Observação
O acesso a essa página exige autorização. Você pode tentar entrar ou alterar diretórios.
O acesso a essa página exige autorização. Você pode tentar alterar os diretórios.
Qualidade de Dados do Microsoft Purview para origens de dados no local permitem que as organizações avaliem, monitorizem e melhorem a qualidade dos dados armazenados em sistemas internos, como bases de dados e plataformas legadas. Suporta fluxos de trabalho de validação, deteção de erros e remediação baseados em regras, garantindo simultaneamente a conformidade com as políticas organizacionais. Ao integrar com a infraestrutura existente, fornece informações consistentes de qualidade de dados e governação em ambientes no local e na cloud.
Ao utilizar um runtime de integração de dados autoalojado, pode dimensionar os processos de qualidade dos dados ao ligar de forma segura origens de dados no local ao Purview. Este artigo abrange o runtime de integração de dados autoalojado baseado no Kubernetes, Linux, que melhora a infraestrutura subjacente e proporciona vários benefícios fundamentais:
- Escalabilidade: capacidade de dimensionar para centenas de máquinas.
- Desempenho: desempenho melhorado para a análise de cargas de trabalho.
- Segurança (em contentores): ativa a implementação em contentores num cluster do Kubernetes, eliminando a necessidade de alojar o runtime de integração de dados diretamente num computador Windows.
Origens de dados suportadas
- Oracle
- SQL Server
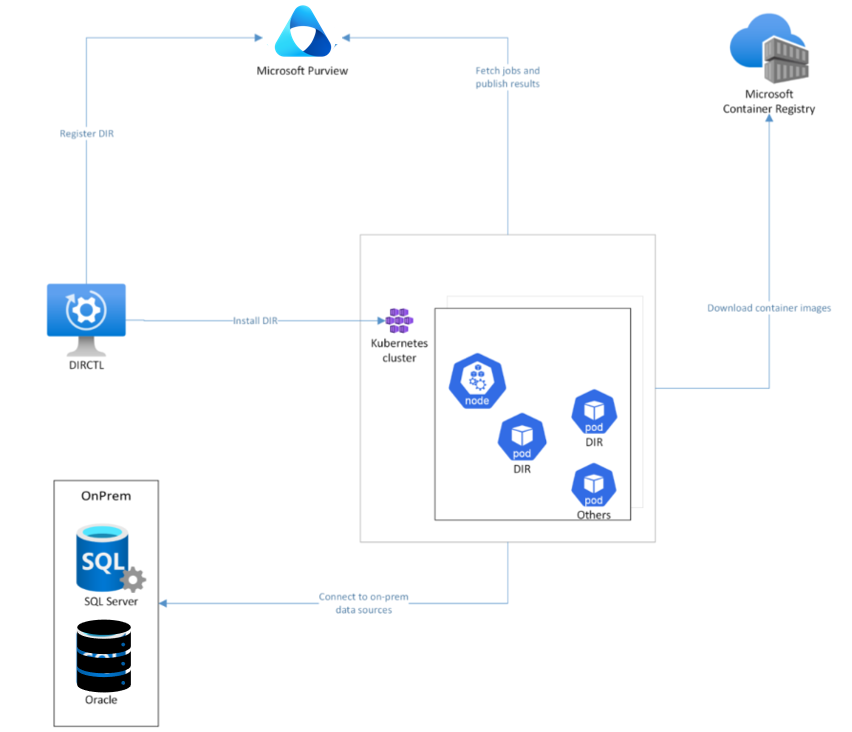
Arquitetura
Numa vista de arquitetura de alto nível, quando instala um runtime de integração de dados baseado no Kubernetes, vários pods são automaticamente configurados nos nós do cluster do Kubernetes. Uma ferramenta de linha de comandos chamada DIRCTL aciona esta instalação. O DIRCTL liga-se ao Serviço Microsoft Purview para registar o runtime de integração de dados e ligar ao cluster do Kubernetes para instalar o runtime de integração de dados autoalojado.
