Observação
O acesso a essa página exige autorização. Você pode tentar entrar ou alterar diretórios.
O acesso a essa página exige autorização. Você pode tentar alterar os diretórios.
APLICA-SE A: Azure Data Factory
Azure Data Factory  Azure Synapse Analytics
Azure Synapse Analytics
Dica
Data Factory no Microsoft Fabric é a próxima geração de Azure Data Factory, com uma arquitetura mais simples, IA interna e novos recursos. Se você não estiver familiarizado com a integração de dados, comece com Fabric Data Factory. As cargas de trabalho existentes do ADF podem ser atualizadas para Fabric para acessar novos recursos em ciência de dados, análise em tempo real e relatórios.
Estruturação de dados refere-se ao processo de transformar e reformatar dados de sua fonte original para deixá-los mais adequados e úteis para diversas aplicações subsequentes.
As organizações precisam ter a capacidade de explorar os dados críticos para seus negócios para a preparação e a estruturação de dados, a fim de obter uma análise precisa dos dados complexos que continuam aumentando diariamente. A preparação de dados é necessária para que as organizações possam usar os dados em vários processos empresariais e reduzir o tempo de retorno.
O Data Factory capacita você com a preparação de dados sem código em escala de nuvem iterativamente usando Power Query. O Data Factory integra-se ao Power Query Online e disponibiliza Power Query M como uma atividade de pipeline.
O Data Factory converte M gerado pelo Editor de Mashup online do Power Query em código spark para execução de escala de nuvem traduzindo M em fluxos de dados Azure Data Factory. A manipulação de dados com Power Query e fluxos de dados é especialmente útil para engenheiros de dados ou "integradores de dados cidadãos".
Casos de uso
Rápida exploração e preparação de dados interativos
Diversos engenheiros de dados e integradores de dados cidadãos podem explorar e preparar conjuntos de dados interativamente em escala de nuvem. Com o aumento de volume, variedade e velocidade de dados em data lakes, os usuários precisam de uma maneira eficaz para explorar e preparar conjuntos de dados. Por exemplo, talvez seja necessário criar um conjunto de dados que tenha todas as informações demográficas de clientes para os novos clientes desde 2017. Você não estará mapeando para um destino conhecido. Você está explorando, estruturando e preparando conjuntos de dados para atender um requisito antes de publicá-los no lake. A estruturação de dados costuma ser usada em cenários de análise menos formais. Os conjuntos de dados preparados podem ser usados para fazer transformações e operações de aprendizado de máquina downstream.
Preparação de dados agile sem código
Os integradores de dados cidadãos gastam mais de 60% do tempo procurando e preparando dados. Eles têm buscado fazer isso de uma maneira livre de códigos para assim melhorar a produtividade operacional. Permitir que os integradores de dados cidadãos enriqueçam, modelem e publiquem dados usando ferramentas conhecidas como Power Query Online de maneira escalonável melhora drasticamente sua produtividade. A manipulação em Azure Data Factory permite o uso do familiar editor de mashup do Power Query Online para que integrações de dados feitas por cidadãos corrijam erros rapidamente, padronizem dados e produzam dados de alta qualidade para dar suporte a decisões de negócios.
Validação e exploração de dados
Examine visualmente seus dados de forma livre de código para remover exceções, anomalias e formá-los para análise rápida.
Fontes suportadas
| Conector | Formato de dados | Tipo de autenticação |
|---|---|---|
| Azure Blob Storage | CSV, Parquet, Excel | Chave de conta, Entidade de Serviço |
| Azure Data Lake Storage Gen1 | CSV, Parquet, Excel | Principal de Serviço, MSI |
| Azure Data Lake Storage Gen2 | CSV, Parquet, Excel | Chave de conta, Entidade de Serviço |
| Banco de Dados SQL do Azure | - | autenticação SQL, MSI, Principal do Serviço |
| Azure Synapse Analytics | - | autenticação SQL, MSI, Principal do Serviço |
O editor de mashup
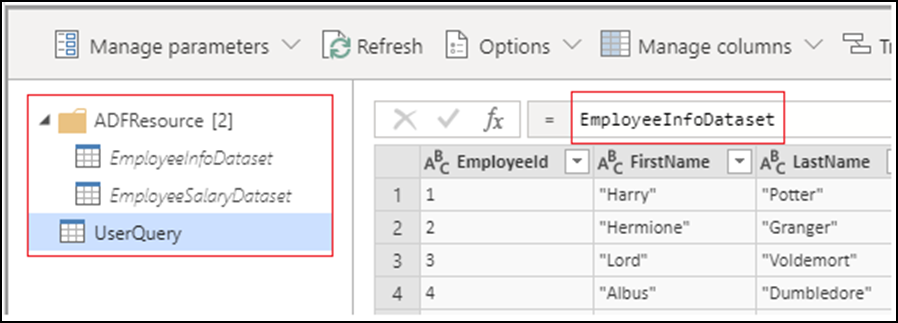
Quando você cria uma atividade Power Query, todos os conjuntos de dados de origem se tornam consultas de conjunto de dados e são colocados na pasta ADFResource. Por padrão, o UserQuery aponta a primeira consulta de conjuntos de dados. Qualquer transformação deve ser feita no UserQuery, pois alterações nas consultas de conjuntos de dados não terão suporte e nem serão persistentes. No momento, não há suporte para a renomeação, a adição ou a exclusão de consultas.
Atualmente, nem todas as funções Power Query M têm suporte para manipulação de dados, ainda que estejam disponíveis durante a fase de desenvolvimento. Ao criar suas atividades de Power Query, a seguinte mensagem de erro será exibida se uma função não for suportada:
The Power Query Spark Runtime does not support the function
Para obter mais informações sobre transformações com suporte, consulte Power Query funções de estruturação de dados.
Conteúdo relacionado
Saiba como criar um mashup de estruturação de dados do Power Query.