Microsoft Fabric のデータ エンジニアリングとデータ サイエンスのエクスペリエンスは、フル マネージドの Spark コンピューティング プラットフォームで動作します。 既定では、ワークスペース内のすべての Spark ジョブは同じプールとリソース設定を共有しますが、ワークロードによって要件が異なることがよくあります。 軽量データ変換では、大規模な機械学習ジョブと同じドライバー メモリは必要ありません。
ファブリック環境を使用すると、ワークロードごとに Spark コンピューティング構成を調整できるため、ワークスペース全体の既定値を変更することなく、各ノートブックまたは Spark ジョブ定義を適切なランタイム バージョン、プール、ドライバー/Executor のサイズ設定で実行できます。
ワークスペース レベルのコンピューティング設定を構成する
ワークスペース管理者は、環境項目がワークスペースの既定のコンピューティング構成をオーバーライドできるかどうかを制御します。 アイテム レベルのカスタマイズを無効にしておくと、ワークスペース全体で一貫したリソース使用量が確保されます。 これを有効にすると、メンバーと共同作成者は、個々のワークロードのコンピューティングを柔軟に調整できます。
ブラウザーで、 Fabric ポータルで Fabric ワークスペースに移動します。
ワークスペース設定を選択します。
[データ エンジニアリング/サイエンス] を選択し、[Spark の設定] を選択します。
[ プール ] タブを選択します。
項目のコンピュート構成をカスタマイズトグルをオンに切り替えます。
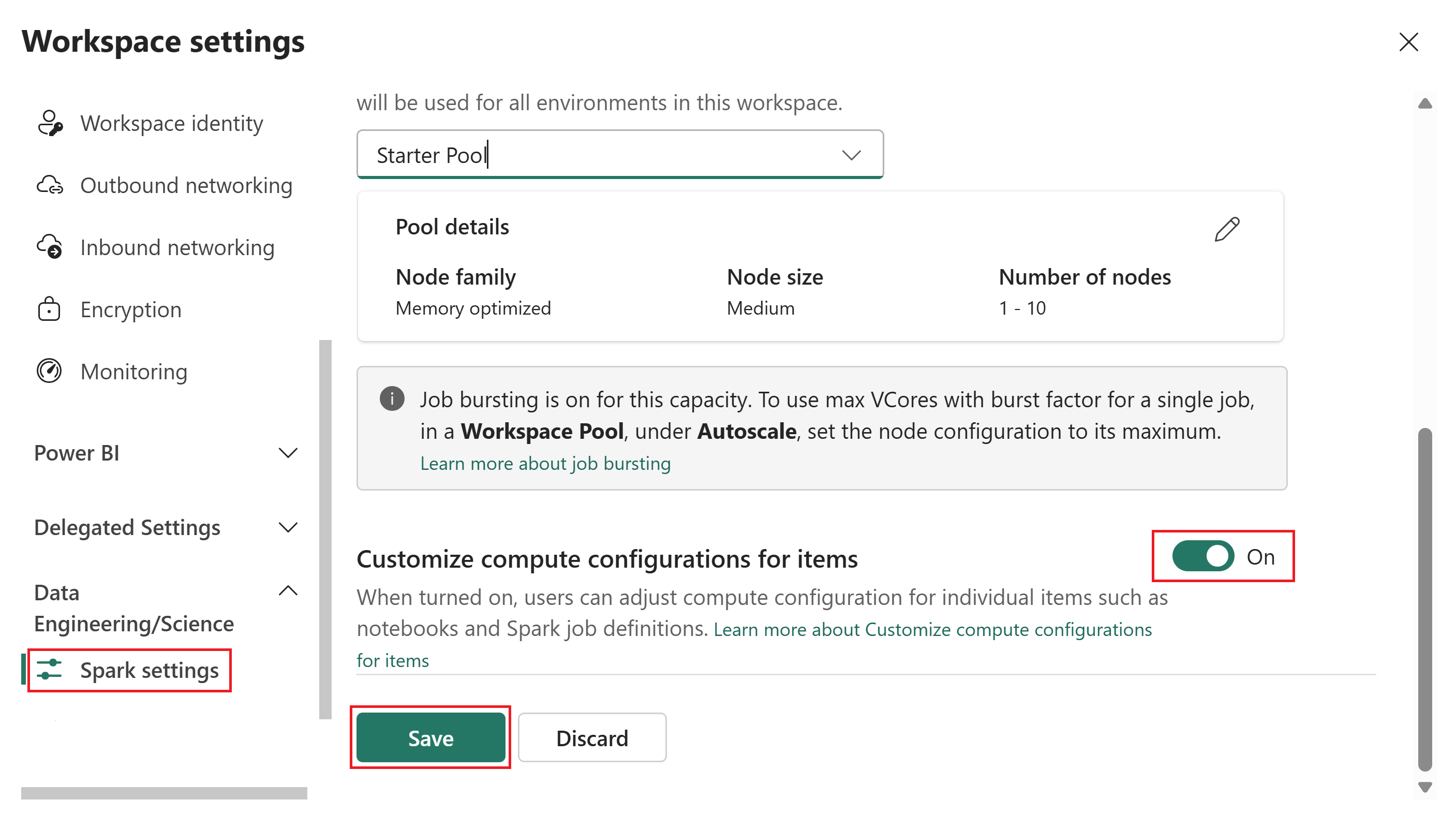
このトグルがオンの場合、メンバーと共同作成者は Fabric 環境でセッション レベルのコンピューティング構成を変更できます。 オフにすると、環境項目の [コンピューティング ] セクションが無効になり、すべての Spark ジョブでワークスペースの既定のプールが使用されます。
保存を選びます。

環境でコンピューティングを構成する
ワークスペース管理者が項目レベルのカスタマイズを有効にしたら、環境項目内でコンピューティング設定を構成できます。 これには、Spark ランタイムの選択、プールの選択、ドライバーと Executor リソースのチューニングが含まれます。
Spark ランタイムを選択する
環境項目を開きます。
[ ホーム ] タブで、[ ランタイム ] ドロップダウンを選択し、ランタイム バージョンを選択します。
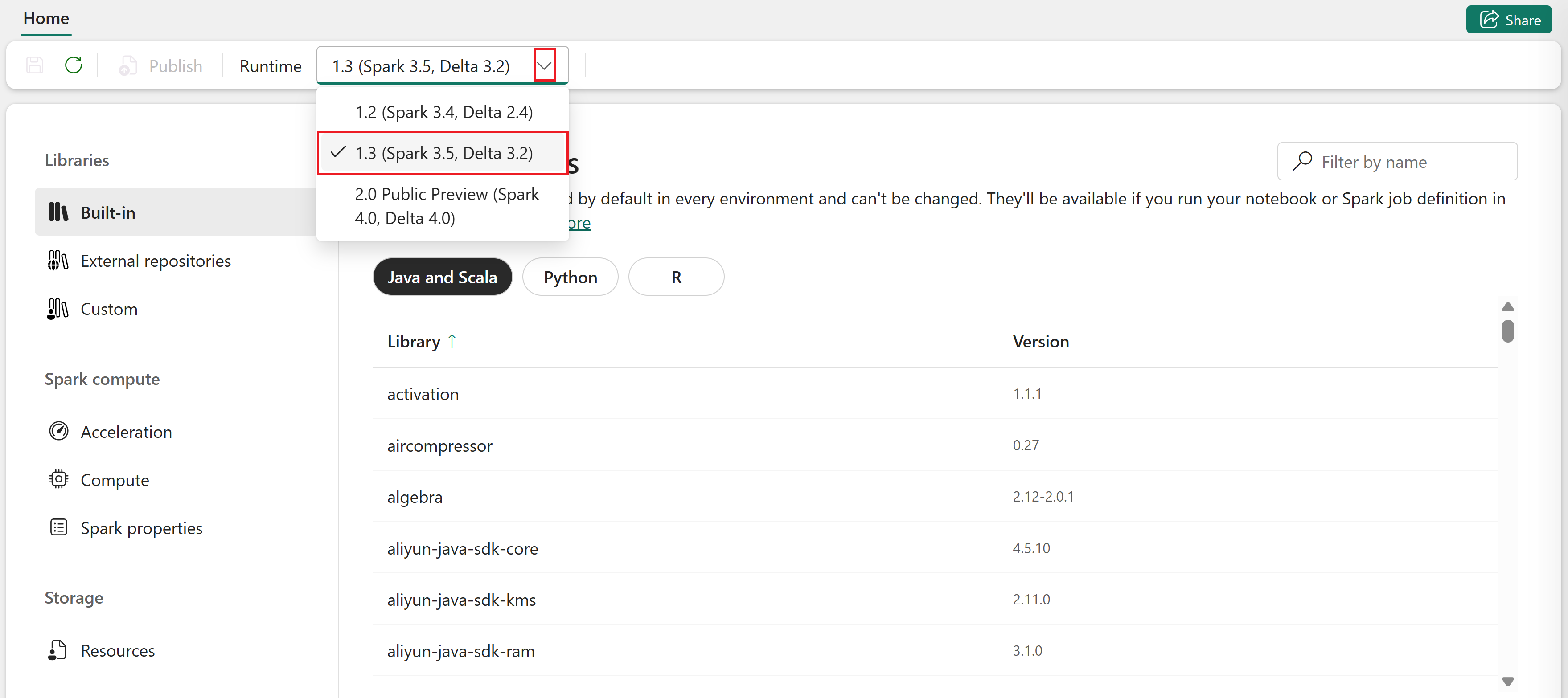

各 Spark ランタイム には、独自の既定の設定とプレインストールされたパッケージがあります。
Important
- ランタイムの変更は、環境を保存して発行するまで有効になりません。
- 既存のライブラリまたはコンピューティング設定が選択したランタイムと互換性がない場合、発行は失敗します。 互換性のない設定を削除または更新してから、もう一度発行します。
- 詳細な発行手順については、「 変更を保存して発行する」を参照してください。
プールを選択してコンピューティング プロパティを調整する
環境を開き、[ コンピューティング ] セクションに移動します。
[ 環境プール] で、ワークスペース管理者によって作成されたスターター プールまたはカスタム プールを選択します。
![環境の [コンピューティング] セクションでプールを選択する場所を示すスクリーンショット。](media/environment-introduction/environment-pool-selection.png)
[ コンピューティング ] ページのドロップダウンを使用して、選択したプールのセッション レベルの Spark プロパティを構成します。 使用可能な値は、プールのノード サイズによって異なります。
![環境の [コンピューティング] セクションのコンピューティング プロパティのドロップダウンを示すスクリーンショット。](media/environment-introduction/env-cores-selection.png)
プロパティの例としては、以下があります。
- Spark ドライバー コア – Spark ドライバーに割り当てられたコアの数。
- Spark ドライバー メモリ – Spark ドライバーに割り当てられたメモリの量。
- Spark Executor コア – 各 Executor に割り当てられたコアの数。
- Spark executor メモリ – 各 executor に割り当てられたメモリ量。
![環境の [コンピューティング] セクションでプールを選択する場所を示すスクリーンショット。](media/environment-introduction/environment-pool-selection.png#lightbox)
![環境の [コンピューティング] セクションのコンピューティング プロパティのドロップダウンを示すスクリーンショット。](media/environment-introduction/env-cores-selection.png#lightbox)
使用可能なプールのサイズとリソースの制限の詳細については、 Fabric の Spark コンピューティングに関するページを参照してください。
注
Spark プロパティは、 spark.conf.set 制御アプリケーション レベルのパラメーターを使用して設定され、ここで説明する環境コンピューティング設定とは関係ありません。