Important
この機能は ベータ版です。 アカウント管理者は、アカウント コンソール の [プレビュー ] ページからこの機能へのアクセスを制御できます。 Manage Azure Databricks プレビューを参照してください。
Azure Databricksコーディング エージェント統合を使用すると、Cursor、Gemini CLI、Codex CLI などのコーディング エージェントのアクセスと使用を管理できます。 Unity AI Gateway 上に構築され、コーディング ツールのレート制限、使用状況の追跡、推論テーブルを提供します。
Features
- アクセス: 1 つの請求書の下にあるさまざまなコーディング ツールとモデルに直接アクセスできます。
- 可観測性: すべてのコーディング ツールの使用状況、支出、メトリックを追跡するための 1 つの統合ダッシュボード。
- 統合ガバナンス: 管理者は、Unity AI Gateway を介してモデルのアクセス許可とレート制限を直接管理できます。
Requirements
- Unity AI Gateway プレビューがあなたのアカウントに対して有効になりました。 Manage Azure Databricks プレビューを参照してください。
- Unity AI Gateway でサポートされているリージョン内のAzure Databricks ワークスペース。
- ワークスペースに対して有効になっている Unity カタログ。 「Unity Catalog のワークスペースを有効にする」を参照してください。
設定
最も速く開始する方法は、ucode(1 つのコマンドで Unity AI Gateway を使用してサポートされているコーディング エージェントをインストール、認証、構成するAzure Databricksの CLI) を使用することです。
ucode を使用する (推奨)
ucode (Unity AI Gateway のコーディング CLI) は、Unity AI Gateway に対してコーディング エージェントを実行するための単一のエントリ ポイントです。 OAuth を処理し、各エージェントの構成ファイルを書き込み、登録したすべての LLM または MCP サーバーを介してトラフィックをルーティングします。 サポートされているエージェント:
手順 1: ucode をインストールする
uv tool install git+https://github.com/databricks/ucode
Python 3.12 以降と uv が必要です。
手順 2: コーディング エージェントを開く
目的のエージェントを実行します。 最初の起動時に、ucode は、Azure Databricks ワークスペースの URL の入力を求め、エージェントの構成ファイルを自動的に認証して書き込みます。 以降の起動は、エージェントに直接移動します。
ucode codex # OpenAI Codex
ucode gemini # Gemini CLI
ucode opencode # OpenCode
ucode copilot # GitHub Copilot CLI
ucode pi # Pi
ucode は、エージェント名の後のフラグを基になるツールに渡します。次に例を示します。
ucode codex --full-auto
複数のコーディング エージェントを同時に構成するには、次のコマンドを実行します。
ucode configure
MCP 対応エージェントに Azure Databricks の MCP サーバー(Unity Catalog 関数、ベクトル検索、SQL ウェアハウス、および検出された外部接続)を登録するには:
ucode configure mcp
過去 7 日間の Unity AI Gateway の使用状況の概要を表示するには:
ucode usage
完全なコマンド リファレンスについては、次を実行します。
ucode --help
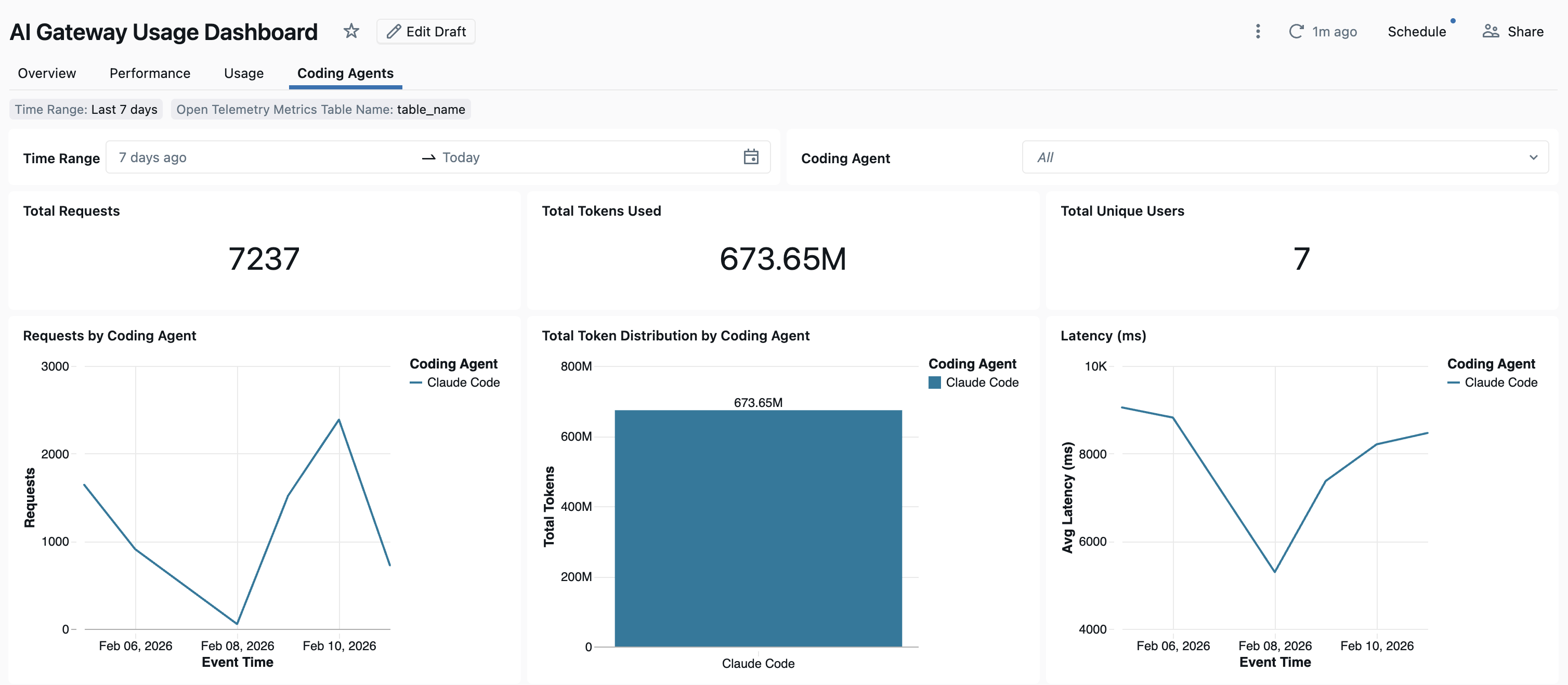
Dashboard
Unity AI Gateway を使用してコーディング エージェントの使用状況を追跡した後は、組み込みのダッシュボードでメトリックを表示および監視できます。
ダッシュボードを開くには、[AI ゲートウェイ] ページから [ダッシュボードの表示 ] を選択します。 このアクションにより、コーディング ツールを使用するためのグラフを含む事前構成済みのダッシュボードが作成されます。
![[ダッシュボードの表示] ボタン](../_static/images/ai-gateway/view-dashboard-beta.png)
手動セットアップ
エージェントを自分で構成する場合は、次の手順に従います。
