適用対象: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
ヒント
Data Factory in Microsoft Fabric は、よりシンプルなアーキテクチャ、組み込みの AI、および新機能を備えた次世代のAzure Data Factoryです。 データ統合を初めて使用する場合は、Fabric Data Factory から始めます。 既存の ADF ワークロードをFabricにアップグレードして、データ サイエンス、リアルタイム分析、レポートの新機能にアクセスできます。
データ フローは、Azure Data Factory パイプラインとAzure Synapse Analytics パイプラインの両方で使用できます。 この記事は、マッピング データ フローに適用されます。 変換を初めて使用する場合は、入門記事「 マッピング データ フローを使用したデータの変換」を参照してください。
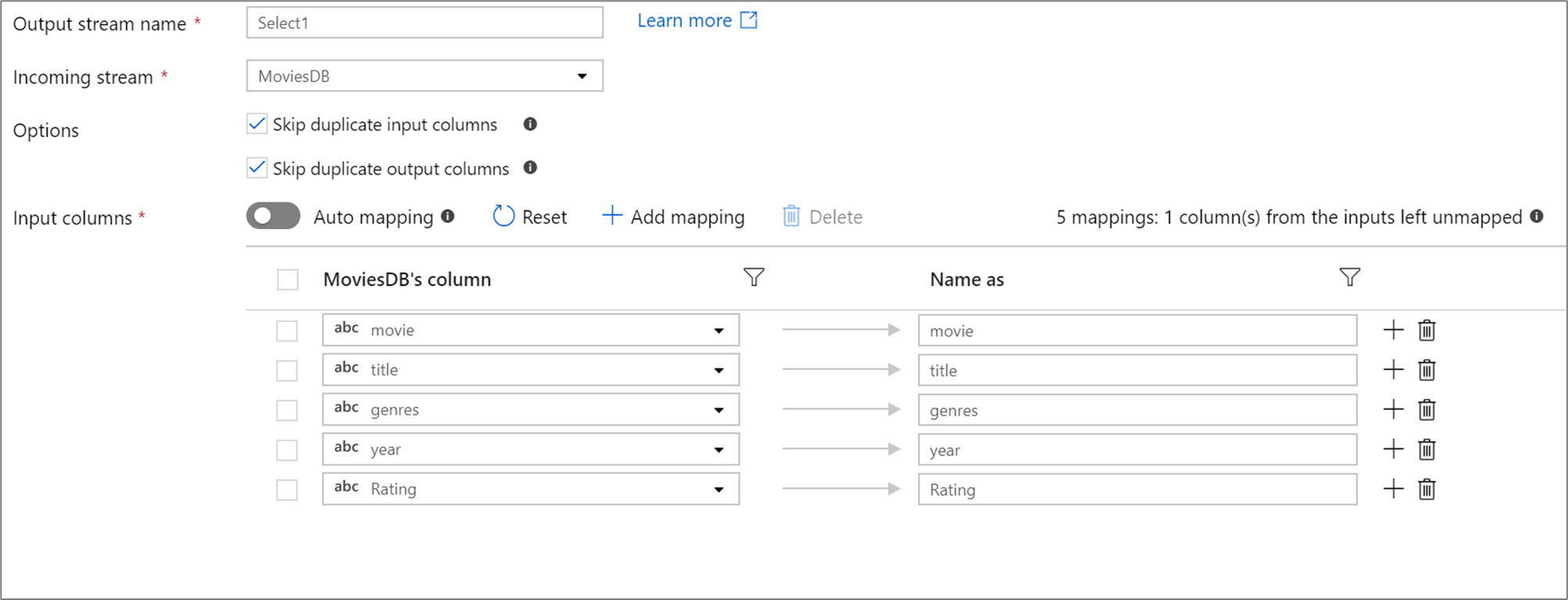
列の名前変更、削除、または並べ替えを行うには、選択変換を使用します。 この変換は、行データを変更するものではなく、どの列が下流に伝達されるかを選択するものです。
選択変換では、固定マッピングを指定したり、パターンを使用してルールベースのマッピングを行ったり、自動マッピングを有効にしたりすることができます。 固定マッピングとルールベース マッピングは、両方とも同じ選択変換内で使用できます。 定義されているいずれのマッピングとも一致しない列は削除されます。
固定マッピング
プロジェクションで定義されている列の数が 50 未満の場合は、定義されているすべての列に、既定で固定マッピングが使用されます。 固定マッピングでは、定義済みの受信列が受け取られ、正確な名前にマップされます。
注
固定マッピングでは、ドリフトした列をマップしたり、名前を変更したりすることはできません。
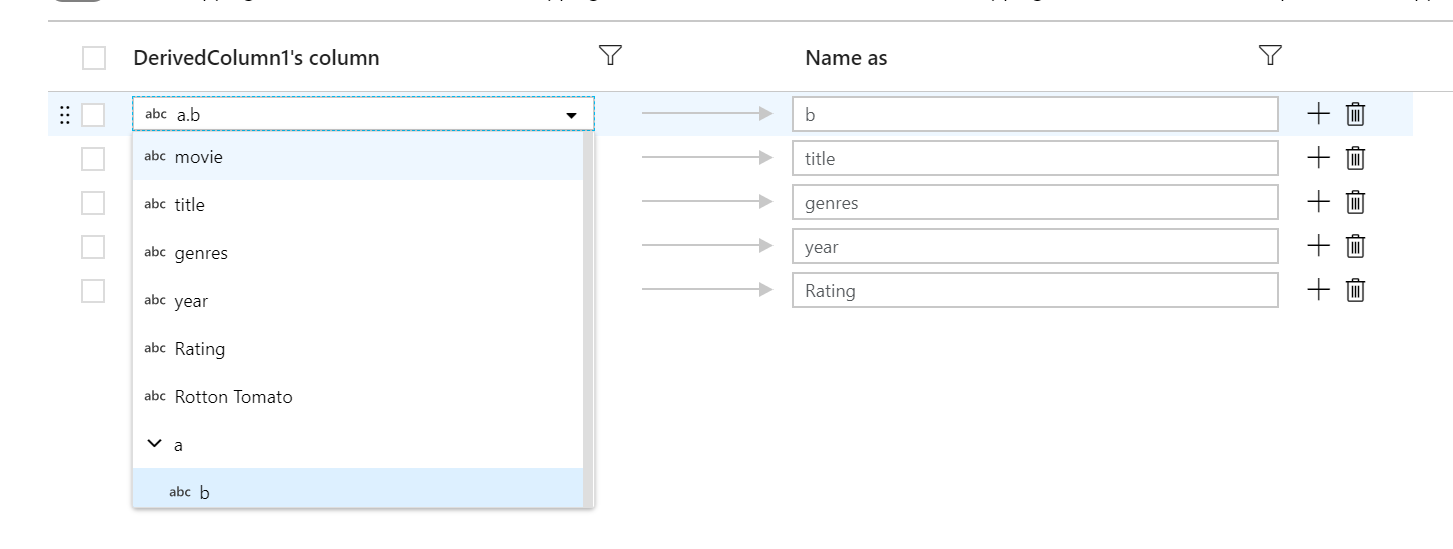
階層列のマッピング
固定マッピングは、階層列のサブ列を最上位レベルの列にマップするために使用することもできます。 階層が定義されている場合は、列のドロップダウンを使用してサブ列を選択します。 選択変換では、サブ列の値とデータ型を使用して新しい列が作成されます。
ルールベースのマッピング
一度に多数の列をマップしたり、変動した列を下流に渡したりする場合は、ルール基準のマッピングを使用し、列パターンを用いてマッピングを定義します。 列の name、type、stream、および position に基づいて照合されます。 フィールドとルールベースの両方のマッピングを任意に組み合わせることもできます。 既定では、50 列を超えるすべてのプロジェクションは、既定ではルールベースのマッピングになり、すべての列に対して照合され、入力された名前が出力されます。
ルールベースのマッピングを追加するには、 [マッピングの追加] をクリックし、 [ルールベースのマッピング] を選択します。
![スクリーンショットには、[マッピングの追加] から選択されたルールベースのマッピングが示されています。](media/data-flow/rule2.png)
各ルールベースのマッピングには、2 つの入力が必要となります。照合の基準となる条件、およびマップされた各列に付ける名前です。 どちらの値も式ビルダーを使用して入力ます。 左側の式ボックスに、ブール値の一致条件を入力します。 右側の式ボックスに、一致した列のマップ先を指定します。

一致した列の入力名を参照するには、$$ 構文を使用します。 上の図を例として使用します。ユーザーは、名前が 6 文字より短いすべての文字列型の列に対して照合したいとします。 ある入力列に test という名前が付けられていた場合、式 $$ + '_short' によりその列の名前が test_short に変更されます。 これが唯一のマッピングの場合、条件を満たしていないすべての列が、出力されるデータから削除されます。
パターンは、変動した列と定義された列の両方に一致します。 どの定義された列がルールによってマップされたかを確認するには、ルールの横にある眼鏡アイコンをクリックします。 データ プレビューを使用して出力を確認します。
正規表現マッピング
下向きのシェブロン アイコンをクリックすると、正規表現のマッピング条件を指定できます。 正規表現のマッピング条件により、指定された正規表現の条件に一致するすべての列名が照合されます。 これは、標準のルールベースのマッピングと組み合わせて使用できます。

上記の例では、正規表現パターン (r)、つまり小文字の r を含むすべての列名と照合されます。 標準のルールベースのマッピングと同様に、一致したすべての列は、$$ 構文を使用した右側の条件によって変更されます。
列名の中に正規表現との一致が複数存在する場合は、$n を使用して、特定の一致を参照することができます ('n' は、どの一致を参照するかを示します)。 たとえば、'$2' を使用すると、列名内の 2 番目の一致を参照できます。
ルールベースの階層
定義されたプロジェクションに階層がある場合は、ルールベースのマッピングを使用して、階層のサブ列をマップできます。 一致条件と、マップ対象のサブ列が含まれる複合列を指定します。 一致したすべてのサブ列は、右側に指定された [付ける名前] ルールを使用して出力されます。
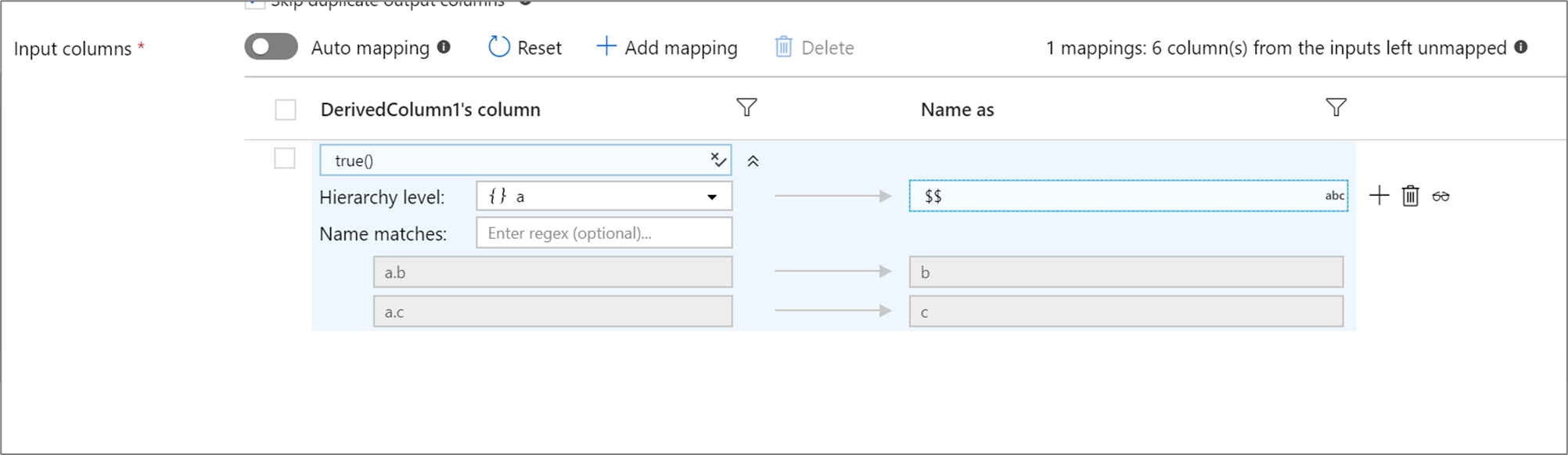
上記の例では、複合列 a のすべてのサブ列に対して照合されます。
a には 2 つのサブ列 b と c が含まれています。 [付ける名前] 条件が b であるため、出力スキーマには 2 つの列 c と $$ が含まれす。
[パラメーター化]
列名は、ルールベースのマッピングを使用してパラメーター化できます。 受信列の名前とパラメーターは、キーワード name を使用して照合します。 たとえば、mycolumn というデータ フロー パラメーターがある場合に、mycolumn と同じ列名を照合するルールを作成することもできます。 一致する列の名前を、ハードコーディングされた文字列 ("business key" など) に変更して、明示的に参照することもできます。 この例の場合は、一致条件が name == $mycolumn、名前条件が "business key" となります。
自動マッピング
選択変換を追加する際には、自動マッピング スライダーを切り替えることで、自動マッピングを有効にすることができます。 自動マッピングを使用した場合、選択変換では、すべての受信列 (重複を除く) が、入力と同じ名前にマップされます。 これには漂った列が含まれます。つまり、出力データには、スキーマで定義されていない列が含まれる可能性があります。 誤差の列の詳細については、「スキーマの誤差」を参照してください。

自動マッピングをオンにした場合、選択変換では、重複スキップの設定が適用され、既存の列に新しい別名が指定されます。 別名は、自己結合のシナリオで、同じストリームに対して複数の結合や参照を実行する場合に便利です。
重複する列
既定では、選択変換を実行すると、入力と出力の両方のプロジェクションで、重複する列が削除されます。 多くの場合、重複する入力列は、各側で列名が重複する結合変換や参照変換から取得されます。 2 つの異なる入力列を同じ名前にマップすると、重複する出力列が発生する可能性があります。 チェックボックスを切り替えて、重複する列を削除するか、または渡すかを選択してください。

列の順序
出力列の順序は、マッピングの順序によって決まります。 入力列が複数回マップされた場合は、最初のマッピングのみが受け入れられます。 重複する列が削除される際には、最初の一致が保持されます。
データ フローのスクリプト
構文
<incomingStream>
select(mapColumn(
each(<hierarchicalColumn>, match(<matchCondition>), <nameCondition> = $$), ## hierarchical rule-based matching
<fixedColumn>, ## fixed mapping, no rename
<renamedFixedColumn> = <fixedColumn>, ## fixed mapping, rename
each(match(<matchCondition>), <nameCondition> = $$), ## rule-based mapping
each(patternMatch(<regexMatching>), <nameCondition> = $$) ## regex mapping
),
skipDuplicateMapInputs: { true | false },
skipDuplicateMapOutputs: { true | false }) ~> <selectTransformationName>
例
次に示すのは、選択マッピングとそのデータ フロー スクリプトの例です。
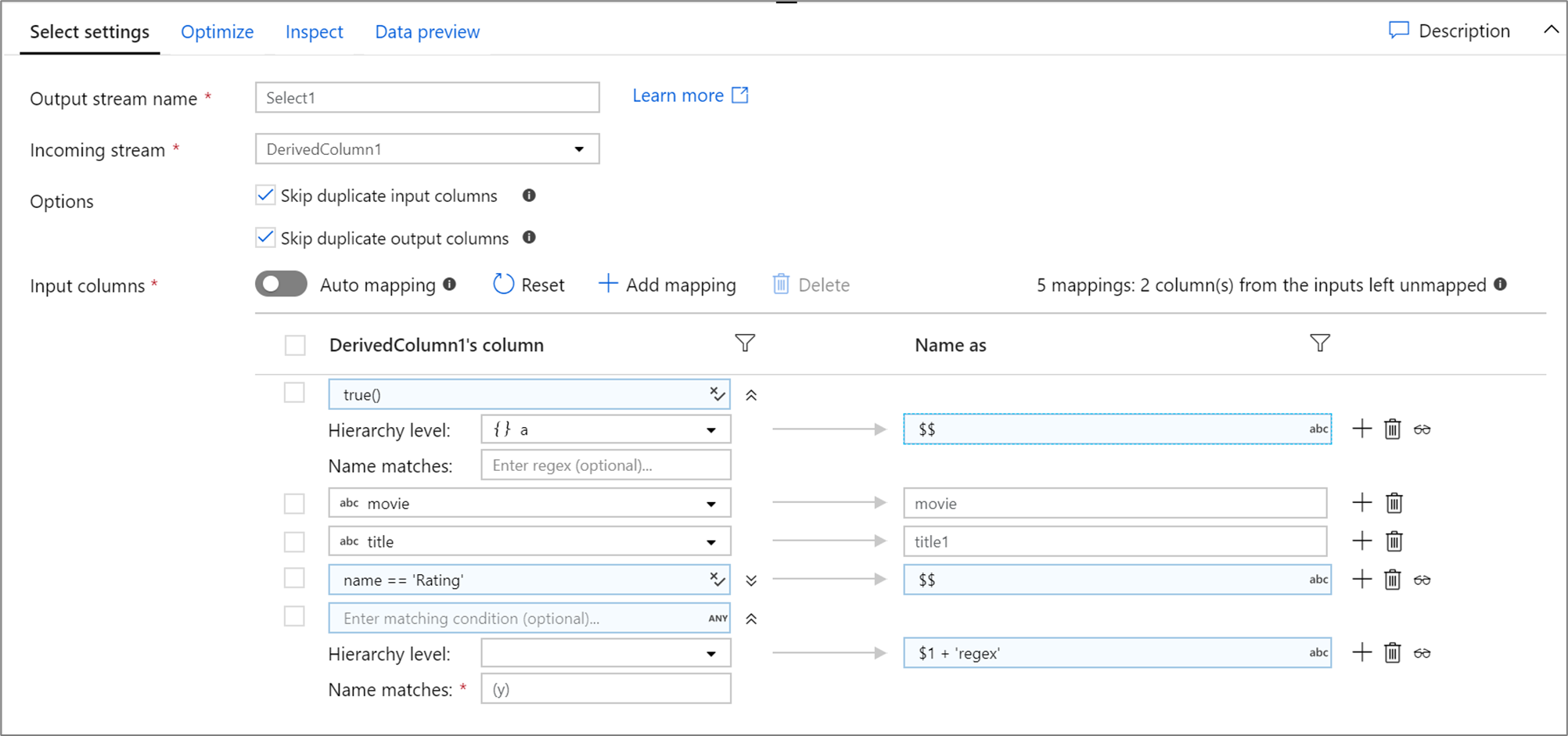
DerivedColumn1 select(mapColumn(
each(a, match(true())),
movie,
title1 = title,
each(match(name == 'Rating')),
each(patternMatch(`(y)`),
$1 + 'regex' = $$)
),
skipDuplicateMapInputs: true,
skipDuplicateMapOutputs: true) ~> Select1
関連するコンテンツ
- 選択を使用して列の名前変更、並べ替え、およびエイリアス化を実行した後、シンク変換を使用してデータをデータストアに格納します。