Observação
O acesso a essa página exige autorização. Você pode tentar entrar ou alterar diretórios.
O acesso a essa página exige autorização. Você pode tentar alterar os diretórios.
O processamento de linguagem natural abrange técnicas que analisam, entendem e geram linguagem humana a partir de dados de texto. Azure fornece serviços gerenciados controlados por API e estruturas de software livre distribuídas que abordam cargas de trabalho de processamento de linguagem natural que vão desde análise de sentimento e reconhecimento de entidade até classificação de documentos e resumo de texto. Este guia ajuda você a avaliar e escolher entre as principais opções de processamento de linguagem natural em Azure para que você possa corresponder a tecnologia certa aos requisitos de carga de trabalho.
Observação
Este guia se concentra nos recursos de processamento de linguagem natural disponíveis por meio de Azure Language e Apache Spark com o Spark NLP no Azure Databricks ou Microsoft Fabric. Ele não fornece diretrizes sobre como selecionar modelos de idioma ou projetar Azure soluções OpenAI. Algumas descrições de plataforma podem referenciar integrações de modelo de fundação ou modelo de fala com suporte como detalhes de implementação, mas este guia se concentra na seleção do serviço de processamento de linguagem natural. Para obter mais informações, consulte Escolher uma tecnologia de serviços de IA.
Entender o processamento de linguagem natural e os modelos de linguagem
Antes de avaliar Azure serviços, entenda o que é o processamento de linguagem natural, como ele difere dos modelos de linguagem e quais tarefas ele aborda.
Distinguir o processamento de linguagem natural de modelos de linguagem
Esta seção esclarece o limite entre o processamento de linguagem natural e os modelos de linguagem e examina os principais recursos que as técnicas de processamento de linguagem natural habilitam.
| Dimensão | Processamento de idioma natural | Modelos de linguagem |
|---|---|---|
| Scope | Um campo amplo que abrange diversas técnicas de processamento de texto, incluindo tokenização, lematização, reconhecimento de entidade, análise de sentimento e classificação de documentos. | Um subconjunto de aprendizado profundo do processamento de linguagem natural focado em tarefas de geração e compreensão de linguagem de alto nível. |
| Exemplos | Analisadores baseados em regra, classificadores de frequência de documento inverso a termos (TF-IDF), reconhecedores de entidade nomeados, analisadores de sentimento. | GPT, BERT e modelos semelhantes baseados em transformers que geram texto semelhante ao humano e ciente do contexto. |
| Saída | Sinais estruturados como rótulos, pontuações, intervalos extraídos e sintaxe analisada. | Linguagem natural fluente, como texto gerado, resumos, respostas e conclusões. |
| Relationship | O domínio pai. O processamento de linguagem natural abrange todo o espectro de métodos de processamento de texto. | Uma ferramenta no processamento de linguagem natural. Os modelos de linguagem aprimoram o processamento de linguagem natural sem substituí-lo. Eles lidam com tarefas cognitivas mais amplas, mas não são sinônimos de processamento de linguagem natural. |
Recursos de processamento de linguagem natural
Classifique documentos rotulando-os como confidenciais ou spam. O processamento de linguagem natural categoriza automaticamente documentos com base no conteúdo para dar suporte a fluxos de trabalho de conformidade e filtragem.
Resumir texto identificando entidades no documento. O processamento de linguagem natural extrai entidades-chave para produzir resumos concisos que capturam as informações mais importantes.
Marque documentos com palavras-chave usando entidades identificadas. Depois de identificar entidades, você pode gerar marcas de palavra-chave que simplificam a organização do documento. Use estas tags para pesquisa e recuperação com base no conteúdo.
Detecte tópicos para navegação e descoberta de documentos relacionados. O processamento de linguagem natural identifica os principais tópicos usando entidades extraídas, que dão suporte à categorização de documentos e à navegação baseada em tópicos.
Avaliar o sentimento do texto. A análise de sentimento avalia o tom emocional do texto e classifica o conteúdo como positivo, negativo ou neutro.
Alimente as saídas de processamento de linguagem natural em fluxos de trabalho subsequentes. Resultados como entidades extraídas, pontuações de sentimento e rótulos de tópico servem como entradas para processamento, indexação de pesquisa e análise.
