Observação
O acesso a essa página exige autorização. Você pode tentar entrar ou alterar diretórios.
O acesso a essa página exige autorização. Você pode tentar alterar os diretórios.
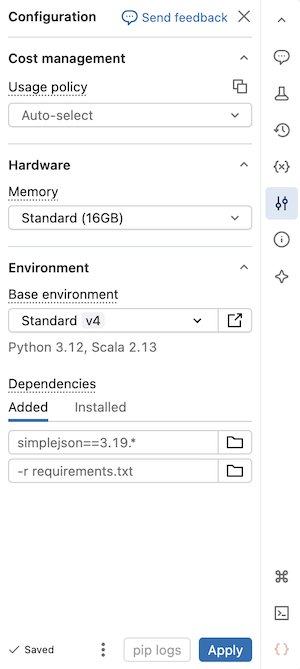
Esta página explica como usar o painel lateral ambiente de um notebook sem servidor para configurar dependências, políticas de uso sem servidor, memória e ambiente base. Este painel fornece um único local para gerenciar as configurações sem servidor do notebook. As configurações configuradas neste painel só se aplicam quando o notebook está conectado à computação sem servidor.
Para expandir o painel lateral ambiente, clique no botão ![]() à direita do notebook.
à direita do notebook.
Usar o AI Runtime (GPU sem servidor)
Important
O AI Runtime está em Visualização Pública.
Siga estas etapas para configurar o AI Runtime, alimentado pela computação de GPU sem servidor, em seu notebook do Databricks:
- Em um notebook de programação, clique no menu suspenso de computação na parte superior e selecione GPU sem servidor.
- Clique no
 Para abrir o painel lateral ambiente .
Para abrir o painel lateral ambiente . - Selecione A10 no campo Acelerador .
- No ambiente base, selecione Standard para o ambiente padrão ou IA para o ambiente otimizado para IA com bibliotecas de machine learning pré-instaladas.
- Clique em Aplicar e confirme se deseja aplicar o AI Runtime ao seu ambiente de notebook.
Para obter mais detalhes, consulte AI Runtime.
Usar computação sem servidor de memória alta
Important
Esse recurso está em uma versão prévia.
Se você se deparar com erros de memória insuficiente no notebook, é possível configurar o notebook para usar um tamanho de memória mais alto. Essa configuração aumenta o tamanho da memória REPL usada ao executar o código no notebook. Ele não afeta o tamanho da memória da sessão do Spark. O uso sem servidor com memória alta tem uma taxa de emissão de DBU maior do que a memória padrão.
As opções de memória disponíveis são:
- Padrão: memória total de 16 GB.
- Alta: memória total de 32 GB.
Para definir a configuração de memória do notebook:
- Na interface do usuário do notebook, clique no painel lateral Ambiente
 .
. - Em Memória, selecione Memória alta.
- Clique em Aplicar.
Essa configuração também se aplica às tarefas de trabalho do notebook, que são executadas usando as preferências de memória do notebook. Atualizar a preferência de memória no notebook afeta a próxima execução do trabalho.
Selecionar uma política de uso sem servidor
Important
Esse recurso está em uma versão prévia.
As políticas de uso de serverless permitem que sua organização aplique tags personalizadas no uso de serverless para atribuição de cobrança granular.
Se o seu workspace usar políticas de utilização sem servidor para atribuir o uso sem servidor, você poderá selecionar a política que deseja aplicar ao notebook. Se um usuário for atribuído a apenas uma política de uso sem servidor, essa política será selecionada por padrão.
Você pode selecionar a política de uso sem servidor depois que o notebook estiver conectado aos recursos de computação sem servidor usando o painel lateral ambiente :
- Na interface do usuário do notebook, clique no painel lateral Ambiente.
- Na política de uso sem servidor , selecione a política de uso sem servidor que você deseja aplicar ao seu notebook.
- Clique em Aplicar.
Quando essa configuração é concluída, todo o uso do notebook herda as marcas personalizadas da política de uso sem servidor.
Note
Se o notebook for proveniente de um repositório Git ou não tiver uma política de uso sem servidor atribuída, ele usará como padrão sua última política de uso sem servidor escolhida quando ele for anexado ao uso de computação sem servidor.
Selecionar um ambiente base
Um ambiente base determina as bibliotecas pré-instaladas e a versão do ambiente disponíveis para seu notebook sem servidor. O seletor de ambiente base no painel lateral ambiente fornece uma interface unificada para selecionar seu ambiente. Para ver detalhes sobre cada versão do ambiente, consulte versões de ambiente sem servidor. O Databricks recomenda usar a versão mais recente para obter os recursos de notebook mais atualizados.
O seletor de ambiente base inclui as seguintes opções:
- Padrão: o ambiente base padrão com bibliotecas fornecidas pelo Databricks.
- IA: um ambiente base com otimização de IA com bibliotecas de machine learning pré-instaladas. Essa opção aparece somente quando um acelerador (GPU) é selecionado.
-
Mais: expande para mostrar opções adicionais:
- Versões anteriores de ambientes standard e de IA.
- Personalizado: permite que você especifique um ambiente personalizado usando um arquivo YAML.
- Ambientes de workspace: lista todos os ambientes base compatíveis configurados para seu workspace por um administrador.
Para selecionar um ambiente base:
- Na interface do usuário do notebook, clique no painel lateral Ambiente.
- No Ambiente Base, selecione um ambiente no menu suspenso.
- Clique em Aplicar.
Adicionar dependências ao notebook
Como o serverless não oferece suporte a políticas de computação ou scripts de inicialização, você deve adicionar dependências personalizadas usando o painel lateral Environment. Você pode adicionar dependências individualmente ou usar um ambiente base compartilhável para instalar várias dependências.
Para adicionar individualmente uma dependência:
Na interface do usuário do notebook, clique no painel lateral Ambiente
.Na seção Dependências , clique em Adicionar Dependência e insira o caminho da dependência no campo. Você pode especificar uma dependência em qualquer formato que seja válido em um arquivo requirements.txt. Arquivos wheel do Python ou projetos de Python (por exemplo, o diretório que contém um
pyproject.tomlou umsetup.py) podem estar localizados em arquivos de área de trabalho ou volumes do Unity Catalog.- Se estiver usando um arquivo de workspace, o caminho deverá ser absoluto e começar com
/Workspace/. - Se estiver usando um arquivo em um volume do Catálogo do Unity, o caminho deverá estar no seguinte formato:
/Volumes/<catalog>/<schema>/<volume>/<path>.whl.
- Se estiver usando um arquivo de workspace, o caminho deverá ser absoluto e começar com
Clique em Aplicar. Isso instala as dependências no ambiente virtual do notebook e reinicia o processo de Python.
Important
Não instale o PySpark ou qualquer biblioteca que instale o PySpark como uma dependência em seus notebooks sem servidor. Isso interromperá sua sessão e resultará em um erro. Se isso ocorrer, remova a biblioteca e redefina seu ambiente.
Para exibir dependências instaladas, clique na guia Instalado no painel lateral Ambientes . Os logs de instalação pip para o ambiente do notebook também estão disponíveis clicando em logs de pip na parte inferior do painel.
Criar uma especificação de ambiente personalizado
Você pode criar e reutilizar especificações de ambiente personalizadas.
- Em um notebook sem servidor, selecione um ambiente base e adicione as dependências que você deseja instalar.
- Clique no ícone do menu kebab
 na parte inferior do painel de ambiente e depois clique em Exportar ambiente.
na parte inferior do painel de ambiente e depois clique em Exportar ambiente. - Salve a especificação como um arquivo de workspace ou em um volume do Catálogo do Unity.
Para usar sua especificação de ambiente personalizado em um notebook, selecione Personalizado no menu suspenso Ambiente base e, em seguida, use o ícone ![]() para selecionar seu arquivo YAML.
para selecionar seu arquivo YAML.
Criar utilitários comuns para compartilhar em seu workspace
O exemplo a seguir mostra como armazenar um utilitário comum em um arquivo de workspace e adicioná-lo como uma dependência em seu notebook sem servidor:
Crie uma pasta com a estrutura a seguir. Verifique se os consumidores do seu projeto têm acesso apropriado ao caminho do arquivo:
helper_utils/ ├── helpers/ │ └── __init__.py # your common functions live here ├── pyproject.tomlPreencha o
pyproject.tomlassim:[project] name = "common_utils" version = "0.1.0"Adicione uma função ao
init.pyarquivo. Por exemplo:def greet(name: str) -> str: return f"Hello, {name}!"Na interface do usuário do notebook, clique no ícone Ambiente do painel lateral
Na seção Dependências , clique em Adicionar Dependência e, em seguida, insira o caminho do arquivo util. Por exemplo:
/Workspace/helper_utils.Clique em Aplicar.
Agora você pode usar a função em seu notebook:
from helpers import greet
print(greet('world'))
A saída é:
Hello, world!
Redefinir as dependências do ambiente
Se o notebook estiver conectado à computação sem servidor, o Databricks armazenará automaticamente em cache o conteúdo do ambiente virtual do notebook. Isso significa que você geralmente não precisa reinstalar as dependências Python especificadas no painel lateral Environment ao abrir um notebook existente, mesmo que ele tenha sido desconectado devido à inatividade.
O armazenamento em cache de ambientes virtuais em Python também se aplica a tarefas. Quando um trabalho é executado, qualquer tarefa do trabalho que compartilha o mesmo conjunto de dependências que uma tarefa concluída nessa execução é mais rápida, pois as dependências necessárias já estão disponíveis.
Note
Se você alterar a implementação de um pacote de Python personalizado usado em um trabalho sem servidor, também deverá atualizar seu número de versão para que os trabalhos possam pegar a implementação mais recente.
Para limpar o cache do ambiente e realizar uma nova instalação das dependências especificadas no painel lateral Ambiente de um notebook conectado à computação sem servidor, clique na seta ao lado de Aplicar e, em seguida, clique em Redefinir para os padrões.
Se você instalar pacotes que quebram ou alteram o notebook principal ou o ambiente do Apache Spark, remova os pacotes ofensivos e redefina o ambiente. Iniciar uma nova sessão não limpa todo o cache do ambiente.
Configurar repositórios de pacote de Python padrão
Os administradores do espaço de trabalho podem configurar repositórios de pacotes privados ou autenticados em espaço de trabalhos como a configuração do Pip padrão para notebooks sem servidor e trabalhos sem servidor. Isso permite que os usuários instalem pacotes de repositórios internos de Python sem definir explicitamente index-url ou extra-index-url.
Para obter instruções, os administradores do workspace podem consultar Configurar repositórios de pacotes Python padrão.
Configurar o ambiente para tarefas de trabalho
Para tipos de tarefa de trabalho, como notebook, script Python, Python roda, JAR ou tarefas dbt, as dependências da biblioteca são herdadas da versão do ambiente sem servidor. Para exibir a lista de bibliotecas instaladas, consulte a seção Installed Python libraryes ou Installed Java and Scala libraryes da versão environment que você está usando. Se uma tarefa exigir uma biblioteca que não esteja instalada, você poderá instalar a biblioteca dos arquivos do workspace, volumes do Catálogo Unity ou de repositórios de pacotes públicos.
Para notebooks com um ambiente de notebook existente, você pode executar a tarefa usando o ambiente do notebook ou substituí-la selecionando um ambiente de nível de trabalho.
Important
O uso da computação sem servidor para tarefas JAR está na Prévia Pública.
Para adicionar uma biblioteca ao criar ou editar uma tarefa de trabalho:
No menu suspenso Ambiente e Bibliotecas , clique em
 ao lado do ambiente Padrão ou clique em + Adicionar novo ambiente.
ao lado do ambiente Padrão ou clique em + Adicionar novo ambiente.
Selecione a versão do ambiente no menu suspenso Versão do ambiente. Veja Versões do ambiente sem servidor. O Databricks recomenda escolher a versão mais recente para obter os recursos mais atualizados.
Na caixa de diálogo Configurar ambiente, clique em + Adicionar biblioteca.
Selecione o tipo de dependência no menu suspenso em Bibliotecas.
Na caixa de texto Caminho do arquivo, insira o caminho para a biblioteca.
- Para uma roda de Python em um arquivo de workspace, o caminho deve ser absoluto e começar com
/Workspace/. - Para um Wheel do Python em um volume do Unity Catalog, o caminho deve ser
/Volumes/<catalog>/<schema>/<volume>/<path>.whl. - Para um arquivo
requirements.txt, selecione PyPi e digite-r /path/to/requirements.txt.

- Para uma roda de Python em um arquivo de workspace, o caminho deve ser absoluto e começar com
Clique em Confirmar ou +Adicionar biblioteca para adicionar outra biblioteca.
Se você estiver adicionando uma tarefa, clique em Criar tarefa. Se você estiver editando uma tarefa, clique em Salvar tarefa.
Ambientes base para tarefas de trabalho
Trabalhos sem servidor dão suporte a ambientes base personalizados definidos com arquivos YAML para tarefas de Python, Python roda e notebook. Para tarefas de notebook, você pode selecionar um ambiente base personalizado na configuração de ambiente da tarefa ou usar as configurações de ambiente do próprio notebook, que dão suporte a ambientes de workspace e ambientes base personalizados. Em todos os casos, somente as dependências necessárias para a tarefa são instaladas em runtime. Você pode selecionar um ambiente base personalizado diretamente nas configurações de ambiente do trabalho. Para criar um ambiente base personalizado, consulte Criar uma especificação de ambiente personalizada.
Ambientes base gerenciados em trabalhos
Important
Esse recurso está em Beta. Os administradores do workspace podem controlar o acesso a esse recurso na página Visualizações . Consulte Gerenciar prévias do Azure Databricks.
Você pode selecionar ambientes base gerenciados diretamente nas configurações de ambiente do trabalho. Isso inclui ambientes base de workspace configurados por um administrador de workspace e ambientes base fornecidos por Azure Databricks, como Standard e AI. Esses são os mesmos ambientes base disponíveis no seletor de ambiente do notebook. Para obter informações sobre como criar e gerenciar ambientes base de workspace, consulte Gerenciar ambientes base de workspace sem servidor.
Ambientes base gerenciados têm suporte para notebook, script Python e tarefas de roda Python. Eles não têm suporte para tarefas JAR.
Compatibilidade de ambiente e computação
O ambiente base selecionado deve ser compatível com o tipo de computação da tarefa. Por exemplo, um ambiente criado para computação de GPU não é compatível com a computação de CPU. Na interface do usuário de tarefas, ambientes incompatíveis são esmaecidos no menu suspenso do ambiente base.
Quando você configura uma tarefa de notebook, o tipo de computação (CPU ou GPU) e o ambiente base podem vir das configurações de trabalho ou do notebook.
- Se você definir uma GPU (acelerador de hardware) no nível do trabalho, também deverá selecionar um ambiente base no nível do trabalho. Você não pode usar o ambiente do notebook com um acelerador de nível de tarefa.
- Se você alterar o tipo de computação do notebook (por exemplo, de CPU para GPU) depois de criar um trabalho que faça referência a ele, as tarefas existentes poderão se tornar incompatíveis com o ambiente configurado. Examine as configurações de ambiente do seu trabalho depois de alterar a configuração de computação do notebook.
- Para usuários de API, se o ambiente base for definido no nível do trabalho, mas o tipo de computação for herdado do notebook, a compatibilidade será validada em tempo de execução e não no momento da criação do trabalho. Se a configuração for incompatível, a execução falhará com um erro.