Tip
Microsoft Fabric Data Warehouse は、将来のアーキテクチャ、組み込みの AI、および新機能を備えた、Data Lake 基盤上のエンタープライズ 規模のリレーショナル ウェアハウスです。 データ ウェアハウスを初めて使用する場合は、Fabric Data Warehouseから始めます。 既存の dedicated SQL プール ワークロードは、Fabric にアップグレードして、データ サイエンス、リアルタイム分析、レポートの新機能にアクセスできます。
- Fabric無料試用版を開始します。
- Fabric Data Warehouse 用マイグレーションアシスタント
この記事では、Azure Synapse Analytics のサーバーレス SQL プールのコストを見積もって管理する方法について説明します。
- クエリを発行する前に処理されたデータの量を見積もる
- コスト管理機能を使用して予算を設定する
Azure Synapse Analytics のサーバーレス SQL プールのコストは、Azure 課金の月額料金の一部に過ぎません。 他の Azure サービスを使用している場合は、サードパーティのサービスを含め、Azure サブスクリプションで使用されているすべての Azure サービスとリソースに対して課金されます。 この記事では、Azure Synapse Analytics でサーバーレス SQL プールのコストを計画および管理する方法について説明します。
処理されたデータ
処理されるデータ は、クエリの実行中にシステムが一時的に格納するデータの量です。 処理されるデータは、次の数量で構成されます。
- ストレージから読み取られたデータの量。 この金額には次のものが含まれます。
- データの読み取り中に読み取られたデータ。
- メタデータの読み取り中に読み取られたデータ (Parquet などのメタデータを含むファイル形式の場合)。
- 中間結果のデータ量。 このデータは、クエリの実行中にノード間で転送されます。 これには、エンドポイントへのデータ転送が非圧縮形式で含まれます。
- ストレージに書き込まれるデータの量。 CETAS を使用して結果セットをストレージにエクスポートする場合、書き出されたデータの量は、CETAS の SELECT 部分に対して処理されたデータの量に追加されます。
ストレージからのファイルの読み取りは高度に最適化されています。 このプロセスでは、次のものが使用されます。
- プリフェッチ。読み取られたデータ量にオーバーヘッドが発生する可能性があります。 クエリがファイル全体を読み取る場合、オーバーヘッドは発生しません。 TOP N クエリのようにファイルが部分的に読み取られた場合、プリフェッチを使用してもう少し多くのデータが読み取られます。
- 最適化されたコンマ区切り値 (CSV) パーサー。 PARSER_VERSION='2.0' を使用して CSV ファイルを読み取ると、ストレージから読み取られたデータの量がわずかに増加します。 最適化された CSV パーサーは、同じサイズのチャンクでファイルを並列に読み取ります。 チャンクには必ずしも行全体が含まれているとは限りません。 すべての行が確実に解析されるように、最適化された CSV パーサーは隣接するチャンクの小さなフラグメントも読み取ります。 このプロセスにより、わずかなオーバーヘッドが増加します。
Statistics
サーバーレス SQL プール クエリ オプティマイザーは、統計に依存して最適なクエリ実行プランを生成します。 統計は手動で作成できます。 それ以外の場合は、サーバーレス SQL プールによって自動的に作成されます。 どちらの方法でも、統計は、指定されたサンプル レートで特定の列を返す別のクエリを実行することによって作成されます。 このクエリには、処理されたデータの量が関連付けられています。
作成された統計の恩恵を受けるのと同じクエリまたはその他のクエリを実行すると、可能であれば統計が再利用されます。 統計を作成するために追加のデータは処理されません。
Parquet 列の統計が作成されると、関連する列のみがファイルから読み取られます。 CSV 列の統計が作成されると、ファイル全体が読み取られ、解析されます。
丸め
処理されるデータの量は、クエリごとに最も近い MB に切り上げられます。 各クエリには、少なくとも 10 MB のデータが処理されます。
処理されるデータに含まれないもの
- サーバー レベルのメタデータ (ログイン、ロール、サーバー レベルの資格情報など)。
- エンドポイントで作成するデータベース。 これらのデータベースには、メタデータ (ユーザー、ロール、スキーマ、ビュー、インライン テーブル値関数 [TVF]、ストアド プロシージャ、データベース スコープ資格情報、外部データ ソース、外部ファイル形式、外部テーブルなど) のみが含まれます。
- スキーマ推論を使用すると、ファイル フラグメントが読み取られ、列名とデータ型が推論され、読み取られたデータ量が処理されたデータ量に加算されます。
- CREATE STATISTICS ステートメントを除くデータ定義言語 (DDL) ステートメントは、指定されたサンプルパーセンテージに基づいてストレージからのデータを処理するためです。
- メタデータのみのクエリ。
処理されるデータの量を減らす
データをパーティション分割して Parquet などの圧縮された列ベースの形式に変換することで、処理されるデータのクエリごとの量を最適化し、パフォーマンスを向上させることができます。
例示
3 つのテーブルを想像してみてください。
- population_csvテーブルは、5 TB の CSV ファイルでサポートされています。 ファイルは、同じサイズの 5 つの列に編成されます。
- population_parquet テーブルには、population_csv テーブルと同じデータがあります。 これは、1 TB の Parquet ファイルによってサポートされています。 データは Parquet 形式で圧縮されているため、このテーブルは前のテーブルよりも小さくなります。
- very_small_csv テーブルには、100 KB の CSV ファイルが含まれます。
クエリ 1: SELECT SUM(population) FROM population_csv
このクエリでは、ファイル全体を読み取って解析し、人口列の値を抽出します。 ノードはこのテーブルのフラグメントを処理し、各フラグメントの母集団の合計がノード間で転送されます。 最終的な合計がエンドポイントに転送されます。
このクエリでは、5 TB のデータに加えて、フラグメントの合計を転送するための少量のオーバーヘッドが処理されます。
クエリ 2: SELECT SUM(population) FROM population_parquet
Parquet などの圧縮形式や列ベースの形式に対してクエリを実行すると、クエリ 1 よりも読み取るデータが少なくなります。 この結果は、サーバーレス SQL プールがファイル全体ではなく 1 つの圧縮列を読み取るためです。 この場合、0.2 TB が読み取られます。 (同じサイズの 5 つの列はそれぞれ 0.2 TB です)。ノードはこのテーブルのフラグメントを処理し、各フラグメントの母集団の合計がノード間で転送されます。 最終的な合計がエンドポイントに転送されます。
このクエリでは、0.2 TB に加えて、フラグメントの合計を転送するための少量のオーバーヘッドが処理されます。
クエリ 3: SELECT * FROM population_parquet
このクエリでは、すべての列が読み取られ、すべてのデータが圧縮されていない形式で転送されます。 圧縮形式が 5:1 の場合、クエリは 1 TB を読み取り、5 TB の非圧縮データを転送するため、6 TB を処理します。
クエリ 4: very_small_csvからの SELECT COUNT(*)
このクエリは、ファイル全体を読み取ります。 このテーブルのストレージ内のファイルの合計サイズは 100 KB です。 ノードはこのテーブルのフラグメントを処理し、各フラグメントの合計がノード間で転送されます。 最終的な合計がエンドポイントに転送されます。
このクエリでは、100 KB をわずかに超えるデータが処理されます。 このクエリで処理されるデータの量は、この記事の「丸め」セクションで指定されているとおり、10 MB に丸められます。
コスト管理
サーバーレス SQL プールのコスト管理機能を使用すると、処理されるデータ量の予算を設定できます。 日、週、月に対して処理されるデータの予算を TB 単位で設定できます。 同時に、1 つ以上の予算を設定できます。 サーバーレス SQL プールのコスト管理を構成するには、Synapse Studio または T-SQL を使用できます。
Synapse Studio でサーバーレス SQL プールのコスト管理を構成する
Synapse Studio でサーバーレス SQL プールのコスト制御を構成するには、Analytics プールの下にある SQL プール項目を選択するよりも、左側のメニューの [管理] 項目に移動します。 サーバーレス SQL プールをポイントすると、コスト管理のアイコンが表示されます。このアイコンをクリックします。
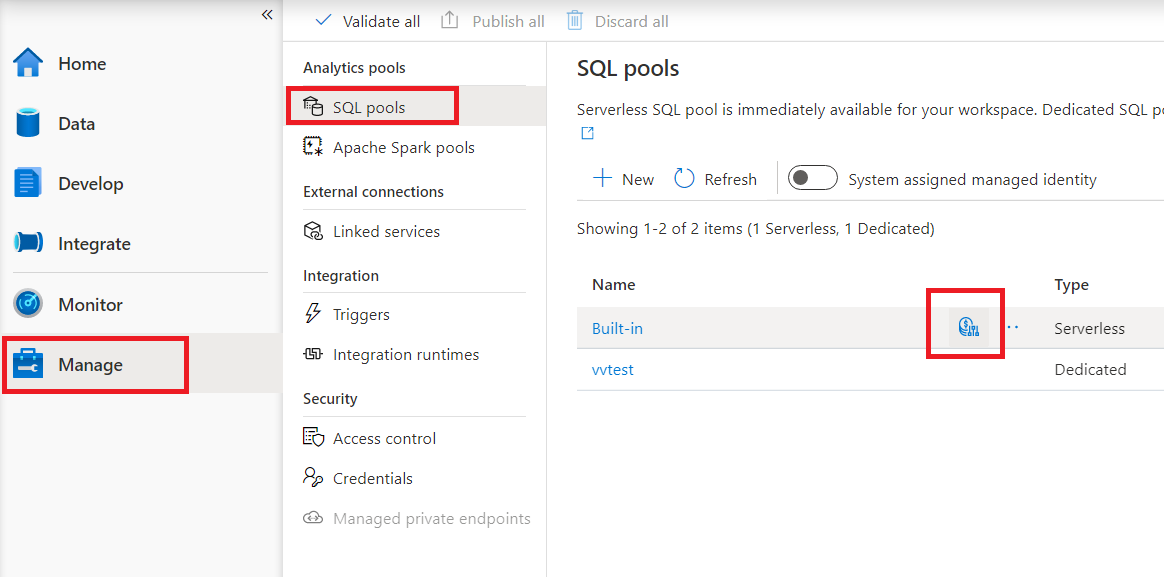
コスト管理アイコンをクリックすると、サイド バーが表示されます。
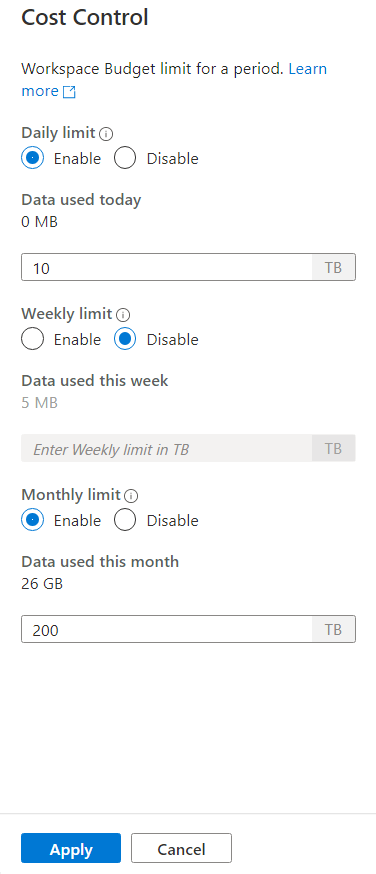
1 つ以上の予算を設定するには、まず、テキスト ボックスに整数値を入力するよりも、設定する予算の [有効にする] ラジオ ボタンをクリックします。 値の単位は TB です。 予算を構成したら、サイド バーの下部にある [適用] ボタンをクリックします。 これで予算が設定されました。
T-SQL でサーバーレス SQL プールのコスト管理を構成する
T-SQL でサーバーレス SQL プールのコスト制御を構成するには、次のストアド プロシージャの 1 つ以上を実行する必要があります。
sp_set_data_processed_limit
@type = N'daily',
@limit_tb = 1
sp_set_data_processed_limit
@type= N'weekly',
@limit_tb = 2
sp_set_data_processed_limit
@type= N'monthly',
@limit_tb = 3334
現在の構成を確認するには、次の T-SQL ステートメントを実行します。
SELECT * FROM sys.configurations
WHERE name like 'Data processed %';
現在の日、週、または月の間に処理されたデータの量を確認するには、次の T-SQL ステートメントを実行します。
SELECT * FROM sys.dm_external_data_processed
コスト管理で定義されている制限を超える
クエリの実行中に制限を超えた場合、クエリは終了しません。
制限を超えると、期間に関する詳細、その期間に対して定義された制限、およびその期間に対して処理されたデータを含むエラー メッセージを含む新しいクエリが拒否されます。 たとえば、新しいクエリが実行され、週単位の制限が 1 TB に設定され、超過した場合、エラー メッセージは次のようになります。
Query is rejected because SQL Serverless budget limit for a period is exceeded. (Period = Weekly: Limit = 1 TB, Data processed = 1 TB))
次のステップ
パフォーマンスのためにクエリを最適化する方法については、 サーバーレス SQL プールのベスト プラクティスに関するページを参照してください。