Identificar possíveis casos de uso
Cenários de negócios em vários setores se beneficiam de soluções de processamento de linguagem natural. Os casos de uso a seguir mostram como as técnicas de processamento de linguagem natural abordam os desafios do mundo real, desde o processamento de documentos não estruturados até a habilitação de aplicativos emergentes em segurança cibernética e acessibilidade.
Processar documentos e texto não estruturado
Extraia inteligência de documentos criados por computador. O processamento de linguagem natural permite o processamento de documentos em finanças, saúde, varejo, governo e outros setores. Você pode analisar documentos criados digitalmente para extrair informações estruturadas de entradas não estruturadas. Para documentos manuscritos, use Azure Document Intelligence para converter conteúdo manuscrito em texto antes de aplicar técnicas de processamento de linguagem natural.
Aplique tarefas de processamento de linguagem natural independente do setor para processamento de texto. O NER (reconhecimento de entidade nomeado), a classificação, o resumo e a extração de relação ajudam você a processar e analisar automaticamente o conteúdo do documento não estruturado. Essas tarefas funcionam entre domínios e não exigem personalização específica do setor.
Crie modelos específicos do domínio para análise especializada. Exemplos dessas tarefas incluem modelos de estratificação de risco para serviços de saúde, classificação de ontologia para gerenciamento de conhecimento e resumos de varejo para dados de produtos e clientes. O treinamento de modelo personalizado em Azure Language e Spark NLP ajuda a melhorar a precisão desses formatos de documento específicos do domínio.
Gere relatórios automatizados a partir de entradas de dados estruturadas. Você pode sintetizar e gerar relatórios textuais abrangentes a partir de dados estruturados. Essa funcionalidade ajuda setores como finanças e conformidade que exigem documentação completa.
Habilitar pesquisa, tradução e análise
Crie grafos de conhecimento e habilite a pesquisa semântica por meio da recuperação de informações. O processamento de linguagem natural dá suporte à criação de grafo de conhecimento e pesquisa semântica, o que permite que os sistemas interpretem o significado da consulta em vez de depender apenas da correspondência de palavras-chave.
Suporte à descoberta de medicamentos e ensaios clínicos com grafos de conhecimento médico. Os sistemas de processamento de linguagem natural analisam o texto clínico. Grafos de conhecimento médico construídos a partir desse texto dão suporte a pipelines de descoberta de medicamentos e pareamento de ensaios clínicos. Esses grafos conectam entidades como drogas, condições e resultados para acelerar os fluxos de trabalho de pesquisa. Text analytics for health no Azure Language extrai entidades médicas, relações e afirmações que você pode usar para construir esses grafos.
Traduzir texto para IA de conversa em aplicativos voltados para o cliente. A tradução de texto habilita a IA de conversação em vários setores. Você pode criar aplicativos multilíngues voltados para o cliente que processam e respondem no idioma preferencial do usuário. O Spark NLP fornece recursos de tradução diretamente. Em Azure, use Azure Translator, que é um serviço separado de Azure Language.
Analise o sentimento e a inteligência emocional para a percepção da marca. A análise de sentimento ajuda a monitorar a percepção da marca e analisar os comentários dos clientes, apresentando sinais emocionais positivos, negativos e nuances do texto.
Estender o processamento de linguagem natural para domínios emergentes
Crie interfaces ativadas por voz para IoT (Internet das Coisas) e dispositivos inteligentes. O processamento de linguagem natural manipula a saída de texto de sistemas de reconhecimento de fala para entender a intenção do usuário e extrair significado em cenários de IoT e dispositivo inteligente. Cenários ativados por voz exigem Azure Speech para conversão de fala em texto antes do processamento de linguagem natural.
Ajuste a saída do idioma dinamicamente usando modelos de linguagem adaptáveis. Os modelos de linguagem adaptável ajustam dinamicamente a saída da linguagem para atender a diferentes níveis de compreensão de público, o que dá suporte à entrega de conteúdo educacional e à acessibilidade.
