このページでは、Azure Databricks ワークスペースからデータを照会し、Databricks Connector for Google Sheets を使用して Google スプレッドシートにインポートする方法について説明します。 テーブルを直接選択したり、SQL クエリを記述したり、パラメーターを追加したり、ピボット テーブルを作成したりできます。 コネクタは、結果を更新して既存のクエリを再利用できるように、すべてのクエリをインポートとして自動的に保存します。
前提条件
インポート方法を選択する
テーブルを選択するか、SQL クエリを記述することで、Azure Databricksから Google スプレッドシートにデータをインポートできます。 データがインポートされると、クエリはシートに関連付けられます。 このコネクタでは、Google スプレッドシートの上限 である 1,000 万セルまでのインポートがサポートされています。
シート名を変更すると、マッピングが中断されます。 名前の変更を処理する方法については、「 制限事項」を参照してください。
Important
"データの選択" を使用して Unity カタログメトリック ビューをインポートする場合、Unity カタログメトリックはピボットデータを表しているため、ピボットテーブルとしてのみインポートできます。
Warnung
適用されたテーブルの書式を削除または変更しないでください。 Google Sheets テーブル識別子は、インポートを更新するために使用されます。 書式設定を削除すると、更新エラーが発生します。
開始するインポート方法を選択します。
データの選択
Azure Databricksのテーブルからデータをインポートするには、次の操作を行います。
- Google Sheets Databricks Connector サイドバーの [ 新しいインポート] の [ インポート] メソッドで、[ データの選択] を選択します。
- [ カタログ] で、カタログ、スキーマ、テーブルのドロップダウン メニューを使用して、インポートするテーブルを検索します。
- 必要に応じて、 資産名 を更新して、このインポートの名前を変更します。
- 必要に応じて、[ フィールド] で、含める列または除外する列を選択します。
- 必要に応じて 、ピボット テーブルとしてインポートできます。
- フィルターを追加するには、+ フィルターをフィルターの下でクリックします。 フィルターを適用する 列 とフィルターの種類を選択 します。
- 必要に応じて、[ 行の制限 ] をオンにして、インポートする行数の制限を設定します。 この制限は既定で有効になっており、1,000 行に設定されています。
- [ 出力先] で、クエリ結果を新しいシートに保存するか、現在のシートに保存するかを選択します。
- 新しいシートを選択する場合は、シートの名前を入力します。
- 現在のシートを選択する場合は、データの追加を開始するセルを指定します。
- [ 保存] & [インポート] をクリックしてシートを設定します。
SQL クエリを記述する
新しい SQL クエリを作成するには、次の操作を行います。
- Google Sheets Databricks Connector サイドバーの [ 新しいインポート] で、[ SQL の書き込み] を選択します。
- Databricks では、特定できるようにクエリの名前を入力することをお勧めします。
- カタログ、スキーマ、およびテーブルを参照できます。
- [クエリ] テキストに、SQL クエリを入力します。
- 必要に応じて 、クエリ パラメーターを追加できます。
- [ 出力先] で、クエリ結果を新しいシートに保存するか、現在のシートに保存するかを選択します。
- 新しいシートを選択する場合は、シートの名前を入力します。
- 現在のシートを選択する場合は、データの追加を開始するセルを指定します。
- [ 保存] & [インポート] をクリックしてクエリを実行し、シートにデータを入力します。
注
クエリの実行は 15 分後にタイムアウトになります。 クエリがこの制限を超えると、自動的に取り消されます。 大きな結果セットの場合、最初の 1,000 行が直ちに書き込まれ、残りのデータは段階的にフェッチされます。 データフェッチが中断された場合、部分的な結果はシートに残り、クエリを再実行することでクリアできます。

クエリ パラメーターを追加する (省略可能)
SQL クエリにクエリ パラメーターを追加するには:
クエリに、
:parameter_nameの形式で少なくとも 1 つのクエリ パラメーターがあることを確認します。 クエリ パラメーターの詳細については、「 名前付きパラメーター マーカーの使用」を参照してください。[ + パラメーターの追加] をクリックします。
最初のボックスにパラメーターを入力します。 パラメーター名がクエリ エディターで入力したものと一致していることを確認します。
2 番目のボックスに、シート名の後の感嘆符を含む、パラメーター値のシート名とセルの位置を入力します。
クエリ パラメーターをさらに追加するには、[ + パラメーターの追加] をもう一度クリックします。
たとえば、次のクエリには、シート
:trip_distanceセル H1 で定義されているクエリ パラメーターsheet_1が含まれています。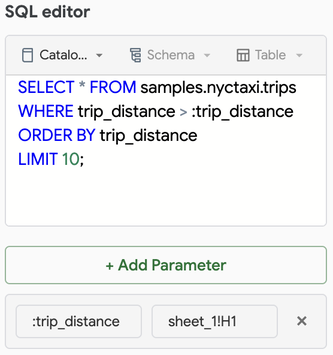
ピボット テーブルとしてインポートする (省略可能)
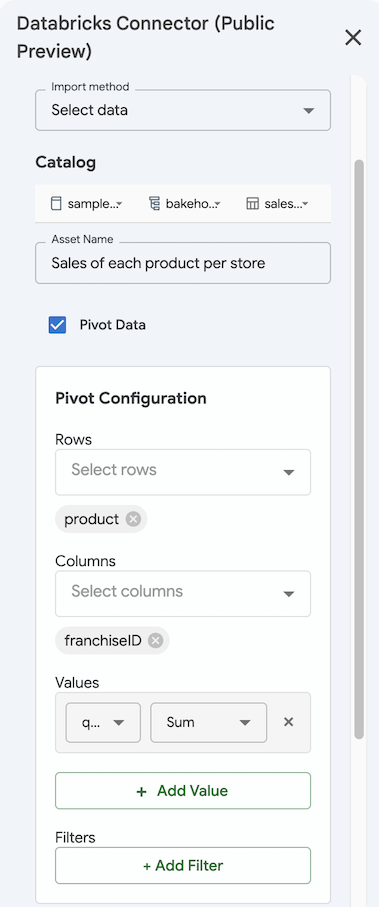
データをピボット テーブルとしてインポートするには、次の操作を行います。
- [データの選択] メソッドを使用して データ をインポートするには、[ ピボット テーブル ] チェック ボックスをオンにします。
- [ ピボットの構成] で、ピボット テーブルのディメンションの 行 と 列 を選択します。
- 集計する値を指定します。 [ + 値の追加] をクリックし、列と集計方法を選択します。
- 必要に応じて、[+ フィルターの 追加 ] をクリックしてフィルターを追加し、 列 と フィルターの種類を選択します。
- [ 保存] および [インポート] をクリックして、結果をピボット テーブルとしてインポートします。 ピボット テーブルのインポートは、新しいシートに自動的にインポートされます。
インポートされたデータを管理する
Azure Databricksからインポートするデータを管理するには、次の操作を行います。
コネクタサイドバーの[ 保存されたインポート ]タブをクリックします。
インポートされたデータを手動で更新するには:
- 1 つのインポートを更新する: クエリ名の横にある更新アイコンをクリックします。
- すべてのインポートを更新する: カレンダー アイコンの横にある [ 保存されたインポート ] タブの上部にある更新アイコンをクリックします。
定期的なスケジュールでインポートを自動的に更新するには、「 Google スプレッドシートでデータの更新をスケジュールする」を参照してください。
インポート先のシートを確認するには、[
![Kebab] メニュー アイコンをクリックします。](../../_static/images/product-icons/overflowicon.svg) >クエリ名の横にあるシートに移動します。
>クエリ名の横にあるシートに移動します。インポートを編集するには、[
>クエリ名の横にある [編集] をクリックします。インポートを削除するには、[
>クエリ名の横にある [削除] をクリックします。 これにより、Google スプレッドシートにインポートされたデータではなく、クエリが削除されます。 インポートしたデータは手動で削除する必要があります。

共有への影響
このアドオンは、Google シートを共有する機能には影響しません。 ただし、ファイルを共有する方法は、受信者がアドオンを使用して実行できるアクションに影響します。
- ビューアーまたはコメンダー ロールを持つ受信者は、アドオンにアクセスできません。
- エディター ロールと同等のデータ資産アクセス権を持つ受信者は、Google アカウントでアドオンを使用できます。 所有者と同じようにコネクタを使用できます。
- エディター ロールを持ち、基になるリソースに同じアクセス権を持つ受信者は、同じAzure Databricks ワークスペースにログインしている場合、インポートを更新できます。
制限事項
既存のインポートにアタッチされているシートの名前を変更または削除すると、インポートを更新できなくなります。 これを修正するには、次 のいずれかの 操作を行います。
- まったく同じ名前でシートを再作成します。
- 新しいインポートを作成するには、[ソースとして クエリを選択 ] を選択し、インポートを再利用して、[ 新規として保存] をクリックします。
2 つのクエリが同じ範囲または重複する範囲にマップされた場合、アドオンには最後に実行されたクエリの結果が表示されます。 これにより、以前にインポートされたデータが上書きされます。