適用対象: Azure Data Factory
Azure Data Factory Azure Synapse Analytics
Azure Synapse Analytics
ヒント
Data Factory in Microsoft Fabric は、よりシンプルなアーキテクチャ、組み込みの AI、および新機能を備えた次世代のAzure Data Factoryです。 データ統合を初めて使用する場合は、Fabric Data Factory から始めます。 既存の ADF ワークロードをFabricにアップグレードして、データ サイエンス、リアルタイム分析、レポートの新機能にアクセスできます。
データ ラングリングでは、元のソースからのデータをさまざまなダウンストリーム アプリケーションに適した便利なものするために、変換と再フォーマットが行われます。
組織は、日々増加し続ける複雑なデータを正確に分析するために、データの準備とラングリングの目的で重要なビジネス データを調査する能力を必要としています。 さまざまなビジネス プロセスのデータを使用して、価値創造までの時間を短縮できるようにするには、データの準備が不可欠です。
Data Factory を使用すると、Power Queryを使用して、クラウド規模でコード不要のデータ準備を繰り返し行うことができます。 Data Factory は、Power Query Online と統合され、Power Query M 関数をパイプライン アクティビティとして使用できるようにします。
Data Factory は、Power Query Online Mashup エディターによって生成された M を、M を Azure Data Factory データ フローに変換してクラウド スケール実行用の Spark コードに変換します。 Power Queryとデータ フローを使用したデータラングリングは、データ エンジニアや "市民データ インテグレーター" に特に役立ちます。
利用事例
迅速な対話型のデータ探索と準備
複数のデータ エンジニアやシティズン データ インテグレーターが、データセットをクラウド規模で対話的に探索し、準備することができます。 データ レイク内のデータの量、種類、速さが増大するなか、ユーザーは、データ セットを探索して準備するための効果的な方法を必要としています。 たとえば、2017 年以降の新規顧客を対象に、すべての顧客人口統計情報を含んだデータセットを作成するようなケースもあるでしょう。 既知のターゲットにマッピングしていません。 レイクに公開する前に、データセットの探索、ラングリング、準備を行って、要件を満たすことになります。 ラングリングは、それほど厳格ではない分析シナリオでよく使用されます。 準備されたデータセットは、変換や機械学習のために使用できます。
コードフリーのアジャイルなデータ準備
シティズン データ インテグレーターは、データを探して準備するのに、業務時間の 60% 以上を費やしています。 業務の生産性を向上させるため、彼らはこれらの作業をコーディングなし行う方法を探しています。 市民データ インテグレーターが、スケーラブルな方法で Power Query Online などの既知のツールを使用してデータを強化、整形、公開できるようにすることで、生産性が大幅に向上します。 Azure Data Factoryでラングリングを使用すると、使い慣れたPower Query Online マッシュアップ エディターを使用して、市民データ インテグレーターがエラーを迅速に修正し、データを標準化し、高品質のデータを生成してビジネス上の意思決定をサポートできます。
データの検証と調査
コードを使用せずにデータを視覚的にスキャンして、外れ値や異常を除外し、データを高速分析用に整形することができます。
サポートされているソース
| コネクタ | データ形式 | 認証の種類 |
|---|---|---|
| Azure Blob Storage | CSV、Parquet、Excel | アカウント キー、サービス プリンシパル、MSI |
| Azure Data Lake Storage Gen1 | CSV、Parquet、Excel | サービス プリンシパル、MSI |
| Azure Data Lake Storage Gen2 | CSV、Parquet、Excel | アカウント キー、サービス プリンシパル、MSI |
| Azure SQL Database | - | SQL 認証、MSI、サービス プリンシパル |
| Azure Synapse Analytics | - | SQL 認証、MSI、サービス プリンシパル |
マッシュアップ エディター
Power Query アクティビティを作成すると、すべてのソース データセットがデータセット クエリになり、ADFResource フォルダーに配置されます。 既定では、UserQuery は最初のデータセット クエリを指します。 データセット クエリに対する変更はサポートされておらず、永続化もされないため、すべての変換は UserQuery で実行される必要があります。 クエリの名前変更、追加、削除は、現在サポートされていません。
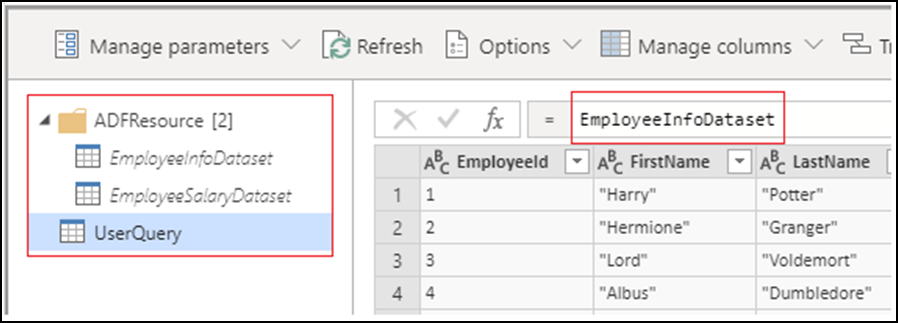
現時点では、作成中に使用可能であるにもかかわらず、すべての Power Query M 関数がデータ ラングリングでサポートされているわけではありません。 Power Query アクティビティのビルド中に、関数がサポートされていない場合は、次のエラー メッセージが表示されます。
The Power Query Spark Runtime does not support the function
サポートされている変換の詳細については、「Power Query データ ラングリング関数を参照してください。
関連するコンテンツ
Power Query のデータラングリングマッシュアップを作成する方法について学びます。