イベント処理を理解する
Azure Stream Analytics は、ストリーミング データの複合イベント処理と分析のためのサービスです。 Stream Analytics は、次の目的に使用されます。
- Azure イベント ハブ、Azure IoT Hub、Azure Storage Blob コンテナーなどの "入力" からデータを取り込みます。
- "クエリ" を使用してデータ値の選択、プロジェクション、集計を行うことでデータを処理します。
- Azure Data Lake Storage Gen2、Azure SQL Database、Azure Cosmos DB、Azure Functions、Azure Event Hubs、Microsoft Power BI などの 出力に結果を書き込みます。
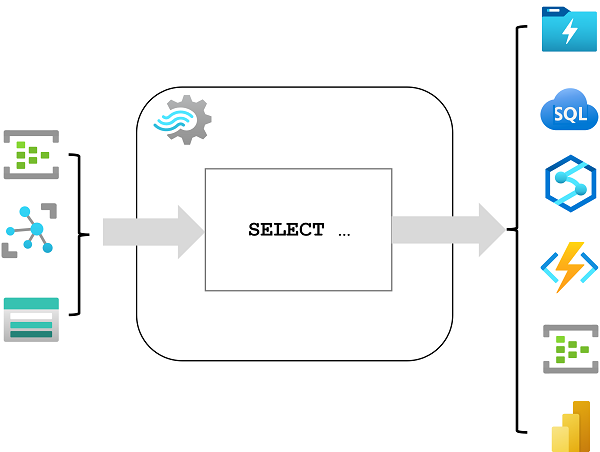
開始すると、Stream Analytics クエリが永続的に実行され、入力に到着した新しいデータが処理され、結果が出力に格納されます。
Stream Analytics では、 1 回の イベント処理と 少なくとも 1 回の イベント配信が保証されるため、イベントは失われることはありません。 イベントの配信が失敗した場合の復旧機能が組み込まれています。 また、Stream Analytics には、ジョブの状態を維持するための組み込みのチェックポイント処理が用意されており、反復可能な結果が生成されます。 Azure Stream Analytics はサービスとしてのプラットフォーム (PaaS) ソリューションであるため、フル マネージドで信頼性が高いです。 さまざまなソースと宛先との組み込みの統合により、柔軟なプログラミング モデルが提供されます。 Stream Analytics エンジンはメモリ内コンピューティングを有効にするため、高いパフォーマンスを提供します。
Azure Stream Analytics ジョブとクラスター
Azure Stream Analytics を使用する最も簡単な方法は、Azure サブスクリプションで Stream Analytics "ジョブ" を作成し、その入力と出力を構成して、ジョブでデータの処理に使用されるクエリを定義することです。 クエリは、構造化照会言語 (SQL) 構文を使用して表され、参照値を提供するために複数のデータ ソースから静的参照データを組み込み、入力から取り込まれたストリーミング データと組み合わせることができます。
ストリーム プロセスの要件が複雑な場合やリソースを大量に消費する場合は、Stream Analytics ジョブと同じ基になる処理エンジンを使用する Stream Analysis クラスターを作成できますが、専用テナントでは (そのため、処理は他の顧客の影響を受けないため)、構成可能なスケーラビリティを使用して、特定のシナリオに適したスループットとコストのバランスを定義できます。
入力
Azure Stream Analytics では、次の種類の入力からデータを取り込むことができます。
- Azure Event Hubs
- Azure IoT Hub
- Azure Blob ストレージ
- Azure Data Lake Storage Gen2
- Apache Kafka
入力は通常、ストリーミング データのソースを参照するために使用されます。これは、新しいイベント レコードが追加されると処理されます。 さらに、静的データを取り込むための 参照 入力を定義して、リアルタイムのイベントストリーム データを拡張することもできます。 たとえば、各気象ステーションの一意の ID を含むリアルタイム気象観測データのストリームを取り込み、気象ステーション ID をよりわかりやすい名前に一致させる静的な参照入力でそのデータを拡張できます。
出力
出力は、ストリーム処理の結果が送信される宛先です。 Azure Stream Analytics では、次の用途に使用できるさまざまな出力シンクがサポートされています。
- 詳細な分析のために結果を保持する。たとえば、Azure Data Lake Storage Gen2、Azure SQL Database、または Azure Cosmos DB に書き込みます。
- ログとテレメトリ データを大規模に分析する。たとえば、Azure Data Explorer に結果を送信します。
- データ ストリームのリアルタイムの視覚化を表示します。たとえば、Microsoft Power BI のデータセットにデータを追加します。
- ダウンストリーム処理用にフィルター処理または要約されたイベントを生成する。たとえば、Azure Event Hubs に結果を書き込みます。
クエリ
ストリーム処理ロジックはクエリにカプセル化されます。 クエリは、1 つ以上の入力からデータ フィールドを選択し、データをフィルター処理または集計し、結果を出力に書き込む SQL ステートメントを使用して定義されます。 たとえば、次のクエリでは、 気象イベント 入力のイベントをフィルター処理して、 温度 値が 0 未満のイベントからのデータのみを含め、結果を コールド temps 出力に書き込みます。
SELECT observation_time, weather_station, temperature
INTO cold-temps
FROM weather-events TIMESTAMP BY observation_time
WHERE temperature < 0
EventProcessedUtcTime という名前のフィールドは、Azure Stream Analytics クエリによってイベントが処理される時刻を定義するために自動的に作成されます。 このフィールドを使用してイベントのタイムスタンプを確認することも、この例に示すように TIMESTAMP BY 句を使用して別の DateTime フィールドを明示的に指定することもできます。 ストリーミング データの読み取り元の入力に応じて、1 つ以上の潜在的なタイムスタンプ フィールドが自動的に作成される場合があります。たとえば、 Event Hubs 入力を使用すると、 EventQueuedUtcTime という名前のフィールドが生成され、イベントがイベント ハブ キューで受信された時刻が記録されます。
タイムスタンプとして使用されるフィールドは、テンポラル ウィンドウでデータを集計するときに重要です。これについては、次に説明します。
コードなしのエディター
SQL を記述せずにストリーム処理ジョブを構築する場合、Azure Stream Analytics にはコードなしのエディターが含まれています。 Azure Stream Analytics ポータルまたは Azure Event Hubs ポータルからアクセスできます。 コードなしのエディターには、コードを記述せずに、入力ソースの接続、変換の追加 (ウィンドウと集計を含む)、出力の構成を行うドラッグ アンド ドロップ キャンバスが用意されています。
コードなしのエディターを使用すると、プロトタイプをすばやく作成し、必要に応じて生成された SQL クエリを表示またはカスタマイズして、より高度なシナリオを実現できます。