カーソル IDE
Unity AI Gateway エンドポイントを使用するように Cursor を構成するには:
手順 1: ベース URL と API キーを構成する
カーソルを開き、 設定>Cursor 設定>Models>API キーに移動します。
OpenAI ベース URL のオーバーライドを有効にし、URL を入力します。
https://<workspace-url>/ai-gateway/cursor/v1<workspace-url>をAzure Databricksワークスペースの URL に置き換えます。Azure Databricks個人用アクセス トークンを OpenAI API Key フィールドに貼り付けます。
手順 2: カスタム モデルを追加する
- [カーソル設定] で [ + カスタム モデルの追加] をクリックします。
- Unity AI Gateway エンドポイント名を追加し、トグルを有効にします。
注
現在、Azure Databricks作成された基盤モデル エンドポイントのみがサポートされています。
手順 3: 統合をテストする
-
Cmd+L(macOS) またはCtrl+L(Windows/Linux) で Ask モードを開き、モデルを選択します。 - メッセージを送信します。 すべての要求がAzure Databricks経由でルーティングされるようになりました。
Codex コマンドラインインターフェース
手順 1: Codex CLI をインストールまたは更新する
Codex CLI バージョン 0.118 以降をインストールまたは更新します。
npm install -g @openai/codex@latest
手順 2: Codex 構成ファイルを作成または更新する
~/.codex/config.tomlで Codex 構成ファイルを作成または編集します。
profile = "default"
[profiles.default]
model_provider = "Databricks"
[model_providers.Databricks]
name = "Databricks :re[ai-gateway]"
base_url = "<workspace-url>/ai-gateway/codex/v1"
wire_api = "responses"
[model_providers.Databricks.auth]
command = "sh"
args = ["-c", "databricks auth token --host <workspace-url> --output json | jq -r '.access_token'"]
timeout_ms = 5000
refresh_interval_ms = 1800000
<workspace-url>をAzure Databricksワークスペースの URL に置き換えます。
手順 3: ワークスペースに対する認証
注
これは 1 回だけ行う必要があります。 Codex を起動するたびに再認証する必要はありません。
まず、Azure Databricks CLI がインストールされていることを確認します。 手順については、 Databricks CLI のインストールまたは更新 を参照してください。
次に、次の認証を行います。
databricks auth login --host <workspace-url>
<workspace-url>をAzure Databricksワークスペースの URL に置き換えます。
手順 4: Codex を開始する
codex
モデルを変更するには、 /modelを使用します。
Gemini CLI
手順 1: Gemini CLI の最新バージョンをインストールする
npm install -g @google/gemini-cli@nightly
手順 2: 環境変数を構成する
ファイル ~/.gemini/.env を作成し、次の構成を追加します。 詳細については、 Gemini CLI 認証に関するドキュメント を参照してください。
GEMINI_MODEL=databricks-gemini-2-5-flash
GOOGLE_GEMINI_BASE_URL=https://<workspace-url>/ai-gateway/gemini
GEMINI_API_KEY_AUTH_MECHANISM="bearer"
GEMINI_API_KEY=<databricks_pat_token>
<workspace-url>をAzure Databricksワークスペースの URL に置き換え、<databricks_pat_token>を個人用アクセス トークンに置き換えます。
OpenTelemetry データ収集を設定する
