Notitie
Voor toegang tot deze pagina is autorisatie vereist. U kunt proberen u aan te melden of de directory te wijzigen.
Voor toegang tot deze pagina is autorisatie vereist. U kunt proberen de mappen te wijzigen.
Belangrijk
Deze functie is beschikbaar als preview-versie.
Fabric Runtime biedt naadloze integratie binnen het Microsoft Fabric-ecosysteem en biedt een robuuste omgeving voor data engineering- en data science-projecten die mogelijk worden gemaakt door Apache Spark.
In dit artikel maakt u kennis met Fabric Runtime 2.0 Public Preview, de nieuwste runtime die is ontworpen voor big data-berekeningen in Microsoft Fabric. Het markeert de belangrijkste functies en onderdelen die deze release een belangrijke stap voorwaarts maken voor schaalbare analyses en geavanceerde workloads.
Fabric Runtime 2.0 bevat de volgende onderdelen en upgrades die zijn ontworpen om uw gegevensverwerkingsmogelijkheden te verbeteren:
- Apache Spark 4.0
- Besturingssysteem: Azure Linux 3.0 (Mariner 3.0)
- Java: 21
- Scala: 2.13
- Python: 3.12
- Delta Lake: 4.0
- R: 4.5.2
Aanbeveling
Fabric Runtime 2.0 bevat ondersteuning voor de systeemeigen uitvoeringsengine, die de prestaties aanzienlijk kan verbeteren zonder meer kosten. U kunt de systeemeigen uitvoeringsengine op omgevingsniveau inschakelen, zodat alle taken en notebooks automatisch de verbeterde prestatiemogelijkheden overnemen.
