Notitie
Voor toegang tot deze pagina is autorisatie vereist. U kunt proberen u aan te melden of de directory te wijzigen.
Voor toegang tot deze pagina is autorisatie vereist. U kunt proberen de mappen te wijzigen.
Belangrijk
Lakebase Autoscaling is de nieuwste versie van Lakebase, met automatisch schalen van rekenkracht, schaal-tot-nul, branching-functionaliteit en direct herstellen. Zie Beschikbaarheid van regio's voor ondersteunde regio's. Als u een door Lakebase ingericht gebruiker bent, raadpleegt u Lakebase Ingericht.
Aan het einde van deze handleiding hebt u een actieve Postgres-database met voorbeeldgegevens, verbonden met Unity Catalog, met gegevens die stromen tussen Lakebase en het Databricks Lakehouse.
Stappen: (1) Een project maken → (2) Connect → (3) Create a table → (4) Register in Unity Catalog → (5) Serve data
Stap 1: Uw eerste project maken
Open de Lakebase-app vanuit de switcher voor apps.

Selecteer Automatisch schalen om toegang te krijgen tot de gebruikersinterface voor automatisch schalen van Lakebase.
Klik op Nieuw project. Geef uw project een naam en selecteer uw Postgres-versie. Uw project wordt gemaakt met één production vertakking, een standaarddatabase databricks_postgres en rekenresources die zijn geconfigureerd voor de vertakking.

Het kan even duren voordat uw rekenproces is geactiveerd. De berekening voor de production vertakking is altijd ingeschakeld (schaal-naar-nul is uitgeschakeld), maar u kunt deze instelling zo nodig configureren.
De regio voor uw project wordt automatisch ingesteld op uw werkruimteregio.
Meer informatie: Een project maken | Autoscaling | Opschaling naar nul
Stap 2: Verbinding maken met uw database
Selecteer in uw project de productiebranch en klik op Verbinden. Verbindingsreeksen werken met elke standaard Postgres-client (psql, pgAdmin, DBeaver of toepassingsframeworks).

Als u verbinding wilt maken met uw Databricks-identiteit, kopieert u het fragment uit het psql verbindingsdialoogvenster en plakt u het OAuth-token wanneer hierom wordt gevraagd:
psql 'postgresql://your-email@databricks.com@ep-abc-123.databricks.com/databricks_postgres?sslmode=require'
Meer informatie: Quickstart | psql | pgAdmin | Postgres-clients
Stap 3: Uw eerste tabel maken
De Lakebase SQL-editor wordt vooraf geladen met voorbeeld-SQL. Selecteer in uw project de productiebranch , open de SQL-editor en voer de opgegeven instructies uit om een playing_with_lakebase tabel te maken en voorbeeldgegevens in te voegen.
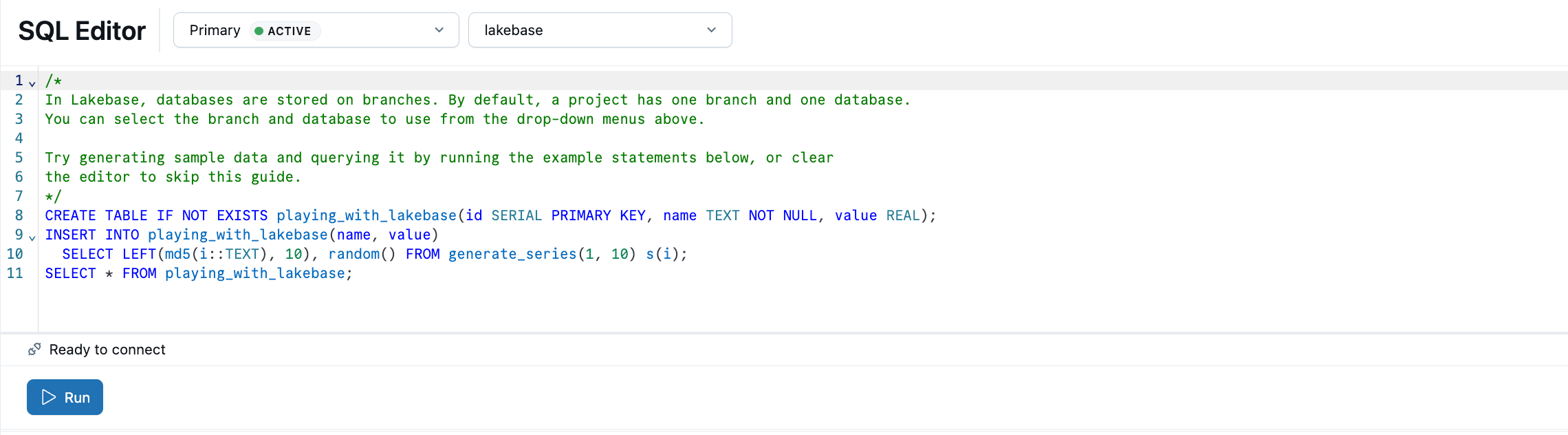
Meer informatie: SQL-editor | Tabellen-editor | Postgres-clients
Stap 4: Registreren in Unity Catalog
Uw Lakebase-database wordt uitgevoerd, maar is onzichtbaar voor de rest van het Databricks-platform totdat u deze registreert in Unity Catalog. Nadat u zich hebt geregistreerd, kunt u query's uitvoeren op Lakebase-tabellen vanuit Databricks SQL, operationele gegevens samenvoegen met Lakehouse-analyses en geïntegreerde governance toepassen.
Maak in Catalog Explorer een nieuwe catalogus met als type Lakebase Autoscaling, die verwijst naar de production-vertakking en databricks_postgres-database van uw project.

U kunt nu query's uitvoeren vanuit een SQL-warehouse:
SELECT * FROM lakebase_catalog.public.playing_with_lakebase;
Meer informatie: Registreren in Unity Catalog
Stap 5: Serveer lakehouse-gegevens in uw app
Gesynchroniseerde tabellen brengen analytische gegevens uit Unity Catalog naar uw Lakebase-database, zodat toepassingen er query's op kunnen uitvoeren met transactionele leesbewerkingen met lage latentie. Maak een voorbeeld van een Unity Catalog-tabel en synchroniseer deze vervolgens met Lakebase.
Maak in een SQL Warehouse of notebook een brontabel:
CREATE TABLE main.default.user_segments AS
SELECT * FROM VALUES
(1001, 'premium', 2500.00, 'high'),
(1002, 'standard', 450.00, 'medium'),
(1003, 'premium', 3200.00, 'high'),
(1004, 'basic', 120.00, 'low')
AS segments(user_id, tier, lifetime_value, engagement);
Synchroniseer deze tabel nu naar Lakebase. Maak in Catalog Explorer een gesynchroniseerde tabel van user_segments in de momentopnamemodus, gericht op de databricks_postgres-database van uw project. Met de momentopnamemodus worden de gegevens eenmaal gekopieerd. Voor continue updates gebruikt u de geactiveerde of continue modus.
Zodra de synchronisatie is voltooid, zijn de gegevens beschikbaar in Lakebase als default.user_segments_synced. Voer een query uit in de Lakebase SQL-editor:
SELECT * FROM "default".user_segments_synced WHERE engagement = 'high';
Opmerking
default moet worden geciteerd omdat het een gereserveerd postgreSQL-trefwoord is. Het gesynchroniseerde tabelschema neemt de naam van het Unity Catalog-schema over, dus als uw schema een naam defaultheeft, moet u het altijd citeren in query's. Aanhalingstekens rond andere id's zijn optioneel.

Uw lakehouse-analyse is nu klaar voor gebruik vanuit uw transactionele database.
Meer informatie: Synced tables | Sync modes | Data type mapping
Volgende stappen
- Een app bouwen:Zelfstudie voor Databricks-apps | Externe apps
- Ontwikkelen met vertakkingen:Zelfstudie voor ontwikkeling op basis van vertakkingen
- Uw team instellen:Project- en databasetoegang verlenen
- Ontdek het platform:Basisconcepten | Projectoverzicht | Alle tutorials