Gebeurtenisverwerking begrijpen
Azure Stream Analytics is een service voor complexe gebeurtenisverwerking en analyse van streaminggegevens. Stream Analytics wordt gebruikt voor het volgende:
- Gegevens opnemen uit een invoer, zoals een Azure Event Hub, Azure IoT Hub of Azure Storage-blobcontainer.
- De gegevens verwerken met behulp van een query om gegevenswaarden te selecteren, te projecteren en samen te voegen.
- Schrijf de resultaten naar een uitvoer, zoals Azure Data Lake Storage Gen2, Azure SQL Database, Azure Cosmos DB, Azure Functions, Azure Event Hubs, Microsoft Power BI of andere.
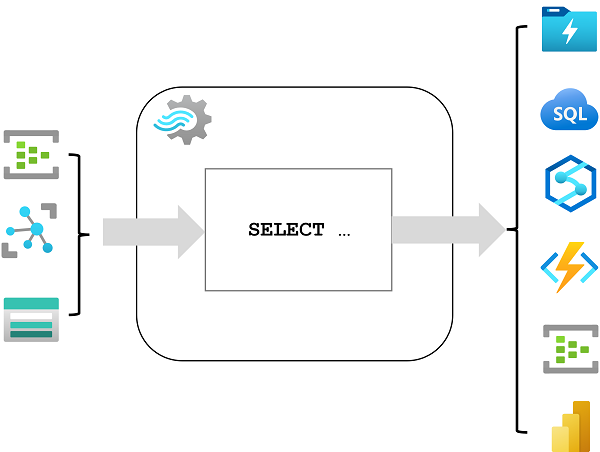
Zodra deze is gestart, wordt een Stream Analytics-query voortdurend uitgevoerd, waarbij nieuwe gegevens worden verwerkt wanneer deze binnenkomen in de invoer en resultaten opslaan in de uitvoer.
Stream Analytics garandeert precies één gebeurtenisverwerking en ten minste eenmaal uitgevoerde levering van gebeurtenissen, zodat gebeurtenissen nooit verloren gaan. Het heeft ingebouwde herstelmogelijkheden voor het geval het bezorgen van een gebeurtenis mislukt. Stream Analytics biedt ook ingebouwde controlepunten om de status van uw taak te behouden en herhaalbare resultaten te produceren. Omdat Azure Stream Analytics een PaaS-oplossing (platform-as-a-service) is, wordt deze volledig beheerd en zeer betrouwbaar. De ingebouwde integratie met verschillende bronnen en bestemmingen en biedt een flexibel programmeermodel. De Stream Analytics-engine maakt berekeningen in het geheugen mogelijk, zodat deze hoge prestaties biedt.
Azure Stream Analytics-taken en clusters
De eenvoudigste manier om Azure Stream Analytics te gebruiken, is door een Stream Analytics-taak te maken in een Azure-abonnement, de invoer(en) en uitvoer(en) te configureren en de query te definiëren die door de taak wordt gebruikt om de gegevens te verwerken. De query wordt uitgedrukt met behulp van sql-syntaxis (Structured Query Language) en kan statische referentiegegevens uit meerdere gegevensbronnen bevatten om opzoekwaarden op te geven die kunnen worden gecombineerd met de streaminggegevens die zijn opgenomen uit een invoer.
Als uw stroomprocesvereisten complex of resource-intensief zijn, kunt u een Stream Analysis-cluster maken dat gebruikmaakt van dezelfde onderliggende verwerkingsengine als een Stream Analytics-taak, maar in een toegewezen tenant (zodat uw verwerking niet wordt beïnvloed door andere klanten) en met configureerbare schaalbaarheid waarmee u de juiste balans tussen doorvoer en kosten voor uw specifieke scenario kunt definiëren.
Invoer
Azure Stream Analytics kan gegevens opnemen uit de volgende soorten invoer:
- Azure Event Hubs
- Azure IoT Hub
- Azure Blob-opslag
- Azure Data Lake Storage Gen2
- Apache Kafka
Invoer wordt doorgaans gebruikt om te verwijzen naar een bron van streaminggegevens, die worden verwerkt als nieuwe gebeurtenisrecords worden toegevoegd. Daarnaast kunt u verwijzingsinvoer definiëren die worden gebruikt om statische gegevens op te nemen om de realtime gebeurtenisstreamgegevens te verbeteren. U kunt bijvoorbeeld een stroom realtime weerobservatiegegevens opnemen die een unieke id voor elk weerstation bevatten en die gegevens uitbreiden met een statische referentie-invoer die overeenkomt met de id van het weerstation naar een zinvollere naam.
Uitgangen
Uitvoer zijn bestemmingen waarnaar de resultaten van de stroomverwerking worden verzonden. Azure Stream Analytics biedt ondersteuning voor een breed scala aan uitvoersinks, die kunnen worden gebruikt voor het volgende:
- Permanente resultaten voor verdere analyse; Bijvoorbeeld door te schrijven naar Azure Data Lake Storage Gen2, Azure SQL Database of Azure Cosmos DB.
- Logboek- en telemetriegegevens op schaal analyseren; Bijvoorbeeld door resultaten te verzenden naar Azure Data Explorer.
- Een realtime visualisatie van de gegevensstroom weergeven; Bijvoorbeeld door gegevens toe te voegen aan een gegevensset in Microsoft Power BI.
- Gefilterde of samengevatte gebeurtenissen genereren voor downstreamverwerking; Bijvoorbeeld door resultaten naar Azure Event Hubs te schrijven.
Opvragen
De logica voor stroomverwerking wordt ingekapseld in een query. Query's worden gedefinieerd met behulp van SQL-instructies die gegevensvelden SELECTERENUIT een of meer invoergegevens, de gegevens filteren of aggregeren en de resultaten naar een uitvoer schrijven. De volgende query filtert bijvoorbeeld de gebeurtenissen uit de invoer van weergebeurtenissen om alleen gegevens van gebeurtenissen met een temperatuurwaarde kleiner dan 0 op te nemen en schrijft de resultaten naar de uitvoer van cold-temps :
SELECT observation_time, weather_station, temperature
INTO cold-temps
FROM weather-events TIMESTAMP BY observation_time
WHERE temperature < 0
Er wordt automatisch een veld met de naam EventProcessedUtcTime gemaakt om het tijdstip te definiëren waarop de gebeurtenis wordt verwerkt door uw Azure Stream Analytics-query. U kunt dit veld gebruiken om de tijdstempel van de gebeurtenis te bepalen of u kunt expliciet een ander Datum/tijd-veld opgeven met behulp van de TIMESTAMP BY-component , zoals wordt weergegeven in dit voorbeeld. Afhankelijk van de invoer van waaruit de streaminggegevens worden gelezen, kunnen een of meer potentiële tijdstempelvelden automatisch worden gemaakt; Wanneer u bijvoorbeeld een Event Hubs-invoer gebruikt, wordt een veld met de naam EventQueuedUtcTime gegenereerd om het tijdstip vast te leggen waarop de gebeurtenis is ontvangen in de Event Hub-wachtrij.
Het veld dat wordt gebruikt als een tijdstempel is belangrijk bij het samenvoegen van gegevens via tijdelijke vensters, wat hierna wordt besproken.
Geen code-editor
Als u liever uw streamverwerkingstaak bouwt zonder SQL te schrijven, bevat Azure Stream Analytics een editor zonder code. U kunt deze openen via de Azure Stream Analytics-portal of de Azure Event Hubs-portal. De no-code-editor biedt een canvas voor slepen en neerzetten waarin u invoerbronnen verbindt, transformaties toevoegt (inclusief vensters en aggregaties) en uitvoer configureert zonder code te schrijven.
U kunt de editor zonder code gebruiken om snel een prototype te maken en vervolgens de gegenereerde SQL-query voor geavanceerdere scenario's weer te geven of aan te passen.