Durante a instalação, o processo transfere imagens do runtime de integração de dados do MCR (Microsoft Container Registries) para os pods do runtime de integração de dados. Após a instalação estar concluída, os pods no cluster ligam-se ao serviço Purview para solicitar tarefas de análise. À medida que uma tarefa de análise é solicitada, pode ligar a sua origem de dados no local para análise da Qualidade dos Dados.
Pré-requisitos
ferramenta de Linha de Comandos do Integração de Dados Runtime (DIRCTL)
Precisa da ferramenta da Linha de Comandos do Integração de Dados Runtime (DIRCTL) para configurar o runtime de integração de dados. Para obter instruções de transferência e instalação, veja Configurar a ferramenta DIRCTL para o runtime de integração autoalojado (pré-visualização).
Funções
Para configurar um runtime integrado autoalojado no Purview, precisa da função Administrador de Governação de Dados.
Cluster do Kubernetes
Precisa de um cluster do Kubernetes baseado em Linux existente ou tem de preparar um. Identifique os nós com um seletor de nós, que segue a definição do seletor de nós do Kubernetes. Configuração mínima:
- Tipo de contentor: Linux
- Versão do Kubernetes: 1.24.9 ou posterior
- SO do nó: Linux so baseado em execução na arquitetura x86
- Especificação de nó: CPU mínima de oito núcleos, memória de 32 GB e, pelo menos, 80 GB de espaço disponível no disco rígido
- Contagem de nós: 1 ou mais (dimensionador automático de cluster fixo e não ativado)
- Número do pod por Nó: 20 ou mais (número máximo do Pod – contagem de outros Pods que não pertencem a Self-Hosted IR)
Observação
A pasta /var/irstorage/ de cada nó está reservada para o runtime integrado autoalojado. É legível e gravável para o runtime de integração de dados. Pode obter registos desta pasta ou carregar controladores externos para esta pasta. O runtime de integração de dados cria a pasta se não existir e não elimina a pasta após a eliminação do runtime de integração de dados. As imagens de contentor utilizadas pelo runtime de integração de dados são geridas pela Libertação da Memória do Kubernetes, que não é limpa pelo runtime de integração de dados. Configure o limiar adequado para o cluster do Kubernetes.
A conectividade de saída é necessária para extrair imagens de contentor, bem como para uma operação adicional, que inclui atividades como solicitar tarefas de qualidade de dados e emitir estatísticas geradas.
Contexto do Kubernetes
O contexto do Kubernetes, que contém informações do cluster do Kubernetes e as permissões e credenciais do utilizador para este cluster, é necessário para comunicar com o cluster do Kubernetes. Para facilitar a configuração das permissões do utilizador para a gestão de DIR, pode começar com o Kubernetes Administração função. Este contexto é gerado com a configuração do cluster do Kubernetes e guardado num ficheiro de configuração. Onde e como pode obter este ficheiro depende da configuração do cluster do Kubernetes.
Se utilizar o kubeadm init para configurar o cluster do Kubernetes, pode encontrar o ficheiro
/etc/Kubernetes/admin.confde configuração em .Se utilizar o AKS, pode seguir a documentação de orientação do AKS para utilizar o comando do módulo Az PowerShell para obter as credenciais deste cluster para o seu computador local. Pode intercalar o contexto com o ficheiro
$HOME/.kube/configde configuração em diretamente.Se estiver a utilizar outras ferramentas para configurar um cluster do Kubernetes, veja a documentação do Kubernetes.
Depois de obter o ficheiro de configuração para o contexto do Kubernetes, intercale-o no ficheiro
$HOME/.kube/configde configuração no computador onde pretende executar o comando IRCTL. Em alternativa, pode definir o ficheiro de configuração do contexto do Kubernetes numa variável de ambiente chamadaKUBECONFIG. Para obter mais informações sobre o contexto do Kubernetes, veja como configurar o acesso a vários clusters.
Configurar um runtime de integração de dados autoalojado
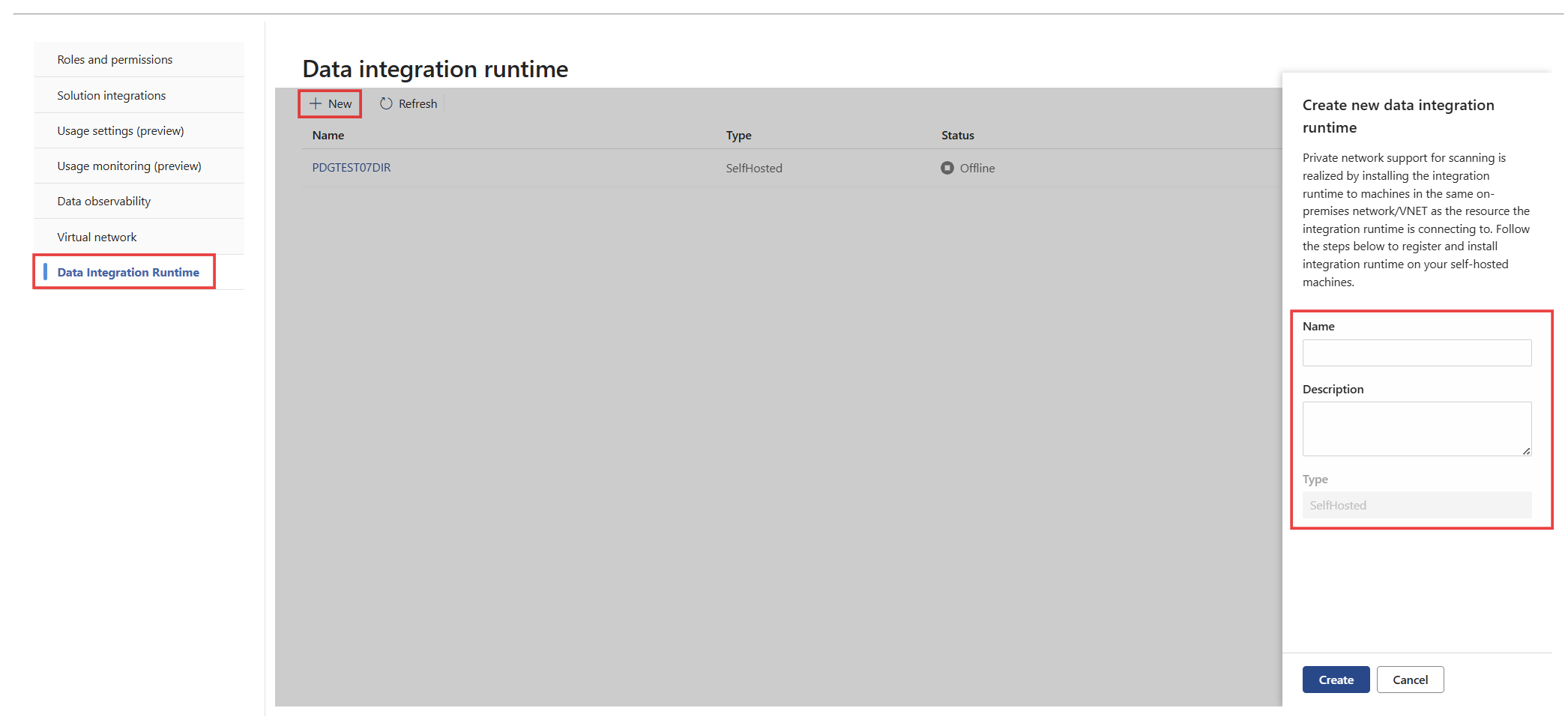
Aceda a Definições>Catálogo unificado do Microsoft Purview>Integração de Dados Runtime e, em seguida, selecione Novo para criar um runtime de integração de dados.
Introduza um Nome e uma Descrição para o runtime integrado autoalojado e, em seguida, selecione Criar.
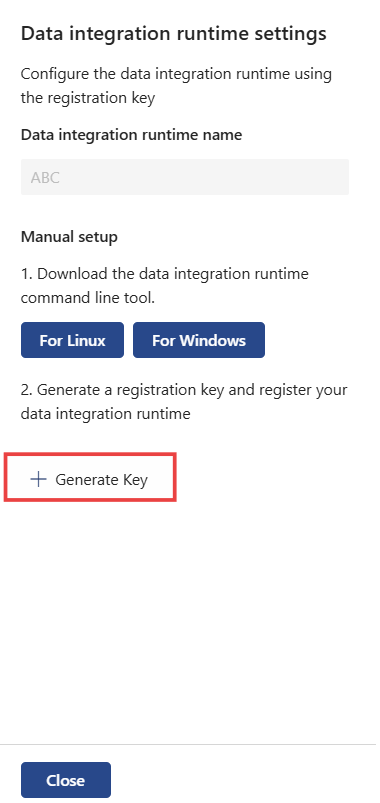
Selecione Gerar chave para gerar uma chave de registo e registar o runtime de integração de dados.
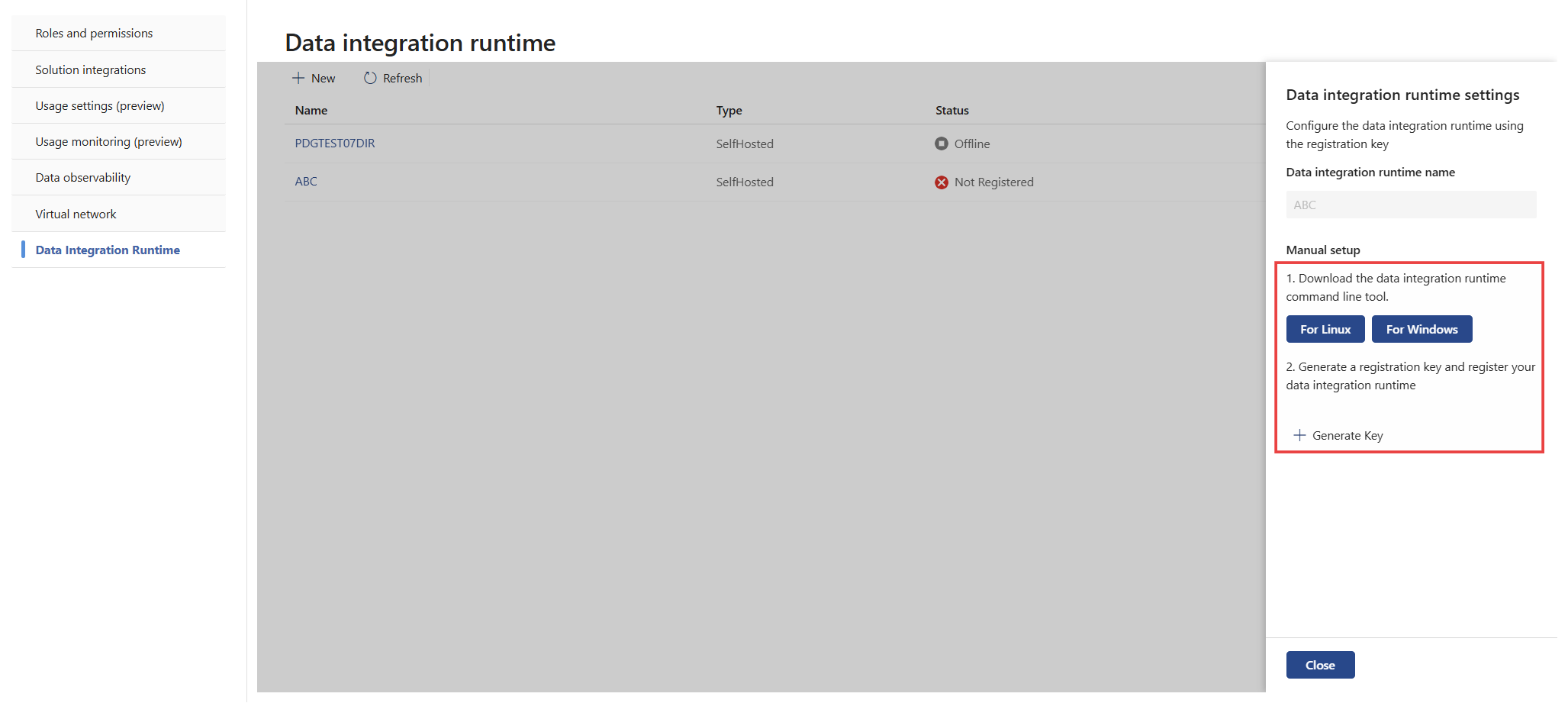
Copie o valor da chave e selecione Concluído.
Dica
Se necessário, pode regenerar uma chave ou revogar uma chave gerada.
Selecione Para Linux para transferir a ferramenta Integração de Dados Linha de Comandos de Runtime (DIRCTL). Obtenha detalhes sobre como instalar e gerir DIRCTL.
No computador onde pretende executar a linha de comandos DIRCTL, instale DIRCTL a partir da transferência. O DIRCTL liga-se ao cluster do Kubernetes através do contexto da configuração do Kube. Se não especificar um contexto, DIRCTL utiliza o contexto atual. Pode definir o contexto de uma de duas formas:
- Execute a
kubectllinha de comandos e execute este comando para confirmar o contexto atual:-
kubectl config get-contexts: listar todos os contextos configurados no computador -
kubectl config current-context: Obter o nome de contexto atual kubectl config use-context <name of context>
-
- Execute DIRCTL e execute
-contextpara especificar o contexto na configuração do Kube.
- Execute a
Execute o comando DIRCTL Create:
./DIRCTL create - -registration-key <registration-key copied from the portal>. O comando DIRCTL Create regista um novo runtime de integração de dados com a Qualidade dos Dados e inicia a criação de uma aplicação no Kubernetes como um pod específico do runtime de integração de dados registados. Processa o aprovisionamento de recursos e a configuração essenciais para a funcionalidade do runtime de integração de dados, mantendo a compatibilidade com os requisitos de sistema existentes.
Após a conclusão do registo, pode marcar a status do runtime de integração de dados na página Integração de Dados Runtime em Definições. O status é apresentado como Online. Também pode marcar a status do runtime de integração de dados ao executar este comando: ./DIRCTL describe.
Dica
Estes são os pontos finais públicos aos quais o runtime de integração de dados se liga e que têm de ser permitidos listados:
- < >purview_account_name.purview.azure.com
- Mcr.microsoft.com
- *.data.mcr.microsoft.com
Configurar a ligação da origem de dados no local com o runtime de integração de dados
Ligar à base de dados Oracle
Crie ligações ao associá-las a uma instância de runtime de integração de dados.
- No Catálogo unificado, aceda a Gestão> de estado de funcionamentoQualidade dos dados.
- Selecione o domínio de governação onde criou o produto de dados com o recurso de dados Oracle.
- Selecione Gerir e, em seguida, selecione Ligação para configurar a ligação para a sua base de dados Oracle.
Adicione as seguintes informações para configurar a ligação:
- Introduza um Nome a apresentar para a ligação.
- Introduza uma Descrição.
- Em Tipo de origem, selecione Oracle.
- Selecione o Runtime de integração de dados que criou como parte do pré-requisito.
- Introduza o Nome do anfitrião .
- Introduza o Número da porta .
- Introduza o Nome do serviço.
- Introduza o Nome do esquema.
- Selecione um método de Autenticação.
- Introduza o Nome de utilizador.
- Em Credencial, introduza a subscrição Azure, Azure Key Vault ligação, Nome do segredo e Versão do segredo.
- Selecione Submeter para concluir a configuração da ligação.
Dica
Se não tiver todas as informações necessárias, selecione Guardar como rascunho para continuar mais tarde quando tiver as restantes informações para concluir a configuração da ligação.
Esta imagem ilustra como criar uma ligação:

Ligar à base de dados SQL Server
Crie ligações ao associá-las a uma instância de runtime de integração de dados, tal como faz para o Oracle. No SQL Server, uma base de dados individual pode conter tabelas pertencentes a vários esquemas, pelo que pode utilizar uma única ligação para analisar todos os esquemas numa única base de dados. Uma ligação só aceita informações da base de dados, mas não o esquema. Crie ligações para SQL Server tal como faz para outros tipos de origem de dados.
- No Catálogo unificado, aceda a Gestão> de estado de funcionamentoQualidade dos dados.
- Selecione o domínio de governação onde criou o produto de dados com o recurso de dados Oracle.
- Selecione Gerir e, em seguida, selecione Ligação para configurar a ligação para a sua base de dados Oracle.
Adicione as seguintes informações para configurar a ligação com êxito:
- Introduza um Nome a apresentar para a ligação.
- Introduza uma Descrição.
- Em Tipo de origem, selecione SQL Server.
- Selecione o Runtime de integração de dados que criou como parte do pré-requisito.
- Introduza o Ponto Final do Servidor.
- Introduza o Nome da base de dados .
- Selecione um método de Autenticação.
- Introduza o Nome de utilizador.
- Em Credencial, introduza a subscrição do Azure, Azure Key Vault ligação e o Nome do segredo.
- Selecione Submeter para concluir a configuração da ligação.
Dica
Se não tiver todas as informações necessárias, selecione Guardar como rascunho para continuar mais tarde quando tiver as restantes informações para concluir a configuração da ligação.
Esta imagem ilustra como criar uma ligação:

Verificação da qualidade de dados
Depois de concluir a configuração da ligação, siga a criação de perfis de qualidade de dados e a análise de documentos para medir e monitorizar a qualidade dos dados do Oracle e SQL Server origens de dados no local.
- Descrição geral da qualidade dos dados
- Origens de dados suportadas
- Configurar a ligação de origem de dados
- Análise da qualidade do produto de dados
- Análise da qualidade do recurso de dados
- Análise de qualidade de dados incremental
Elevada disponibilidade e escalabilidade
Atribua vários nós no cluster do Kubernetes para elevada disponibilidade com o seletor de nós durante a instalação do runtime de integração autoalojado suportado pelo Kubernetes. As vantagens de ter vários nós incluem:
Maior disponibilidade do runtime de integração autoalojado para que não seja um único ponto de falha para análises.
Mais análises simultâneas. Cada nó pode processar muitas execuções de análise ao mesmo tempo. Se precisar de mais análises simultâneas, pode aumentar horizontalmente os nós do cluster do Kubernetes.
Ao analisar algumas origens, como Azure Blob, Azure Data Lake Storage Gen2 e Arquivos do Azure, cada execução de análise pode utilizar vários nós para aumentar o desempenho da análise. Para outras origens, as análises são executadas apenas num dos nós.
Pode atualizar as capacidades do runtime de integração autoalojado suportado pelo Kubernetes ao aumentar horizontal ou dimensionar manualmente os nós do cluster do Kubernetes.
Observação
Tem de carregar todos os controladores necessários para a análise em cada novo nó.
Requisito de rede
| Nome de domínio | Porta de saída | Descrição |
|---|---|---|
Cloud pública: <tenantID>-api.purview-service.microsoft.com Azure Governamental: <tenantID>-api.purview-service.microsoft.us China: <tenantID>-api.purview-service.microsoft.cn |
443 | Necessário para ligar ao serviço Microsoft Purview. Se utilizar pontos finais privados do Microsoft Purview, o ponto final privado da conta abrange este ponto final. |
Cloud pública: <purview_account>.purview.azure.com Azure Governamental: <purview_account>.purview.azure.us China: <purview_account>.purview.azure.cn |
443 | Necessário para ligar ao serviço Microsoft Purview. Se utilizar pontos finais privados do Microsoft Purview, o ponto final privado da conta abrange este ponto final. |
| mcr.microsoft.com | 443 | Necessário para transferir imagens. |
| *.data.mcr.microsoft.com | 443 | Necessário para transferir imagens. |