Notitie
Voor toegang tot deze pagina is autorisatie vereist. U kunt proberen u aan te melden of de directory te wijzigen.
Voor toegang tot deze pagina is autorisatie vereist. U kunt proberen de mappen te wijzigen.
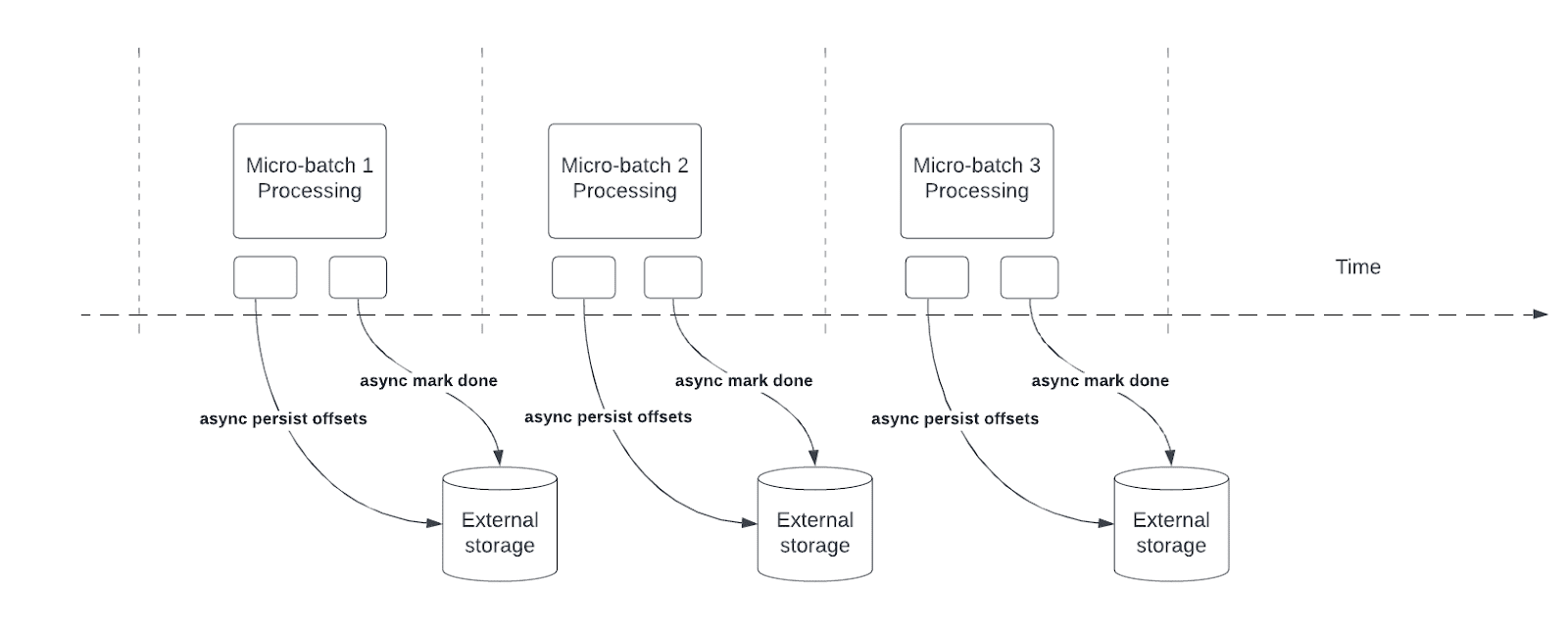
Asynchrone voortgangstracering vermindert de latentie voor Structured Streaming-pijplijnen door query's in staat te stellen de voortgang van controlepunten asynchroon bij te werken en gegevens in elke microbatch te verwerken.
Tijdens het verwerken van queries houdt Structured Streaming offsets vast en beheert deze om de voortgang van queries in offsetLog en commitLog in elke microbatch te meten. Zonder asynchrone voortgangstracering hebben offsetbeheerbewerkingen rechtstreeks invloed op de verwerkingslatentie, omdat gegevensverwerking pas kan worden voortgezet als ze zijn voltooid.
Notitie
Asynchrone voortgangstracering is niet compatibel met Trigger.once of Trigger.availableNow triggers. Indien ingeschakeld mislukken gestructureerde streaming-query's met Trigger.once of Trigger.availableNow.
Configuratieopties
| Optie | Verstek | Beschrijving |
|---|---|---|
asyncProgressTrackingEnabled |
false |
Of u asynchrone voortgangstracering wilt inschakelen. |
asyncProgressTrackingCheckpointIntervalMs |
1000 |
Het interval in milliseconden tussen schrijfbewerkingen voor offsets en voltooiingscommits. |
Asynchrone voortgangstracering inschakelen
Als u asynchrone voortgangstracering wilt inschakelen, stelt u asyncProgressTrackingEnabled in op true.
Python
stream = (spark.readStream
.format("kafka")
.option("kafka.bootstrap.servers", "host1:port1,host2:port2")
.option("subscribe", "in")
.load()
)
query = (stream.writeStream
.format("kafka")
.option("topic", "out")
.option("checkpointLocation", "/tmp/checkpoint")
.option("asyncProgressTrackingEnabled", "true")
.start()
)
Scala
val stream = spark.readStream
.format("kafka")
.option("kafka.bootstrap.servers", "host1:port1,host2:port2")
.option("subscribe", "in")
.load()
val query = stream.writeStream
.format("kafka")
.option("topic", "out")
.option("checkpointLocation", "/tmp/checkpoint")
.option("asyncProgressTrackingEnabled", "true")
.start()
Doorvoer verbeteren met controlepuntfrequentie
De standaardfrequentie van het controlepunt is 1000 milliseconden en biedt een goede doorvoer voor de meeste query's. Wanneer offsetbeheerbewerkingen sneller plaatsvinden dan asynchrone voortgangstracering deze kan verwerken, ontstaat er een achterstand van offsetbeheerbewerkingen. Om te voorkomen dat de achterstand verder groeit, kan het bijhouden van asynchrone voortgang de verwerking van gegevens blokkeren of vertragen, waardoor de verwachte voordelen van lage latentie mogelijk worden aangetast.
In dit scenario raadt Databricks u aan om het controlepuntinterval te verhogen:
Python
query = (stream.writeStream
.format("kafka")
.option("topic", "out")
.option("checkpointLocation", "/tmp/checkpoint")
.option("asyncProgressTrackingEnabled", "true")
.option("asyncProgressTrackingCheckpointIntervalMs", "5000")
.start()
)
Scala
val query = stream.writeStream
.format("kafka")
.option("topic", "out")
.option("checkpointLocation", "/tmp/checkpoint")
.option("asyncProgressTrackingEnabled", "true")
.option("asyncProgressTrackingCheckpointIntervalMs", "5000")
.start()
Notitie
De hersteltijd voor fouten neemt toe met de intervaltijd van het controlepunt. In geval van een fout moet een pijplijn alle gegevens opnieuw verwerken sinds het vorige geslaagde controlepunt. Voordat u deze wijziging in productie aanbrengt, moet u rekening houden met de afweging tussen een lagere latentie tijdens de reguliere verwerking in vergelijking met de hersteltijd in het geval van een storing.
Asynchrone voortgangstracering uitschakelen
Wanneer asynchrone voortgangstracering is ingeschakeld, garandeert de stream geen controlepuntvoortgang voor elke batch. U moet de voortgang bij het controlepunt vastleggen voordat u deze functie kunt uitschakelen.
Voer de volgende stappen uit om uit te schakelen:
Ten minste twee microbatches verwerken met
asyncProgressTrackingEnabledingesteld optrueenasyncProgressTrackingCheckpointIntervalMsingesteld op0:Python
query = (stream.writeStream .format("kafka") .option("topic", "out") .option("checkpointLocation", "/tmp/checkpoint") .option("asyncProgressTrackingEnabled", "true") .option("asyncProgressTrackingCheckpointIntervalMs", "0") .start() )Scala
val query = stream.writeStream .format("kafka") .option("topic", "out") .option("checkpointLocation", "/tmp/checkpoint") .option("asyncProgressTrackingEnabled", "true") .option("asyncProgressTrackingCheckpointIntervalMs", "0") .start()Stop de query:
Python
query.stop()Scala
query.stop()Schakel het bijhouden van asynchrone voortgang uit en start de query opnieuw op:
Python
query = (stream.writeStream .format("kafka") .option("topic", "out") .option("checkpointLocation", "/tmp/checkpoint") .option("asyncProgressTrackingEnabled", "false") .start() )Scala
val query = stream.writeStream .format("kafka") .option("topic", "out") .option("checkpointLocation", "/tmp/checkpoint") .option("asyncProgressTrackingEnabled", "false") .start()
Als u asynchrone voortgangstracking uitschakelt zonder de bovenstaande stappen te volgen, kan de volgende fout optreden:
java.lang.IllegalStateException: batch x doesn't exist
In de stuurprogrammalogboeken ziet u mogelijk de volgende fout:
The offset log for batch x doesn't exist, which is required to restart the query from the latest batch x from the offset log. Please ensure there are two subsequent offset logs available for the latest batch via manually deleting the offset file(s). Please also ensure the latest batch for commit log is equal or one batch earlier than the latest batch for offset log.
Limitations
- Voor Kafka-sinks ondersteunt asynchrone voortgangsbewaking alleen staatloze pijplijnen.
- Asynchrone voortgangstracering garandeert geen exacte eenmalige end-to-end verwerking, omdat offsetbereiken voor een batch kunnen veranderen bij een fout. Sommige sinks, zoals Kafka, bieden nooit precies één keer garanties.