Observação
O acesso a essa página exige autorização. Você pode tentar entrar ou alterar diretórios.
O acesso a essa página exige autorização. Você pode tentar alterar os diretórios.
APLICA-SE A: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Dica
Data Factory no Microsoft Fabric é a próxima geração de Azure Data Factory, com uma arquitetura mais simples, IA interna e novos recursos. Se você não estiver familiarizado com a integração de dados, comece com Fabric Data Factory. As cargas de trabalho existentes do ADF podem ser atualizadas para Fabric para acessar novos recursos em ciência de dados, análise em tempo real e relatórios.
Neste tutorial, você usará o portal Azure para criar um data factory. Em seguida, você usa a ferramenta Copiar Dados para criar um pipeline que copia dados de um banco de dados SQL Server para o Armazenamento de Blobs do Azure.
Observação
- Se você não estiver familiarizado com Azure Data Factory, consulte Introduction to Data Factory.
Neste tutorial, você executa as seguintes etapas:
- Criar uma fábrica de dados.
- Usar a ferramenta Copy Data para criar um pipeline.
- Monitore as execuções de pipeline e de atividade.
Pré-requisitos
assinatura do Azure
Antes de começar, se você ainda não tiver uma assinatura Azure, criar uma conta gratuita.
Azure funções
Para criar instâncias de data factory, a conta de usuário usada para fazer logon no Azure deve ter uma função Colaborador ou Proprietário atribuída ou deve ser um administrador da assinatura do Azure.
Para exibir as permissões que você tem na assinatura, acesse o portal do Azure. Selecione seu nome de usuário no canto superior direito, depois selecione Permissões. Se tiver acesso a várias assinaturas, selecione a que for adequada. Para obter instruções de exemplo sobre como adicionar um usuário a uma função, consulte Assign Azure funções usando o portal Azure.
SQL Server 2014, 2016 e 2017
Neste tutorial, você usará um banco de dados SQL Server como um armazenamento de dados source. O pipeline no data factory criado neste tutorial copia dados desse banco de dados do SQL Server (origem) para um Armazenamento de Blobs (coletor). Em seguida, crie uma tabela chamada emp em seu banco de dados SQL Server e insira algumas entradas de exemplo na tabela.
Inicie SQL Server Management Studio. Se ainda não estiver instalado no computador, vá para Download SQL Server Management Studio.
Conecte-se à sua instância de SQL Server usando suas credenciais.
Crie um banco de dados de exemplo. No modo de exibição de árvore, clique com o botão direito do mouse em Bancos de Dados e selecione Novo Banco de Dados.
Na janela Novo Banco de Dados, digite um nome para o banco de dados e selecione OK.
Para criar a tabela emp e inserir alguns dados de exemplo nela, execute o seguinte script de consulta no banco de dados. No modo de exibição de árvore, clique com o botão direito do mouse no banco de dados que você criou e selecione Nova Consulta.
CREATE TABLE dbo.emp ( ID int IDENTITY(1,1) NOT NULL, FirstName varchar(50), LastName varchar(50) ) GO INSERT INTO emp (FirstName, LastName) VALUES ('John', 'Doe') INSERT INTO emp (FirstName, LastName) VALUES ('Jane', 'Doe') GO
conta de armazenamento do Azure
Neste tutorial, você usa uma conta de armazenamento do Azure para fins gerais (especificamente o Armazenamento de blobs) como armazenamento de dados de destino/coletor. Se você não tiver uma conta de armazenamento de fins gerais, confira Criar uma conta de armazenamento para obter instruções sobre como criar uma. O pipeline no data factory criado neste tutorial copia dados desse banco de dados do SQL Server (origem) para esse Armazenamento de Blobs (coletor).
Obter o nome da conta de armazenamento e a chave da conta
Use o nome e a chave da sua conta de armazenamento neste tutorial. Para obter o nome e a chave da sua conta de armazenamento, realize as etapas a seguir:
Entre no portal Azure com seu nome de usuário Azure e senha.
No painel esquerdo, selecione Todos os serviços. Filtre usando a palavra-chave Armazenamento e selecione Contas de armazenamento.

Na lista de contas de armazenamento, filtre pela sua conta de armazenamento, se necessário. Em seguida, selecione sua conta de armazenamento.
Na janela Conta de armazenamento, selecione Chaves de acesso.
Nas caixas Nome da conta de armazenamento e key1, copie os valores e depois cole-os no Bloco de Notas ou outro editor para uso posterior neste tutorial.
Criar uma fábrica de dados
No menu superior, selecione Criar um recurso>Analytics>Data Factory:

Na página Novo Fábrica de Dados, em Nome, insira ADFTutorialDataFactory.
O nome do data factory deve ser único globalmente. Se a seguinte mensagem de erro for exibida para o campo nome, altere o nome do data factory (por exemplo, yournameADFTutorialDataFactory). Para ver as regras de nomenclatura para artefatos do Data Factory, confira Data Factory – Regras de nomenclatura.

Selecione a assinatura do Azure na qual você deseja criar a fábrica de dados.
Em Grupo de Recursos, use uma das seguintes etapas:
Selecione Usar existente e selecione um grupo de recursos existente na lista suspensa.
Selecione Criar novoe insira o nome de um grupo de recursos.
Para saber mais sobre grupos de recursos, consulte Use grupos de recursos para gerenciar seus recursos Azure.
Em Versão, selecione V2.
Em Local, selecione a localização para a fábrica de dados. Apenas os locais com suporte são exibidos na lista suspensa. Os armazenamentos de dados (por exemplo, banco de dados Armazenamento do Azure e SQL) e cálculos (por exemplo, Azure HDInsight) usados pelo Data Factory podem estar em outros locais/regiões.
Selecione Criar.
Depois de finalizada a criação, a página Data Factory será exibida conforme mostrado na imagem.

Selecione Open no bloco Open Azure Data Factory Studio para iniciar a interface do usuário do Data Factory em uma guia separada.
Usar a ferramenta Copy Data para criar um pipeline
Na home page Azure Data Factory, selecione Ingest para iniciar a ferramenta Copiar Dados.

Na página Propriedades da ferramenta Copiar dados, escolha Tarefa de cópia interna em Tipo de tarefa e Executar uma vez agora em Cadência da tarefa ou agendamento da tarefa e selecione Avançar.
Na página Armazenamento de dados de origem, selecione + Criar conexão.
Em Novo conexão, pesquise SQL Server e selecione Continue.
Na caixa de diálogo Nova conexão (SQL Server) , em Nome, insira SqlServerLinkedService. Selecione +Novo em Conectar por meio do runtime de integração. Você deve criar um runtime de integração auto-hospedada, baixá-lo para seu computador e registrá-lo com o Data Factory. O runtime de integração auto-hospedada copia dados entre seu ambiente local e a nuvem.
Na caixa de diálogo Instalação do Integration Runtime, selecione Auto-hospedado. Depois selecione Continuar.
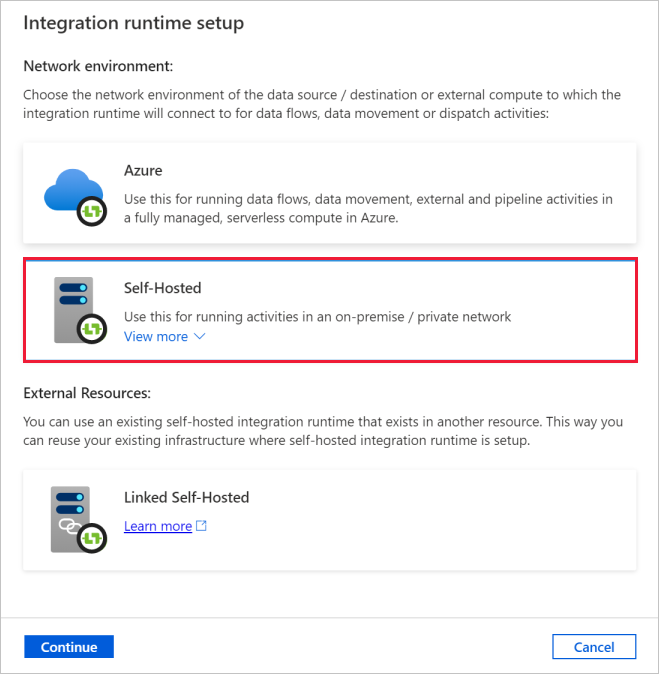
Na caixa de diálogo Instalação do runtime de integração, em Nome, insira TutorialIntegrationRuntime. Em seguida, selecione Criar.
Na caixa de diálogo Instalação do runtime de integração, selecione Clique aqui para iniciar a instalação expressa para este computador. Essa ação instala o Integration Runtime em seu computador e o registra com o Data Factory. Como alternativa, você pode usar a opção de baixar o arquivo de instalação manual, executá-lo e usar a chave para registrar o runtime de integração.
Execute o aplicativo baixado. Você verá o status da instalação rápida na janela.

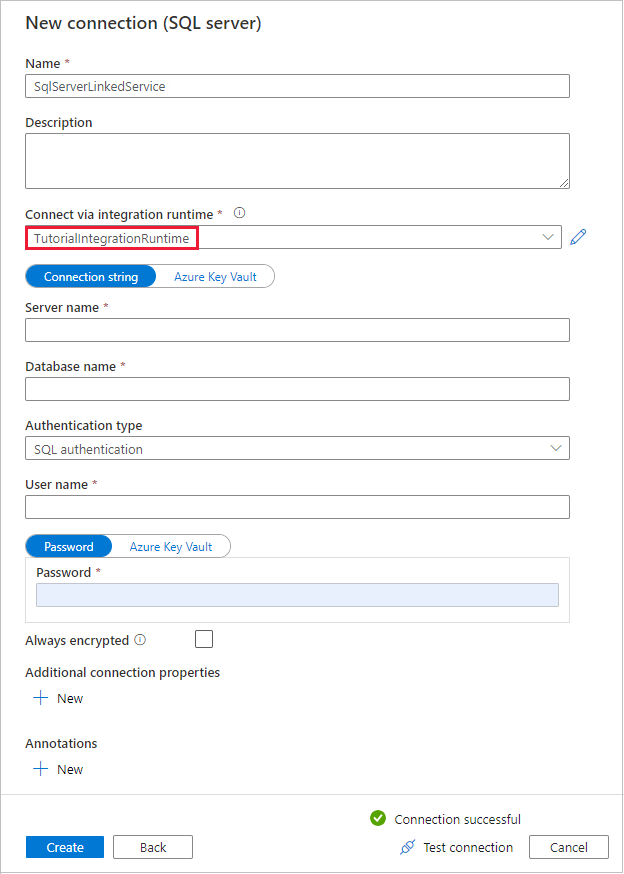
Na caixa de diálogo New Connection (SQL Server), confirme se TutorialIntegrationRuntime está selecionado em Connect via integration runtime. Em seguida, execute as etapas a seguir:
um. Em Nome, digite SqlServerLinkedService.
b. Em Server name, insira o nome da instância SQL Server.
c. Em Nome do banco de dados, insira o nome do seu banco de dados local.
d. Em Tipo de autenticação, selecione a autenticação adequada.
e. Em User name, insira o nome do usuário com acesso ao SQL Server.
f. Insira a senha do usuário.
g. Teste a conectividade e selecione Criar.
Na página Source data store, verifique se a conexão SQL Server recém-criada está selecionada no bloco Connection. Em seguida, na seção Tabelas de origem, escolha TABELAS EXISTENTES e selecione a tabela dbo.emp na lista e Avançar. Você pode selecionar qualquer outra tabela com base em seu banco de dados.
Na página Aplicar filtro, visualize os dados e veja o esquema dos dados de entrada selecionando o botão Visualizar dados. Em seguida, selecione Avançar.
Na página Armazenamento de dados de destino, selecione + Criar conexão
Em A nova conexão, pesquise e selecione Armazenamento de Blobs do Azure e selecione Continue.

Na caixa de diálogo New connection (Armazenamento de Blobs do Azure), execute as seguintes etapas:
um. Em Nome, insira AzureStorageLinkedService.
b. Em Conectar por meio do runtime de integração, selecione TutorialIntegrationRuntime e escolha Chave de conta em Método de autenticação.
c. Em Assinatura do Azure, selecione sua assinatura do Azure na lista suspensa.
d. Em Nome da conta de armazenamento, selecione sua conta de armazenamento na lista suspensa.
e. Teste a conectividade e selecione Criar.
Na caixa de diálogo Destination data store, verifique se a conexão Armazenamento de Blobs do Azure recém-criada está selecionada no bloco Connection. Em Caminho da pasta, insira adftutorial/fromonprem. Você criou o contêiner adftutorial como parte dos pré-requisitos. Se a pasta de saída não existir (neste caso fromonprem), o Data Factory a cria automaticamente. Também é possível usar o botão Explorar para explorar o armazenamento de blobs e seus contêineres/pastas. Se você não especificar nenhum valor em Nome de arquivo, por padrão o nome da fonte será usado (neste caso dbo.emp).

Na caixa de diálogo Configurações de formato de arquivo, selecione Avançar.
Na caixa de diálogo Configurações, em Nome da tarefa, insira CopyFromOnPremSqlToAzureBlobPipeline e selecione Avançar. A ferramenta Copy Data cria um pipeline com o nome especificado para este campo.
Na caixa de diálogo Resumo, revise os valores para todas as configurações e selecione Avançar.
Na página Implantação, selecione Monitorar para monitorar o pipeline (tarefa).
Quando a execução do pipeline for concluída, você pode visualizar o status do pipeline que você criou.
Na página "Execuções de pipeline", selecione Atualizar para atualizar a lista. Selecione o link em Nome do pipeline para ver os detalhes da execução de atividade ou execute o pipeline novamente.

Na página "Execuções de atividade", selecione o link Detalhes (ícone de óculos) na coluna Nome da atividade para obter mais detalhes sobre a operação de cópia. Para voltar à página "Execuções de pipeline", selecione o link Todas as execuções de pipeline no menu de navegação estrutural. Para atualizar a exibição, selecione Atualizar.

Confira se existe o arquivo de saída na pasta fromonprem do contêiner adftutorial.
Selecione a guia Criar à esquerda para alternar para o modo de edição. É possível atualizar serviços vinculados, conjuntos de dados e pipelines criados pela ferramenta usando o editor. Selecione Código para exibir o código JSON associado à entidade aberta no editor. Para obter detalhes sobre como editar essas entidades na interface do usuário do Data Factory, consulte a versão do portal Azure deste tutorial.

Conteúdo relacionado
O pipeline neste caso copia dados de um banco de dados SQL Server para o armazenamento de blobs. Você aprendeu a:
- Criar uma fábrica de dados.
- Usar a ferramenta Copy Data para criar um pipeline.
- Monitore as execuções de pipeline e de atividade.
Para obter uma lista dos armazenamentos de dados com suporte do Data Factory, confira Armazenamentos de dados com suporte.
Para saber mais sobre como copiar dados em massa de uma origem para um destino, avance para o tutorial a seguir: