Notitie
Voor toegang tot deze pagina is autorisatie vereist. U kunt proberen u aan te melden of de directory te wijzigen.
Voor toegang tot deze pagina is autorisatie vereist. U kunt proberen de mappen te wijzigen.
Verwerking van natuurlijke taal omvat technieken die menselijke taal analyseren, begrijpen en genereren op basis van tekstgegevens. Azure biedt beheerde API-services en gedistribueerde opensource-frameworks die betrekking hebben op workloads voor verwerking van natuurlijke taal die variëren van sentimentanalyse en entiteitsherkenning tot documentclassificatie en samenvatting van tekst. Deze handleiding helpt u bij het evalueren en kiezen van de primaire opties voor verwerking van natuurlijke taal op Azure, zodat u de juiste technologie aan uw workloadvereisten kunt koppelen.
Notitie
Deze handleiding richt zich op de mogelijkheden voor verwerking van natuurlijke taal die beschikbaar zijn via Azure Language en Apache Spark met Spark NLP op Azure Databricks of Microsoft Fabric. Het biedt geen richtlijnen voor het selecteren van taalmodellen of het ontwerpen van Azure OpenAI-oplossingen. Sommige platformbeschrijvingen kunnen verwijzen naar ondersteunde basismodel- of spraakmodelintegraties als implementatiedetails, maar deze handleiding is gericht op de selectie van de service voor verwerking van natuurlijke taal. Zie Een AI-servicestechnologie kiezen voor meer informatie.
Inzicht in verwerking van natuurlijke taal en taalmodellen
Voordat u Azure services evalueert, begrijpt u wat verwerking van natuurlijke taal is, hoe deze verschilt van taalmodellen en welke taken worden verwerkt.
Natuurlijke taalverwerking onderscheiden van taalmodellen
In deze sectie wordt de grens tussen natuurlijke taalverwerking en taalmodellen verduidelijkt en worden de belangrijkste mogelijkheden beschreven die technieken voor natuurlijke taalverwerking mogelijk maken.
| Dimensie | Natuurlijke taalverwerking | Taalmodellen |
|---|---|---|
| Scope | Een breed veld dat betrekking heeft op diverse technieken voor tekstverwerking, waaronder tokenisatie, stemming, entiteitsherkenning, sentimentanalyse en documentclassificatie. | Een deep learning-subset van verwerking van natuurlijke taal gericht op taalbegrip en generatietaken op hoog niveau. |
| Examples | Op regels gebaseerde parsers, term frequentie-inverse documentfrequentie (TF-IDF) classificaties, herkenners van benoemde entiteiten, sentimentanalysatoren. | GPT-, BERT- en vergelijkbare transformatormodellen die menselijke, contextbewuste tekst genereren. |
| Uitvoer | Gestructureerde signalen zoals labels, scores, geëxtraheerde fragmenten en geparseerde zinsbouw. | Vloeiende natuurlijke taal, zoals gegenereerde tekst, samenvattingen, antwoorden en voltooiingen. |
| Relatie | Het bovenliggende domein. Verwerking van natuurlijke taal omvat het volledige spectrum van tekstverwerkingsmethoden. | Een hulpprogramma in natuurlijke taalverwerking. Taalmodellen verbeteren de verwerking van natuurlijke taal zonder deze te vervangen. Ze verwerken bredere cognitieve taken, maar zijn niet synoniem voor verwerking van natuurlijke taal. |
Mogelijkheden voor verwerking van natuurlijke taal
Classificeer documenten door ze als gevoelig of spam te labelen. Met verwerking van natuurlijke taal worden documenten automatisch gecategoriseert op basis van inhoud ter ondersteuning van nalevings- en filterwerkstromen.
Tekst samenvatten door entiteiten in het document te identificeren. Verwerking van natuurlijke taal extraheert belangrijke entiteiten om beknopte samenvattingen te produceren die de belangrijkste informatie vastleggen.
Tag documenten met trefwoorden met behulp van geïdentificeerde entiteiten. Nadat u entiteiten hebt geïdentificeerd, kunt u trefwoordtags genereren die de documentorganisatie vereenvoudigen. Gebruik deze tags voor zoeken en ophalen op basis van inhoud.
Onderwerpen detecteren voor navigatie en gerelateerde documentdetectie. Verwerking van natuurlijke taal identificeert belangrijke onderwerpen met behulp van geëxtraheerde entiteiten, die ondersteuning bieden voor documentcategorisatie en navigatie op basis van onderwerpen.
Tekstentiment beoordelen. Sentimentanalyse evalueert de emotionele toon van tekst en classificeert inhoud als positief, negatief of neutraal.
Voer uitvoer van verwerking van natuurlijke taal in downstreamwerkstromen in. Resultaten zoals geëxtraheerde entiteiten, sentimentscores en onderwerplabels fungeren als invoer voor verwerking, zoekindexering en analyse.
Mogelijke gebruiksvoorbeelden identificeren
Bedrijfsscenario's in veel branches profiteren van oplossingen voor natuurlijke taalverwerking. In de volgende gebruiksvoorbeelden ziet u hoe technieken voor natuurlijke taalverwerking echte uitdagingen aanpakken, van het verwerken van ongestructureerde documenten tot het inschakelen van opkomende toepassingen in cyberbeveiliging en toegankelijkheid.
Documenten en ongestructureerde tekst verwerken
Informatie extraheren uit door de machine gemaakte documenten. Verwerking van natuurlijke taal maakt documentverwerking mogelijk in financiële sectoren, gezondheidszorg, detailhandel, overheid en andere sectoren. U kunt digitaal gemaakte documenten analyseren om gestructureerde informatie uit ongestructureerde invoer te extraheren. Voor handgeschreven documenten gebruikt u Azure Document Intelligence om handgeschreven inhoud te converteren naar tekst voordat u technieken voor natuurlijke taalverwerking toepast.
Toepassen van industrie-onafhankelijke natuurlijke taalverwerkingstaken voor tekstverwerking. NER (Named Entity Recognition), classificatie, samenvatting en relationele extractie helpen u automatisch ongestructureerde documentinhoud te verwerken en analyseren. Deze taken werken tussen domeinen en vereisen geen branchespecifieke aanpassing.
Bouw domeinspecifieke modellen voor gespecialiseerde analyse. Voorbeelden van deze taken zijn risicostratificatiemodellen voor gezondheidszorg, ontologieclassificatie voor kennisbeheer en samenvattingen van retail voor product- en klantgegevens. Aangepaste modeltraining in Azure Language en Spark NLP helpt de nauwkeurigheid van deze domeinspecifieke documentindelingen te verbeteren.
Geautomatiseerde rapporten genereren op basis van gestructureerde gegevensinvoer. U kunt uitgebreide tekstrapporten maken en genereren op basis van gestructureerde gegevens. Deze mogelijkheid helpt sectoren zoals financiën en naleving waarvoor grondige documentatie is vereist.
Zoeken, vertalen en analyses inschakelen
Maak kennisgrafieken en schakel semantische zoekopdrachten in via het ophalen van gegevens. Verwerking van natuurlijke taal biedt ondersteuning voor het maken van kennisgrafiek en semantische zoekopdrachten, waardoor systemen query's kunnen interpreteren in plaats van alleen te vertrouwen op trefwoordkoppeling.
Ondersteuning voor drugdetectie en klinische proeven met medische kennisgrafieken. Systemen voor natuurlijke taalverwerking analyseren klinische tekst. Medische kennisgrafieken die zijn gebouwd op basis van die tekst ondersteunen pijplijnen voor drugdetectie en het vergelijken van klinische proeven. Deze grafieken verbinden entiteiten zoals drugs, voorwaarden en resultaten om onderzoekswerkstromen te versnellen. Tekstanalyse voor gezondheid in Azure Taal extraheert medische entiteiten, relaties en asserties die u kunt gebruiken om deze grafieken samen te stellen.
Tekst vertalen voor conversationele AI in klantgerichte toepassingen. Tekstomzetting maakt conversationele AI mogelijk in meerdere branches. U kunt meertalige klantgerichte toepassingen bouwen die de voorkeurstaal van de gebruiker verwerken en erop reageren. Spark NLP biedt vertaalmogelijkheden rechtstreeks. Gebruik in Azure Azure Translator, een afzonderlijke service van Azure Language.
Analyseer sentiment en emotionele intelligentie voor merkperceptie. Sentimentanalyse helpt u bij het bewaken van merkperceptie en het analyseren van feedback van klanten door positieve, negatieve en genuanceerde emotionele signalen van tekst te herkennen.
Natuurlijke taalverwerking uitbreiden naar opkomende domeinen
Bouw spraakgestuurde interfaces voor IoT (Internet of Things) en slimme apparaten. Verwerking van natuurlijke taal verwerkt de tekstuitvoer van spraakherkenningssystemen om inzicht te krijgen in de intentie van de gebruiker en betekenis te extraheren in IoT- en slimme-apparaatscenario's. Voor spraakgestuurde scenario's is Azure Speech vereist voor spraak-naar-tekstconversie voordat natuurlijke taal wordt verwerkt.
Pas de taaluitvoer dynamisch aan met behulp van adaptieve taalmodellen. Adaptieve taalmodellen passen taaluitvoer dynamisch aan voor verschillende niveaus van begrip van doelgroepen, die ondersteuning bieden voor de levering van onderwijsinhoud en toegankelijkheid.
Phishing en onjuiste informatie detecteren via tekstanalyse voor cyberbeveiliging. Verwerking van natuurlijke taal analyseert communicatiepatronen en taalgebruik in realtime om potentiële beveiligingsrisico's in digitale communicatie te identificeren. Met deze analyse kunt u phishingpogingen en verkeerd-informatiecampagnes detecteren.
Azure Taal evalueren
Azure Language is een cloudservice die natuurlijke taalverwerkingsfuncties biedt voor het begrijpen en analyseren van tekst. U kunt deze openen via de Foundry-portal, REST API's en clientbibliotheken voor Python, C#, Java en JavaScript zonder infrastructuur voor beheer. Voor het ontwikkelen van AI-agents hebt u ook toegang tot deze mogelijkheden via de MCP-server (Azure Language Model Context Protocol). U kunt deze benaderen als een externe server in de Microsoft Foundry-hulpprogrammacatalogus of als een lokale zelf-gehoste server.
Vooraf gemaakte functies
Vooraf gemaakte functies vereisen geen modeltraining en zijn klaar voor gebruik:
NER: Identificeert en categoriseert entiteiten in tekst in vooraf gedefinieerde typen, zoals personen, organisaties, locaties en datums.
PII-detectie: Identificeert en redacteert persoonsgegevens (PII), inclusief gevoelige persoonlijke en gezondheidsgegevens, in tekst- en getranscribeerde gesprekken.
Taaldetectie: Hiermee wordt de taal van een document in een breed scala aan talen en dialecten gedetecteerd.
Sentimentanalyse en meninganalyse: Identificeert positieve, negatieve of neutrale gevoelens in tekst en koppelt meningen aan specifieke elementen, zoals productkenmerken of serviceaspecten.
Sleuteltermextractie: Evalueert ongestructureerde tekst en retourneert een lijst met hoofdconcepten en sleuteltermen.
Samenvatting: Condenseert documenten en gesprekken met behulp van extractieve of abstractieve benaderingen, die ondersteuning bieden voor samenvatting van tekst, chat en callcenter.
Tekstanalyse voor status: Extraheert en labelt relevante gezondheidsinformatie uit ongestructureerde klinische tekst, waaronder medische entiteiten, relaties en asserties.
Aangepaste modellen trainen
U kunt aanpasbare functies gebruiken om modellen op uw gegevens te trainen voor het verwerken van domeinspecifieke verwerkingstaken voor natuurlijke taal:
- Aangepaste herkenning van benoemde entiteiten (CNER): Ontwikkel op maat gemaakte modellen om domeinspecifieke entiteitscategorieën uit ongestructureerde tekst te extraheren. Gebruik CNER wanneer vooraf gedefinieerde NER-categorieën uw domeinwoordenlijst niet behandelen.
Azure Language MCP-server en -agents
Notitie
De Azure Language MCP - server en zowel de intentieroutering als de agenten voor exacte vraagbeantwoording zijn in preview. Preview-functies bevatten geen SLA (Service Level Agreement) en we raden ze niet aan voor productieworkloads. Sommige functies worden mogelijk niet ondersteund of hebben mogelijk beperkte mogelijkheden. Zie Aanvullende gebruiksvoorwaarden voor Microsoft Azure previews voor meer informatie.
Azure Language biedt vooraf gedefinieerde agents en flexibele implementatieopties voor workloads voor verwerking van natuurlijke taal in productie:
Agent voor intentieroutering: Beheert gespreksstromen. Het begrijpt gebruikersintenties en routes naar nauwkeurige antwoorden via deterministische, controleerbare logica. Gebruik deze agent wanneer u transparante, deterministische conversationele routering nodig hebt.
Exact vraag-antwoord agent: Biedt betrouwbare, woord-voor-woord antwoorden op bedrijfskritieke vragen terwijl het menselijk toezicht en de kwaliteitscontrole behouden blijven. Gebruik deze agent wanneer de nauwkeurigheid en consistentie van de reactie essentieel zijn.
U kunt beide agents openen via de Foundry-hulpprogrammacatalogus. Zie Azure Language MCP-server en -agents (preview) voor meer informatie.
De Azure Language MCP-server ondersteunt meerdere implementatieopties:
Extern in de cloud gehoste MCP-server: In de catalogus met foundry-hulpprogramma's wordt deze server vermeld. De server biedt in de cloud beheerde toegang tot Azure taalmogelijkheden en vereist geen lokale infrastructuur.
Lokale zelf-hostende MCP-server: Ondersteunt on-premises of zelfbeheerde implementaties voor nalevings-, beveiligings- of gegevenslocatievereisten.
Implementatie in containers: De volgende functies bieden ondersteuning voor implementatie in containers voor scenario's waarvoor lokale verwerking of lucht-gapped omgevingen zijn vereist. Zie Azure AI-containers ondersteunen voor de volledige lijst met beschikbare containers en hun beschikbaarheidsstatus.
- Sentimentanalyse
- Taaldetectie
- Sleutelwoordextractie
- NER
- PII-detectie
- CNER
- Tekstanalyse voor gezondheid
- Samenvatting (preview)
Apache Spark evalueren met Spark NLP
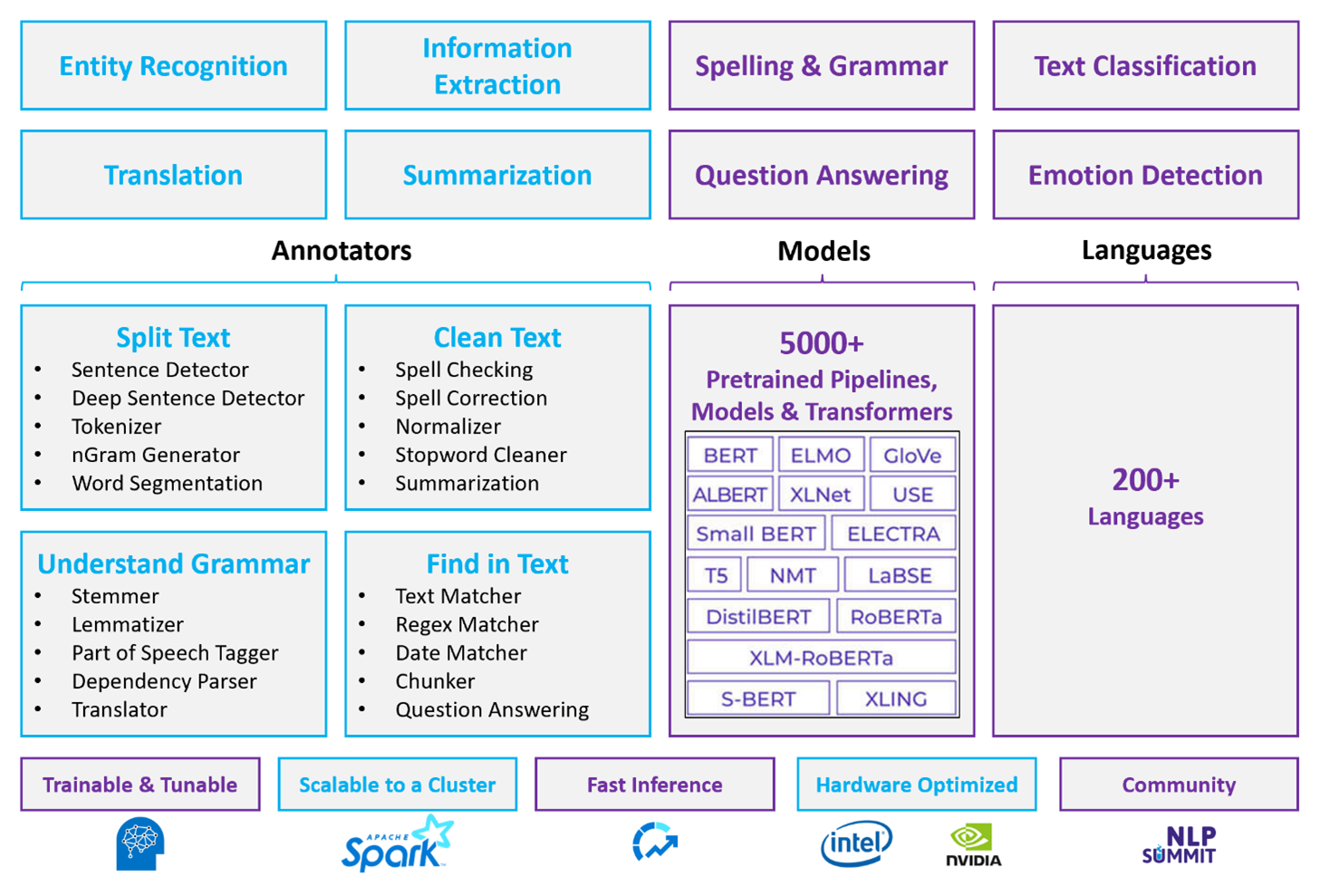
Apache Spark met Spark NLP is een gedistribueerde opensource-benadering voor verwerking in natuurlijke taal die op clusterschaal werkt. De Spark NLP-platformarchitectuur, prestaties en vooraf samengesteld modelecosysteem maken het een sterke optie voor grootschalige, aanpasbare werkbelastingen voor natuurlijke taalverwerking op Azure Databricks of Fabric.
Platform en architectuur begrijpen
U wordt aangeraden Fabric of Azure Databricks te gebruiken voor werkbelastingen voor natuurlijke taalverwerking op basis van Apache Spark.
Apache Spark biedt parallelle verwerking in het geheugen voor big data-analyses. Fabric en Azure Databricks biedt u toegang tot apache Spark-verwerkingsmogelijkheden voor grootschalige workloads voor verwerking van natuurlijke taal.
Spark NLP werkt als een systeemeigen uitbreiding van Spark ML op gegevensframes. Deze integratie maakt geïntegreerde verwerking van natuurlijke taal en machine learning-pijplijnen mogelijk met verbeterde prestaties op gedistribueerde clusters.
Spark NLP is een opensource-bibliotheek met ondersteuning voor Python, Java en Scala. De bibliotheek biedt functionaliteit die vergelijkbaar is met spaCy en Natural Language Toolkit (NLTK), waaronder spellingcontrole, sentimentanalyse en documentclassificatie.

Apache®, Apache Spark en het vlamlogo zijn geregistreerde handelsmerken of handelsmerken van de Apache Software Foundation in de United States en/of andere landen. Er wordt geen goedkeuring door De Apache Software Foundation geïmpliceerd door het gebruik van deze markeringen.
Prestaties en schaalbaarheid evalueren
Openbare benchmarks tonen aanzienlijke snelheidsverbeteringen ten opzichte van andere bibliotheken voor natuurlijke taalverwerking. In vergelijking met frameworks zoals spaCy en NLTK demonstreert Spark NLP snellere training en deductie op gedistribueerde clusters. Aangepaste modellen waarmee Spark NLP-treinen nauwkeurigheidsniveaus bereiken die overeenkomen met die van andere frameworks voor natuurlijke taalverwerking, waardoor het geschikt is voor productieworkloads waarvoor snelheid en precisie is vereist.
Geoptimaliseerde builds voor CPU's, GPU's en Intel Xeon-chips maken volledig gebruik van Apache Spark-clusters. Deze builds maken het mogelijk om training en inferentie efficiënt te schalen over clusterknooppunten.
MPNet-insluitingen en ONNX-ondersteuning maken nauwkeurige, contextbewuste verwerking mogelijk. MPNet produceert compacte vectorweergaven die semantische betekenis vastleggen en ONNX-ondersteuning biedt u de mogelijkheid om geoptimaliseerde modellen te importeren en uit te voeren voor deductie.
Vooraf gemaakte modellen en pijplijnen gebruiken
Vooraf gemaakte deep learning-modellen verwerken NER, documentclassificatie en gevoelsdetectie. De bibliotheek wordt geleverd met vooraf samengestelde Deep Learning-modellen.
Vooraf getrainde taalmodellen ondersteunen woord-, segment-, zin- en documentbesluitingen. De bibliotheek bevat vooraf getrainde taalmodellen die ondersteuning bieden voor woord-, segment-, zin- en documentbesluitingsniveaus. Deze insluitingen bieden compacte vectorweergaven die downstreamtaken mogelijk maken, zoals overeenkomsten zoeken en classificatie.
Geïntegreerde verwerking van natuurlijke taal en machine learning-pijplijnen ondersteunen documentclassificatie en risicovoorspelling. De integratie met Spark ML ondersteunt geïntegreerde verwerking van natuurlijke taal en machine learning-pijplijnen voor taken zoals documentclassificatie en risicovoorspelling. Met deze geïntegreerde benadering kunt u tekstverwerking combineren met traditionele machine learning-modellen in één pijplijn, waardoor de architectuur eenvoudiger wordt.
Veelvoorkomende uitdagingen voor verwerking van natuurlijke taal oplossen
Zowel Azure Language als Apache Spark met Spark NLP hebben te maken met veelvoorkomende uitdagingen bij het verwerken van natuurlijke taal op schaal. Als u deze uitdagingen begrijpt, kunt u resources plannen, pijplijnen ontwerpen en nauwkeurigheids verwachtingen instellen voordat u een van beide opties doorvoert.
Resourceverwerking
Voor het verwerken van vrije tekst zijn aanzienlijke rekenbronnen en -tijd vereist. Vrije tekstdocumenten zijn rekenintensief en tijdrovend om te analyseren. Elk document vereist tokenisatie, normalisatie en modeldeductie voordat het bruikbare resultaten produceert.
Spark NLP-workloads vereisen vaak GPU-rekenimplementatie. Voor grootschalige Spark NLP-pijplijnen bieden GPU-versnelde clusters op Azure Databricks of Fabric de parallelle verwerkingskracht die nodig is voor training en deductie. Optimalisaties zoals Llama 3.x model kwantisatie helpen de geheugenvoetafdruk te verminderen en de doorvoer voor deze intensieve taken te verbeteren.
Azure Taal vereist doorvoerplanning en quotabeheer. De service verwerkt resourcebeheer, maar voor API-aanroepen met een hoog volume is een zorgvuldige doorvoerplanning vereist. Bewaak uw aanvraagtarieven op basis van servicelimieten en frequentielimieten om beperking te voorkomen en consistente verwerkingsprestaties te garanderen.
Documentstandaardisatie
Documenten in de praktijk volgen zelden een consistente structuur. Deze inconsistentie creëert uitdagingen voor extractiepijplijnen en vereist opzettelijke strategieën om de nauwkeurigheid tussen bronnen te behouden.
Inconsistente notaties: Zonder een gestandaardiseerde documentindeling kan het extraheren van specifieke feiten uit vrije tekst lastig zijn. Het kan bijvoorbeeld een uitdaging zijn om factuurnummers en datums van verschillende leveranciers te extraheren, omdat veldindelingen, labels en opmaak per bron verschillen.
Modeltraining: Wanneer u aangepaste modellen traint in Spark NLP en Azure Language, kunt u zich aanpassen aan domeinspecifieke documentindelingen. Wanneer u traint op representatieve voorbeelden van uw werkelijke documenten, kunt u de nauwkeurigheid van extractie verbeteren voor velden, entiteiten en patronen die vooraf gedefinieerde modellen niet goed verwerken.
Gegevensvariant en complexiteit
Diverse documentstructuren en taalkundige nuances voegen complexiteit toe. Tekstgegevens in de echte wereld hebben veel indelingen, schrijfstijlen en talen. Voor het aanpakken van deze variaties zijn modellen vereist die dubbelzinnigheid, taal, afkortingen en domeinspecifieke terminologie kunnen verwerken terwijl de nauwkeurigheid behouden blijft.
MPNet-insluitingen in Spark NLP bieden een uitgebreid contextueel begrip. MET MPNet-insluitingen worden contextuele relaties tussen woorden en woordgroepen vastgelegd, waardoor Spark NLP-pijplijnen genuanceerde tekst effectiever kunnen verwerken. Deze insluitingen produceren compacte vectorweergaven die semantische betekenis behouden in verschillende documentindelingen.
Aangepaste modellen in Azure Language worden aangepast aan domeinspecifieke tekstpatronen. Met CNER kunt u modellen trainen op uw eigen gelabelde gegevens om patronen te herkennen die specifiek zijn voor uw domein. Deze aanpak verbetert de betrouwbaarheid door het model te leren entiteiten en categorieën te herkennen die vooraf gedefinieerde modellen missen.
Criteria voor sleutelselectie toepassen
Gebruik de volgende criteria om te bepalen welke Azure optie voor verwerking van natuurlijke taal het beste past bij uw vereisten. Elk criterium beschrijft een workloadkenmerk en identificeert de service waarmee deze wordt aangepakt.
Beheerde mogelijkheden voor natuurlijke taalverwerking: Gebruik Azure Language API's voor entiteitsherkenning, intentieidentificatie, onderwerpdetectie of sentimentanalyse. Deze mogelijkheden zijn beschikbaar als beheerde services met minimale installatie en u hoeft geen infrastructuur in te richten of te beheren.
Vooraf gedefinieerde of vooraf getrainde modellen: Gebruik Azure Taal als u van plan bent vooraf gedefinieerde of vooraf getrainde modellen te gebruiken zonder infrastructuur te beheren. Deze benadering past bij kleine tot middelgrote gegevenssets en standaardtaken voor verwerking van natuurlijke taal, waarbij vooraf gebouwde modellen voldoende nauwkeurigheid bieden. Het biedt automatisch schalen, ingebouwde beveiliging en prijsstelling per oproep zonder de overhead van clusterbeheer.
Custom-modeltraining voor grote tekstgegevenssets: Gebruik Azure Databricks of Fabric met Spark NLP. Deze platforms bieden de rekenkracht en flexibiliteit die u nodig hebt voor uitgebreide modeltraining op grote tekstgegevenssets. U kunt ook modellen downloaden via Spark NLP, waaronder Llama 3.x en MPNet.
Low-level natural language processing primitives: Gebruik Azure Databricks of Fabric met Spark NLP voor tokenization, stemming, lemmatization en TF-IDF. U kunt ook een opensource-bibliotheek gebruiken, zoals spaCy of NLTK. Azure Language in Foundry Tools maakt intern gebruik van tokenisatie als onderdeel van de modelpijplijn, maar deze stappen worden niet weergegeven als zelfstandige, controleerbare API's.
Pijplijnen voor natuurlijke taalverwerking bouwen met behulp van Spark NLP
Spark NLP volgt hetzelfde ontwikkelingspatroon als traditionele Spark ML-modellen wanneer u een pijplijn voor verwerking van natuurlijke taal uitvoert. U beheert getrainde modellen met behulp van MLflow voor het bijhouden van experimenten en productie-implementatie.

Kernpijplijnonderdelen samenstellen
Een Spark NLP-pijplijn ketent annotatoren in een reeks. Elke annotator transformeert de uitvoer van de vorige fase en bouwt van onbewerkte tekst naar semantische vectoren.
DocumentAssembler is het toegangspunt voor elke Spark NLP-pijplijn. Gebruik
setCleanupModeom optionele tekstvoorverwerking toe te passen, zoals het verwijderen van HTML-tags of het normaliseren van witruimten, voordat downstream-annotatoren actief worden.ZinDetector identificeert zingrenzen in het samengestelde document. Deze retourneert gedetecteerde zinnen als een
Arraybinnen één rij of als afzonderlijke rijen, afhankelijk van uw pijplijnconfiguratie. Nauwkeurige zinsdetectie is belangrijk omdat veel downstreamaantekenaars op zinsniveau werken.Tokenizer verdeelt onbewerkte tekst in discrete tokens, zoals woorden, getallen en symbolen. Als de standaardregels onvoldoende zijn voor uw domein, voegt u aangepaste regels toe om gespecialiseerde woordenschat, afbreekstreepjes of domeinspecifieke patronen af te handelen.
Normalizer verfijnt tokens door reguliere expressies en woordenlijsttransformaties toe te passen. Tekst wordt gereinigd om ruis te verminderen voordat het wordt ingesloten. U kunt bijvoorbeeld accenten strippen, converteren naar kleine letters of aangepaste woordenlijsttoewijzingen toepassen om terminologie te standaardiseren.
WordEmbeddings wijst tokens toe aan semantische vectoren voor contextuele verwerking. Elk token wordt weergegeven als een compacte vector die de betekenis ervan vastlegt ten opzichte van andere tokens. Niet-opgeloste tokens die niet worden weergegeven in de woordenlijst voor insluitingen, worden standaard ingesteld op nul vectoren.
Modellen beheren met MLflow
Spark NLP maakt gebruik van Spark MLlib-pijplijnen met systeemeigen MLflow-ondersteuning . U hoeft geen aangepaste serialisatie- of integratiecode te schrijven.
MLflow beheert het bijhouden van experimenten, modelversiebeheer en implementatie. U kunt pijplijnparameters, metrische gegevens en artefacten registreren tijdens het uitvoeren van de training. MLflow houdt elk experiment bij, zodat u resultaten in iteraties kunt vergelijken en geslaagde configuraties kunt reproduceren.
MLflow kan rechtstreeks worden geïntegreerd met Azure Databricks en Fabric. Op Azure Databricks wordt MLflow vooraf geïnstalleerd en nauw geïntegreerd met de werkruimte. Fabric biedt ook een built-in MLflow-ervaring met systeemeigen experimenten bijhouden en automatisch aanmelden, zodat u MLflow niet afzonderlijk hoeft te installeren. Als u Spark NLP uitvoert in een andere Apache Spark-omgeving, kunt u MLflow afzonderlijk installeren en configureren voor het bijhouden van experimenten op een externe traceringsserver.
Gebruik het MLflow-modelregister om modellen te promoten voor productie en beheer. Het modelregister biedt een centrale opslagplaats voor het beheren van modelversies in uw pijplijnen voor verwerking in natuurlijke taal. In klassieke implementaties worden overgangsmodellen door fasen zoals fasering, productie en gearchiveerd. In Azure Databricks gebruiken nieuwere implementaties Models in Unity Catalog, waarmee vaste fasen worden vervangen door aangepaste aliassen en tags voor flexibeler levenscyclusbeheer. Op Fabric biedt de werkruimte een eigen modelregister op basis van MLflow.
Mogelijkheidsmatrix
De volgende tabellen geven een overzicht van de belangrijkste verschillen in mogelijkheden tussen Spark NLP op Azure Databricks of Fabric en Azure Language.
Algemene mogelijkheden
| Vermogen | Spark NLP (Azure Databricks of Fabric) | Azure Taal |
|---|---|---|
| Vooraf getrainde modellen als een service | Ja | Ja |
| REST-API | Ja | Ja |
| Programmeerbaarheid | Python, Scala | Zie ondersteunde programmeertalen. |
| Ondersteunt de verwerking van grote gegevenssets en grote documenten | Ja | Beperkt 1 |
1.Azure Language heeft limieten voor documentgrootte per aanvraag die per modus variëren. Synchrone aanvragen ondersteunen maximaal 5120 tekens per document en asynchrone aanvragen ondersteunen maximaal 125.000 tekens per document. Beide modi ondersteunen maximaal 25 documenten per API-aanroep. U kunt grote gegevenssetvolumes verwerken via batchverwerking en paginering, maar afzonderlijke documenten die de tekenlimiet voor de gekozen modus overschrijden, vereisen segmentering. Zie Data- en frequentielimieten voor Azure Language.
Mogelijkheden van annotator
| Vermogen | Spark NLP (Azure Databricks of Fabric) | Azure Taal |
|---|---|---|
| Zinherkenner | Ja | Nee. |
| Diepgaand zinnen-detectiesysteem | Ja | Nee. |
| Tokenizer | Ja | Alleen intern (niet beschikbaar als een zelfstandige API) |
| N-gram opwekker | Ja | Nee. |
| Word segmentatie | Ja | Ja |
| Stemmen | Ja | Nee. |
| Lemmatisator | Ja | Nee. |
| Woordsoorten markeren | Ja | Nee. |
| Afhankelijkheidsparser | Ja | Nee. |
| Vertaling | Ja | Nee. |
| Stopwoordenreiniger | Ja | Nee. |
| Spellingcorrectie | Ja | Nee. |
| Normalisator | Ja | Ja |
| Tekstvergelijker | Ja | Nee. |
| TF-IDF | Ja | Nee. |
| Matcher voor reguliere expressies | Ja | Beperkt |
| Datum Matcher | Ja | Beperkt |
| Chunker | Ja | Nee. |
Mogelijkheden voor verwerking van natuurlijke taal op hoog niveau
| Vermogen | Spark NLP (Azure Databricks of Fabric) | Azure Taal |
|---|---|---|
| Spellingscontrole | Ja | Nee. |
| Samenvatting | Ja | Ja |
| Vragen beantwoorden | Ja | Ja |
| Gevoelsdetectie | Ja | Ja |
| Emotiedetectie | Ja | Beperkt 2 |
| Tokenclassificatie | Ja | Beperkt 3 |
| Tekstclassificatie | Ja | Beperkt 3 |
| Tekstweergave | Ja | Nee. |
| NER | Ja | Ja (vooraf samengesteld). CNER is beschikbaar via aangepaste modellen. 3 |
| Taaldetectie | Ja | Ja |
| Ondersteunt andere talen dan Engels | Ja. Zie ondersteunde talen voor Spark NLP. | Ja. Zie Azure Language ondersteunde talen. |
2.Azure Language ondersteunt meninganalyse, waarmee sentimenten worden geïdentificeerd die zijn gekoppeld aan specifieke aspecten van tekst, maar geen specifieke emotiedetectie bieden (zoals vreugde, woede of verdrietclassificatie).
3.Beschikbaarvia aangepaste modellen. U traint CNER- of aangepaste entiteitsherkenningsmodellen op uw eigen gelabelde gegevens.
Bijdragers
Microsoft dit artikel onderhoudt. De volgende inzenders hebben dit artikel geschreven.
Hoofdauteurs:
- Ananya Ghosh Chowdhury | Principal Cloud Solution Architect
- Kranthi Manchikanti | Senior AI Solutions Engineer
Andere Inzenders:
- Freddy Ayala | Architect van cloudoplossingen
- Tincy Elias | Senior Cloud Solution Architect
- De Steller van Microsoft | Senior Cloud Solution Architect
Als u niet-openbare LinkedIn-profielen wilt zien, meldt u zich aan bij LinkedIn.
Volgende stappen
- Introtion to AI in Azure
- Oplossingen voor natuurlijke taalverwerking ontwikkelen met behulp van Foundry Tools
Verwante middelen
Azure Taaldocumentatie:
Documentatie voor Spark NLP:
Azure onderdelen:
Informatiebronnen: