Notitie
Voor toegang tot deze pagina is autorisatie vereist. U kunt proberen u aan te melden of de directory te wijzigen.
Voor toegang tot deze pagina is autorisatie vereist. U kunt proberen de mappen te wijzigen.
Het choreograafpatroon decentraliseert werkstroomlogica en verdeelt verantwoordelijkheden naar andere onderdelen binnen een systeem. In plaats van afhankelijk van een centrale orchestrator bepalen services wanneer en hoe een bedrijfsbewerking moet worden verwerkt.
Context en probleem
Doorgaans verdeelt u een cloudtoepassing in verschillende kleine services die samenwerken om een end-to-end zakelijke transactie te verwerken. Eén bewerking binnen een transactie kan leiden tot meerdere punt-naar-punt-aanroepen tussen alle services. In het ideale gevallen zijn deze services losjes gekoppeld. Het is lastig om een gedistribueerde, efficiënte en schaalbare werkstroom te ontwerpen omdat het complexe communicatie tussen services omvat.
Een algemeen patroon voor communicatie is het gebruik van een gecentraliseerde service of een orchestrator. Binnenkomende aanvragen worden door de orchestrator geleid, die vervolgens de bewerkingen delegeert aan de respectieve services. Elke service voltooit zijn verantwoordelijkheid en is niet op de hoogte van de algehele werkstroom.

Doorgaans implementeert u het orchestratorpatroon als aangepaste software die domeinkennis heeft over de verantwoordelijkheden van de services binnen het systeem. Een voordeel van deze aanpak is dat de orchestrator de status van een transactie kan consolideren op basis van de resultaten van afzonderlijke bewerkingen die de downstreamservices uitvoeren.
Deze aanpak creëert ook enkele obstakels. Het toevoegen of verwijderen van services kan bestaande logica verbreken omdat u delen van het communicatiepad opnieuw moet instellen. Deze afhankelijkheid maakt orchestrator-implementatie complex en moeilijk te onderhouden. De orchestrator kan de betrouwbaarheid van de workload negatief beïnvloeden. Onder belasting kunnen prestatieknelpunten optreden en het single point of failure (SPoF) zijn. Het kan ook trapsgewijze fouten veroorzaken in de downstreamservices.
Solution
Delegeer de logica voor transactieafhandeling tussen de services. Laat elke service deelnemen aan de communicatiewerkstroom voor een bedrijfsbewerking en bepalen wanneer en hoe deze moet worden verwerkt.
Het choreograafpatroon minimaliseert de afhankelijkheid van aangepaste software die de communicatiewerkstroom centraliseert. De onderdelen implementeren algemene logica terwijl ze de werkstroom onder elkaar choreograferen zonder rechtstreeks met elkaar te communiceren.
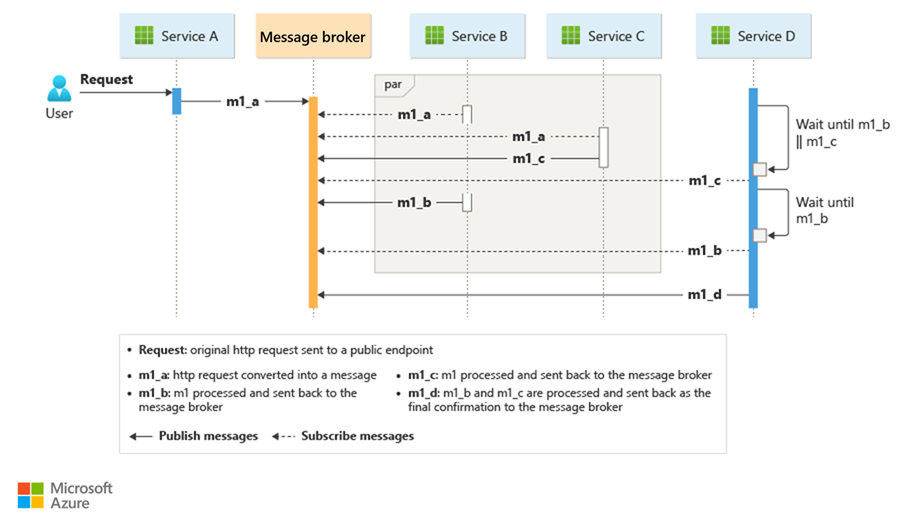
Een veelgebruikte manier om choreografie te implementeren, is door een berichtenbroker te gebruiken die aanvragen buffert totdat downstreamonderdelen deze claimen en verwerken. In de volgende afbeelding ziet u de verwerking van aanvragen via een publiceer-abonneermodel.

Clientaanvragen worden in een message broker als berichten in de wachtrij geplaatst.
De services of de abonnee raadpleegt de broker om te bepalen of het het bericht kan verwerken op basis van de toegepaste bedrijfslogica. De broker kan ook berichten pushen naar abonnees die geïnteresseerd zijn in dat bericht.
Elke geabonneerde service voert de bewerking uit zoals het bericht aangeeft en reageert op de broker met een bericht over succes of mislukking van de bewerking.
Als de bewerking is geslaagd, kan de service een bericht terugsturen naar dezelfde wachtrij of een andere berichtenwachtrij, zodat een andere service de werkstroom indien nodig kan voortzetten. Als de bewerking mislukt, werkt de berichtenbroker met andere services om die bewerking of de hele transactie te compenseren.
Problemen en overwegingen
Houd rekening met de volgende punten wanneer u besluit hoe u dit patroon implementeert:
Het afhandelen van fouten kan lastig zijn. Onderdelen in een toepassing kunnen atomische taken beheren en afhankelijk zijn van andere onderdelen van het systeem. Fout in het ene onderdeel kan van invloed zijn op andere onderdelen, wat kan leiden tot vertragingen bij het voltooien van de algehele aanvraag.
Als u fouten probleemloos wilt afhandelen, implementeert u logica voor foutafhandeling, wat complexiteit introduceert. Foutafhandelingslogica, zoals compenserende transacties, is ook gevoelig voor fouten.
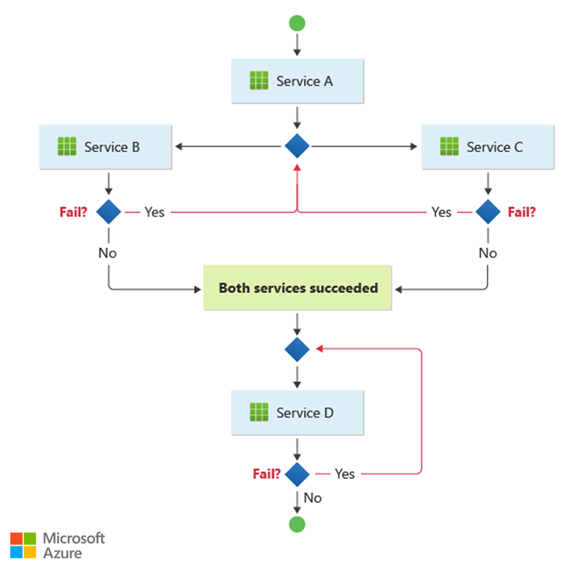
Dit patroon past bij een werkstroom die onafhankelijke bedrijfsprocessen parallel verwerkt. De werkstroom kan ingewikkeld worden wanneer choreografie in een opeenvolging moet plaatsvinden. Service D kan de bewerking bijvoorbeeld pas starten nadat Service B en Service C hun bewerkingen hebben voltooid.
Dit patroon brengt uitdagingen met zich mee als het aantal services snel groeit. Veel onafhankelijke bewegende onderdelen bemoeilijken de werkstroom tussen services. U moet gedistribueerde tracering en correlatie-id's consistent gebruiken om de waarneembaarheid te behouden.
In een orchestrator-geleid ontwerp kan het centrale onderdeel tolerantieverantwoordelijkheden, zoals het opnieuw afhandelen van pogingen voor tijdelijke, niet-tijdelijke en time-outfouten, delegeren aan een toegewezen tolerantiehandler.
Wanneer u de orchestrator verwijdert in een op choreografie gebaseerd ontwerp, nemen downstreamonderdelen geen tolerantieverantwoordelijkheden aan. Ze blijven centraal in de resilience beheerder. Maar downstreamonderdelen moeten rechtstreeks met die handler communiceren, waardoor de punt-naar-punt-communicatie toeneemt.
Evolutie van gebeurtenisschema's kan leiden tot belangrijke wijzigingen in consumenten in de loop van de tijd. In dit patroon gebruiken meerdere onafhankelijke services dezelfde gebeurtenissen. Als een producer de gegevensstructuur van een gebeurtenis wijzigt, kan dit downstream gebruikers verstoren die afhankelijk zijn van het oude schema. Gebruik een schemaregister om gebeurteniscontracten te beheren en achterwaarts compatibele evolutie te gebruiken naarmate services onafhankelijk van elkaar veranderen.
Gebeurtenisvolgorde wordt niet gegarandeerd bij herpogingen of schaalvergroting. Ontwerp voor idempotentie en stuur berichten opnieuw in de juiste volgorde om dubbele of gebeurtenissen die buiten volgorde zijn af te handelen.
Gedecentraliseerde gebeurtenistopologieën kunnen op schaal ontstaand gedrag creëren. Wanneer veel services op elkaars gebeurtenissen reageren, kan het systeem onbedoeld feedbacklussen of gebeurtenisstormen produceren. Een kleine gebeurtenis kan een trapsgewijze stroomafwaartse reacties veroorzaken. Als u circulaire gebeurtenisketens wilt voorkomen, gebruikt u voorzorgsmaatregelen zoals gebeurtenisfiltering, gelijktijdigheidslimieten voor consumenten, begrenzing en expliciete regels.


Wanneer gebruikt u dit patroon?
Gebruik dit patroon wanneer:
De downstreamonderdelen verwerken atomische bewerkingen onafhankelijk. U kunt dit patroon beschouwen als een brand- en vergeetmechanisme , waarbij een onderdeel een taak uitvoert die geen actief beheer nodig heeft. Wanneer de taak is voltooid, verzendt het onderdeel een melding naar de andere onderdelen.
U verwacht dat de onderdelen regelmatig worden bijgewerkt en vervangen. Met dit patroon kunt u de toepassing met minder inspanning en minimale onderbreking van bestaande services wijzigen.
U gebruikt serverloze architecturen voor eenvoudige werkstromen. De onderdelen kunnen kortlevend en gebeurtenisgestuurd zijn. Wanneer er een gebeurtenis optreedt, maakt de service onderdelen die een taak uitvoeren en verwijdert de service onderdelen nadat ze deze taak hebben voltooid.
Communicatie tussen gebonden contexten vereist losse koppeling tussen domeingrenzen. Voor communicatie binnen één gebonden context past u in plaats daarvan een orchestrator-patroon toe.
De centrale orchestrator introduceert een prestatieknelpunt.
Dit patroon is mogelijk niet geschikt wanneer:
De toepassing is complex en vereist een centraal onderdeel voor het verwerken van gedeelde logica om de downstreamonderdelen lichtgewicht te houden.
Punt-naar-punt-communicatie tussen de onderdelen is onvermijdelijk.
U moet bedrijfslogica gebruiken om alle bewerkingen te consolideren die downstreamonderdelen verwerken.
Werklastontwerp
Evalueer hoe u het choreografiepatroon in het ontwerp van een workload gebruikt om de doelstellingen en principes aan te pakken die worden behandeld in de pijlers van het Azure Well-Architected Framework. De volgende tabel bevat richtlijnen over hoe dit patroon de doelstellingen van elke pijler ondersteunt.
| Pilaar | Hoe dit patroon ondersteuning biedt voor pijlerdoelen |
|---|---|
| Operational Excellence helpt bij het leveren van workloadkwaliteit via gestandaardiseerde processen en teamcohesie. | De gedistribueerde onderdelen in dit patroon zijn autonoom en ontworpen om te worden vervangen, zodat u de werkbelasting kunt wijzigen door minder algemene wijzigingen in het systeem. - OE:04 Tools en processen |
| Prestatie-efficiëntie helpt uw workload efficiënt te voldoen aan de vereisten door middel van optimalisaties in schalen, gegevens en code. | Dit patroon biedt een alternatief wanneer prestatieknelpunten optreden in een gecentraliseerde orkestratietopologie. - PE:02 Capaciteitsplanning - PE:05 Schalen en partitioneren |
Als dit patroon compromissen binnen een pijler introduceert, moet u deze tegen de doelstellingen van de andere pijlers overwegen.
Voorbeeld
In dit voorbeeld ziet u het choreograafpatroon door een gebeurtenisgestuurde, cloudeigen workload te maken die functies naast microservices uitvoert. Wanneer een klant verzoekt om een pakket te verzenden, wijst de workload een drone toe. Nadat het pakket klaar is voor ophalen door de geplande drone, wordt het leveringsproces gestart. Terwijl het pakket onderweg is, verwerkt het werkproces de verzending totdat het de verzonden status ontvangt.

De opnameservice ontvangt clientaanvragen en converteert deze naar berichten met de bezorgingsgegevens. Zakelijke transacties beginnen nadat services deze nieuwe berichten verwerken.
Voor één clientbedrijfstransactie zijn drie afzonderlijke bedrijfsactiviteiten vereist:
Een pakket maken of bijwerken.
Wijs een drone toe om het pakket te leveren.
De levering afhandelen, inclusief het controleren en verzenden van een melding wanneer het pakket wordt verzonden.
Microservices voor pakketten, droneplanners en leveringen voeren de zakelijke verwerking uit. De services gebruiken berichten in plaats van een centrale orchestrator om met elkaar te communiceren. Elke service moet vooraf een protocol implementeren dat de bedrijfswerkstroom coördineert op een gedecentraliseerde manier.
Ontwerpen
Services verwerken zakelijke transacties in een reeks via meerdere hops. Elke hop deelt één berichtenbus tussen alle zakelijke services.
Wanneer een client een bezorgingsaanvraag verzendt via een HTTP-eindpunt, ontvangt de opnameservice deze, converteert deze naar een bericht en publiceert het bericht vervolgens naar de gedeelde berichtenbus. De geabonneerde zakelijke services verwerken nieuwe berichten die aan de bus zijn toegevoegd. Wanneer een zakelijke service het bericht ontvangt, wordt de bewerking voltooid of mislukt de aanvraag of treedt er een time-out op. Als de aanvraag slaagt, reageert de service met de Ok statuscode op de bus, genereert een nieuw bewerkingsbericht en verzendt deze naar de berichtenbus. Als de aanvraag mislukt of een time-out optreedt, rapporteert de service een fout door de redencode naar de berichtenbus te verzenden en het bericht vervolgens toe te wijzen aan een wachtrij met dode letters (DLQ). De service verplaatst ook berichten die deze niet binnen een bepaalde tijd naar de DLQ kan ontvangen of verwerken.
Dit ontwerp maakt gebruik van meerdere berichtenbussen om de hele zakelijke transactie te verwerken. Azure Service Bus en Azure Event Grid bieden het berichtenserviceplatform voor dit ontwerp. De workload wordt uitgevoerd in Azure Container Apps, die als host fungeert voor Azure Functions voor gegevensinname. Container Apps verwerkt gebeurtenisgestuurde verwerking die de bedrijfslogica uitvoert.
Dit ontwerp zorgt er ook voor dat de choreografie in een reeks plaatsvindt. Eén Service Bus-naamruimte bevat een onderwerp met twee abonnementen en een sessiebewuste wachtrij. De ingestiedienst publiceert berichten naar de topic. De pakketservice en drone scheduler-service abonneren zich op het onderwerp en publiceren berichten die de wachtrij met geslaagde aanvragen melden. Neem een algemene sessie-id op die een GUID koppelt aan de leverings-id, zodat services niet-gebonden reeksen gerelateerde berichten op volgorde kunnen verwerken. De leveringsservice wacht op twee gerelateerde berichten voor elke transactie. Het eerste bericht geeft aan dat het pakket gereed is om te worden verzonden en het tweede bericht geeft aan dat een drone is gepland.
In dit ontwerp verwerkt Service Bus berichten van hoge waarde die niet verloren of gedupliceerd mogen worden tijdens het hele bezorgingsproces. Wanneer het pakket wordt verzonden, wordt een wijziging van de status gepubliceerd naar Event Grid. De afzender van de gebeurtenis heeft geen verwachting over hoe de statuswijziging wordt verwerkt. Downstream-organisatieservices die dit ontwerp niet omvat, kunnen luisteren naar dit gebeurtenistype en specifieke bedrijfslogica uitvoeren, zoals het verzenden van een orderstatus-e-mail naar de gebruiker.
Als u dit patroon implementeert in een andere rekenservice, zoals AKS, kunt u de standaard voor de Publisher-Subscriber patroontoepassing implementeren met twee containers in dezelfde pod. De ene container voert de ambassadeur uit die communiceert met de berichtenbus die u kiest terwijl de andere container de bedrijfslogica uitvoert. Deze aanpak verbetert de prestaties en schaalbaarheid. De ambassadeur en de zakelijke service delen hetzelfde netwerk, wat de latentie vermindert en de doorvoer verhoogt.
Om trapsgewijze bewerkingen voor opnieuw proberen te voorkomen die tot meerdere pogingen kunnen leiden, moeten zakelijke services onmiddellijk onaanvaardbare berichten markeren. Verrijk deze berichten met behulp van algemene redencodes of een gedefinieerde toepassingscode, zodat de services deze kunnen verplaatsen naar een DLQ. Overweeg om het Saga-patroon te implementeren om consistentieproblemen van downstreamservices te beheren. Een andere service verwerkt bijvoorbeeld berichten met dode letters alleen voor hersteldoeleinden door een compensatie uit te voeren, opnieuw te proberen of een draaitransactie uit te voeren.
De bedrijfsdiensten zijn idempotent zodat herhaalde pogingen geen dubbele bronnen creëren. De pakketservice maakt bijvoorbeeld gebruik van upsert-bewerkingen om gegevens toe te voegen aan het gegevensarchief.
Volgende stappen
Centraliseer gebeurtenisschemabeheer met behulp van het schemaregister in Azure Event Hubs om de compatibiliteit te behouden naarmate uw services zich ontwikkelen.
Bekijk asynchrone berichtopties in Azure voor meer informatie over de verschillende beschikbare infrastructuuropties voor het implementeren van een gedecentraliseerde werkstroom.
Evalueer de technische mogelijkheden van verschillende platforms om de juiste Azure Messaging-service te kiezen voor uw specifieke choreografievereisten.
Verwante middelen
Bekijk deze patronen in uw ontwerp voor choreografie:
Modulariseer de zakelijke service met behulp van het Ambassador-patroon.
Implementeer het patroonQueue-Based Load Leveling om pieken in de werkbelasting te verwerken.
Gebruik asynchrone gedistribueerde berichten via het Publisher-Subscriber patroon.
Gebruik compenserende transacties om een reeks geslaagde bewerkingen ongedaan te maken als een of meer gerelateerde bewerkingen mislukken.