Observação
O acesso a essa página exige autorização. Você pode tentar entrar ou alterar diretórios.
O acesso a essa página exige autorização. Você pode tentar alterar os diretórios.
APLICA-SE A: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Dica
Data Factory no Microsoft Fabric é a próxima geração de Azure Data Factory, com uma arquitetura mais simples, IA interna e novos recursos. Se você não estiver familiarizado com a integração de dados, comece com Fabric Data Factory. As cargas de trabalho existentes do ADF podem ser atualizadas para Fabric para acessar novos recursos em ciência de dados, análise em tempo real e relatórios.
Os fluxos de dados estão disponíveis em os pipelines do Azure Data Factory e os pipelines do Azure Synapse Analytics. Este artigo se aplica ao fluxo de dados de mapeamento. Se você for novo em transformações, consulte o artigo introdutório Transformar dados usando fluxos de dados de mapeamento.
Use a transformação de flowlet para executar um flowlet de fluxo de dados de mapeamento criado anteriormente. Para ter uma visão geral dos fluxolets, confira Flowlets no fluxo de dados de mapeamento | Microsoft Docs
Observação
A transformação de flowlet em pipelines Azure Data Factory e Synapse Analytics está em versão prévia pública
Configuração
A transformação de flowlet contém as seguintes configurações
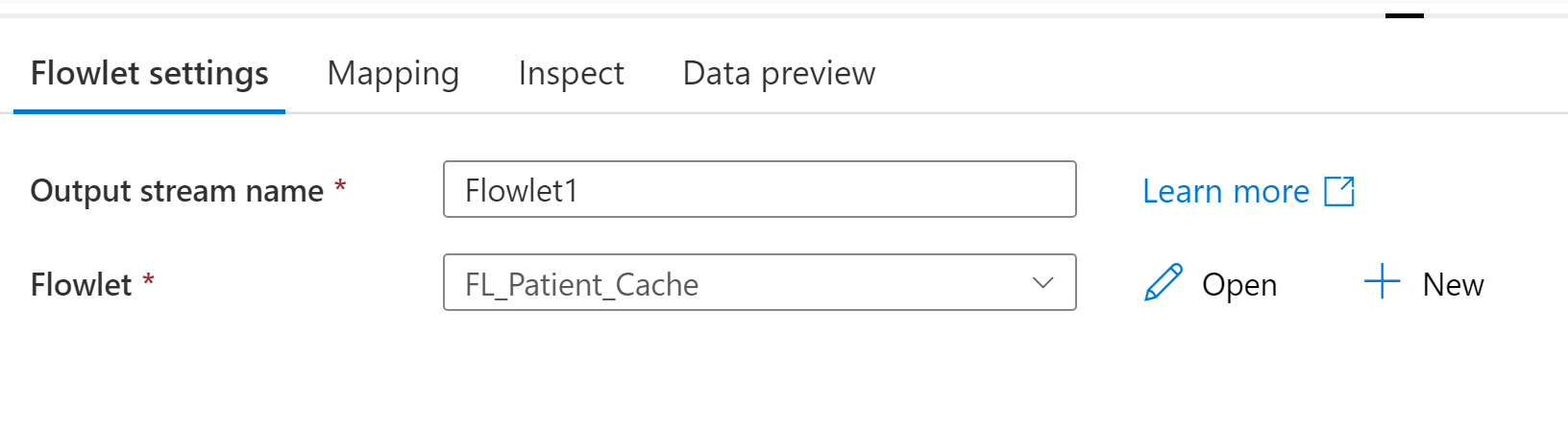
Flowlet
Selecione o flowlet para executar. Depois que o flowlet for selecionado, você poderá mapear colunas de entrada, se houver, na guia de mapeamento.
Mapeamento
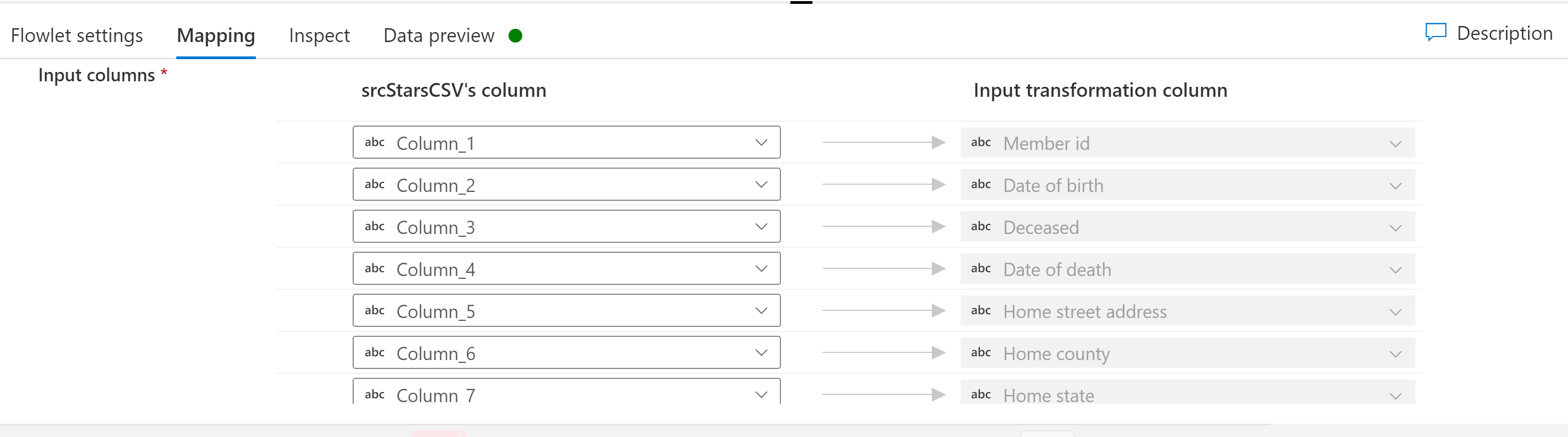
Se o flowlet selecionado tiver colunas de entrada, você poderá mapear colunas do fluxo de entrada para as colunas de entrada esperadas no flowlet. Esse mapeamento de suas colunas de fluxos de dados de mapeamento para o flowlet é o que permite que os flowlets sirva como snippets reutilizáveis da lógica de fluxo de dados de mapeamento entre potencialmente muitos fluxos de dados de mapeamento.
Script de fluxo de dados
Sintaxe
<incomingStream>
<transformation> ~> <transformationName>
<outputStream>
Exemplo
source1 derive(Test = "test") ~> DerivedColumn1
DerivedColumn1 output() ~> output1