Observação
O acesso a essa página exige autorização. Você pode tentar entrar ou alterar diretórios.
O acesso a essa página exige autorização. Você pode tentar alterar os diretórios.
APPLIES TO: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Dica
Data Factory no Microsoft Fabric é a próxima geração de Azure Data Factory, com uma arquitetura mais simples, IA interna e novos recursos. Se você não estiver familiarizado com a integração de dados, comece com Fabric Data Factory. As cargas de trabalho existentes do ADF podem ser atualizadas para Fabric para acessar novos recursos em ciência de dados, análise em tempo real e relatórios.
Os fluxos de dados estão disponíveis em pipelines Azure Data Factory e pipelines de Azure Synapse Analytics. Este artigo se aplica ao fluxo de dados de mapeamento. Se você for novo em transformações, consulte o artigo introdutório Transformar dados usando fluxos de dados de mapeamento.
A transformação de ocorrências é uma transformação de filtragem de linha que verifica se os dados existem em outra fonte ou fluxo. O fluxo de saída inclui todas as linhas no fluxo à esquerda que existem ou não existem no fluxo correto. A transformação de ocorrências é semelhante a SQL WHERE EXISTS e SQL WHERE NOT EXISTS.
Configuração
- Escolha o fluxo de dados cuja ocorrência você está verificando na lista suspensa Fluxo à direita.
- Especifique se você está procurando os dados existentes ou não existentes na configuração Tipo de ocorrência.
- Selecione se deseja ou não uma Expressão personalizada.
- Escolha quais colunas de chave você deseja comparar como condições de ocorrência. Por padrão, o fluxo de dados procura igualdade entre uma coluna em cada fluxo. Para comparar por meio de um valor calculado, passe o mouse sobre a lista suspensa da coluna e selecione Coluna computada.
Várias condições de ocorrência
Para comparar várias colunas de cada fluxo, adicione uma nova condição de ocorrência clicando no ícone de adição ao lado de uma linha existente. Cada condição adicional é unida por uma instrução "and". Comparar duas colunas é o mesmo que a seguinte expressão:
source1@column1 == source2@column1 && source1@column2 == source2@column2
Expressão personalizada
Para criar uma expressão de forma livre que contenha operadores diferentes de "and" e "equals to", selecione o campo Expressão personalizada. Insira uma expressão personalizada por meio do construtor de expressões de fluxo de dados clicando na caixa azul.

Se você estiver criando padrões dinâmicos em seus fluxos de dados usando a "associação tardia" de colunas por meio do descompasso de esquema, poderá usar a função de expressão byName() para usar a transformação existente sem embutir em código (ou seja, fazer a associação antecipada) os nomes de coluna. Exemplo: toString(byName('ProductNumber','source1')) == toString(byName('ProductNumber','source2'))
Otimização de transmissão

Em transformação de junções, pesquisas e ocorrências, se um ou ambos os fluxos de dados se ajustarem à memória do nó de trabalho, você poderá otimizar o desempenho habilitando a Difusão. Por padrão, o mecanismo do Spark decidirá automaticamente se deseja ou não transmitir um lado. Para escolher manualmente o lado a ser transmitido, selecione Fixo.
Não é recomendável desabilitar a transmissão por meio da opção Desativar, a menos que suas uniões estejam tendo erros de tempo limite.
Script de fluxo de dados
Sintaxe
<leftStream>, <rightStream>
exists(
<conditionalExpression>,
negate: { true | false },
broadcast: { 'auto' | 'left' | 'right' | 'both' | 'off' }
) ~> <existsTransformationName>
Exemplo
O exemplo abaixo é uma transformação de ocorrência chamada checkForChanges que usa NameNorm2 como fluxo à esquerda e TypeConversions como fluxo à direita. A condição de ocorrência é a expressão NameNorm2@EmpID == TypeConversions@EmpID && NameNorm2@Region == DimEmployees@Region que retorna true se houver correspondência entre as colunas EMPID e Region de cada fluxo. Como estamos verificando a ocorrência, negate é false. Não estamos habilitando nenhuma difusão na guia otimizar, portanto, broadcast tem valor 'none'.
Na experiência de interface do usuário, essa transformação é semelhante à imagem abaixo:
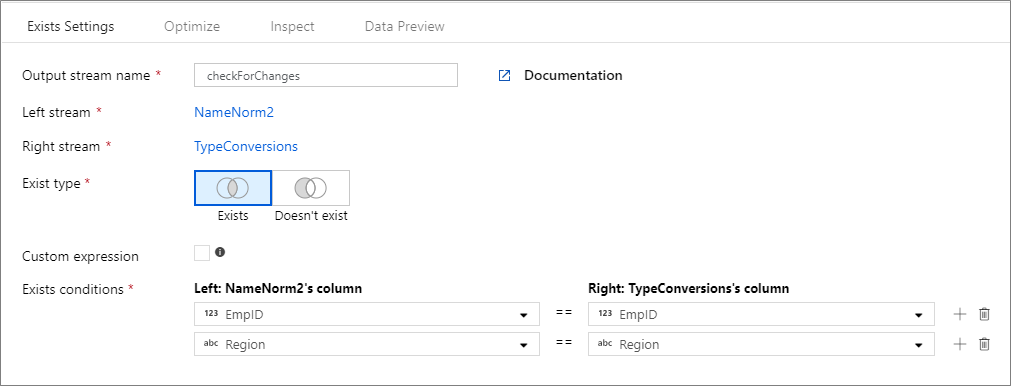
O script de fluxo de dados para essa transformação está no trecho de código abaixo:
NameNorm2, TypeConversions
exists(
NameNorm2@EmpID == TypeConversions@EmpID && NameNorm2@Region == DimEmployees@Region,
negate:false,
broadcast: 'auto'
) ~> checkForChanges