Runtime 2.0 inschakelen
U kunt Runtime 2.0 inschakelen op werkruimteniveau of op het itemniveau van de omgeving. Gebruik de werkruimte-instelling om Runtime 2.0 toe te passen als de standaardinstelling voor alle Spark-workloads in uw werkruimte. U kunt ook een omgevingsitem maken met Runtime 2.0 voor gebruik met specifieke notebooks of Spark-taakdefinities, waardoor de standaardinstelling van de werkruimte wordt overschreven.
Runtime 2.0 inschakelen in werkruimte-instellingen
Runtime 2.0 instellen als de standaardinstelling voor uw hele werkruimte:
Navigeer naar de pagina Werkruimte-instellingen in uw Fabric-werkruimte.
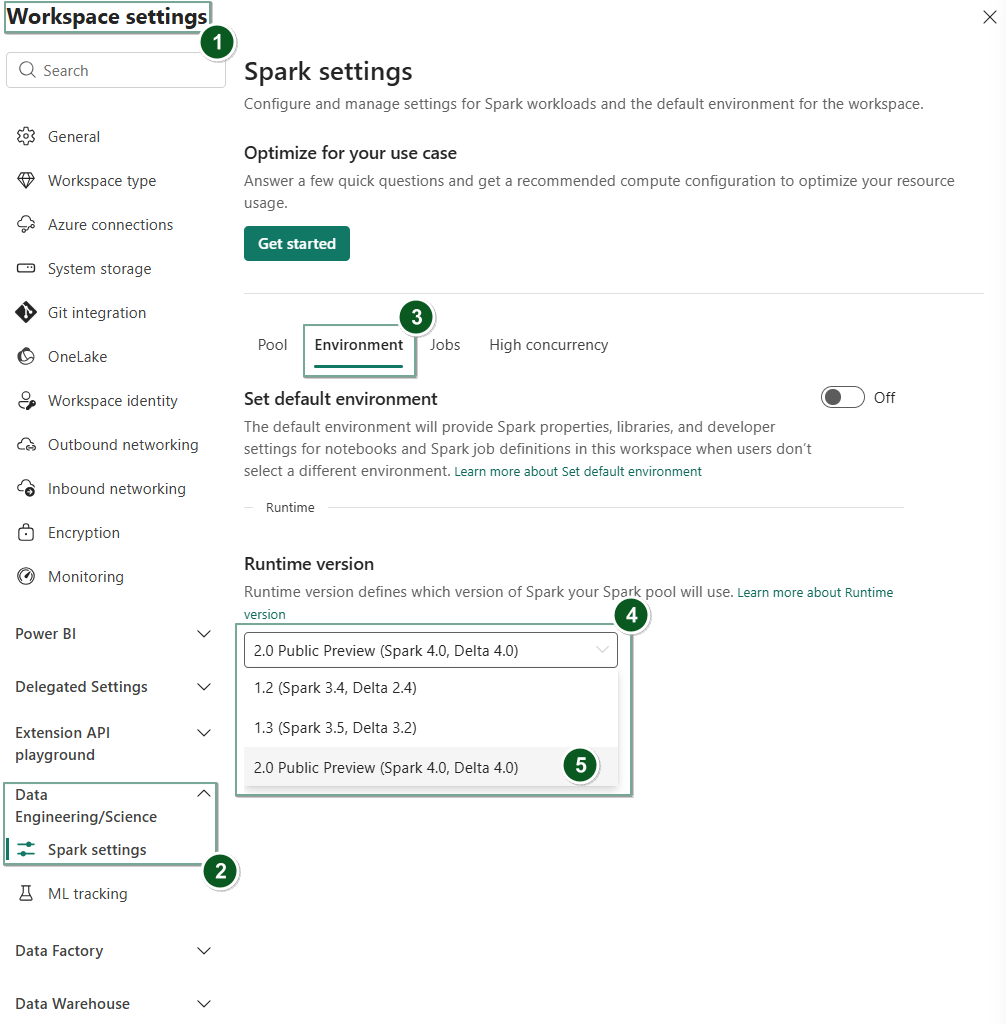
Selecteer het tabblad Data Engineering/Science en selecteer vervolgens Spark-instellingen.
Selecteer het tabblad Omgeving.
Selecteer onder de vervolgkeuzelijst runtimeversie de optie 2.0 Openbare preview (Spark 4.0, Delta 4.0) en sla uw wijzigingen op.
Runtime 2.0 is ingesteld als de standaardruntime voor uw werkruimte.

Runtime 2.0 inschakelen in een omgevingselement
Runtime 2.0 gebruiken met specifieke notebooks of Spark-taakdefinities:
Maak een nieuwe omgeving of open een bestaande.
Selecteer in de vervolgkeuzelijst Runtime de 2.0 Openbare preview (Spark 4.0, Delta 4.0)
Saveen bevestigPublishuw wijzigingen.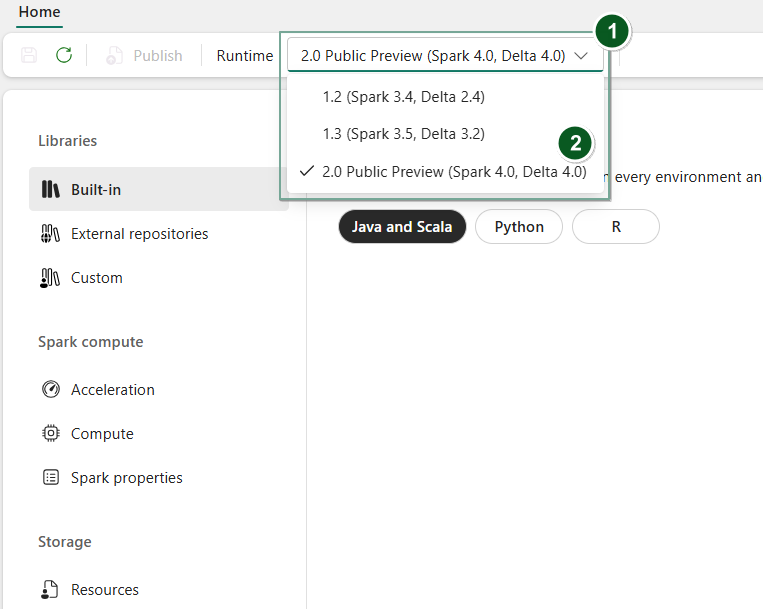
Vervolgens kunt u deze omgeving gebruiken met uw
NotebookofSpark Job Definition.