Azure Databricksでは、OpenTelemetry メトリックとログをコーディング エージェントから Unity カタログのマネージド デルタ テーブルにエクスポートできます。 すべてのメトリックは、OpenTelemetry 標準メトリック プロトコルを使用してエクスポートされた時系列データであり、ログは OpenTelemetry ログ プロトコルを使用してエクスポートされます。
Requirements
- Azure Databricksでプレビュー版のOpenTelemetryが有効になりました。 Manage Azure Databricks プレビューを参照してください。
手順 1: Unity カタログで OpenTelemetry テーブルを作成する
OpenTelemetry メトリックとログ スキーマを使用して事前構成された Unity カタログのマネージド テーブルを作成します。
メトリック テーブル
CREATE TABLE <catalog>.<schema>.<table_prefix>_otel_metrics (
name STRING,
description STRING,
unit STRING,
metric_type STRING,
gauge STRUCT<
start_time_unix_nano: LONG,
time_unix_nano: LONG,
value: DOUBLE,
exemplars: ARRAY<STRUCT<
time_unix_nano: LONG,
value: DOUBLE,
span_id: STRING,
trace_id: STRING,
filtered_attributes: MAP<STRING, STRING>
>>,
attributes: MAP<STRING, STRING>,
flags: INT
>,
sum STRUCT<
start_time_unix_nano: LONG,
time_unix_nano: LONG,
value: DOUBLE,
exemplars: ARRAY<STRUCT<
time_unix_nano: LONG,
value: DOUBLE,
span_id: STRING,
trace_id: STRING,
filtered_attributes: MAP<STRING, STRING>
>>,
attributes: MAP<STRING, STRING>,
flags: INT,
aggregation_temporality: STRING,
is_monotonic: BOOLEAN
>,
histogram STRUCT<
start_time_unix_nano: LONG,
time_unix_nano: LONG,
count: LONG,
sum: DOUBLE,
bucket_counts: ARRAY<LONG>,
explicit_bounds: ARRAY<DOUBLE>,
exemplars: ARRAY<STRUCT<
time_unix_nano: LONG,
value: DOUBLE,
span_id: STRING,
trace_id: STRING,
filtered_attributes: MAP<STRING, STRING>
>>,
attributes: MAP<STRING, STRING>,
flags: INT,
min: DOUBLE,
max: DOUBLE,
aggregation_temporality: STRING
>,
exponential_histogram STRUCT<
attributes: MAP<STRING, STRING>,
start_time_unix_nano: LONG,
time_unix_nano: LONG,
count: LONG,
sum: DOUBLE,
scale: INT,
zero_count: LONG,
positive_bucket: STRUCT<
offset: INT,
bucket_counts: ARRAY<LONG>
>,
negative_bucket: STRUCT<
offset: INT,
bucket_counts: ARRAY<LONG>
>,
flags: INT,
exemplars: ARRAY<STRUCT<
time_unix_nano: LONG,
value: DOUBLE,
span_id: STRING,
trace_id: STRING,
filtered_attributes: MAP<STRING, STRING>
>>,
min: DOUBLE,
max: DOUBLE,
zero_threshold: DOUBLE,
aggregation_temporality: STRING
>,
summary STRUCT<
start_time_unix_nano: LONG,
time_unix_nano: LONG,
count: LONG,
sum: DOUBLE,
quantile_values: ARRAY<STRUCT<
quantile: DOUBLE,
value: DOUBLE
>>,
attributes: MAP<STRING, STRING>,
flags: INT
>,
metadata MAP<STRING, STRING>,
resource STRUCT<
attributes: MAP<STRING, STRING>,
dropped_attributes_count: INT
>,
resource_schema_url STRING,
instrumentation_scope STRUCT<
name: STRING,
version: STRING,
attributes: MAP<STRING, STRING>,
dropped_attributes_count: INT
>,
metric_schema_url STRING
) USING DELTA
TBLPROPERTIES (
'otel.schemaVersion' = 'v1'
)
ログ テーブル
CREATE TABLE <catalog>.<schema>.<table_prefix>_otel_logs (
event_name STRING,
trace_id STRING,
span_id STRING,
time_unix_nano LONG,
observed_time_unix_nano LONG,
severity_number STRING,
severity_text STRING,
body STRING,
attributes MAP<STRING, STRING>,
dropped_attributes_count INT,
flags INT,
resource STRUCT<
attributes: MAP<STRING, STRING>,
dropped_attributes_count: INT
>,
resource_schema_url STRING,
instrumentation_scope STRUCT<
name: STRING,
version: STRING,
attributes: MAP<STRING, STRING>,
dropped_attributes_count: INT
>,
log_schema_url STRING
) USING DELTA
TBLPROPERTIES (
'otel.schemaVersion' = 'v1'
)
手順 2: コーディング エージェントの env vars を更新する
OpenTelemetry メトリックのサポートが有効になっているコーディング エージェントで、次の環境変数を構成します。
{
"OTEL_METRICS_EXPORTER": "otlp",
"OTEL_EXPORTER_OTLP_METRICS_PROTOCOL": "http/protobuf",
"OTEL_EXPORTER_OTLP_METRICS_ENDPOINT": "https://<workspace-url>/api/2.0/otel/v1/metrics",
"OTEL_EXPORTER_OTLP_METRICS_HEADERS": "content-type=application/x-protobuf,Authorization=Bearer <databricks_pat_token>,X-Databricks-UC-Table-Name=<catalog>.<schema>.<table_prefix>_otel_metrics",
"OTEL_METRIC_EXPORT_INTERVAL": "10000",
"OTEL_LOGS_EXPORTER": "otlp",
"OTEL_EXPORTER_OTLP_LOGS_PROTOCOL": "http/protobuf",
"OTEL_EXPORTER_OTLP_LOGS_ENDPOINT": "https://<workspace-url>/api/2.0/otel/v1/logs",
"OTEL_EXPORTER_OTLP_LOGS_HEADERS": "content-type=application/x-protobuf,Authorization=Bearer <databricks_pat_token>,X-Databricks-UC-Table-Name=<catalog>.<schema>.<table_prefix>_otel_logs",
"OTEL_LOGS_EXPORT_INTERVAL": "5000"
}
手順 3: コーディング エージェントを実行します。
データは、5 分以内に Unity カタログ テーブルに反映されます。