最適化戦略の比較と結合
Tip
詳細については、「 テキストと画像 」タブを参照してください。
プロンプト エンジニアリング、RAG、および微調整を個別に調べてきたので、それらがどのように相互に関連しているかを見てみましょう。 これらの戦略は相互に排他的ではありません。これらは、さまざまな最適化目標を満たすために組み合わせることができる補完的な方法です。
最適化のスペクトルを理解する
3 つの最適化戦略では、モデルのパフォーマンスのさまざまなディメンションに対処します。
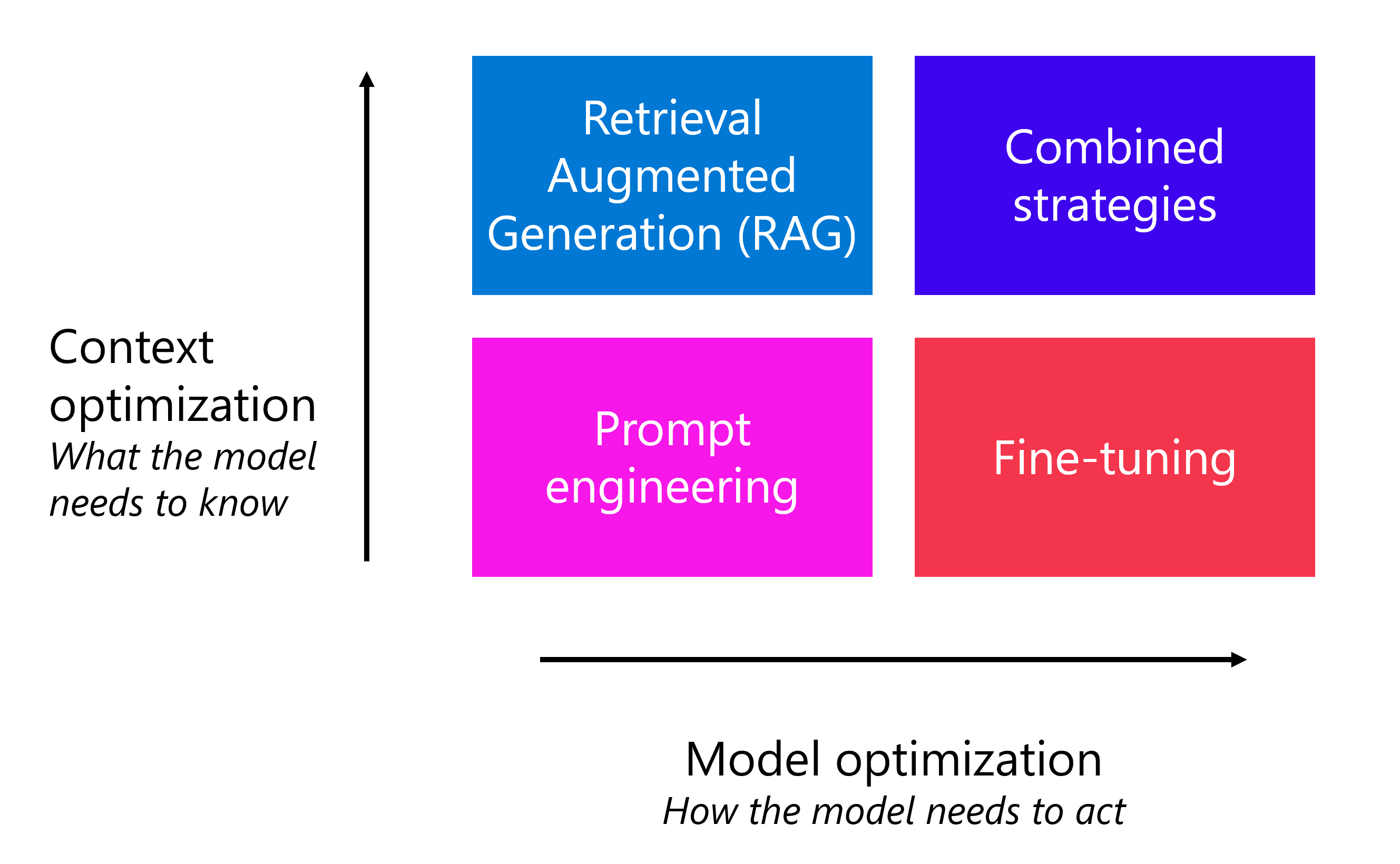
- コンテキストに合わせて最適化する: モデルにドメイン固有の知識がなく、応答の精度を最大限に高めたい場合。 RAG は、外部ソースから関連するデータを取得することで、これに対処します。
- モデルを最適化する: 動作の一貫性を最大限に高めることで、応答の形式、スタイル、またはトーンを改善する場合。 微調整は、目的の出力を示す例でモデルをトレーニングすることで、これに対処します。
プロンプト エンジニアリングは、双方向をサポートする基盤です。 プロンプト エンジニアリングを使用して、モデルに動作方法と焦点を合わせる方法を指示し、プロンプト エンジニアリングだけでは不十分な場合は RAG または微調整をレイヤー化します。
戦略を比較する
各戦略には、実装時間、複雑さ、コスト、および最適な機能の点で異なるトレードオフがあります。
| 戦略 | 実装する時間 | 複雑さ | 費用 | 最適な用途 |
|---|---|---|---|---|
| プロンプト エンジニアリング | 低 | 低 | 低 (トークンごとのみ) | トーン、フォーマット、および動作のガイド;迅速な反復;手順と例を提供する |
| RAG | ミディアム | ミディアム | Medium (検索インフラストラクチャ + ストレージ + トークンごと) | 事実の正確さ、ドメイン固有の知識、動的または頻繁に変化するデータ |
| 微調整 | 高 | 高 | 高 (トレーニング コンピューティング + モデル ホスティング + トークンごと) | 動作の一貫性、スタイルの適用、プロンプトの長さの短縮、モデルの蒸留 |
迅速なエンジニアリングのトレードオフ
プロンプト エンジニアリングは、最も迅速かつ安価な最適化戦略です。 インフラストラクチャを変更することなく、すぐに開始できます。 ただし、より長いプロンプトでは要求ごとにより多くのトークンが消費され、モデルは常に複雑な指示に従わない場合があります。 プロンプト エンジニアリングでは、学習されていない情報にモデルがアクセスすることはできません。
RAG のトレードオフ
RAG では、クエリ時に関連するデータ up-to-date がモデルに提供されるため、ファクトの精度が大幅に向上します。 ただし、search serviceの設定、インデックスの作成と保守、埋め込みの処理が必要です。 RAG 応答の品質は、検索インデックスの品質と、データのチャンクとインデックスの作成の程度によって異なります。
トレードオフの微調整
ファインチューニングを行うと、モデルの重みに望ましいパターンが埋め込まれるため、モデルの動作が最も一貫性を持つようになります。 また、プロンプトを短くすることで、要求ごとのコストを削減することもできます。 ただし、微調整には最も高い先行投資があります。トレーニング データを準備し、コンピューティングのトレーニング料金を支払い、カスタム モデルをホストする必要があります。 また、微調整されたモデルは、基本モデルが更新されたとき、または要件が変更されたときに再トレーニングする必要がある場合もあります。
より良い結果を得るための戦略を組み合わせる
最も効果的な生成 AI アプリケーションでは、多くの場合、複数の戦略が一緒に使用されます。 一般的な組み合わせを次に示します。
プロンプトエンジニアリング + RAG
これは最も一般的な組み合わせです。 プロンプト エンジニアリングを使用して、モデルの動作 (システム メッセージと命令を使用) と RAG を定義し、正確な応答に必要な事実コンテキストを提供します。 例えば次が挙げられます。
- システム メッセージは、旅行アドバイザーとして機能し、特定の方法で応答を書式設定するようにモデルに指示します。
- RAG は、モデルが実際のホテル名と価格で回答できるように、ホテル カタログから詳細を取得します。
この組み合わせは、 モデルの動作方法 と 、モデルが知る必要がある内容の両方に対処します。
迅速なエンジニアリングと微調整
この組み合わせは、モデルが特定のスタイルまたは形式に一貫して従う必要がある場合に使用します。 微調整されたモデルはベースラインの動作を処理し、システム メッセージは会話ごとに追加のコンテキストを提供します。 例えば次が挙げられます。
- 微調整されたモデルは、旅行代理店のブランドの声で常に応答するようにトレーニングされています。
- システム メッセージは、季節的なプロモーションを優先するなど、セッション固有の命令を追加します。
RAG + 微調整
事実に基づく動作と一貫した動作の両方が必要な場合は、これらの戦略を組み合わせます。 微調整されたモデルにより、応答スタイルが確実に信頼できる一方で、RAG は現在のドメイン固有のデータを提供します。 例えば次が挙げられます。
- 微調整されたモデルは、代理店のブランドの声と構造化された形式で応答を生成します。
- RAG は、最新のホテルの価格と可用性をカタログから取得します。
3つの戦略をすべて一緒に
最も要求の厳しいアプリケーションでは、プロンプト エンジニアリング、RAG、および微調整されたモデルを一緒に使用できます。 各レイヤーは、異なる懸念事項を処理します。
- 微調整により 、一貫性のあるスタイルと形式が保証されます。
- RAG は、最新の正確なドメインの知識を提供します。
- プロンプト エンジニアリング では、会話固有の命令とガードレールが追加されます。
意思決定フレームワークを適用する
使用する戦略を決定するときは、単純な作業を開始し、必要な場合にのみ複雑さを追加します。
- プロンプト エンジニアリングから始める: システム メッセージのテスト、少数の例、パラメーターのチューニング。 結果が要件を満たしているかどうかを評価します。
- 精度が重要な場合は RAG を追加します: モデルが正しく応答するために特定のデータ、現在のデータ、またはプライベート データにaccessする必要がある場合は、Azure AI 検索を使用して RAG を実装します。
- 一貫性が重要な場合は、微調整を追加します。詳細なプロンプトにもかかわらず、モデルが目的のスタイル、トーン、または形式を確実に維持しない場合は、代表的な例を使用してモデルを微調整します。
- 必要に応じて組み合わせる: アプリケーションの特定の要件に基づくレイヤー戦略。 すべてのアプリケーションで 3 つすべてが必要なわけではありません。
この増分アプローチを使用すると、不要なコストと複雑さを回避しながら、アプリケーションに必要な最適化レベルを確実に達成できます。