Detectar phishing e desinformação por meio da análise de texto de segurança cibernética. O processamento de linguagem natural analisa os padrões de comunicação e o uso da linguagem em tempo real para identificar possíveis ameaças à segurança na comunicação digital. Essa análise ajuda a detectar tentativas de phishing e campanhas de desinformação.
Avaliar Azure Idioma
Azure Language é um serviço baseado em nuvem que fornece recursos de processamento de linguagem natural para entender e analisar texto. Você pode acessá-lo por meio do portal Foundry, APIs REST e bibliotecas de cliente para Python, C#, Java e JavaScript sem infraestrutura para gerenciar. Para o desenvolvimento do agente de IA, você também pode acessar esses recursos por meio do servidor mcp (Protocolo de Contexto do Modelo de Linguagem) do Azure. Você pode acessá-lo como um servidor remoto no catálogo de ferramentas do Microsoft Foundry ou como um servidor auto-hospedado local.
Recursos pré-criados
Os recursos predefinidos não exigem treinamento de modelo e estão prontos para uso:
NER: Identifica e categoriza entidades em texto em tipos predefinidos, como pessoas, organizações, locais e datas.
Detecção de PII: Identifica e redigi informações de identificação pessoal (PII), incluindo dados pessoais e de integridade confidenciais, em conversas de texto e transcritas.
Detecção de idioma: Detecta o idioma de um documento em uma ampla variedade de idiomas e dialetos.
Análise de sentimento e mineração de opinião: Identifica o sentimento positivo, negativo ou neutro no texto e vincula opiniões a elementos específicos, como atributos de produto ou aspectos de serviço.
Extração de frase-chave: Avalia o texto não estruturado e retorna uma lista dos principais conceitos e frases-chave.
Resumo: Condensa documentos e conversas usando abordagens extrativas ou abstrativas, que dão suporte ao resumo de texto, chat e call center.
Análise de texto para saúde: Extrai e rotula informações de saúde relevantes do texto clínico não estruturado, incluindo entidades médicas, relações e afirmações.
Treinar modelos personalizados
Você pode usar recursos personalizáveis para treinar modelos em seus dados para lidar com tarefas de processamento de linguagem natural específicas do domínio:
- CNER (reconhecimento de entidades nomeadas personalizado): Crie modelos personalizados para extrair categorias de entidades específicas do domínio em texto não estruturado. Use CNER quando as categorias NER predefinidas não abrangem seu vocabulário de domínio.
Azure servidor de linguagem MCP e agentes
Observação
O servidor MCP de linguagem do Azure e os agentes de roteamento de intenções e de respostas a perguntas exatas estão em versão prévia. As funcionalidades prévias não incluem um SLA (acordo de nível de serviço) e não as recomendamos para cargas de trabalho de produção. Alguns recursos podem não ter suporte ou ter recursos limitados. Para obter mais informações, consulte Supplemental terms of use for Microsoft Azure previews.
Azure Language fornece agentes predefinidos e opções de implantação flexíveis para cargas de trabalho de processamento de linguagem natural de produção:
Agente de roteamento de intenção: Gerencia fluxos de conversação. Ele entende as intenções do usuário e as rotas para respostas precisas por meio de lógica determinística e auditável. Use esse agente quando precisar de roteamento de conversa transparente e determinístico.
Agente de resposta a perguntas exatas: Fornece respostas confiáveis, palavra por palavra para questões críticas aos negócios, mantendo a supervisão humana e o controle de qualidade. Use esse agente quando a precisão e a consistência da resposta forem essenciais.
Você pode acessar ambos os agentes por meio do catálogo de ferramentas do Foundry. Para obter mais informações, consulte Azure Language MCP Servidor e Agentes (Versão Prévia).
O servidor MCP de linguagem Azure dá suporte a várias opções de implantação:
Servidor MCP hospedado na nuvem remota: O catálogo de ferramentas do Foundry lista este servidor. O servidor fornece acesso gerenciado por nuvem aos recursos de linguagem Azure e não requer nenhuma infraestrutura local.
Servidor MCP auto-hospedado local: Dá suporte a implantações locais ou autogerenciadas para requisitos de conformidade, segurança ou residência de dados.
Implantação em contêineres: Os recursos a seguir oferecem suporte à implantação em contêineres para cenários que exigem processamento local ou ambientes isolados. Para obter a lista completa de contêineres disponíveis e seu status de disponibilidade, consulte Azure suporte a contêineres de IA.
- Análise de sentimento
- Detecção de idioma
- Extração de frase-chave
- NER
- Detecção de PII
- CNER
- Análise de Texto para a Saúde
- Resumo (versão prévia)
Avaliar o Apache Spark com o Spark NLP
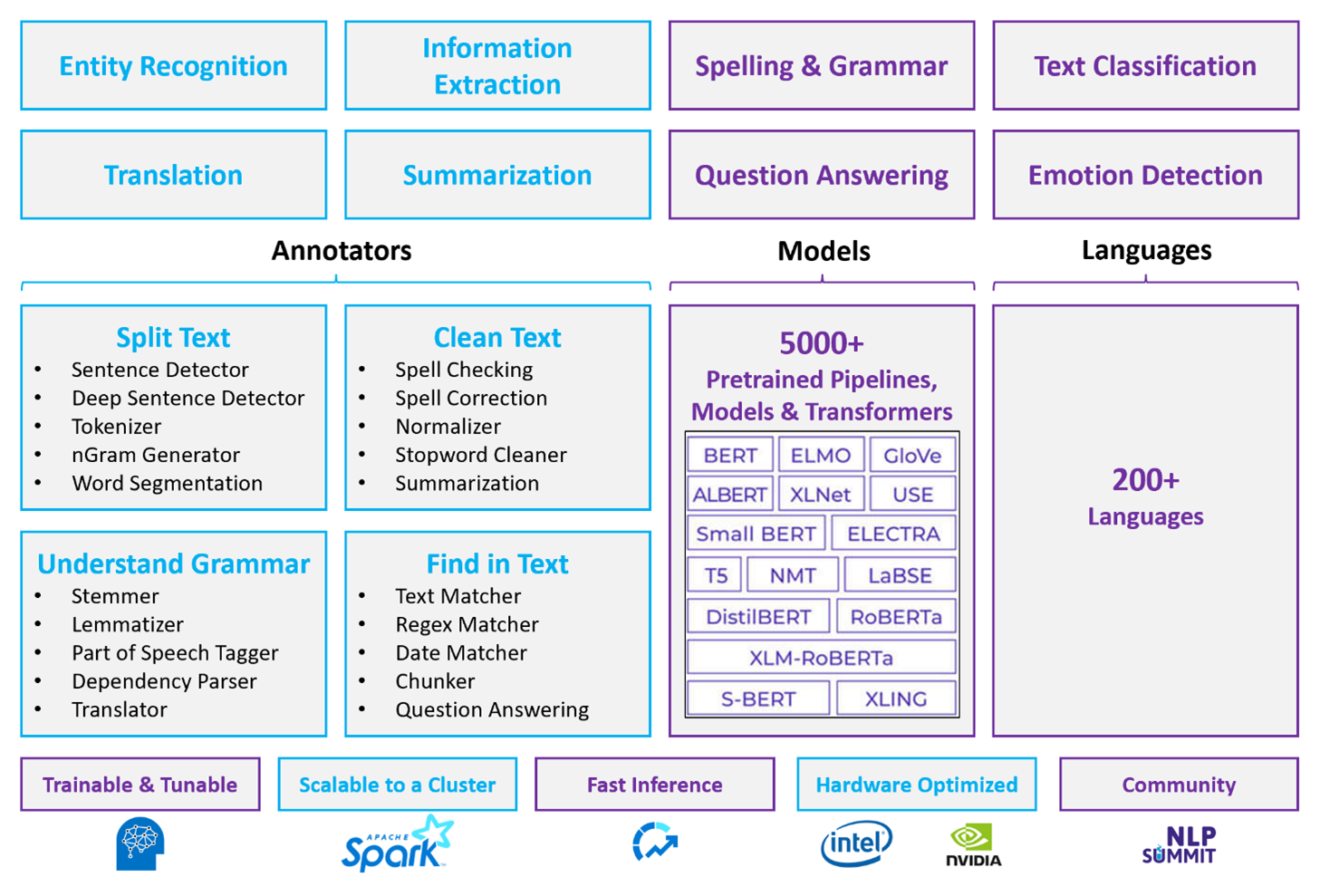
O Apache Spark com o Spark NLP é uma abordagem distribuída e de software livre para o processamento de linguagem natural que opera em escala de cluster. A arquitetura da plataforma SPARK NLP, o desempenho e o ecossistema de modelos predefinidos o tornam uma opção forte para cargas de trabalho de processamento de linguagem natural personalizáveis em larga escala em Azure Databricks ou Fabric.
Entender a plataforma e a arquitetura
Recomendamos que você use Fabric ou Azure Databricks para cargas de trabalho de processamento de linguagem natural baseadas no Apache Spark.
O Apache Spark fornece processamento paralelo na memória para análise de Big Data. Fabric e Azure Databricks oferecem acesso aos recursos de processamento do Apache Spark para cargas de trabalho de processamento de linguagem natural em larga escala.
O Spark NLP opera como uma extensão nativa do Spark ML em quadros de dados. Essa integração permite pipelines unificados de processamento de linguagem natural e machine learning com melhor desempenho em clusters distribuídos.
O Spark NLP é uma biblioteca de software livre com suporte Python, Java e Scala. A biblioteca fornece funcionalidade comparável ao NLTK (Kit de Ferramentas de Linguagem Natural e SpaCy), incluindo verificação ortográfica, análise de sentimento e classificação de documentos.

Apache®, Apache Spark e o logotipo da chama são marcas registradas ou marcas comerciais do Apache Software Foundation no United States e/ou em outros países. Nenhum endosso do Apache Software Foundation está implícito com o uso dessas marcas.
Avaliar o desempenho e a escalabilidade
Os parâmetros de comparação públicos mostram melhorias significativas de velocidade em relação a outras bibliotecas de processamento de linguagem natural. Em comparação com estruturas como spaCy e NLTK, o Spark NLP demonstra treinamento e inferência mais rápidos em clusters distribuídos. Modelos personalizados que o Spark NLP treina atingem níveis de precisão equivalentes aos de outros frameworks de processamento de linguagem natural, o que os torna adequados para cargas de trabalho de produção que exigem velocidade e precisão.
Builds otimizados para CPUs, GPUs e chips Intel Xeon utilizam plenamente clusters Apache Spark. Essas compilações permitem que o treinamento e a inferência sejam dimensionados com eficiência entre nós do cluster.
As inserções MPNet e o suporte ao ONNX habilitam o processamento preciso e com reconhecimento de contexto. O MPNet produz representações de vetor densas que capturam significado semântico e o suporte ao ONNX permite importar e executar modelos otimizados para inferência.
Usar modelos e fluxos predefinidos
Modelos de aprendizado profundo predefinidos lidam com NER, classificação de documentos e detecção de sentimento. A biblioteca vem com modelos de aprendizado profundo predefinidos.
Os modelos de linguagem pré-treinados dão suporte a inserções de palavra, parte, frase e documento. A biblioteca inclui modelos de linguagem pré-treinados que dão suporte a níveis de inserção de palavras, partes, frases e documentos. Essas inserções fornecem representações de vetor densas que permitem tarefas downstream, como pesquisa e classificação de similaridade.
Pipelines unificados de processamento de linguagem natural e machine learning dão suporte à classificação de documentos e à previsão de risco. A integração com o Spark ML dá suporte a pipelines unificados de processamento de linguagem natural e machine learning para tarefas como classificação de documentos e previsão de risco. Com essa abordagem unificada, você pode combinar o processamento de texto com modelos tradicionais de machine learning em um único pipeline, o que reduz a complexidade arquitetônica.
Enfrentar desafios comuns de processamento de linguagem natural
Ambos Azure Language e Apache Spark com Spark NLP enfrentam desafios comuns no processamento de linguagem natural em escala. Se você entender esses desafios, poderá planejar recursos, projetar pipelines e definir expectativas de precisão antes de se comprometer com qualquer uma das opções.
Processamento de recursos
O processamento de texto de forma livre requer recursos computacionais e tempo significativos. Documentos de texto de forma livre são computacionalmente caros e com uso intensivo de tempo para análise. Cada documento requer tokenização, normalização e inferência de modelo antes de produzir resultados utilizáveis.
As cargas de trabalho do Spark NLP geralmente exigem a implantação de computação de GPU. Para pipelines do Spark NLP em larga escala, os clusters acelerados por GPU em Azure Databricks ou Fabric fornecem o poder de processamento paralelo necessário para treinamento e inferência. Otimizações como a quantização de modelo llama 3.x ajudam a reduzir o volume de memória e melhorar a taxa de transferência dessas tarefas intensivas.
Azure Language requer planejamento de capacidade e gerenciamento de cotas. O serviço lida com o gerenciamento de recursos, mas chamadas à API de alto volume exigem um planejamento cuidadoso de desempenho. Monitore suas taxas de solicitação em relação aos limites de serviço e limites de taxa para evitar a limitação e garantir um desempenho de processamento consistente.
Padronização de documentos
Documentos do mundo real raramente seguem uma estrutura consistente. Essa inconsistência cria desafios para fluxos de extração e requer estratégias deliberadas para manter a precisão em todas as fontes.
Formatos inconsistentes: Sem um formato de documento padronizado, a extração de fatos específicos do texto de forma livre pode ser difícil. Por exemplo, pode ser um desafio extrair números de fatura e datas de diferentes fornecedores porque layouts de campo, rótulos e formatação variam entre fontes.
Treinamento de modelos personalizados: Ao treinar modelos personalizados no Spark NLP e Azure Language, é possível adaptar-se aos formatos específicos de documentos do domínio. Ao treinar amostras representativas de seus documentos reais, você pode melhorar a precisão de extração para campos, entidades e padrões que os modelos predefinidos não lidam bem.
Variedade e complexidade de dados
Estruturas de documentos diversas e nuances linguísticas adicionam complexidade. Os dados de texto do mundo real vêm em muitos formatos, estilos de escrita e idiomas. Lidar com essas variações requer modelos que podem lidar com ambiguidade, gírias, abreviações e terminologia específica do domínio, mantendo a precisão.
As incorporações MPNet no Spark NLP fornecem uma compreensão contextual mais aprimorada. As incorporações MPNet capturam relações contextuais entre palavras e frases, o que ajuda os pipelines NLP do Spark a tratar textos com nuances de forma mais eficaz. Essas inserções produzem representações vetoriais densas que preservam o significado semântico em diferentes formatos de documento.
Modelos personalizados no Azure Language adaptam-se a padrões de texto específicos do domínio. Com o CNER , você pode treinar modelos em seus próprios dados rotulados para reconhecer padrões específicos ao seu domínio. Essa abordagem melhora a confiabilidade ensinando o modelo a reconhecer entidades e categorias que os modelos predefinidos perdem.
Aplicar critérios de seleção principais
Use os critérios a seguir para determinar qual opção de processamento de idioma natural Azure melhor atende aos seus requisitos. Cada critério descreve uma característica de carga de trabalho e identifica o serviço que o trata.
capacidades de processamento de linguagem natural gerenciado: Use Azure Language APIs para reconhecimento de entidades, identificação de intenção, detecção de tópicos ou análise de sentimento. Esses recursos estão disponíveis como serviços gerenciados com configuração mínima e você não precisa provisionar nem gerenciar nenhuma infraestrutura.
Modelos predefinidos ou pré-treinados: use o Azure Language se você planeja usar modelos predefinidos ou pré-treinados sem gerenciar a infraestrutura. Essa abordagem atende a conjuntos de dados pequenos a médios e tarefas de processamento de linguagem natural padrão em que os modelos predefinidos fornecem precisão suficiente. Ele fornece dimensionamento automático, segurança embutida e preços por chamada sem sobrecarga de gerenciamento de cluster.
Treinamento de modelo customizado em grandes conjuntos de dados de texto: Use Azure Databricks ou Fabric com Spark NLP. Essas plataformas fornecem o poder computacional e a flexibilidade necessárias para o treinamento extensivo do modelo em grandes conjuntos de dados de texto. Você também pode baixar modelos por meio do Spark NLP, incluindo Llama 3.x e MPNet.
Primitivos de processamento de linguagem natural de baixo nível: use Azure Databricks ou Fabric com o Spark NLP para tokenização, stemming, lematização e TF-IDF. Como alternativa, use uma biblioteca de software livre, como spaCy ou NLTK. Azure Language in Foundry Tools usa a tokenização internamente como parte de seu pipeline de modelo, mas não expõe essas etapas como APIs autônomas e controláveis.
Criar pipelines de processamento de linguagem natural usando o SPARK NLP
O Spark NLP segue o mesmo padrão de desenvolvimento que os modelos tradicionais do Spark ML quando você executa um pipeline de processamento de linguagem natural. Você gerencia modelos treinados usando o MLflow para acompanhamento de experimentos e implantação de produção.

Montar componentes principais do pipeline
Um pipeline do Spark NLP encadeia os anotadores em sequência. Cada anotador transforma a saída do estágio anterior e converte o texto bruto em vetores semânticos.
DocumentAssembler é o ponto de entrada para cada pipeline do Spark NLP. Use
setCleanupModepara aplicar o pré-processamento de texto opcional, como remoção de marca HTML ou normalização de espaço em branco, antes que os anotadores downstream executem.SentenceDetector identifica os limites de sentença no documento montado. Ele retorna as frases detectadas como um elemento
Arraydentro de uma única linha ou como linhas separadas, dependendo da configuração do pipeline. A detecção precisa de frases é importante porque muitos anotores downstream operam no nível da sentença.O tokenizador divide o texto bruto em tokens discretos, como palavras, números e símbolos. Se as regras padrão forem insuficientes para seu domínio, adicione regras personalizadas para lidar com vocabulário especializado, termos hifenizados ou padrões específicos do domínio.
O normalizador refina tokens aplicando expressões regulares e transformações de dicionário. Limpa o texto para reduzir o ruído antes da inserção. Por exemplo, você pode remover ênfases, converter em letras minúsculas ou aplicar mapeamentos de dicionário personalizados para padronizar a terminologia.
O WordEmbeddings mapeia tokens para vetores semânticos para processamento contextual. Cada token é representado como um vetor denso que captura seu significado em relação a outros tokens. Tokens que não aparecem no vocabulário de embeddings e, portanto, não são resolvidos são padronizados para vetores zero.
Gerenciar modelos usando o MLflow
O Spark NLP usa pipelines do Spark MLlib com suporte nativo MLflow. Você não precisa escrever um código de integração ou serialização personalizado.
O MLflow gerencia o acompanhamento de experimentos, o controle de versão do modelo e a implantação. Você pode registrar parâmetros, métricas e artefatos de pipeline durante as execuções de treinamento. O MLflow rastreia cada experimento, para que você possa comparar resultados entre iterações e reproduzir configurações bem-sucedidas.
O MLflow integra-se diretamente com Azure Databricks e Fabric. No Azure Databricks, o MLflow vem pré-instalado e se integra firmemente ao workspace. Fabric também fornece uma experiência de MLflow embutida com acompanhamento de experimentos nativo e registro automático, portanto, você não precisa instalar o MLflow separadamente. Se você executar o Spark NLP em outro ambiente baseado no Apache Spark, poderá instalar o MLflow separadamente e configurá-lo para acompanhar experimentos em um servidor de acompanhamento remoto.
Use o Registro de Modelo do MLflow para promover modelos para produção e manter a governança. O Registro de Modelo fornece um repositório central para gerenciar versões de modelo em seus pipelines de processamento de linguagem natural. Em implantações clássicas, os modelos transitam por estágios como teste, produção e arquivamento. Em Azure Databricks, as implantações mais recentes usam Models no Catálogo do Unity, que substitui estágios fixos por aliases e marcas personalizadas para gerenciamento de ciclo de vida mais flexível. Em Fabric, o workspace fornece seu próprio registro de modelo baseado em MLflow.
Matriz de funcionalidades
As tabelas a seguir resumem as principais diferenças de recursos entre o Spark NLP em Azure Databricks ou Fabric e Azure Language.
