Nota
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare ad accedere o modificare le directory.
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare a modificare le directory.
Questo articolo fornisce raccomandazioni per la pianificazione della capacità per Dominio di Active Directory Services (AD DS).
Obiettivi della pianificazione della capacità
La pianificazione della capacità non equivale alla risoluzione degli eventi imprevisti delle prestazioni. Gli obiettivi della pianificazione della capacità sono:
- Implementare e gestire correttamente un ambiente.
- Ridurre al minimo il tempo impiegato per la risoluzione dei problemi di prestazioni.
Nella pianificazione della capacità, un'organizzazione potrebbe avere un obiettivo di base dell'utilizzo del 40% del processore durante i periodi di picco per soddisfare i requisiti di prestazioni del client e fornire tempo sufficiente per aggiornare l'hardware nel data center. Nel frattempo, impostano la soglia di avviso di monitoraggio per i problemi di prestazioni al 90% in un intervallo di cinque minuti.
Quando si supera continuamente la soglia di gestione della capacità, aggiungere processori più o più veloci per aumentare la capacità o ridimensionare il servizio tra più server sarebbe una soluzione. Le soglie di avviso delle prestazioni consentono di sapere quando è necessario intervenire immediatamente quando i problemi di prestazioni influiscono negativamente sull'esperienza client. Al contrario, una soluzione di risoluzione dei problemi sarebbe più preoccupata per affrontare gli eventi monouso.
La gestione della capacità è proattiva: progettazione, dimensioni e monitoraggio dell'ambiente in modo che le tendenze di utilizzo rimangano entro le soglie definite e le azioni di ridimensionamento possano verificarsi prima dell'impatto dell'utente. La risoluzione dei problemi relativi alle prestazioni è reattiva: risolvere le condizioni acute che stanno già degradando le operazioni degli utenti.
La pianificazione della capacità per i sistemi con scalabilità orizzontale consiste nell'assicurarsi che l'hardware e il servizio possano gestire il carico previsto. In entrambi i casi, l'obiettivo è assicurarsi che il sistema possa gestire il carico previsto pur offrendo un'esperienza utente ottimale. Le opzioni di architettura seguenti consentono di raggiungere tale obiettivo:
- Virtualization
- Archiviazione ad alta velocità, ad esempio unità SSD (Solid State Drive) e NVMe (memoria non volatile express)
- Gli scenari cloud
Active Directory Domain Services (AD DS) è un servizio distribuito maturo che molti prodotti Microsoft e di terze parti usano come back-end. È uno dei componenti più critici per garantire che altre applicazioni abbiano la capacità necessaria.
Informazioni importanti da considerare prima di iniziare la pianificazione
Per sfruttare al meglio questo articolo, è necessario eseguire le operazioni seguenti:
- Assicurarsi di aver letto e compreso le linee guida per l'ottimizzazione delle prestazioni per Windows Server.
- La piattaforma Windows Server è un'architettura basata su x64, che offre uno spazio di indirizzi di memoria maggiore rispetto ai sistemi x86. Le linee guida di questo articolo si applicano all'ambiente Active Directory indipendentemente dalla versione di Windows Server. Per le versioni correnti, le funzionalità di memoria x64 espanse consentono di memorizzare nella cache database di dimensioni maggiori in memoria, anche se i principi di pianificazione della capacità rimangono invariati. Le linee guida si applicano anche se l'ambiente dispone di un albero delle informazioni sulla directory (DIT) che può rientrare interamente nella memoria di sistema disponibile.
- Comprendere che la pianificazione della capacità è un processo continuo, quindi è consigliabile esaminare regolarmente il livello di compilazione dell'ambiente in base alle proprie aspettative.
- Comprendere che l'ottimizzazione si verifica su più cicli di vita hardware man mano che cambiano i costi hardware. Ad esempio, se la memoria diventa più economica, il costo per core diminuisce o il prezzo delle diverse opzioni di archiviazione cambia.
- Pianificare il periodo di picco giornaliero occupato. È consigliabile impostare i piani in base a intervalli di 30 minuti o ore. Quando si sceglie l'intervallo, prendere in considerazione le informazioni seguenti:
- Gli intervalli maggiori di un'ora potrebbero nascondersi quando il servizio raggiunge effettivamente la capacità massima.
- Gli intervalli inferiori a 30 minuti possono rendere gli aumenti temporanei più importanti di quelli effettivamente.
- Pianificare la crescita nel corso del ciclo di vita dell'hardware per l'azienda. Questa pianificazione della crescita può includere strategie per l'aggiornamento o l'aggiunta di hardware in modo sfalsato o un aggiornamento completo ogni tre o cinque anni. Ogni piano di crescita richiede una stima della quantità di carico in Active Directory. I dati cronologici consentono di eseguire una valutazione più accurata.
- La tolleranza di errore è la capacità di un sistema di continuare a funzionare correttamente quando alcuni componenti hanno esito negativo. Dopo aver determinato la capacità necessaria (nota come n), è necessario pianificare la tolleranza di errore. Prendere in considerazione n + 1, n + 2 o anche n + x scenari. Ad esempio, se sono necessari due controller di dominio (CD), pianificarne tre in modo da poter gestire il fallimento di un CD.
In base al piano di crescita, aggiungere server aggiuntivi in base alla necessità dell'organizzazione di assicurarsi che la perdita di uno o più server non causi il superamento delle stime massime della capacità massima del sistema.
Ricordarsi di integrare i piani di crescita e tolleranza di errore. Ad esempio, un controller di dominio (DC) gestisce il carico di oggi. Le previsioni mostrano che il carico raddoppia entro un anno e saranno necessari due data center solo per soddisfare la domanda. Ciò non lascia alcuna capacità di riserva per la tolleranza di errore. Per evitare questa mancanza di capacità, è consigliabile invece pianificare l'avvio con tre controller di dominio. Se il budget non consente tre controller di dominio, è anche possibile iniziare con due controller di dominio, quindi pianificare l'aggiunta di un terzo dopo tre o sei mesi.
Note
L'aggiunta di applicazioni compatibili con Active Directory potrebbe avere un impatto notevole sul carico del controller di dominio, indipendentemente dal fatto che il carico provenga dai server dell'applicazione o dai client.
Ciclo di pianificazione della capacità in tre parti
Prima di iniziare il ciclo di pianificazione, è necessario decidere la qualità del servizio richiesta dall'organizzazione. Tutte le indicazioni e le indicazioni contenute in questo articolo sono per ambienti di prestazioni ottimali. Tuttavia, è possibile rilassarli in modo selettivo nei casi in cui non è necessaria l'ottimizzazione. Ad esempio, se l'organizzazione richiede un livello di concorrenza superiore e un'esperienza utente più coerente, è consigliabile esaminare la configurazione di un data center. I data center consentono di prestare maggiore attenzione alla ridondanza e ridurre al minimo i colli di bottiglia del sistema e dell'infrastruttura. Al contrario, se si pianifica una distribuzione per un ufficio satellite con solo pochi utenti, non è necessario preoccuparsi tanto dell'ottimizzazione hardware e dell'infrastruttura, che consente di scegliere opzioni a basso costo.
Successivamente, è necessario decidere se usare macchine virtuali o fisiche. Dal punto di vista della pianificazione della capacità, non c'è risposta corretta o sbagliata. È tuttavia necessario tenere presente che ogni scenario offre un set diverso di variabili da usare.
Gli scenari di virtualizzazione offrono due opzioni:
- Mapping diretto, in cui è disponibile un solo ospite per host.
- Scenari di host condivisi , in cui sono presenti più guest per host.
È possibile gestire scenari di mapping diretto in modo identico agli host fisici. Se si sceglie uno scenario host condiviso, vengono introdotte altre variabili da prendere in considerazione nelle sezioni successive. Gli host condivisi competono anche per le risorse con Active Directory Domain Services (AD DS), che potrebbero influire sulle prestazioni del sistema e sull'esperienza utente.
Dopo aver risposto a queste domande di pianificazione precedenti, si esaminerà il ciclo di pianificazione della capacità stesso. Ogni ciclo di pianificazione della capacità prevede un processo in tre passaggi:
- Misurare l'ambiente esistente, determinare dove sono attualmente presenti i colli di bottiglia del sistema e ottenere le nozioni di base ambientali necessarie per pianificare la quantità di capacità necessaria per la distribuzione.
- Determinare l'hardware necessario in base ai requisiti di capacità.
- Monitorare e verificare che l'infrastruttura configurata funzioni entro le specifiche. I dati raccolti in questo passaggio diventano la baseline per il ciclo successivo di pianificazione della capacità.
Applicazione del processo
Per ottimizzare le prestazioni, assicurarsi che i componenti principali seguenti siano selezionati correttamente e ottimizzati per il caricamento dell'applicazione:
- Memory
- Network
- Storage
- Processor
- Netlogon
I requisiti di archiviazione di base per i Servizi di dominio Active Directory e il comportamento generale del software client compatibile significano che l'hardware moderno di classe server soddisfa facilmente le esigenze di pianificazione della capacità degli ambienti con un massimo di 10.000 a 20.000 utenti. Anche se la pianificazione della capacità rimane importante per tutte le distribuzioni, gli ambienti più piccoli hanno in genere maggiore flessibilità nelle scelte hardware, perché la maggior parte dei sistemi server correnti può gestire questi carichi senza richiedere un'ottimizzazione specializzata.
