Observação
O acesso a essa página exige autorização. Você pode tentar entrar ou alterar diretórios.
O acesso a essa página exige autorização. Você pode tentar alterar os diretórios.
Fazer com que cada serviço decida quando e como processar uma operação de negócios, em vez de depender de um orquestrador central. Essa abordagem descentraliza a lógica do fluxo de trabalho e distribui responsabilidades entre os componentes de um sistema.
Contexto e problema
Normalmente, você divide um aplicativo baseado em nuvem em vários pequenos serviços que trabalham juntos para processar uma transação comercial de ponta a ponta. Uma única operação dentro de uma transação pode resultar em várias chamadas ponto a ponto entre todos os serviços. O ideal é que esses serviços sejam fracamente acoplados. É desafiador criar um fluxo de trabalho distribuído, eficiente e escalonável porque envolve comunicação intersserviço complexa.
Um padrão comum para comunicação é usar um serviço centralizado ou um orquestrador. As solicitações recebidas fluem por meio do orquestrador à medida que ele delega as operações aos respectivos serviços. Cada um dos serviços conclui sua função e não está ciente do fluxo de trabalho geral.

Normalmente, você implementa o padrão de orquestração como um software feito sob medida, possuindo conhecimento de domínio sobre as responsabilidades dos serviços dentro do sistema. Um benefício dessa abordagem é que o orquestrador pode consolidar o status de uma transação com base nos resultados de operações individuais que os serviços downstream realizam.
Essa abordagem também cria alguns obstáculos. Adicionar ou remover serviços pode quebrar a lógica existente, pois você precisa reconectar partes do caminho de comunicação. Essa dependência torna a implementação do orchestrator complexa e difícil de manter. O orquestrador pode afetar negativamente a confiabilidade da carga de trabalho. Sob carga, ele pode introduzir gargalos de desempenho e ser o único ponto de falha (SPoF). Ele também pode causar falhas em cascata nos serviços downstream.
Solução
Delegar a lógica de manipulação de transações entre os serviços. Permitir que cada serviço participe do fluxo de trabalho de comunicação de uma operação de negócios e decida quando e como processá-la.
O padrão coreográfico minimiza a dependência de software personalizado que centraliza o fluxo de trabalho de comunicação. Os componentes implementam uma lógica comum enquanto coreografam o fluxo de trabalho entre si sem se comunicarem diretamente entre si.
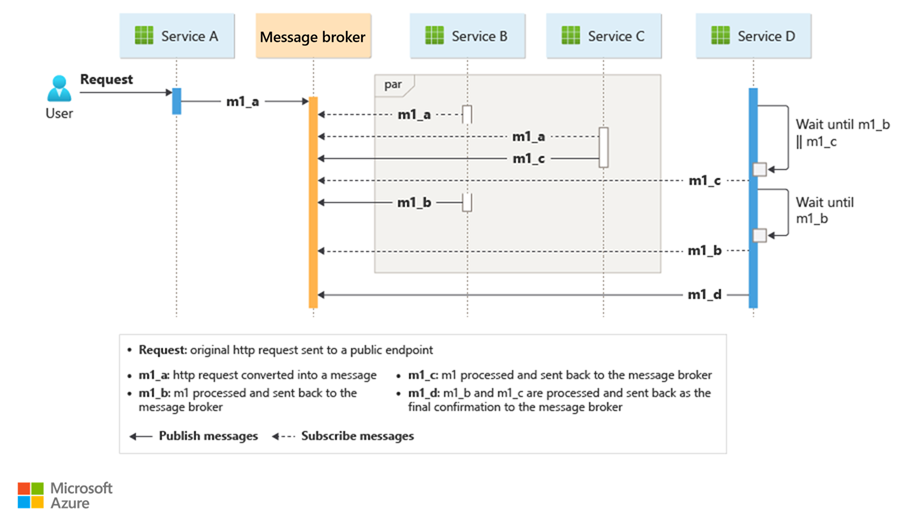
Uma maneira comum de implementar uma coreografia é usar um agente de mensagens que armazena solicitações em buffer até que os componentes downstream as reivindiquem e as processem. A imagem a seguir mostra o tratamento de solicitações por meio de um modelo de editor-assinante.

As solicitações do cliente são enfileiradas como mensagens em um broker de mensagens.