Funcionalidades gerais
| Capacidade | Spark NLP (Azure Databricks ou Fabric) | Idioma do Azure |
|---|---|---|
| Modelos pré-treinados como serviço | Sim | Sim |
| API REST | Sim | Sim |
| Programabilidade | Python, Scala | Consulte as linguagens de programação com suporte. |
| Dá suporte ao processamento de grandes conjuntos de dados e documentos grandes | Sim | Limitado 1 |
1.Azure Language tem limites de tamanho de documento por solicitação que variam de acordo com o modo. Solicitações síncronas dão suporte a até 5.120 caracteres por documento e solicitações assíncronas dão suporte a até 125.000 caracteres por documento. Ambos os modos dão suporte a até 25 documentos por chamada à API. Você pode processar grandes volumes de conjunto de dados por meio de lote e paginação, mas documentos individuais que excedem o limite de caracteres para o modo escolhido exigem agrupamento. Para obter mais informações, consulte Data e limites de taxa para Azure Language.
Funcionalidades do anotador
| Capacidade | Spark NLP (Azure Databricks ou Fabric) | Idioma do Azure |
|---|---|---|
| Detector de sentenças | Sim | Não |
| Detector de sentenças profundas | Sim | Não |
| Tokenizador | Sim | Somente interno (não exposto como uma API autônoma) |
| Gerador de N-grama | Sim | Não |
| segmentação de palavras | Sim | Sim |
| Lematizador | Sim | Não |
| Lematizador | Sim | Não |
| Etiquetagem de Partes do Discurso | Sim | Não |
| Analisador de dependência | Sim | Não |
| Tradução | Sim | Não |
| Limpador de palavras irrelevantes | Sim | Não |
| Correção ortográfica | Sim | Não |
| Normalizador | Sim | Sim |
| Correspondente de texto | Sim | Não |
| TF-IDF | Sim | Não |
| Correspondente de expressão regular | Sim | Limitado |
| Correspondente de data | Sim | Limitado |
| Chunker | Sim | Não |
Recursos de processamento de linguagem natural de alto nível
| Capacidade | Spark NLP (Azure Databricks ou Fabric) | Idioma do Azure |
|---|---|---|
| Verificação ortográfica | Sim | Não |
| Resumo | Sim | Sim |
| Respostas às perguntas | Sim | Sim |
| Detecção de sentimento | Sim | Sim |
| Detecção de Emoções | Sim | Limitado 2 |
| Classificação de token | Sim | Limitado 3 |
| Classificação de texto | Sim | Limitado 3 |
| Representação de texto | Sim | Não |
| NER | Sim | Sim (pré-construído). O CNER está disponível por meio de modelos personalizados. 3 |
| Detecção de idioma | Sim | Sim |
| Dá suporte a idiomas diferentes do inglês | Sim. Consulte os idiomas com suporte do Spark NLP. | Sim. Consulte Azure Idiomas compatíveis. |
2.Azure Language dá suporte à mineração de opiniões, que identifica sentimentos vinculados a aspectos específicos do texto, mas não fornece detecção dedicada de emoções (como alegria, raiva ou classificação de tristeza).
3.Disponível através de modelos personalizados. Você treina os modelos de reconhecimento de entidade CNER ou personalizados em seus próprios dados rotulados.
Contribuidores
Microsoft mantém este artigo. Os colaboradores a seguir escreveram este artigo.
Autores principais:
- Ananya Ghosh Chowdhury | Arquiteto principal de soluções de nuvem
- Kranthi Manchikanti | Engenheiro sênior de soluções de IA
Outros colaboradores:
- Freddy Ayala | Arquiteto de Soluções na Nuvem
- Tincy Elias | Arquiteto sênior de soluções de nuvem
- Moritz Steller | Arquiteto Sênior de Soluções de Nuvem
Para ver perfis de LinkedIn não públicos, entre em LinkedIn.
Próximas etapas
- Introdução à IA no Azure
- Desenvolva soluções de processamento de linguagem natural usando Foundry Tools
Recursos relacionados
documentação do idioma Azure:
- Visão geral Azure Language
- Documentação do Foundry
Documentação do Spark NLP:
Azure componentes:
Saiba mais sobre os recursos: