各サービスが、中央オーケストレーターに依存するのではなく、業務処理をいつどのように実行するかをそれぞれ判断できるようにします。 このアプローチでは、ワークフロー ロジックが分散化され、システムのコンポーネント全体に責任が分散されます。
コンテキストと問題
通常は、クラウドベースのアプリケーションを、エンドツーエンドのビジネス トランザクションを処理するために連携するいくつかの小さなサービスに分割します。 トランザクション内で 1 つの操作を実行すると、すべてのサービス間で複数のポイントツーポイント呼び出しが発生する可能性があります。 理想的には、これらのサービスは疎結合されています。 複雑なサービス間通信を伴うため、分散型で効率的でスケーラブルなワークフローを設計するのは困難です。
通信の一般的なパターンは、集中化されたサービスまたはオーケストレーターとして使用するというものです。 受信要求は、それぞれのサービスに操作を委任するオーケストレーターを通過します。 各サービスは責任を果たしており、ワークフロー全体を認識していません。

通常、オーケストレーター パターンは、システム内のサービスの責任に関するドメイン知識を持つカスタム ソフトウェアとして実装します。 このアプローチの利点の 1 つは、オーケストレーターが、ダウンストリーム サービスが実行する個々の操作の結果に基づいてトランザクションの状態を統合できることです。
この方法にはいくつかの障害が生じることもあります。 サービスを追加または削除すると、通信パスの一部を再配線する必要があるため、既存のロジックが壊れる可能性があります。 この依存関係により、オーケストレーターの実装が複雑になり、メンテナンスが困難になります。 オーケストレーターは、ワークロードの信頼性に悪影響を及ぼす可能性があります。 負荷の下では、パフォーマンスのボトルネックが発生し、単一障害点 (SPoF) になる可能性があります。 また、ダウンストリーム サービスで連鎖的なエラーが発生する可能性もあります。
ソリューション
サービス間でトランザクション処理ロジックを委任します。 各サービスが業務のコミュニケーション ワークフローに参加し、いつどのように処理するかを決定します。
コレオグラフィ パターンは、通信ワークフローを一元化するカスタム ソフトウェアへの依存関係を最小限に抑えます。 コンポーネントは、相互に直接通信することなく、ワークフローを相互に振り付ける一般的なロジックを実装します。
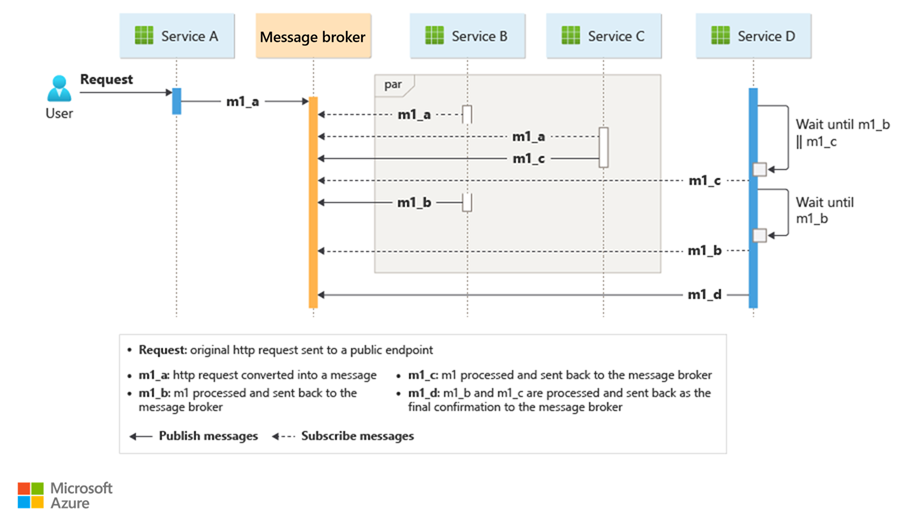
コレオグラフィを実装する一般的な方法は、ダウンストリーム コンポーネントが要求を取得して処理するまで要求をバッファリングするメッセージ ブローカーを使用することです。 次の図は、 パブリッシャー サブスクライバー モデルを介した要求処理を示しています。

クライアントは、メッセージ ブローカーのメッセージとしてキューを要求します。
サービスまたはサブスクライバーはブローカーをポーリングして、実装されたビジネス ロジックに基づいてメッセージを処理できるかどうかを判断します。 ブローカーは、そのメッセージに関心のあるサブスクライバーにメッセージをプッシュすることもできます。
サブスクライブされた各サービスは、メッセージが示し、操作の成功または失敗のメッセージでブローカーに応答するように、その操作を行います。
操作が成功した場合、サービスはメッセージを同じキューまたは別のメッセージ キューにプッシュして、必要に応じて別のサービスがワークフローを続行できるようにします。 操作が失敗した場合は、メッセージ ブローカーは他のサービスと連携して、その操作またはトランザクション全体を補正します。
問題と考慮事項
このパターンを実装する方法を決定するときは、次の点を考慮してください。
エラーの処理は困難な場合があります。 アプリケーション内のコンポーネントはアトミック タスクを管理し、システムの他の部分に依存する場合があります。 1 つのコンポーネントでエラーが発生すると、他のコンポーネントに影響が及び、要求全体の完了に遅延が発生する可能性があります。
エラーを適切に処理するには、エラー処理ロジックを実装します。これにより、複雑さが生まれます。 補正トランザクションなどのエラー処理ロジックでも、エラーが発生しやすくなります。
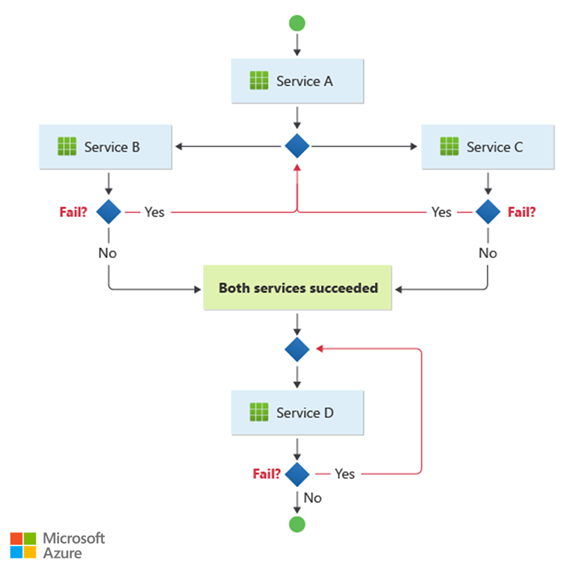
このパターンは、独立したビジネス操作を並行して処理するワークフローに適しています。 コレオグラフィを順番に実行する必要がある場合、ワークフローは複雑になる可能性があります。 たとえば、サービス D は、サービス B とサービス C が正常に操作を完了した後にのみ、その操作を開始できます。
このパターンは、サービスの数が急速に増加する場合に課題を提示します。 多くの独立した可動部分は、サービス間のワークフローを複雑にします。 観測性を維持するには、 分散トレース と相関識別子を常に使用する必要があります。
オーケストレーター主導の設計では、中央コンポーネントは、一時的、非一時的、タイムアウトエラーの再試行処理などの回復性の責任を専用の回復性ハンドラーに委任できます。
コレオグラフィベースの設計でオーケストレーターを削除しても、ダウンストリーム コンポーネントは回復性の責任を負いません。 レジリエンシーハンドラーで集中管理されたままになります。 しかし、ダウンストリーム コンポーネントはそのハンドラーと直接通信する必要があり、ポイントツーポイント通信が増加します。
イベント スキーマの進化により、時間の経過と同時にコンシューマーが破壊的変更を引き起こす可能性があります。 このパターンでは、複数の独立したサービスが同じイベントを使用します。 プロデューサーがイベントのデータ構造を変更すると、古いスキーマに依存するダウンストリーム コンシューマーが中断される可能性があります。 スキーマ レジストリを使用してイベント コントラクトを管理し、サービスが個別に進化するにつれて下位互換性のある進化を使用します。
再試行またはスケールアウトでは、イベントの順序は保証されません。重複または順序外のイベントを処理するために、べき等性を設計し、メッセージを順番に再出力します。
分散型イベント トポロジは、大規模な新しい動作を作成できます。 多くのサービスが互いのイベントに反応すると、システムが誤ってフィードバック ループまたはイベント ストームを生成する可能性があります。 マイナー イベントは、ダウンストリームの反応の連鎖を引き起こす可能性があります。 循環イベント チェーンを防ぐには、イベント フィルター処理、コンシューマーコンカレンシー制限、調整、明示的ルールなどのガードレールを使用します。


このパターンを使用する場合
このパターンは次の状況で使用します。
ダウンストリーム コンポーネントは、アトミック操作を個別に処理します。 このパターンは、アクティブな管理を必要としないタスクをコンポーネントが実行する 、ファイア アンド フォーゲット メカニズムと考えてください。 タスクが完了すると、コンポーネントは他のコンポーネントに通知を送信します。
コンポーネントを頻繁に更新して置き換える必要があります。 このパターンを使用すると、既存のサービスに対する労力を減らし、中断を最小限に抑えてアプリケーションを変更できます。
単純なワークフローにはサーバーレス アーキテクチャを使用します。 コンポーネントは、有効期間が短く、イベントドリブンである場合があります。 イベントが発生すると、サービスはタスクを実行するコンポーネントを作成し、そのタスクの完了後にコンポーネントを削除します。
境界付けられたコンテキスト間の通信には、ドメイン境界を越えた疎結合が必要です。 1 つの境界付けられたコンテキスト内の通信の場合は、代わりにオーケストレーター パターンを適用します。
中央オーケストレーターでは、パフォーマンスのボトルネックが発生します。
このパターンは、次の場合に適さない場合があります。
アプリケーションは複雑で、ダウンストリーム コンポーネントを軽量に保つために、共有ロジックを処理するための中央コンポーネントが必要です。
コンポーネント間のポイントツーポイント通信は避けられません。
ビジネス ロジックを使用して、ダウンストリーム コンポーネントが処理するすべての操作を統合する必要があります。
ワークロード設計
ワークロードの設計でコレオグラフィ パターンを使用して、 Azure Well-Architected Framework の柱で説明されている目標と原則に対処する方法を評価します。 次の表は、このパターンが各柱の目標をサポートする方法に関するガイダンスを示しています。
| 支柱 | このパターンが柱の目標をサポートする方法 |
|---|---|
| オペレーショナルエクセレンス は、標準化されたプロセスとチームの結束によってワークロードの品質を提供します。 | このパターンの分散コンポーネントは自律的であり、置き換え可能に設計されているため、システムの全体的な変更を減らしながらワークロードを変更できます。 - OE:04 ツールとプロセス |
| パフォーマンス効率 は、スケーリング、データ、およびコードの最適化を通じて、ワークロード の需要を効率的に満たすのに役立ちます。 | このパターンは、中央集中型オーケストレーショントポロジでパフォーマンスボトルネックが発生した場合の代替方法を提供します。 - PE:02 容量計画 - PE:05 スケーリングとパーティショニング |
このパターンによって柱内にトレードオフが生じる場合は、他の柱の目標に照らして検討してください。
例
この例では、マイクロサービスと共に関数を実行するイベント ドリブンのクラウドネイティブ ワークロードを作成することで、コレオグラフィ パターンを示します。 クライアントがパッケージの発送を要求すると、ワークロードによってドローンが割り当てられます。 スケジュールされたドローンでパッケージを受け取る準備ができたら、配送プロセスが開始されます。 パッケージが輸送中、ワークロードは出荷状態を受け取るまで配信を処理します。

インジェスト サービスはクライアント要求を受信し、配信の詳細を含むメッセージに変換します。 ビジネス トランザクションは、サービスがそれらの新しいメッセージを使用した後に開始されます。
1 つのクライアント ビジネス トランザクションには、次の 3 つの異なるビジネス操作が必要です。
パッケージを作成または更新します。
ドローンを割り当ててパッケージを配送します。
パッケージが出荷されたときに通知を確認および送信するなど、配信を処理します。
パッケージ、ドローン スケジューラ、および配信マイクロサービスは、ビジネス処理を実行します。 サービスは、中央オーケストレーターではなくメッセージングを使用して相互に通信します。 各サービスは、分散化された方法でビジネス ワークフローを調整するプロトコルを事前に実装する必要があります。
設計
サービスは、複数のホップを通じて一連のビジネス トランザクションを処理します。 各ホップは、すべてのビジネス サービス間で 1 つのメッセージ バスを共有します。
クライアントが HTTP エンドポイントを介して配信要求を送信すると、インジェスト サービスはそれを受信し、メッセージに変換して、共有メッセージ バスにメッセージを発行します。 サブスクライブされたビジネス サービスは、バスに追加された新しいメッセージを処理します。 ビジネス サービスがメッセージを受信すると、操作が正常に完了するか、要求が失敗またはタイムアウトします。要求が成功すると、サービスは Ok 状態コードを使用してバスに応答し、新しい操作メッセージを生成してメッセージ バスに送信します。 要求が失敗またはタイムアウトした場合、サービスは理由コードをメッセージ バスに送信してエラーを報告し、メッセージを配信不能キュー (DLQ) に追加します。 また、サービスは、特定の時間内に受信または処理できないメッセージを DLQ に移動します。
この設計では、複数のメッセージ バスを使用してビジネス トランザクション全体を処理します。 Azure Service Bus と Azure Event Grid は 、この設計のためのメッセージング サービス プラットフォームを提供します。 ワークロードは、インジェストのために Azure Functions をホストする AzureContainer Apps 上で実行されます。 Container Apps は、ビジネス ロジックを実行する イベントドリブン処理 を処理します。
この設計により、振付が順番に行われることも保証されます。 1 つの Service Bus 名前空間には、2 つのサブスクリプションとセッション対応キューを持つトピックが含まれています。 インジェスト サービスは、トピックにメッセージを発行します。 パッケージ サービスとドローン スケジューラ サービスはトピックをサブスクライブし、成功した要求をキューに通知するメッセージを発行します。 GUID を配信識別子に関連付ける共通セッション識別子を含め、サービスが関連するメッセージの無制限のシーケンスを順番に処理できるようにします。 配信サービスは、トランザクションごとに 2 つの関連メッセージを待機します。 最初のメッセージは、パッケージを出荷する準備ができていることを示し、2 番目のメッセージはドローンがスケジュールされていることを通知します。
この設計では、Service Bus は、配信プロセス全体で失われたり重複したりしてはならない、価値の高いメッセージを処理します。 パッケージが出荷されると、状態の変更が Event Grid に発行されます。 イベントの送信者は、状態の変更がどのように処理されるかについて期待しません。 この設計に含まれていないダウンストリーム組織サービスは、このイベントの種類をリッスンし、注文状態の電子メールをユーザーに送信するなど、特定のビジネス ロジックを実行できます。
AKS などの別のコンピューティング サービスにこのパターンをデプロイする場合は、同じポッドに 2 つのコンテナーを含む Publisher-Subscriber パターン アプリケーションの定型句を実装できます。 一方のコンテナーは、選択したメッセージ バスと対話する アンバサダー を実行し、もう 1 つのコンテナーはビジネス ロジックを実行します。 このアプローチにより、パフォーマンスとスケーラビリティが向上します。 アンバサダーとビジネス サービスは同じネットワークを共有するため、待機時間が短縮され、スループットが向上します。
複数回試行される可能性がある連鎖的な再試行操作を回避するために、ビジネス サービスは、許容できないメッセージに直ちにフラグを設定する必要があります。 サービスが DLQ に移動できるように、一般的な理由コードまたは定義されたアプリケーション コードを使用して、これらのメッセージを強化します。 ダウンストリーム サービスからの整合性の問題を管理するために Saga パターンを実装することを検討してください。 たとえば、別のサービスは、補正、再試行、またはピボット トランザクションを実行することによってのみ、修復目的で配信不能メッセージを処理します。
ビジネスサービスは、冪等性を持ち、再試行操作で重複するリソースが作成されないようにします。 たとえば、パッケージ サービスはアップサート操作を使用してデータ ストアにデータを追加します。
次のステップ
Azure Event Hubs のスキーマ レジストリを使用してイベント スキーマ管理を一元化し、サービスの進化に合わせて互換性を維持します。
Azure の非同期メッセージング オプションを確認して、分散ワークフローを実装するために使用できるさまざまなインフラストラクチャの選択肢について学習します。
さまざまなプラットフォームの技術的な機能を評価して、特定の振り付け要件 に適した Azure メッセージング サービスを選択 します。
関連リソース
振付のためのデザインでは、次のパターンを検討してください。
アンバサダー パターンを使用してビジネス サービスをモジュール化します。
Queue-Based 負荷平準化パターンを実装して、ワークロードの急増を処理します。
Publisher-Subscriber パターンで非同期分散メッセージングを使用します。
補正トランザクションを使用して、1 つ以上の関連する操作が失敗した場合に一連の正常な操作を元に戻します。