適用対象: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
ヒント
Data Factory in Microsoft Fabric は、よりシンプルなアーキテクチャ、組み込みの AI、および新機能を備えた次世代のAzure Data Factoryです。 データ統合を初めて使用する場合は、Fabric Data Factory から始めます。 既存の ADF ワークロードをFabricにアップグレードして、データ サイエンス、リアルタイム分析、レポートの新機能にアクセスできます。
データ フローは、Azure Data Factory パイプラインとAzure Synapse Analytics パイプラインの両方で使用できます。 この記事は、マッピング データ フローに適用されます。 変換を初めて使用する場合は、入門記事「 マッピング データ フローを使用したデータの変換」を参照してください。
集計変換では、データ ストリームに含まれる列の集計を定義します。 式ビルダーを使用して、既存の列または計算列によってグループ化される、SUM、MIN、MAX、COUNT などのさまざまな種類の集計を定義できます。
グループ化
集計で句ごとのグループ化として使用するために、既存の列を選択するか、新しい計算列を作成します。 既存の列を使用するには、ドロップダウンから列を選択します。 新しい計算列を作成するには、句をポイントし、 [計算列] をクリックします。 これにより、データ フローの式ビルダーが開きます。 計算列を作成したら、 [Name as]\(名前\) フィールドに出力列の名前を入力します。 追加のグループ条件を追加するには、既存の条件にカーソルを合わせて、プラスアイコンをクリックします。
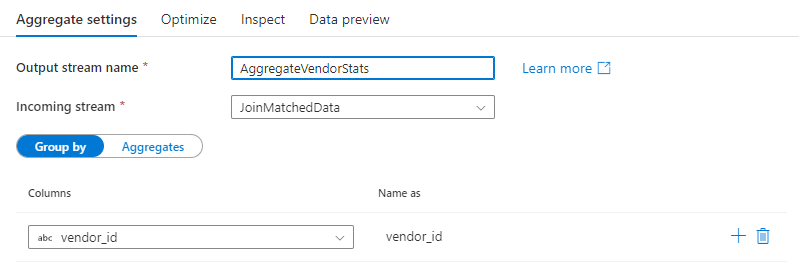
集計変換では、句ごとのグループ化は省略可能です。
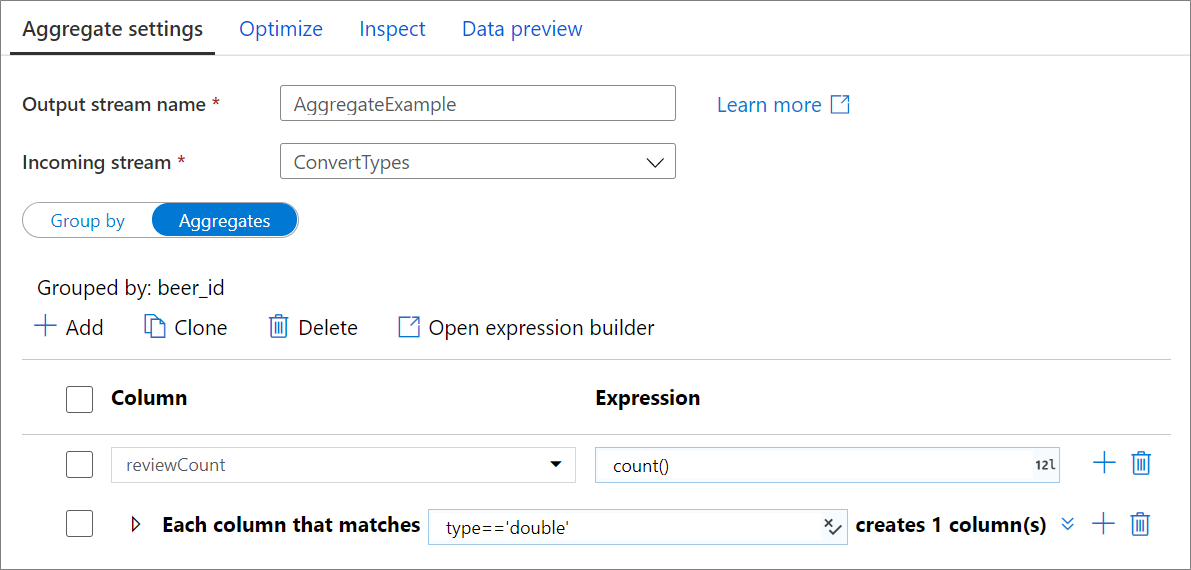
列を集計する
[集計] タブに移動して、集計式を作成します。 既存の列を集計で上書きするか、新しいフィールドを新しい名前で作成します。 集計式は、列名セレクターの右側のボックスに入力されます。 式を編集するには、テキスト ボックスをクリックして式ビルダーを開きます。 集計列をさらに追加するには、列リストの上にある [追加] をクリックするか、既存の集計列の横にあるプラス記号のアイコンをクリックします。 [列の追加] または [列パターンの追加] のいずれかを選択します。 各集計式には、少なくとも 1 つの集計関数が含まれている必要があります。
Note
デバッグ モードでは、式ビルダーで集計関数を使用したデータのプレビューを生成することはできません。 集計変換のデータのプレビューを表示するには、式ビルダーを終了し、[データ のプレビュー] タブで確認します。
カラムパターン
一連の列に同じ集計を適用するには、列パターンを使用します。 入力スキーマからの列は、通常は削除されますが、それらの多くを保持したい場合に、これは役立ちます。
first() などのヒューリスティックを使用して、集計を通じて入力列を保持します。
行と列の再接続
集計変換は、SQL 集計の SELECT クエリと似ています。 Group By 句または集計関数に含まれていない列は、集計変換の出力にフローしません。 集計された出力に他の列を含める場合は、次のいずれかの方法を実行します。
- その追加の列を含めるには、
last()やfirst()などの集計関数を使用します。 - 自己結合パターンを使用して、列を出力ストリームに再結合します。
重複した行の削除
集計変換の一般的な使用方法は、ソース データ内の重複したエントリを削除または特定することです。 このプロセスは重複除去と呼ばれます。 グループ化キーのセットに基づいて、選択したヒューリスティックを使用して、どの重複行を保持するかを決定します。 一般的なヒューリスティックは、first()、last()、max()、および min() です。 グループ化列を除くすべての列にルールを適用するには、列パターンを使用します。
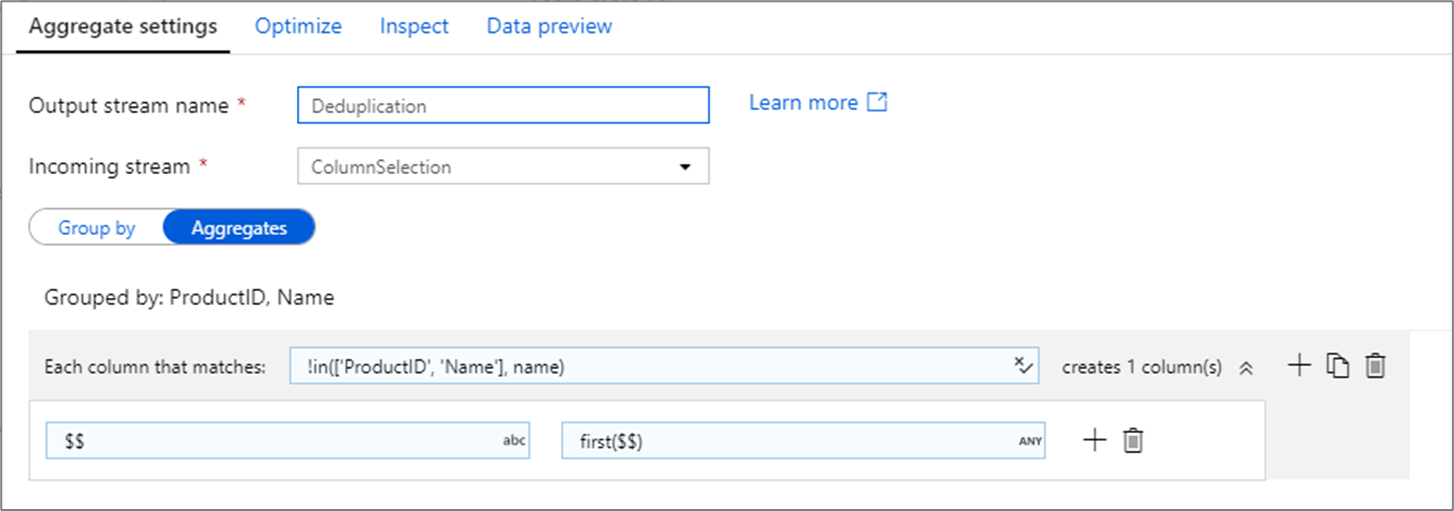
上の例では、列 ProductID および Name がグループ化に使用されています。 これらの 2 つの列の 2 つの行に同じ値がある場合、それらは重複していると見なされます。 この集計変換では、一致した最初の行の値が保持され、それ以外の値はすべて削除されます。 列パターン構文を使用すると、名前が ProductID および Name ではないすべての列が既存の列名にマップされ、最初に一致した行の値が指定されます。 出力スキーマは、入力スキーマと同じです。
データ検証のシナリオでは、count() 関数を使用して、存在している重複の数をカウントできます。
データ フローのスクリプト
構文
<incomingStream>
aggregate(
groupBy(
<groupByColumnName> = <groupByExpression1>,
<groupByExpression2>
),
<aggregateColumn1> = <aggregateExpression1>,
<aggregateColumn2> = <aggregateExpression2>,
each(
match(matchExpression),
<metadataColumn1> = <metadataExpression1>,
<metadataColumn2> = <metadataExpression2>
)
) ~> <aggregateTransformationName>
例
次の例では、受信ストリーム MoviesYear を受け取り、列 year で行をグループ化します。 この変換では、列 avgrating の平均に評価される集計列 Rating が作成されます。 この集計変換には AvgComedyRatingsByYear という名前が付けられます。
UI では、この変換は次の図のようになります。
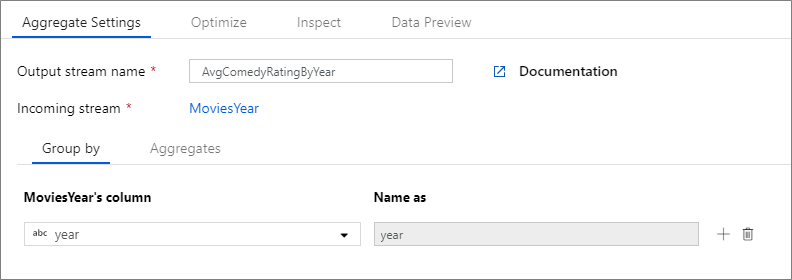
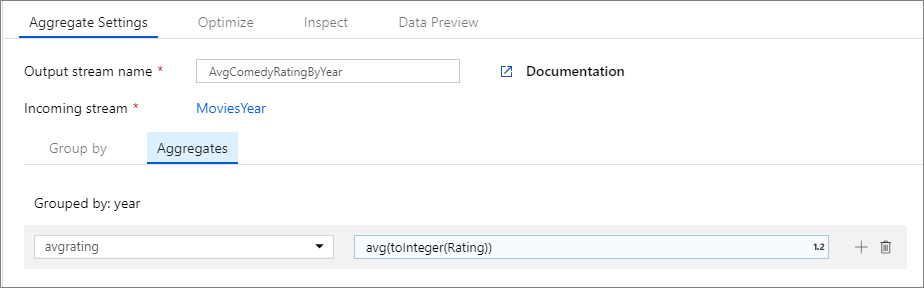
この変換のデータ フロー スクリプトは、次のスニペットに含まれています。
MoviesYear aggregate(
groupBy(year),
avgrating = avg(toInteger(Rating))
) ~> AvgComedyRatingByYear
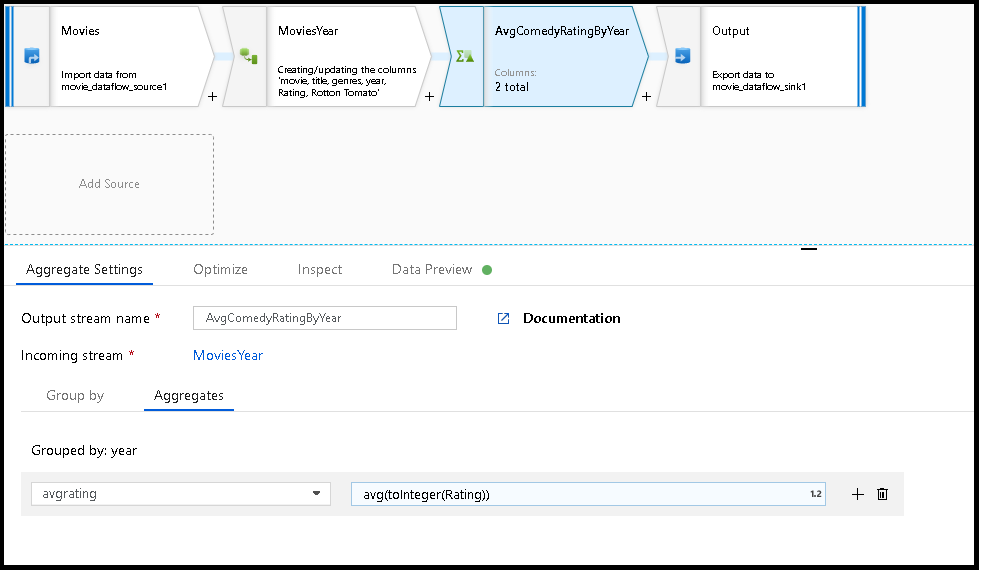
MoviesYear:年とタイトルの列を定義する派生列 AvgComedyRatingByYear: 年別にグループ化されたコメディの平均評価の集計変換 avgrating: 集計値を保持するために作成される新しい列の名前
MoviesYear aggregate(groupBy(year),
avgrating = avg(toInteger(Rating))) ~> AvgComedyRatingByYear
関連するコンテンツ
- ウィンドウ変換を使用してウィンドウベースの集計を定義する