適用対象: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
ヒント
Data Factory in Microsoft Fabric は、よりシンプルなアーキテクチャ、組み込みの AI、および新機能を備えた次世代のAzure Data Factoryです。 データ統合を初めて使用する場合は、Fabric Data Factory から始めます。 既存の ADF ワークロードをFabricにアップグレードして、データ サイエンス、リアルタイム分析、レポートの新機能にアクセスできます。
この記事では、Azure Data Factoryでパラメーター化されたデータ パイプラインを作成するのに役立つ基本的な概念と例について説明します。 パラメーター化と動的式により、ADF に柔軟性が追加され、抽出、変換、読み込み (ETL) または抽出、読み込み、変換 (ELT) ソリューションの柔軟性が向上し、時間を節約できます。 これらの機能により、ソリューションのメンテナンス コストが削減され、既存のパイプラインへの新機能の実装が高速化されます。 パラメーター化により、ハード コーディングが最小限に抑えられるので、ソリューション内の再利用可能なオブジェクトとプロセスの数が増えます。
Azure Data Factory の UI とパラメーター
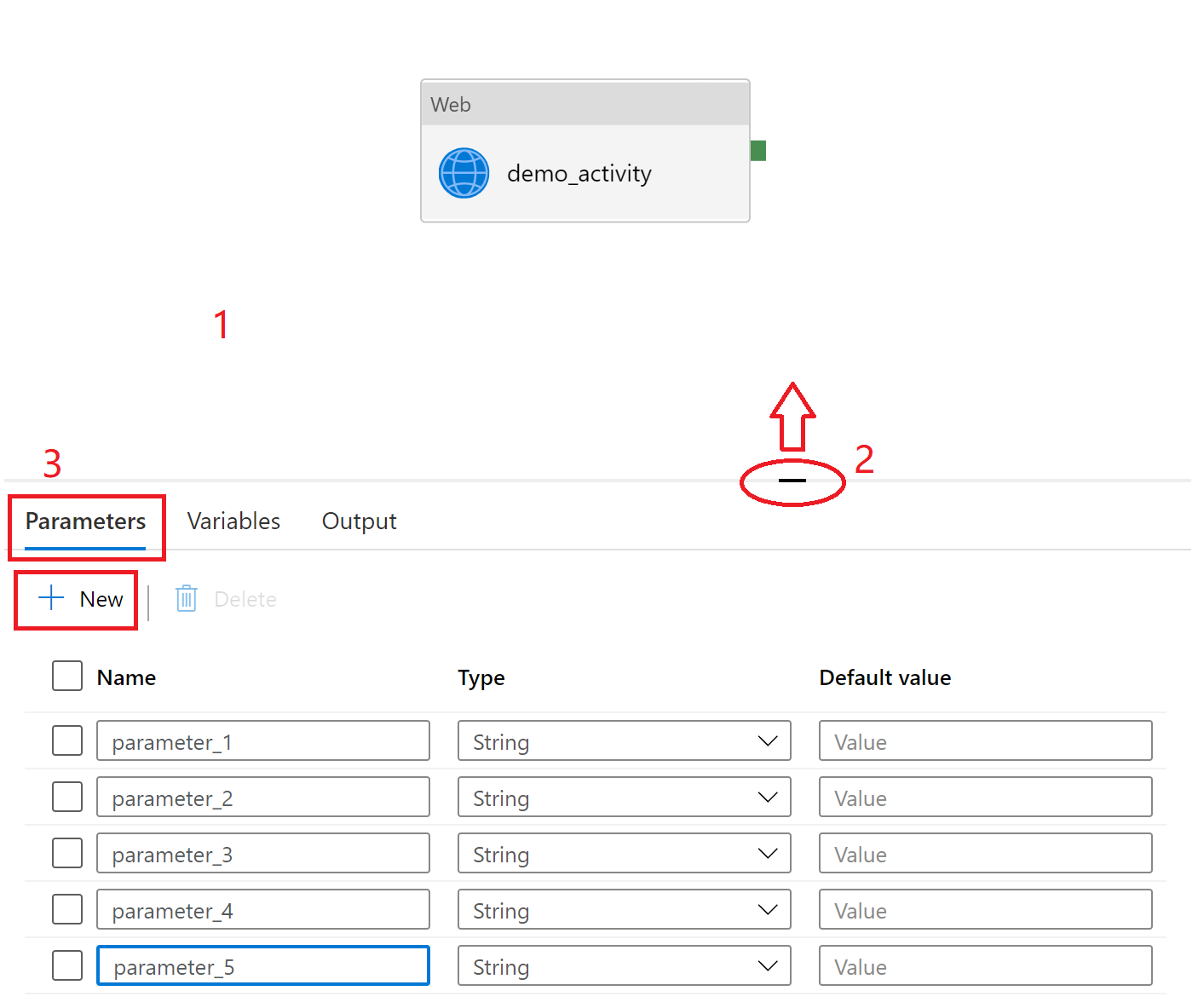
パラメーターの作成と割り当ては、パイプライン、データセット、データ フローの Azure Data Factory ユーザー インターフェイス (UI) で確認できます。
Azure Data Factory studio で、Authoring Canvas に移動し、パイプライン、データセット、またはデータ フローを編集します。
空のキャンバスを選択して、パイプラインの設定を表示します。 アクティビティを選択しないでください。 設定パネルが折りたたまれている可能性があり、その場合、キャンバスの下部から引き上げて表示する必要が生じることがあります。
[ パラメーター ] タブを選択し、[ + 新規 ] を選択してパラメーターを追加します。
また、パラメーター化するプロパティの横にある [ 動的コンテンツの追加 ] を選択して、リンクされたサービスでパラメーターを使用することもできます。

![動的なコンテンツ ボックスと、新しいパラメーターを作成する [+] ボタンが強調表示されているスクリーンショット。](media/parameterize-linked-services/parameterize-linked-services-image-2.png#lightbox)
![リンクされたサービスの [データベース名] ボックスの下にある動的コンテンツ リンクが強調表示されているスクリーンショット。](media/parameterize-linked-services/parameterize-linked-services-image-1-synapse.png#lightbox)
![[+] ボタンを強調表示して新しいパラメーターを作成するスクリーンショット。](media/parameterize-linked-services/parameterize-linked-services-image-2-synapse.png#lightbox)
パラメーターの概念
パラメーターを使用して、パイプライン、データセット、リンクされたサービス、およびデータ フローに外部の値を渡すことができます。 たとえば、Azure Blob Storage内のフォルダーにアクセスするデータセットがある場合は、パイプラインを実行するたびに同じデータセットを再利用して異なるフォルダーにアクセスできるように、フォルダー パスをパラメーター化できます。
パラメーターは変数に似ていますが、パラメーターが外部であるため、パイプライン、データセット、リンクされたサービス、およびデータ フロー に渡されるのに 対し、変数は パイプライン内で定義および使用される 点で異なります。 パラメーターは読み取り専用です。一方、変数の設定アクティビティを使用してパイプライン内で変数を変更できます。
パラメーターは単独で使用することも、式の一部として使用することもできます。 また、パラメーターの値には、リテラル値または実行時に評価される式を指定できます。
次に例を示します。
"name": "value"
または
"name": "@pipeline().parameters.password"
パラメーターを持つ式
式は、パイプライン、データセット、リンクされたサービス、またはデータ フロー定義のさまざまな部分で動的な値を構築するために使用されます。 式は常にアットマーク (@) で始まり、その後にかっこで囲まれた式本体が続きます。 たとえば、次の式では、 concat 関数を使用して 2 つの文字列を結合します。
@concat('Hello, ', 'World!')
式でパラメーターを参照する場合は、次の構文を使用します。
@pipeline().parameters.parameterName
または
@dataset().parameters.parameterName
式の詳細については、 式言語の概要 に関する記事を参照してください。ただし、式でパラメーターを使用する例を次に示します。
複合式の例
次の例では、アクティビティ出力の深いサブフィールドを参照しています。 サブフィールドに評価されるパイプライン パラメーターを参照するには、dot(.) 演算子の代わりに [] 構文を使用します (サブフィールド 1 とサブフィールド 2 の場合と同様)。
@activity('*activityName*').output.*subfield1*.*subfield2*[pipeline().parameters.*subfield3*].*subfield4*
動的コンテンツ エディター
編集が完了すると、動的コンテンツ エディターによってコンテンツ内の文字が自動的にエスケープされます。 たとえば、コンテンツ エディターの次のコンテンツは、2 つの式関数を含む文字列補間です。
{
"type": "@{if(equals(1, 2), 'Blob', 'Table' )}",
"name": "@{toUpper('myData')}"
}
動的コンテンツ エディターは、上記のコンテンツを式 "{ \n \"type\": \"@{if(equals(1, 2), 'Blob', 'Table' )}\",\n \"name\": \"@{toUpper('myData')}\"\n}"に変換します。 この式の結果は、次に示す JSON 形式の文字列です。
{
"type": "Table",
"name": "MYDATA"
}
パラメーターが使用されるデータセット
次の例では、BlobDataset は path という名前のパラメーターを受け取ります。 その値は、式を使用して folderPath プロパティの値を設定します: dataset().path。
{
"name": "BlobDataset",
"properties": {
"type": "AzureBlob",
"typeProperties": {
"folderPath": "@dataset().path"
},
"linkedServiceName": {
"referenceName": "AzureStorageLinkedService",
"type": "LinkedServiceReference"
},
"parameters": {
"path": {
"type": "String"
}
}
}
}
パラメーターが使用されるパイプライン
次の例では、パイプラインは inputPath パラメーターと outputPath パラメーターを受け取ります。 パラメーター化された BLOB データセットの パス は、これらのパラメーターの値を使用して設定されます。 ここで使用する構文は pipeline().parameters.parametername です。
{
"name": "Adfv2QuickStartPipeline",
"properties": {
"activities": [
{
"name": "CopyFromBlobToBlob",
"type": "Copy",
"inputs": [
{
"referenceName": "BlobDataset",
"parameters": {
"path": "@pipeline().parameters.inputPath"
},
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "BlobDataset",
"parameters": {
"path": "@pipeline().parameters.outputPath"
},
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "BlobSource"
},
"sink": {
"type": "BlobSink"
}
}
}
],
"parameters": {
"inputPath": {
"type": "String"
},
"outputPath": {
"type": "String"
}
}
}
}
実践のための詳細な例
パラメーターを備えた Azure Data Factory コピー パイプライン
このAzure Data Factoryコピー パイプライン パラメーターの受け渡しに関するチュートリアルでは、パイプラインとアクティビティの間、およびアクティビティ間でパラメーターを渡す方法について説明します。
パラメーターを使用したデータ フロー パイプラインのマッピング
データ フローでパラメーターを使用する方法の包括的な例については、「パラメーターを使用したマッピング データ フロー」ガイドに従ってください。
パラメーターを使用したメタデータ ドリブン パイプライン
パラメーター ガイドを使用して メタデータ ドリブン パイプライン に従い、パラメーターを使用してメタデータ ドリブン パイプラインを設計する方法の詳細を確認します。 これは、パラメーターの一般的なユース ケースです。
関連コンテンツ
式で使用できるシステム変数の一覧については、「システム変数」を参照してください。