U kunt nu experimenteren met de nieuwste verbeteringen en functionaliteiten die zijn geïntroduceerd in Fabric Runtime 2.0 (Spark 4.0 en Delta Lake 4.0).
Aanbeveling
Het opstarten van de eerste Spark-sessie voor Runtime 2.0 kan enkele minuten duren tijdens de openbare preview. Als u de vertragingen bij koude starts wilt verminderen, gebruikt u Aangepaste Live Pools (preview) om de Spark-pools voor te verwarmen, of configureert u Resourceprofielen om resources van tevoren toe te wijzen.
Opmerking
Het WASB-protocol voor Azure Storage-accounts voor algemeen gebruik v2 (GPv2) is afgeschaft. U moet in plaats daarvan het nieuwste ABFS-protocol gebruiken voor het lezen van en schrijven naar GPv2-opslagaccounts.
Openbare preview
De openbare preview-fase van Fabric Runtime 2.0 biedt u toegang tot nieuwe functies en API's van zowel Spark 4.0 als Delta Lake 4.0. Met de preview kunt u de nieuwste verbeteringen op basis van Spark en Delta direct gebruiken en zorgen voor een soepele gereedheid en overgang voor verbeterde en verbeterde wijzigingen, zoals de nieuwere Java-, Scala- en Python-versies.
Aanbeveling
Voor actuele informatie, een gedetailleerde lijst met wijzigingen en specifieke releaseopmerkingen voor Fabric-runtimes, controleer en abonneer je op Spark Runtime-releases en -updates.
Belangrijke hoogtepunten
Verbeteringen van de prestatie- en uitvoeringsengine
Fabric Runtime 2.0 bevat de systeemeigen uitvoeringsengine, die aanzienlijke prestatieverbeteringen biedt ten opzichte van opensource Spark. De engine maakt gebruik van gevectoriseerde verwerking om Spark-query's op lakehouse-infrastructuur te versnellen zonder dat er codewijzigingen nodig zijn.
Belangrijke prestatiefuncties in Runtime 2.0:
- Tot zes keer sneller: Benchmarks worden zes keer sneller weergegeven in vergelijking met opensource Spark op TPC-DS workloads.
- Gevectoriseerde CSV-parsering: de systeemeigen uitvoeringsengine bevat een gevectoriseerde CSV-parser waarmee CSV-opname en queryworkloads worden versneld. Gevectoriseerde JSON-parsering en spark Structured Streaming-ondersteuning zijn gepland voor toekomstige updates.
Als u de systeemeigen uitvoeringsengine wilt inschakelen, raadpleegt u de systeemeigen uitvoeringsengine voor Fabric Data Engineering.
Apache Spark 4.0
Apache Spark 4.0 markeert een belangrijke mijlpaal als de inaugurele release in de 4.x-serie, die de collectieve inspanning van de levendige opensource-community bekrachtigt.
In deze versie is Spark SQL aanzienlijk verrijkt met krachtige nieuwe functies die zijn ontworpen om expressiviteit en veelzijdigheid voor SQL-workloads te verbeteren, zoals ondersteuning voor VARIANT-gegevenstypen, door de gebruiker gedefinieerde SQL-functies, sessievariabelen, pijpsyntaxis en tekenreekssortering. PySpark ziet continue toewijding aan zowel de functionele breedte als de algehele ontwikkelaarservaring, waarbij een systeemeigen plotting-API, een nieuwe Python-gegevensbron-API, ondersteuning voor Python UDTFs en geïntegreerde profilering voor PySpark UDF's wordt geboden, naast tal van andere verbeteringen. Structured Streaming ontwikkelt zich met belangrijke toevoegingen die meer controle en eenvoudigere foutopsporing bieden, met name de introductie van de Willekeurige status-API v2 voor flexibeler statusbeheer en de statusgegevensbron voor eenvoudiger foutopsporing.
U kunt hier de volledige lijst en gedetailleerde wijzigingen controleren: https://spark.apache.org/releases/spark-release-4-0-0.html.
Opmerking
In Spark 4.0 is SparkR afgeschaft en mogelijk verwijderd in een toekomstige versie.
Delta Lake 4.0
Delta Lake 4.0 markeert een collectieve toezegging om Delta Lake interoperabel te maken tussen verschillende indelingen, gemakkelijker te werken en beter te presteren. Delta 4.0 is een mijlpaalrelease met krachtige nieuwe functies, prestatieoptimalisaties en fundamentele verbeteringen voor de toekomst van open data lakehouses.
U kunt hier de volledige lijst en gedetailleerde wijzigingen bekijken die zijn geïntroduceerd met Delta Lake 3.3 en 4.0: https://github.com/delta-io/delta/releases/tag/v3.3.0. https://github.com/delta-io/delta/releases/tag/v4.0.0.
Gegevensindeling en optimalisatie
Runtime 2.0 ondersteunt functies voor gegevensindeling en optimalisatie voor Delta-tabellen:
- Z-volgorde: organiseer gegevens in Delta-tabelbestanden op basis van opgegeven kolommen om de queryprestaties voor gefilterde query's te verbeteren.
- Liquid Clustering: Een flexibele clusteringbenadering waarmee de gegevensindeling automatisch wordt geoptimaliseerd zonder handmatig onderhoud.
- Parallel laden van Delta-momentopnamen: met de systeemeigen uitvoeringsengine worden momentopnamen van Delta-tabellen parallel geladen, waardoor de opstarttijd van query's voor grote tabellen wordt verminderd.
Belangrijk
Delta Lake 4.0-specifieke functies zijn experimenteel en werken alleen aan Spark-ervaringen, zoals notebooks en Spark-taakdefinities. Als u dezelfde Delta Lake-tabellen wilt gebruiken voor meerdere Microsoft Fabric-workloads, schakelt u deze functies niet in. Lees de interoperabiliteit van Delta Lake-tabelindelingen voor meer informatie over welke protocolversies en -functies compatibel zijn in alle Microsoft Fabric-ervaringen.
Compute-beheer in Runtime 2.0
Runtime 2.0 ondersteunt de volgende functies voor rekenbeheer:
- Resourceprofielen: vooraf gedefinieerde resourcetoewijzingen configureren voor Spark-sessies om aan de workloadvereisten te voldoen en de kosten te beheren.
- Aangepaste livepools (preview): maak toegewezen, vooraf verwarmde Spark-pools die de opstarttijd van de sessie verminderen. Aangepaste livepools zijn beschikbaar in preview voor Runtime 2.0-workloads.
Beperkingen en opmerkingen
- Delta Lake 4.0-specifieke functies zijn experimenteel en werken alleen aan Spark-ervaringen, zoals notebooks en Spark-taakdefinities. Als u dezelfde Delta Lake-tabellen wilt gebruiken voor meerdere Fabric-workloads, schakelt u deze functies niet in. Zie de interoperabiliteit van delta lake-tabelindelingen voor meer informatie.
- Runtime 2.0 is beschikbaar als openbare preview. Sommige functies en API's kunnen vóór algemene beschikbaarheid veranderen.
- De VS Code-extensie voor Fabric Spark ondersteunt Runtime 2.0 voor het ontwikkelen van notebooks en Spark-taakdefinities.
Verwante inhoud
- Apache Spark Runtimes in Fabric : overzicht, versiebeheer en ondersteuning voor meerdere runtimes
- Spark Core-migratiehandleiding
- Migratiehandleidingen voor SQL, Gegevenssets en DataFrame
- Migratiehandleiding voor gestructureerd streamen
- Migratiehandleiding voor MLlib (Machine Learning)
- Migratiehandleiding voor PySpark (Python op Spark)
- Migratiehandleiding voor SparkR (R in Spark)