適用対象: Azure Data Factory
Azure Data Factory Azure Synapse Analytics
Azure Synapse Analytics
ヒント
Data Factory in Microsoft Fabric は、よりシンプルなアーキテクチャ、組み込みの AI、および新機能を備えた次世代のAzure Data Factoryです。 データ統合を初めて使用する場合は、Fabric Data Factory から始めます。 既存の ADF ワークロードをFabricにアップグレードして、データ サイエンス、リアルタイム分析、レポートの新機能にアクセスできます。
このチュートリアルでは、Azure ポータルを使用して、Azure Data Factory パイプラインを作成します。 このパイプラインは、Spark アクティビティとオンデマンドAzure HDInsightリンクされたサービスを使用してデータを変換します。
このチュートリアルでは、以下の手順を実行します。
- データ ファクトリを作成します。
- Spark アクティビティを使用するパイプラインを作成します。
- パイプラインの実行をトリガーする。
- パイプラインの実行を監視します。
Azure サブスクリプションがない場合は、開始する前に free アカウントを作成します。
前提条件
注釈
Azure Az PowerShell モジュールを使用してAzureを操作することをお勧めします。 作業を開始するには、「Install Azure PowerShellを参照してください。 Az PowerShell モジュールに移行する方法については、「
- Azure ストレージ アカウント。 Python スクリプトと入力ファイルを作成し、Azure Storageにアップロードします。 Spark プログラムからの出力は、このストレージ アカウントに格納されます。 オンデマンドの Spark クラスターでは、同じストレージ アカウントがプライマリ ストレージとして使用されます。
注釈
HDInsight は、Standard レベルで、汎用ストレージ アカウントのみをサポートしています。 アカウントが Premium または BLOB のみのストレージ アカウントでないことを確認してください。
-
Azure PowerShell。
Azure PowerShell の手順に従います。
Python スクリプトを BLOB ストレージ アカウントにアップロードする
次の内容を含む WordCount_Spark.py という名前のPython ファイルを作成します。
import sys from operator import add from pyspark.sql import SparkSession def main(): spark = SparkSession\ .builder\ .appName("PythonWordCount")\ .getOrCreate() lines = spark.read.text("wasbs://adftutorial@<storageaccountname>.blob.core.windows.net/spark/inputfiles/minecraftstory.txt").rdd.map(lambda r: r[0]) counts = lines.flatMap(lambda x: x.split(' ')) \ .map(lambda x: (x, 1)) \ .reduceByKey(add) counts.saveAsTextFile("wasbs://adftutorial@<storageaccountname>.blob.core.windows.net/spark/outputfiles/wordcount") spark.stop() if __name__ == "__main__": main()<storageAccountName> をAzureストレージ アカウントの名前に置き換えます。 その後、ファイルを保存します。
Azure Blob Storage で、adftutorial という名前のコンテナーが存在しない場合は作成します。
spark という名前のフォルダーを作成します。
spark フォルダーの下に、script という名前のサブフォルダーを作成します。
WordCount_Spark.py ファイルを script サブフォルダーにアップロードします。
入力ファイルをアップロードする
- minecraftstory.txt という名前のファイルを作成し、任意のテキストを入力しておきます。 このテキストの単語数が Spark プログラムによってカウントされます。
- spark フォルダーの下に、inputfiles という名前のサブフォルダーを作成します。
- inputfiles サブフォルダーに minecraftstory.txt ファイルをアップロードします。
Data Factory の作成
「Quickstart: Azure ポータルを使用してデータ ファクトリを作成するに関する記事の手順に従って、操作するデータ ファクトリがない場合は作成します。
リンクされたサービスを作成します
このセクションでは、2 つのリンクされたサービスを作成します。
- Azure Storage リンク サービスは、Azure ストレージ アカウントをデータ ファクトリにリンクします。 このストレージは、オンデマンドの HDInsight クラスターによって使用されます。 ここには、実行される Spark スクリプトも含まれています。
- オンデマンドの HDInsight のリンクされたサービス。 Azure Data Factory自動的に HDInsight クラスターが作成され、Spark プログラムが実行されます。 HDInsight クラスターは、事前に構成された時間だけアイドル状態になったら削除されます。
Azure Storageリンクされたサービスを作成する
ホーム ページの左側のパネルで [管理] タブに切り替えます。
![[管理] タブを示すスクリーンショット。](media/doc-common-process/get-started-page-manage-button.png)
ウィンドウの下部にある [接続] を選択して、 [+ 新規] を選択します。
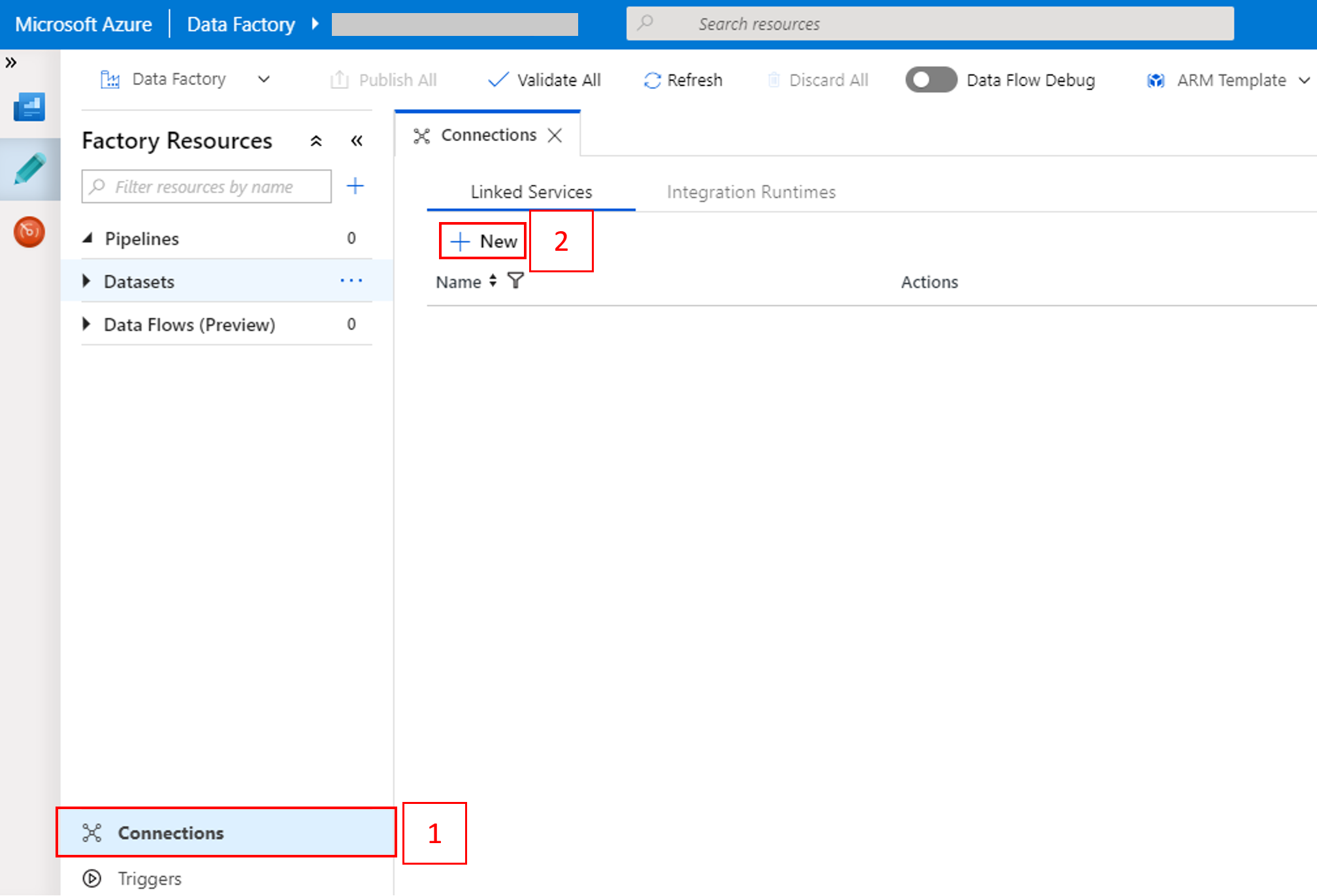
New Linked Service ウィンドウで、Data Store>Azure Blob Storage を選択し、Continue を選択します。

[ストレージ アカウント名] で一覧から名前を選択し、[保存] を選択します。

オンデマンドの HDInsight のリンクされたサービスを作成する
[+ 新規] ボタンをもう一度選択して、別のリンクされたサービスを作成します。
New Linked Service ウィンドウで、Compute>Azure HDInsight を選択し、Continue を選択します。

[New Linked Service](新しいリンクされたサービス) ウィンドウで、次の手順を完了します。
a. [名前] に「AzureHDInsightLinkedService」と入力します。
b. [Type](タイプ) で [On-demand HDInsight](オンデマンド HDInsight) が選択されていることを確認します。
c. [Azure Storage Linked Service](Azure Storage のリンクされたサービス) で [AzureBlobStorage1] を選択します。 このリンクされたサービスは、前の手順で作成したものです。 別の名前を使用した場合は、ここで適切な名前を指定します。
d. [クラスターの種類] で [spark] を選択します。
e. [サービス プリンシパル ID] に、HDInsight クラスターを作成するアクセス許可を備えたサービス プリンシパルの ID を入力します。
このサービス プリンシパルは、サブスクリプションまたはクラスターが作成されるリソース グループの共同作成者ロールのメンバーである必要があります。 詳細については、「Microsoft Entra アプリケーションとサービス プリンシパルの作成を参照してください。 [サービス プリンシパル ID] は "アプリケーション ID" に、 [サービス プリンシパル キー] は "クライアント シークレット" の値に相当します。
f. [サービス プリンシパル キー] に、キーを入力します。
g. [リソース グループ] に、データ ファクトリの作成時に使用したのと同じリソース グループを選択します。 Spark クラスターは、このリソース グループに作成されます。
h. [OS の種類] を展開します。
i. [クラスター ユーザー名] に名前を入力します。
j. そのユーザーのクラスター パスワードを入力します。
k. [完了] を選択します。

注釈
Azure HDInsightでは、サポートされている各Azureリージョンで使用できるコアの合計数が制限されます。 オンデマンド HDInsight のリンクされたサービスの場合、HDInsight クラスターは、プライマリ ストレージとして使用されるのと同じAzure Storageの場所に作成されます。 クラスターを正常に作成するための十分なコア クォータがあることを確認します。 詳細については、「Hadoop、Spark、Kafka などの HDInsight クラスターをセットアップする」を参照してください。
パイプラインを作成する
+ (正符号) ボタンを選択し、メニューの [パイプライン] を選択します。

[アクティビティ] ツールボックスで [HDInsight] を展開します。 [アクティビティ] ツールボックスからパイプライン デザイナー画面に Spark アクティビティをドラッグします。

下部の Spark アクティビティ ウィンドウのプロパティで、次の手順を完了します。
a. [HDI Cluster](HDI クラスター) タブに切り替えます。
b. (前の手順で作成した) AzureHDInsightLinkedService を選択します。

[Script/Jar](スクリプト/Jar) タブに切り替えて、次の手順を実行します。
a. Job Linked Service で AzureBlobStorage1 を選択します。
b. [ストレージを参照] を選択します。
![[スクリプト/Jar] タブでの Spark スクリプトの指定](media/tutorial-transform-data-spark-portal/specify-spark-script.png)
c. adftutorial/spark/script フォルダーに移動します。WordCount_Spark.py を選択し、[完了] を選択します。
パイプラインを検証するために、ツール バーの [検証] ボタンを選択します。 >> (右矢印) ボタンを選択して、検証ウィンドウを閉じます。
![[検証] ボタン](media/tutorial-transform-data-spark-portal/validate-button.png)
[すべて公開] を選択します。 Data Factory UI は、エンティティ (リンクされたサービスとパイプライン) をAzure Data Factory サービスに発行します。
![[すべて公開] ボタン](media/tutorial-transform-data-spark-portal/publish-button.png)
パイプラインの実行をトリガーする
ツール バーの [トリガーの追加] を選択し、 [Trigger Now](今すぐトリガー) を選択します。
![[トリガー] と [今すぐトリガー] ボタン](media/tutorial-transform-data-spark-portal/trigger-now-menu.png)
パイプラインの稼働を監視します
[監視] タブに切り替えます。パイプラインが実行されていることを確認します。 Spark クラスターの作成には約 20 分かかります。
[最新の情報に更新] を定期的にクリックして、パイプラインの実行の状態を確認します。
![[最新の情報に更新] ボタンがある、パイプライン実行を監視するためのタブ](media/tutorial-transform-data-spark-portal/monitor-tab.png)
パイプラインの実行に関連付けられているアクティビティの実行を表示するために、 [アクション] 列の [View Activity Runs](アクティビティの実行の表示) を選択します。

上部の [All Pipeline Runs](すべてのパイプラインの実行) リンクを選択すると、パイプラインの実行ビューに戻ることができます。
![[アクティビティの実行] ビュー](media/tutorial-transform-data-spark-portal/activity-runs.png)
出力を検証する
adftutorial コンテナーの spark/otuputfiles/wordcount フォルダーに出力ファイルが作成されていることを確認します。
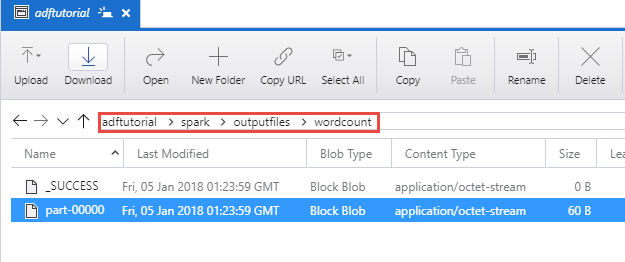
このファイルには、入力テキスト ファイルに含まれている単語と、各単語がファイル内に出現する回数が含まれています。 次に例を示します。
(u'This', 1)
(u'a', 1)
(u'is', 1)
(u'test', 1)
(u'file', 1)
関連するコンテンツ
このサンプルのパイプラインでは、Spark アクティビティとオンデマンドの HDInsight のリンクされたサービスを使用して、データを変換します。 以下の方法を学習しました。
- データ ファクトリを作成します。
- Spark アクティビティを使用するパイプラインを作成します。
- パイプラインの実行をトリガーする。
- パイプラインの実行を監視します。
仮想ネットワーク内のAzure HDInsight クラスターで Hive スクリプトを実行してデータを変換する方法については、次のチュートリアルに進んでください。
Tutorial: Azure Virtual Network で Hive を使用してデータを変換します。