O serviço ou o assinante consulta o broker para determinar se este pode processar essa mensagem com base em sua lógica de negócios implementada. O agente também pode enviar mensagens por push para assinantes interessados nessa mensagem.
Cada serviço assinado faz sua operação conforme a mensagem indica e responde ao agente com uma mensagem de êxito ou falha da operação.
Se a operação for bem-sucedida, o serviço poderá enviar uma mensagem de volta para a mesma fila ou uma fila de mensagens diferente para que outro serviço possa continuar o fluxo de trabalho, se necessário. Se a operação falhar, o agente de mensagens trabalhará com outros serviços para compensar a operação ou toda a transação.
Problemas e considerações
Considere os seguintes pontos ao decidir como implementar esse padrão:
Lidar com falhas pode ser desafiador. Componentes em um aplicativo podem gerenciar tarefas atômicas e depender de outras partes do sistema. A falha em um componente pode afetar outros componentes, o que pode causar atrasos na conclusão da solicitação geral.
Para lidar com falhas normalmente, você implementa a lógica de tratamento de falhas, que introduz complexidade. A lógica de tratamento de falhas, como a compensação de transações, também é propensa a falhas.
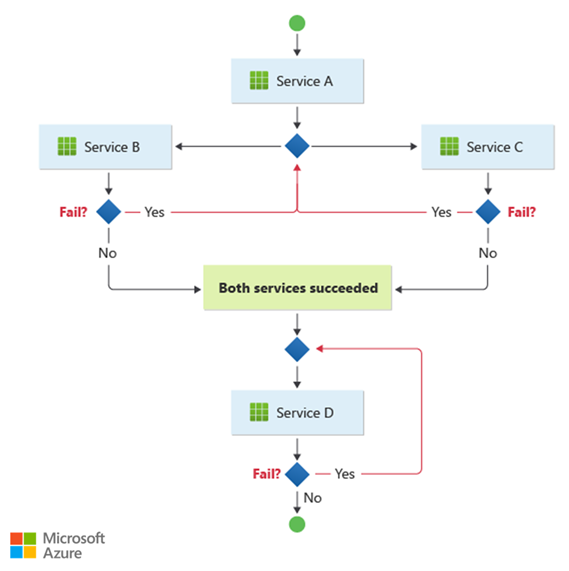
Esse padrão atende a um fluxo de trabalho que processa operações comerciais independentes em paralelo. O fluxo de trabalho pode se tornar complicado quando a coreografia precisa ocorrer em uma sequência. Por exemplo, o Serviço D só pode iniciar sua operação depois que o Serviço B e o Serviço C concluirem suas operações com êxito.
Esse padrão apresentará desafios se o número de serviços aumentar rapidamente. Muitas partes móveis independentes complicam o fluxo de trabalho entre os serviços. Você deve usar consistentemente identificadores de rastreamento distribuído e correlação para manter a observabilidade.
Em um design liderado por um orquestrador, o componente central pode delegar atribuições de resiliência, como o tratamento de tentativas de repetição para falhas transitórias, não transitórias e de tempo limite, a um manipulador de resiliência dedicado.
Quando você remove o orquestrador em um design baseado em coreografia, os componentes downstream não assumem responsabilidades de resiliência. Eles permanecem centralizados no gerenciador de resiliência. Mas os componentes downstream devem se comunicar diretamente com esse manipulador, o que aumenta a comunicação ponto a ponto.
A evolução do esquema de eventos pode causar alterações significativas nos consumidores ao longo do tempo. Nesse padrão, vários serviços independentes consomem os mesmos eventos. Se um produtor alterar a estrutura de dados de um evento, isso pode causar problemas para os consumidores posteriores que dependem do esquema antigo. Use um registro de esquema para gerenciar contratos de eventos e utilizar a evolução compatível com versões anteriores à medida que os serviços evoluem de forma independente.
A ordenação de eventos não é garantida em novas tentativas ou expansão. Projete para idempotência e reemita mensagens em sequência para gerenciar eventos duplicados ou fora de ordem.
Topologias de eventos descentralizadas podem criar comportamentos emergentes em escala. Quando muitos serviços reagem aos eventos uns dos outros, o sistema pode acidentalmente produzir loops de feedback ou tempestades de eventos. Um evento menor pode desencadear uma cascata de reações downstream. Para evitar cadeias de eventos circulares, use diretrizes como filtragem de eventos, limites de simultaneidade do consumidor, controle de taxa e regras explícitas.


Quando usar esse padrão
Use esse padrão quando:
Os componentes downstream lidam com operações atômicas de forma independente. Pense nesse padrão como um mecanismo fire and forget , no qual um componente faz uma tarefa que não precisa de gerenciamento ativo. Quando a tarefa é concluída, o componente envia uma notificação para os outros componentes.
Você espera atualizar e substituir os componentes com frequência. Esse padrão permite modificar o aplicativo com menos esforço e interrupção mínima para os serviços existentes.
Você usa arquiteturas sem servidor para fluxos de trabalho simples. Os componentes podem ser de curta duração e orientados a eventos. Quando ocorre um evento, o serviço cria componentes que fazem uma tarefa e o serviço remove os componentes após a conclusão dessa tarefa.
A comunicação entre contextos limitados requer acoplamento flexível entre limites de domínio. Para comunicação dentro de um único contexto delimitado, aplique um padrão de orquestração.
O orquestrador central introduz um gargalo de desempenho.
O padrão pode não ser adequado nestes casos:
O aplicativo é complexo e requer um componente central para lidar com a lógica compartilhada de modo a manter os componentes downstream leves.
A comunicação ponto a ponto entre os componentes é inevitável.
Você precisa usar a lógica de negócios para consolidar todas as operações que os componentes downstream manipulam.
Design de carga de trabalho
Avalie como usar o padrão de Coreografia no design de uma carga de trabalho para atender as metas e os princípios abordados nos pilares do Azure Well-Architected Framework. A tabela a seguir fornece diretrizes sobre como esse padrão dá suporte às metas de cada pilar.
| Pilar | Como esse padrão apoia os objetivos do pilar |
|---|---|
| A Excelência Operacional ajuda a fornecer qualidade da carga de trabalho por meio de processos padronizados e coesão de equipe. | Os componentes distribuídos nesse padrão são autônomos e projetados para serem substituíveis, para que você possa modificar a carga de trabalho com menos alterações gerais no sistema. - OE:04 Ferramentas e processos |
| A Eficiência de Desempenho ajuda sua carga de trabalho a atender com eficiência às demandas por meio de otimizações no dimensionamento, nos dados e no código. | Esse padrão fornece uma alternativa quando ocorrem gargalos de desempenho em uma topologia de orquestração centralizada. - PE:02 Planejamento de capacidade - PE:05 Dimensionamento e particionamento |
Se esse padrão introduzir compensações dentro de um pilar, considere-as em relação aos objetivos dos outros pilares.
Exemplo
Este exemplo mostra o padrão coreografado criando uma carga de trabalho nativa de nuvem controlada por eventos que executa funções junto com microsserviços. Quando um cliente solicita o envio de um pacote, a carga de trabalho atribui um drone. Depois que o pacote estiver pronto para retirada pelo drone agendado, o processo de entrega será iniciado. Enquanto o pacote está em trânsito, o sistema de logística gerencia a entrega até que receba o status de enviado.

O serviço de ingestão recebe solicitações do cliente e as converte em mensagens que incluem os detalhes de entrega. As transações comerciais começam depois que os serviços consomem essas novas mensagens.
Uma única transação comercial de cliente requer três operações comerciais distintas:
Criar ou atualizar um pacote.
Atribua um drone para entregar o pacote.
Gerencie a entrega, incluindo verificar e enviar uma notificação quando o pacote for enviado.
Os microsserviços de pacote, agendador de drone e entrega executam o processamento de negócios. Os serviços usam mensagens em vez de um orquestrador central para se comunicarem entre si. Cada serviço deve implementar um protocolo com antecedência que coordene o fluxo de trabalho de negócios de forma descentralizada.
Projeto
Os serviços processam transações comerciais em uma sequência por meio de vários saltos. Cada passo compartilha um único barramento de mensagens entre todos os serviços comerciais.
Quando um cliente envia uma solicitação de entrega por meio de um ponto de extremidade HTTP, o serviço de ingestão a recebe, converte-a em uma mensagem e, em seguida, publica a mensagem no barramento de mensagens compartilhado. Os serviços empresariais assinados consomem novas mensagens adicionadas ao ônibus. Quando um serviço empresarial recebe a mensagem, ele conclui a operação com êxito, a solicitação falha ou expira. Se a solicitação for bem-sucedida, o serviço responde ao barramento com o código de status Ok, gera uma nova mensagem de operação e a envia para o barramento de mensagens. Se a solicitação falhar ou atingir o tempo limite, o serviço relatará a falha enviando o código de motivo para o barramento de mensagens e, em seguida, adicionará a mensagem a uma fila de mensagens mortas (DLQ). O serviço também move mensagens que ele não pode receber ou processar dentro de um período específico para o DLQ.
Esse design usa vários barramentos de mensagens para processar toda a transação comercial. O Barramento de Serviço do Azure e a Grade de Eventos do Azure fornecem a plataforma de serviço de mensagens para esse design. A carga de trabalho é executada nos Aplicativos de Contêiner do Azure, que hospeda o Azure Functions para ingestão. Os Aplicativos de Contêiner lidam com o processamento orientado a eventos que executa a lógica de negócios.
Esse design também garante que a coreografia ocorra em uma sequência. Um único namespace do Barramento de Serviço contém um tópico que tem duas assinaturas e uma fila preparada para sessões. O serviço de ingestão publica mensagens no tópico. O serviço de entrega de pacotes e o serviço de agendador de drones assinam o tópico e publicam mensagens que notificam a fila sobre as solicitações bem-sucedidas. Inclua um identificador de sessão comum que associa um GUID ao identificador de entrega para que os serviços possam lidar com sequências ilimitadas de mensagens relacionadas de forma ordenada. O serviço de entrega aguarda duas mensagens relacionadas para cada transação. A primeira mensagem indica que o pacote está pronto para ser enviado e a segunda mensagem sinaliza que um drone está agendado.
Nesse projeto, o Barramento de Serviço gerencia mensagens de alto valor que não devem ser perdidas ou duplicadas ao longo de todo o processo de entrega. Quando o pacote é enviado, uma alteração de estado é publicada no Event Grid. O remetente de eventos não tem nenhuma expectativa sobre como a alteração de estado é tratada. Os serviços de organização downstream que esse design não inclui podem escutar esse tipo de evento e executar uma lógica de negócios específica, como enviar um email de status de pedido para o usuário.
Se você implantar esse padrão em outro serviço de computação, como o AKS, poderá implementar o modelo de aplicativo Publisher-Subscriber com dois contêineres no mesmo pod. Um contêiner executa o embaixador que interage com o barramento de mensagens escolhido enquanto o outro contêiner executa a lógica de negócios. Essa abordagem melhora o desempenho e a escalabilidade. O embaixador e o serviço de negócios compartilham a mesma rede, o que reduz a latência e aumenta a taxa de transferência.
Para evitar operações de repetição em cascata que possam levar a várias tentativas, os serviços empresariais devem sinalizar imediatamente mensagens inaceitáveis. Enriqueça essas mensagens usando códigos de motivos comuns ou um código de aplicativo definido para que os serviços possam movê-las para um DLQ. Considere implementar o padrão saga para gerenciar problemas de consistência de serviços downstream. Por exemplo, outro serviço manipula mensagens de mensagens mortas para fins de correção apenas executando uma compensação, repetição ou transação dinâmica.
Os serviços empresariais são idempotentes para garantir que as operações de repetição não criem recursos duplicados. Por exemplo, o serviço de pacote usa operações upsert para adicionar dados ao armazenamento de dados.
Próximas Etapas
Centralize o gerenciamento de esquema de eventos usando o registro de esquema nos Hubs de Eventos do Azure para manter a compatibilidade à medida que seus serviços evoluem.
Examine as opções de mensagens assíncronas no Azure para saber mais sobre as diferentes opções de infraestrutura disponíveis para implementar um fluxo de trabalho descentralizado.
Avalie os recursos técnicos de diferentes plataformas para escolher o serviço de mensagens do Azure correto para seus requisitos de coreografia específicos.
Recursos relacionados
Considere esses padrões em seu design para coreografia:
Modularizar o serviço de negócios usando o padrão Embaixador.
Implemente o padrão de Nivelamento de Carga Baseado em Fila para lidar com picos de carga de trabalho.
Use mensagens distribuídas assíncronas por meio do padrãoPublisher-Subscriber.
Use transações de compensação para desfazer várias operações bem-sucedidas se uma ou mais operações relacionadas falharem.