schema":[ ] }, "type":"Microsoft.DataFactory/factories/datasets" }Para criar o conjunto de dados AzureBlobDataset, execute o cmdlet
Set-AzDataFactoryV2Dataset.Set-AzDataFactoryV2Dataset -DataFactoryName $dataFactoryName -ResourceGroupName $resourceGroupName -Name "AzureBlobDataset" -File ".\AzureBlobDataset.json"Veja o exemplo de saída:
DatasetName : AzureBlobDataset ResourceGroupName : <resourceGroupName> DataFactoryName : <dataFactoryName> Structure : Properties : Microsoft.Azure.Management.DataFactory.Models.DelimitedTextDataset
Criar um pipeline
Nesta tutorial, você cria um pipeline com uma atividade de cópia. A atividade de cópia usa o SqlServerDataset como o conjunto de dados de entrada e o AzureBlobDataset como o conjunto de dados de saída. O tipo de fonte está definido como SqlSource, e o tipo de coletor está definido como BlobSink.
Crie um arquivo JSON denominado SqlServerToBlobPipeline.json na pasta C:\ADFv2Tutorial com o seguinte código:
{ "name":"SqlServerToBlobPipeline", "properties":{ "activities":[ { "name":"CopySqlServerToAzureBlobActivity", "type":"Copy", "dependsOn":[ ], "policy":{ "timeout":"7.00:00:00", "retry":0, "retryIntervalInSeconds":30, "secureOutput":false, "secureInput":false }, "userProperties":[ ], "typeProperties":{ "source":{ "type":"SqlServerSource" }, "sink":{ "type":"DelimitedTextSink", "storeSettings":{ "type":"AzureBlobStorageWriteSettings" }, "formatSettings":{ "type":"DelimitedTextWriteSettings", "quoteAllText":true, "fileExtension":".txt" } }, "enableStaging":false }, "inputs":[ { "referenceName":"SqlServerDataset", "type":"DatasetReference" } ], "outputs":[ { "referenceName":"AzureBlobDataset", "type":"DatasetReference" } ] } ], "annotations":[ ] } }Para criar o pipeline SQLServerToBlobPipeline, execute o cmdlet
Set-AzDataFactoryV2Pipeline.Set-AzDataFactoryV2Pipeline -DataFactoryName $dataFactoryName -ResourceGroupName $resourceGroupName -Name "SQLServerToBlobPipeline" -File ".\SQLServerToBlobPipeline.json"Veja o exemplo de saída:
PipelineName : SQLServerToBlobPipeline ResourceGroupName : <resourceGroupName> DataFactoryName : <dataFactoryName> Activities : {CopySqlServerToAzureBlobActivity} Parameters :
Criar uma execução de pipeline
Inicie a execução de um pipeline para o pipeline SQLServerToBlobPipeline e capture a ID da execução de pipeline para monitoramento futuro.
$runId = Invoke-AzDataFactoryV2Pipeline -DataFactoryName $dataFactoryName -ResourceGroupName $resourceGroupName -PipelineName 'SQLServerToBlobPipeline'
Monitorar a execução de pipeline
Para verificar continuamente o status de execução do pipeline SQLServerToBlobPipeline, execute o script a seguir no PowerShell e imprima o resultado final:
while ($True) { $result = Get-AzDataFactoryV2ActivityRun -DataFactoryName $dataFactoryName -ResourceGroupName $resourceGroupName -PipelineRunId $runId -RunStartedAfter (Get-Date).AddMinutes(-30) -RunStartedBefore (Get-Date).AddMinutes(30) if (($result | Where-Object { $_.Status -eq "InProgress" } | Measure-Object).count -ne 0) { Write-Host "Pipeline run status: In Progress" -foregroundcolor "Yellow" Start-Sleep -Seconds 30 } else { Write-Host "Pipeline 'SQLServerToBlobPipeline' run finished. Result:" -foregroundcolor "Yellow" $result break } }Aqui está a saída da execução de exemplo:
ResourceGroupName : <resourceGroupName> DataFactoryName : <dataFactoryName> ActivityRunId : 24af7cf6-efca-4a95-931d-067c5c921c25 ActivityName : CopySqlServerToAzureBlobActivity ActivityType : Copy PipelineRunId : 7b538846-fd4e-409c-99ef-2475329f5729 PipelineName : SQLServerToBlobPipeline Input : {source, sink, enableStaging} Output : {dataRead, dataWritten, filesWritten, sourcePeakConnections...} LinkedServiceName : ActivityRunStart : 9/11/2019 7:10:37 AM ActivityRunEnd : 9/11/2019 7:10:58 AM DurationInMs : 21094 Status : Succeeded Error : {errorCode, message, failureType, target} AdditionalProperties : {[retryAttempt, ], [iterationHash, ], [userProperties, {}], [recoveryStatus, None]...}Você pode obter o ID de execução do pipeline SQLServerToBlobPipeline e verificar o resultado detalhado da execução de atividade executando o seguinte comando:
Write-Host "Pipeline 'SQLServerToBlobPipeline' run result:" -foregroundcolor "Yellow" ($result | Where-Object {$_.ActivityName -eq "CopySqlServerToAzureBlobActivity"}).Output.ToString()Aqui está a saída da execução de exemplo:
{ "dataRead":36, "dataWritten":32, "filesWritten":1, "sourcePeakConnections":1, "sinkPeakConnections":1, "rowsRead":2, "rowsCopied":2, "copyDuration":18, "throughput":0.01, "errors":[ ], "effectiveIntegrationRuntime":"ADFTutorialIR", "usedParallelCopies":1, "executionDetails":[ { "source":{ "type":"SqlServer" }, "sink":{ "type":"AzureBlobStorage", "region":"CentralUS" }, "status":"Succeeded", "start":"2019-09-11T07:10:38.2342905Z", "duration":18, "usedParallelCopies":1, "detailedDurations":{ "queuingDuration":6, "timeToFirstByte":0, "transferDuration":5 } } ] }
Verificar a saída
O pipeline cria automaticamente a pasta de saída chamada fromonprem no container de blobs adftutorial. Confirme que você vê o arquivo dbo.emp.txt na pasta de saída.
No portal Azure, na janela de contêiner adftutorial, selecione Refresh para ver a pasta de saída.
Selecione
fromonpremna lista de pastas.Confirme que você vê um arquivo com o nome
dbo.emp.txt.
Conteúdo relacionado
O pipeline neste exemplo copia dados de um local para outro no armazenamento Blob do Azure. Você aprendeu a:
- Criar uma fábrica de dados.
- Criar um runtime de integração auto-hospedada.
- Crie serviços vinculados SQL Server e Armazenamento do Azure.
- Crie conjuntos de dados de Blob SQL Server e Azure.
- Criar um pipeline com uma atividade de cópia para mover os dados.
- Iniciar uma execução de pipeline.
- Monitorar a execução de pipeline.
Para obter uma lista dos armazenamentos de dados com suporte pelo Data Factory, consulte armazenamentos de dados com suporte.
Para saber mais sobre copiar dados em massa de uma origem para um destino, avance para o tutorial a seguir: