検索拡張生成を用いてモデルを基盤する
プロンプト エンジニアリングは、モデルの応答方法をガイドするのに役立ちますが、まだ持っていないモデルの知識を与えることはできません。 言語モデルは大規模なデータセットでトレーニングされますが、トレーニング データには期限があり、組織の個人情報は含まれません。 モデルに関連するコンテキストがない場合は、妥当に聞こえるが、実際には正しくない応答が生成される可能性があります。
この課題に対処するには、対応に基づく関連する事実データをモデルに提供することで、モデルを 作成 できます。 取得拡張生成 (RAG) は、言語モデルを接地するための最も一般的な手法です。
基礎を理解する
基盤を設けずに言語モデルを使用する場合、唯一の情報はそのトレーニングデータから来ます。 結果は文法的に正しく、論理的に構造化されている可能性がありますが、不正確な場合や、製造された詳細が含まれている可能性があります。 たとえば、「パリでどのホテルが利用可能ですか?」と尋ねると、データに基づかない場合は架空のホテル名が返される可能性があります。

プロンプトが 表示 されたら、ユーザーの質問と共に信頼できるソースからの関連データを提供します。 その後、モデルはそのデータに基づいて応答を生成し、より正確でコンテキストに関連する回答を生成します。
違いを考えてみましょう。
- 未設定: モデルはトレーニング データのみに依存し、ホテル名や詳細を発明する可能性があります。
- Grounded: モデルは、実際のホテル カタログ データをコンテキストとして受け取り、実際のホテル名、価格、および可用性で応答します。

グラウンディングでは、モデルをユーザーのニーズに固有の最新の情報に接続することで、応答の実際の精度が向上します。
RAG のしくみ
RAG は、データ ソースから関連情報を取得し、モデルが応答を生成する前にプロンプトに含めるパターンです。 このプロセスは、次の 3 つの手順に従います。
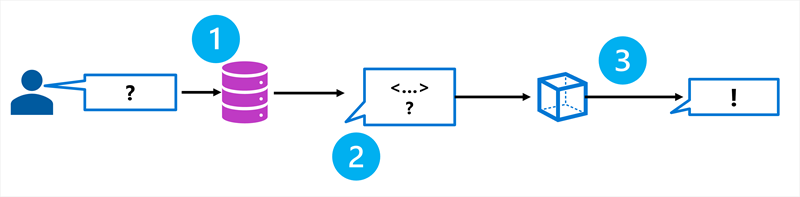
- 取得: データ ソースで、ユーザーの質問に関連する情報を検索します。
- 拡張: 取得した情報をコンテキストとしてプロンプトに追加します。
- 生成: 拡張プロンプトを言語モデルに送信して、固定応答を生成します。
指定したデータ ソースからコンテキストを取得することで、モデルがトレーニング データのみに依存するのではなく、関連する up-to-date 情報を使用するようにします。
検索用の埋め込みを作成する
RAG の重要な要素は、データ ソース内の最も関連性の高い情報を効率的に見つける機能です。 ここで埋め込みとベクター検索が行われるのです。
埋め込みは、テキストをベクトルとして数学的に表現したものです。これは、単語、文、または文書の意味をキャプチャする浮動小数点数のリストです。 埋め込みを作成するには、コンテンツを埋め込みモデル (Microsoft Foundry で使用できる Azure OpenAI 埋め込みモデルなど) に送信します。
たとえば、次の 2 つのドキュメントを想像してみてください。
- "子供たちは公園で楽しく遊びました。"
- "子どもたちは楽しそうに遊び場を走り回っていました。"
これらの文は異なる単語を使用しますが、同様の意味を持ちます。 各埋め込みを作成すると、ベクトルは多次元空間に近接し、セマンティックの類似性を反映します。

コサイン類似度 は、2 つのベクトル間の角度を計算することによって、2 つのベクトルの近さを測定します。 1 に近い値は、ベクトルが非常に類似していることを意味します。 この数学的アプローチを使用すると、正確な単語が一致しない場合でも、関連するドキュメントを見つけることができます。
取得にAzure AI Searchを使用する
Azure AI Search は、Microsoft Foundry の RAG ソリューションの取得コンポーネントを提供します。 これにより、独自のデータを取り込み、検索可能なインデックスを作成し、クエリを実行して関連情報を取得できます。

RAG でAzure AI Searchを使用するには、次の手順を実行します。
- Azure Blob Storage、Azure Data Lake Storage Gen2、Microsoft OneLake などのソースから Microsoft Foundry にデータを追加します。 ファイルを直接アップロードすることもできます。
- 埋め込みモデルを使用してインデックスを作成し、コンテンツのベクター表現を生成します。 インデックスはAzure AI Searchに格納されます。
- ユーザーが質問したときにインデックスに対してクエリを実行します。 システムは質問を埋め込みに変換し、最も類似したコンテンツを検索して、関連する結果を返します。
Azure AI Searchでは、いくつかの検索手法がサポートされています。
- キーワード検索: クエリ内の正確な用語をインデックス内のテキストに一致します。
- セマンティック検索: セマンティック モデルを使用して、正確なキーワードではなく、クエリの意味と一致します。
- ベクター検索: 埋め込みを使用して、意味的に類似したコンテンツを検索します。
- ハイブリッド検索: キーワード、セマンティック、ベクター検索を組み合わせて、最も正確な結果を得られます。 ハイブリッド検索は、生成型 AI アプリケーションに推奨されます。
Azure AI Foundry SDKを使用して RAG を実装する
Azure AI Search インデックスを作成したら、Microsoft Foundry projectを使用してモデルに接続できます。
azure-ai-projects SDK を使用すると、認証済みの OpenAI クライアントを取得し、Responses API を使用して根拠のある回答を生成できます。
次の Python コードは、基本的な実装を示しています。
from azure.ai.projects import AIProjectClient
from azure.identity import DefaultAzureCredential
project = AIProjectClient(
endpoint=os.environ["PROJECT_ENDPOINT"],
credential=DefaultAzureCredential(),
)
client = project.get_openai_client()
response = client.responses.create(
model="gpt-4o",
input=[
{"role": "system", "content": "You are a helpful travel advisor. "
"Use the following hotel data to answer: " + retrieved_context},
{"role": "user", "content": "Which hotels do you offer in Paris?"},
],
)
print(response.output_text)
この例では、retrieved_context は、Azure AI Search インデックスから返されるドキュメントを表します。 これらの結果をシステム メッセージに挿入することで、モデルの応答は、一般的なトレーニング知識ではなく、実際のデータに固定されます。
RAG を使用する場合
RAG は、次の場合に最も効果的です。
- モデルにはドメイン固有の知識が必要: 組織には、製品カタログ、ポリシー ドキュメント、内部knowledge baseなど、モデルがトレーニングされなかったプライベート データがあります。
- 情報は頻繁に変更されます。インベントリ、価格、ニュースなど、データは定期的に更新されます。 RAG は、再トレーニングを行わずに、クエリ時に現在のデータを取得します。
- 事実の精度は重要です。モデルの一般的な知識ではなく、実際のデータに基づく応答が必要です。
- 基本モデルのトレーニング データには、カットオフがあります。モデルのトレーニングのカットオフ日より後に発生したイベントまたは情報にアクセスできる必要があります。
旅行代理店のシナリオでは、RAG を使用すると、顧客は特定のホテル、目的地、予約ポリシーに関する質問をすることができます。これは、すべて代理店の実際のカタログ データに含まれています。
ヒント
独自の検索インフラストラクチャを管理せずに基礎知識を必要とするエージェントを構築する場合は、 Foundry IQ (AI エージェントの基礎を簡素化するマネージド ナレッジ ストア) を検討してください。 詳細については、「Build knowledge-enhanced AI agents with Foundry IQ を参照してください。