Le tabelle nelle tabelle di riepilogo raccolta dati illustrano come valutare l'ambiente esistente per selezionare l'hardware corretto. Le sezioni successive illustrano in dettaglio le raccomandazioni di base e i principi specifici dell'ambiente per l'hardware per aiutare gli amministratori di Active Directory Domain Services a valutare l'infrastruttura.
Altre informazioni da tenere presenti durante la pianificazione:
- Qualsiasi dimensionamento basato sui dati correnti è accurato solo per l'ambiente corrente.
- Quando si effettuano stime, si prevede che la domanda cresce nel ciclo di vita dell'hardware.
- Supportare la crescita futura determinando se è necessario sovradimensionare l'ambiente oggi o aggiungere gradualmente capacità nel corso del ciclo di vita.
- Tutti i principi e le metodologie di pianificazione della capacità che si applicano a una distribuzione fisica si applicano anche a una distribuzione virtualizzata. Tuttavia, quando si pianifica un ambiente virtualizzato, è necessario ricordare di aggiungere il sovraccarico di virtualizzazione a qualsiasi pianificazione o stima correlata al dominio.
- La pianificazione della capacità è una stima, non un valore perfettamente corretto, quindi non aspettarsi che sia perfettamente accurata. Ricordarsi sempre di regolare la capacità in base alle esigenze e verificare costantemente che l'ambiente funzioni come previsto.
Tabelle di riepilogo della raccolta dati
Le tabelle seguenti elencano e illustrano i criteri per determinare le stime hardware.
Ambiente di lavoro
| Component | Estimates |
|---|---|
| Dimensione di archiviazione/database | Da 40 KB a 60 KB per ogni utente |
| RAM | Dimensioni database Indicazioni relative al sistema operativo di base Applicazioni di terze parti |
| Network | 1 GB |
| CPU | 1.000 utenti simultanei per ogni core |
Criteri di valutazione di alto livello
| Component | Criteri di valutazione o conteggio delle prestazioni | Considerazioni sulla pianificazione |
|---|---|---|
| Dimensioni di archiviazione/database | Deframmentazione offline | |
| Prestazioni di archiviazione/database |
|
|
| RAM |
|
|
| Network |
|
|
| CPU |
|
|
| NetLogon |
|
|
Planning
Per molto tempo, la raccomandazione tipica per il dimensionamento di Servizi di dominio Active Directory era quella di inserire una quantità di RAM pari alle dimensioni del database. Anche se l'aumento della potenza di calcolo e il passaggio dall'architettura x86 alla x64 hanno reso aspetti più sottili del dimensionamento per le prestazioni meno importanti per Servizi di dominio Active Directory ospitati in computer fisici, la virtualizzazione ha sottolineato l'importanza dell'ottimizzazione delle prestazioni.
Per risolvere tali problemi, le sezioni seguenti descrivono come determinare e pianificare le richieste di Active Directory as a Service. È possibile applicare queste linee guida a qualsiasi ambiente indipendentemente dal fatto che l'ambiente sia fisico, virtualizzato o misto. Per ottimizzare le prestazioni, l'obiettivo deve essere quello di ottenere l'ambiente di Active Directory Domain Services il più vicino possibile al processore.
RAM
Maggiore è la quantità di spazio di archiviazione che è possibile memorizzare nella cache nella RAM, minore è la necessità di passare al disco.
Per ottimizzare la scalabilità del server, calcolare i requisiti minimi di RAM sommando questi componenti:
- Dimensioni correnti del database
- Quantità consigliata per il sistema operativo
- Raccomandazioni per i fornitori per gli agenti, ad esempio:
- Programmi antivirus
- Monitoraggio del software
- Applicazioni di backup
È anche necessario includere ram aggiuntive per supportare la crescita futura nel corso della durata del server. Questa stima cambia in base alla crescita del database e ai cambiamenti ambientali.
Per gli ambienti in cui la ottimizzazione della RAM non è conveniente o fattibile, vedere la sezione Archiviazione per configurare correttamente l'archiviazione. Questi scenari includono:
- Località satellite con vincoli di budget
- Distribuzioni in cui l'albero delle informazioni sulla directory (DIT) è troppo grande per essere contenuto in memoria
Un'altra cosa importante da considerare per il dimensionamento della memoria è il ridimensionamento del file di pagina. Nel dimensionamento dei dischi, come tutto il resto correlato alla memoria, l'obiettivo è ridurre al minimo l'utilizzo del disco. In particolare, quanto RAM è necessario ridurre al minimo il paging? Le sezioni successive dovrebbero fornire le informazioni necessarie per rispondere a questa domanda. Altre considerazioni relative alle dimensioni delle pagine che non influiscono necessariamente sulle prestazioni di Servizi di dominio Active Directory sono le raccomandazioni del sistema operativo e la configurazione del sistema per i dump della memoria.
Determinare la quantità di RAM necessaria per un controller di dominio può essere difficile a causa di molti fattori complessi:
- I sistemi esistenti non sono sempre indicatori affidabili dei requisiti di RAM perché il servizio LSASS (Local Security Authority Subsystem Service) riduce la RAM sotto pressione di memoria, abbassando artificialmente i requisiti.
- I singoli controller di dominio devono memorizzare nella cache solo i dati a cui sono interessati i client. Ciò significa che i dati memorizzati nella cache in ambienti diversi cambiano a seconda dei tipi di client in esso contenuti. Ad esempio, un controller di dominio in un ambiente con Exchange Server raccoglie dati diversi rispetto a un controller di dominio che autentica solo gli utenti.
- La quantità di lavoro necessaria per valutare la RAM per ogni controller di dominio caso per caso è spesso eccessiva e cambia man mano che l'ambiente cambia.
I criteri alla base delle raccomandazioni consentono di prendere decisioni più informate:
- Più si memorizza nella cache nella RAM, meno è necessario passare al disco.
- L'archiviazione è il componente più lento di un computer. L'accesso ai dati su supporti di archiviazione basati su spindle e SSD è un milione volte più lento rispetto all'accesso ai dati nella RAM.
Considerazioni sulla virtualizzazione della RAM
L'obiettivo dell'ottimizzazione della RAM è ridurre al minimo il tempo impiegato per passare al disco. Evitare il over-commit della memoria nell'host (allocando più RAM ai guest rispetto al computer fisico). Il commit eccessivo non è un problema, ma se l'utilizzo totale dei guest supera la RAM host, le pagine host. Il paging rende le prestazioni dipendenti dal disco quando il controller di dominio (DC) passa al NTDS.dit file di pagina o quando l'host effettua il paging della RAM. Questo comportamento riduce notevolmente le prestazioni e l'esperienza utente.
Esempio di riepilogo del calcolo
| Component | Memoria stimata (esempio) |
|---|---|
| RAM consigliata del sistema operativo di base | 4 GB |
| Attività interne LSASS | 200 MB |
| Agente di monitoraggio | 100 MB |
| Antivirus | 200 MB |
| Database (Catalogo globale) | 8,5 GB |
| Cuscinetto per supporto al backup e agli amministratori per effettuare l'accesso senza problemi | 1 GB |
| Total | 14 GB |
Consigliato: 16 GB
Nel corso del tempo vengono aggiunti più dati al database e la durata media del server è di circa tre o cinque anni. In base a una stima di crescita di 33%, 18 GB è una quantità ragionevole di RAM da inserire in un server fisico.
Network
Questa sezione descrive la valutazione della larghezza di banda totale e della capacità di rete necessarie per la distribuzione, incluse le query client, le impostazioni di Criteri di gruppo e così via. È possibile raccogliere dati per eseguire la stima usando i Network Interface(*)\Bytes Received/sec contatori delle prestazioni e Network Interface(*)\Bytes Sent/sec . Gli intervalli di esempio per i contatori dell'interfaccia di rete devono essere 15, 30 o 60 minuti. Qualsiasi valore inferiore è troppo volatile per buone misurazioni, e qualsiasi valore maggiore uniforma eccessivamente i picchi giornalieri.
Note
In genere, la maggior parte del traffico di rete in un controller di dominio è in uscita perché il controller di dominio risponde alle query client. Di conseguenza, questa sezione si concentra principalmente sul traffico in uscita. Tuttavia, è anche consigliabile valutare ogni ambiente per il traffico in ingresso. È possibile usare le linee guida in questo articolo per valutare anche i requisiti del traffico di rete in ingresso. Per altre informazioni, vedere 929851: L'intervallo di porte dinamiche predefinito per TCP/IP è cambiato in Windows Vista e in Windows Server 2008.
Esigenze di larghezza di banda
La pianificazione della scalabilità della rete riguarda due categorie distinte: la quantità di traffico e il carico della CPU dovuto al traffico di rete.
Quando si pianifica la capacità per il supporto del traffico, è necessario tenere conto di due aspetti. Prima di tutto, è necessario conoscere la quantità di traffico di replica di Active Directory tra i controller di dominio. In secondo luogo, è necessario valutare il traffico tra client e server all'interno del sito. Il traffico intrasito riceve principalmente richieste di piccole dimensioni dai client relativamente alle grandi quantità di dati che invia ai client. 100 MB è in genere sufficiente per gli ambienti con un massimo di 5.000 utenti per server. Per gli ambienti di oltre 5.000 utenti, è consigliabile usare invece una scheda di rete da 1GB e il supporto RSS (Receive Side Scaling).
Per valutare la capacità del traffico intrasito, in particolare negli scenari di consolidamento dei server, è necessario esaminare il Network Interface(*)\Bytes/sec contatore delle prestazioni in tutti i controller di dominio di un sito, aggiungerli insieme, quindi dividere la somma per il numero di controller di dominio di destinazione. Un modo semplice per calcolare questo numero consiste nell'aprire il Monitor Affidabilità e Prestazioni di Windows e osservare la visualizzazione Area sovrapposta. Assicurarsi che tutti i contatori siano ridimensionati allo stesso modo.
Di seguito viene illustrato un esempio di modo più complesso per verificare che questa regola generale si applichi a un ambiente specifico. In questo esempio vengono assunti i presupposti seguenti:
- L'obiettivo è ridurre l'ingombro al minor numero possibile di server. Idealmente, un server trasporta il carico, quindi si distribuisce un altro server per la ridondanza (n + 1 scenario).
- In questo scenario, la scheda di rete corrente supporta solo 100 MB ed è in un ambiente commutato.
- L'utilizzo massimo della larghezza di banda di rete di destinazione è del 60% in uno scenario n (perdita di un data center).
- Ogni server è collegato a circa 10.000 client.
Si esaminerà ora il grafico visualizzato nel Network Interface(*)\Bytes Sent/sec contatore per questo scenario di esempio:
- Il giorno lavorativo inizia a salire intorno alle 5:30 e si snoda alle 17:00.
- Il periodo più trafficato è compreso tra le 8:00 e le 8:15, con più di 25 byte inviati al secondo nel controller di dominio più trafficato.
Note
Tutti i dati sulle prestazioni sono cronologici, quindi il punto dati di picco alle 8:15 indica il carico dalle 8:00 alle 8:15.
- Ci sono picchi prima delle 4:00, con più di 20 byte inviati al secondo nel controller di dominio più trafficato, che potrebbe indicare il carico da fusi orari diversi o attività dell'infrastruttura in background, ad esempio i backup. Poiché il picco alle 8:00 supera questa attività, non è rilevante.
- Nel sito sono presenti cinque controller di dominio.
- Il carico massimo è di circa 5,5 Mbps per data center, che rappresenta il 44 per cento della connessione a 100 Mbps. Usando questi dati, è possibile stimare che la larghezza di banda totale necessaria tra le 8:00 e le 8:15 è di 28MBps.
Note
I contatori di invio/ricezione dell'interfaccia di rete sono in byte, ma la larghezza di banda di rete viene misurata in bit. Pertanto, per calcolare la larghezza di banda totale, è necessario eseguire 100 MB ÷ 8 = 12,5 MB e 1 GB ÷ 8 = 128 MB.
Dopo aver esaminato i dati, quali conclusioni è possibile trarre dall'esempio di utilizzo della rete?
- L'ambiente corrente soddisfa il livello n + 1 di tolleranza di errore con un utilizzo di risorse target del 60%. L'esecuzione offline di un sistema sposta la larghezza di banda per server da circa 5,5 MBps (44%) a circa 7 MBps (56%).
- Sulla base dell'obiettivo precedentemente dichiarato di consolidare in un server, questa modifica di consolidamento supera l'utilizzo massimo previsto e il possibile utilizzo di una connessione da 100 Mbps.
- Con una connessione da 1 GB, questo valore di larghezza di banda per server rappresenta 22% della capacità totale.
- In condizioni operative normali nello scenario n + 1, il carico client è relativamente distribuito a circa 14MBps per server o 11% di capacità totale.
- Per assicurarsi di avere una capacità sufficiente mentre un data center non è disponibile, i valori operativi normali per server sarebbero circa 30% di utilizzo della rete o 38 MBps per server. Le destinazioni di failover avrebbero un utilizzo della rete del 60% o 72 MBps per server.
La distribuzione finale del sistema deve avere una scheda di rete da 1 GB e una connessione all'infrastruttura di rete in grado di supportare il carico necessario. A causa della quantità di traffico di rete, il carico della CPU dalle comunicazioni di rete può potenzialmente limitare la scalabilità massima di Servizi di dominio Active Directory. È possibile usare questo stesso processo per stimare la comunicazione in ingresso al controller di dominio. Nella maggior parte degli scenari, tuttavia, non è necessario calcolare il traffico in ingresso perché è più piccolo del traffico in uscita.
È importante assicurarsi che l'hardware supporti RSS in ambienti con oltre 5.000 utenti per server. Negli scenari con traffico di rete elevato, il bilanciamento del carico di interrupt può diventare un collo di bottiglia. È possibile rilevare possibili colli di bottiglia controllando il contatore Processor(*)\% Interrupt Time per verificare se il tempo di interruzione è distribuito in modo non uniforme tra la CPU. I controller di interfaccia di rete abilitati per RSS possono attenuare queste limitazioni e aumentare la scalabilità.
Note
È possibile adottare un approccio simile per stimare se è necessaria una maggiore capacità quando si consolidano i data center o si ritira un controller di dominio in una posizione satellite. Per stimare la capacità necessaria, esaminare i dati per il traffico in uscita e in ingresso verso i client. Il risultato è la quantità di traffico presente nei collegamenti WAN (Wide Area Network).
In alcuni casi, si potrebbe riscontrare più traffico del previsto perché il traffico è più lento, ad esempio quando il controllo dei certificati non riesce a soddisfare timeout aggressivi nella rete WAN. Per questo motivo, il dimensionamento e l'utilizzo della WAN devono essere effettuati in modo iterativo e continuo.
Considerazioni sulla virtualizzazione per la larghezza di banda della rete
La raccomandazione tipica per un server fisico è una scheda da 1 GB per i server che supportano oltre 5.000 utenti. Quando più guest iniziano a condividere un'infrastruttura di switch virtuale sottostante, verificare che l'host disponga di una larghezza di banda aggregata adeguata per supportare tutti i guest. Tenere conto della larghezza di banda in entrambi gli scenari: quando il DC viene eseguito come VM su un host con traffico di rete tramite uno switch virtuale e quando si collega direttamente a uno switch fisico. I commutatori virtuali richiedono un'attenta pianificazione della larghezza di banda. L'uplink deve supportare i dati aggregati che vi passano attraverso. La scheda di rete fisica dell'host collegata allo switch deve supportare il carico di corrente continua e tutti gli altri guest che condividono lo switch virtuale e si connettono tramite la scheda di rete fisica.
Esempio di riepilogo del calcolo di rete
La tabella seguente contiene valori di uno scenario di esempio che è possibile usare per calcolare la capacità di rete:
| System | Larghezza di banda massima |
|---|---|
| DC 1 | 6,5 MBps |
| DC 2 | 6,25MBps |
| DC 3 | 6,25MBps |
| DC 4 | 5,75MBps |
| DC 5 | 4,75 MBps |
| Total | 28,5 MBps |
In base a questa tabella, la larghezza di banda consigliata sarebbe 72MBps (28,5MBps ÷ 40%).
| Numero di sistemi di destinazione | Larghezza di banda totale (dalla larghezza di banda massima) |
|---|---|
| 2 | 28,5 MBps |
| Risultato di un comportamento normale | 28,5 ÷ 2 = 14,25MBps |
Come sempre, è consigliabile presupporre che il carico client aumenterà nel tempo, quindi è consigliabile pianificare questa crescita il prima possibile. È consigliabile pianificare almeno il 50% della crescita stimata del traffico di rete.
Storage
Quando si pianifica la capacità per l'archiviazione, è necessario considerare due aspetti:
- Capacità o dimensioni di archiviazione
- Performance
Anche se la capacità è importante, è importante non trascurare le prestazioni. Con i costi hardware correnti, la maggior parte degli ambienti non è sufficientemente grande perché entrambi i fattori siano un problema importante. Pertanto, il solito consiglio è quello di inserire solo la RAM quanto le dimensioni del database. Tuttavia, questa raccomandazione potrebbe essere eccessiva per le posizioni satellite in ambienti più grandi.
Sizing
Valutazione dell’archiviazione
Rispetto a quando Active Directory è stato introdotto, in un'epoca in cui le unità da 4 GB e 9 GB erano le dimensioni più comuni delle unità, oggi il ridimensionamento per Active Directory non è nemmeno più una questione rilevante, eccetto che per i contesti più grandi. Con le dimensioni più piccole disponibili del disco rigido nell'intervallo di 180 GB, l'intero sistema operativo, SYSVOL, e NTDS.dit può facilmente entrare su un'unità. Di conseguenza, è consigliabile evitare di investire troppo nel dimensionamento dello spazio di archiviazione.
È consigliabile usare 110% delle NTDS.dit dimensioni disponibili in modo da poter deframmentare lo spazio di archiviazione.
Oltre a questa raccomandazione, è consigliabile prendere le normali considerazioni per soddisfare la crescita futura.
Se si intende valutare lo spazio di archiviazione, è necessario prima valutare quanto grandi devono essere NTDS.dit e SYSVOL. Queste misurazioni consentono di ridimensionare sia il disco fisso che le allocazioni di RAM. Poiché i componenti sono relativamente bassi, non è necessario essere molto precisi quando si esegue la matematica. Per altre informazioni sulla valutazione dell'archiviazione, vedere Limiti di archiviazione e stime della crescita per utenti e unità organizzative di Active Directory.
Note
Gli articoli collegati nel paragrafo precedente sono basati sulle stime delle dimensioni dei dati effettuate durante il rilascio di Active Directory in Windows 2000. Quando si effettua una stima personalizzata, usare le dimensioni degli oggetti che riflettono le dimensioni effettive degli oggetti nell'ambiente.
Quando si esaminano gli ambienti esistenti con più domini, è possibile notare variazioni nelle dimensioni del database. Quando si individuano queste varianti, usare le dimensioni del catalogo globale (GC) e non GC più piccole.
Le dimensioni del database possono variare tra le versioni del sistema operativo. I controller di dominio che eseguono versioni precedenti del sistema operativo hanno dimensioni del database inferiori rispetto ai controller che eseguono una versione successiva. Il controller di dominio con funzionalità come Active Directory REcycle Bin o Credential Roaming abilitato può influire anche sulle dimensioni del database.
Note
- Per i nuovi ambienti, tenere presente che 100.000 utenti nello stesso dominio utilizzano circa 450 MB di spazio. Gli attributi popolati possono avere un impatto enorme sulla quantità totale di spazio utilizzata. Molti oggetti popolano gli attributi, tra cui Microsoft Exchange Server e Skype for Business. Di conseguenza, è consigliabile valutare in base al portfolio di prodotti dell'ambiente. È consigliabile tenere presente che i calcoli e i test per stime precise per tutti gli ambienti, eccetto i più grandi, potrebbero non valere il tempo o lo sforzo significativi.
- Per abilitare la deframmentazione offline, verificare che lo spazio disponibile sia il 110% della dimensione
NTDS.dit. Questo spazio disponibile consente anche di pianificare la crescita nel corso della durata hardware da tre a cinque anni del server. Se si dispone dello spazio di archiviazione, allocare spazio libero sufficiente a 300% delle dimensioni DIT è un modo sicuro per supportare la crescita e la deframmentazione. Questa allocazione del buffer di espansione semplifica la manutenzione futura.
Considerazioni sulla virtualizzazione per l’archiviazione
Negli scenari in cui si allocano più file VHD (Virtual Hard Disk) a un singolo volume, è consigliabile usare un disco a stato fisso. Il disco deve avere almeno 210% le dimensioni del DIT per assicurarsi di disporre di spazio sufficiente per le proprie esigenze. Questa dimensione fissa del VHD include 100% della dimensione DIT più 110% di spazio libero.
Esempio di riepilogo del calcolo dell'archiviazione
Nella tabella seguente sono elencati i valori usati per stimare i requisiti di spazio per uno scenario di archiviazione ipotetico.
| Dati raccolti in fase di valutazione | Size |
|---|---|
NTDS.dit grandezza |
35 GB |
| Modificatore per consentire la deframmentazione offline | 2,1 GB |
| Archiviazione totale necessaria | 73,5 GB |
La stima dell'archiviazione deve includere anche più componenti di archiviazione oltre il database. Questi componenti includono:
- SYSVOL
- File del sistema operativo
- File di pagina
- File temporanei
- Dati memorizzati nella cache locale, ad esempio i file del programma di installazione
- Applications
Prestazioni di archiviazione
Essendo il componente più lento di qualsiasi computer, l’archiviazione può avere il maggiore impatto negativo sull'esperienza client. Per gli ambienti sufficientemente grandi che le raccomandazioni di dimensionamento della RAM in questo articolo non sono fattibili, le conseguenze dell'ignorare la pianificazione della capacità per l'archiviazione possono essere devastanti per le prestazioni del sistema. Le complessità e le varietà della tecnologia di archiviazione disponibile aumentano ulteriormente il rischio, in quanto la raccomandazione tipica di inserire il sistema operativo, i log e il database in dischi fisici separati non si applica universalmente in tutti gli scenari.
Le raccomandazioni precedenti sui dischi presupponevano che un disco fosse uno spindle dedicato che consentiva l'I/O isolato. Questo presupposto di spindle dedicato non è più vero a causa dell'introduzione dei tipi di archiviazione seguenti:
- RAID
- Nuovi tipi di risorse di archiviazione e scenari di archiviazione virtualizzata e condivisa
- Spindle condivisi su una Rete di archiviazione (SAN)
- File VHD su una SAN o su un’archiviazione collegata alla rete
- Unità ssd (SSD)
- Unità NVMe (Memory Express) non volatile
- Architetture di archiviazione a livelli, ad esempio il livello di archiviazione SSD, la memorizzazione nella cache di archiviazione basata su spindle più grande
Altri carichi di lavoro posizionati nell'archiviazione back-end possono sovraccaricare l'archiviazione condivisa, ad esempio RAID, SAN, NAS, JBOD, Storage Spaces e VHD. Questi tipi di dispositivi di archiviazione possono presentare una considerazione aggiuntiva. Ad esempio, i problemi relativi a SAN, rete o driver tra il disco fisico e l'applicazione AD possono causare limitazioni e ritardi. Per chiarire, questi tipi di architetture di archiviazione non sono una scelta errata, ma sono più complessi, il che significa che è necessario prestare particolare attenzione per assicurarsi che ogni componente funzioni come previsto. Per spiegazioni più dettagliate, vedere Appendice C e Appendice D più avanti in questo articolo.
Questa tecnologia di archiviazione a stato solido (NVMe e SSD) non presenta le stesse limitazioni meccaniche dei dischi rigidi tradizionali. Tuttavia, hanno ancora limitazioni di I/O. Quando si superano questi limiti, il sistema può diventare sovraccarico.
L'obiettivo della pianificazione delle prestazioni di archiviazione è garantire che il numero necessario di operazioni di I/O sia sempre disponibile e che si verifichino entro un intervallo di tempo accettabile. Per altre informazioni sugli scenari con l'archiviazione collegata in locale, vedere Appendice C. È possibile applicare i principi nell'appendice a scenari di archiviazione più complessi e conversazioni con i fornitori che supportano le soluzioni di archiviazione back-end.
A causa del numero di opzioni di archiviazione attualmente disponibili, è consigliabile consultare i team di supporto hardware o i fornitori durante la pianificazione per garantire che la soluzione soddisfi le esigenze della distribuzione di Servizi di dominio Active Directory. Durante queste conversazioni, potrebbero risultare utili i contatori delle prestazioni seguenti, soprattutto quando il database è troppo grande per la RAM:
-
LogicalDisk(*)\Avg Disk sec/Read(ad esempio, seNTDS.ditè archiviato nell'unità D, il percorso completo saràLogicalDisk(D:)\Avg Disk sec/Read) LogicalDisk(*)\Avg Disk sec/WriteLogicalDisk(*)\Avg Disk sec/TransferLogicalDisk(*)\Reads/secLogicalDisk(*)\Writes/secLogicalDisk(*)\Transfers/sec
Quando si forniscono i dati, è necessario assicurarsi che gli intervalli di campionamento siano di 15, 30 o 60 minuti per fornire l'immagine più accurata dell'ambiente corrente possibile.
Valutazione dei risultati
Questa sezione è incentrata sulle letture dal database, perché il database è in genere il componente più impegnativo. È possibile applicare la stessa logica alle scritture nel file di log sostituendo <NTDS Log>)\Avg Disk sec/Write e LogicalDisk(<NTDS Log>)\Writes/sec).
Il LogicalDisk(<NTDS>)\Avg Disk sec/Read contatore indica se lo spazio di archiviazione corrente è di dimensioni adeguate. Se il valore è approssimativamente uguale al tempo di accesso al disco previsto per il tipo di disco, il LogicalDisk(<NTDS>)\Reads/sec contatore è una misura valida. Se i risultati sono approssimativamente uguali al tempo di accesso al disco per il tipo di disco, il LogicalDisk(<NTDS>)\Reads/sec contatore è una misura valida. Anche se la latenza accettabile varia in base al fornitore di archiviazione, gli intervalli validi per LogicalDisk(<NTDS>)\Avg Disk sec/Read sono:
- 7.200 rpm: da 9 millisecondi a 12,5 millisecondi (ms)
- 10.000 rpm: da 6 ms a 10 ms
- 15.000 rpm: da 4 ms a 6 ms
- SSD : da 1 ms a 3 ms
Si potrebbe sentire da altre origini che le prestazioni di archiviazione si degradano intorno a 15 ms a 20 ms. La differenza tra questi valori e i valori nell'elenco precedente è che i valori dell'elenco mostrano l'intervallo operativo normale. Gli altri valori sono a scopo di risoluzione dei problemi, che consentono di identificare quando l'esperienza client è danneggiata abbastanza che diventa evidente. Per altre informazioni, vedere Appendice C.
-
LogicalDisk(<NTDS>)\Reads/secè la quantità di operazioni di I/O attualmente eseguite dal sistema.- Se
LogicalDisk(<NTDS>)\Avg Disk sec/Readè compreso nell'intervallo ottimale per l'archiviazione back-end, è possibile usareLogicalDisk(<NTDS>)\Reads/secdirettamente per ridimensionare l'archiviazione. - Se
LogicalDisk(<NTDS>)\Avg Disk sec/Readnon è compreso nell'intervallo ottimale per l'archiviazione back-end, sono necessarie altre operazioni di I/O in base alla formula seguente:LogicalDisk(<NTDS>)\Avg Disk sec/Read÷ tempo di accesso al disco multimediale fisico ×LogicalDisk(<NTDS>)\Avg Disk sec/Read
- Se
Quando si eseguono questi calcoli, ecco alcuni aspetti da considerare:
- Se il server ha una quantità di RAM non ottimale, i valori risultanti potrebbero essere troppo alti e non sufficientemente accurati da essere utili per la pianificazione. Tuttavia, è comunque possibile usarli per prevedere scenari peggiori.
- Se si aggiunge o si ottimizza la RAM, si riduce anche la quantità di operazioni di I/O
LogicalDisk(<NTDS>)\Reads/Secdi lettura. Questa riduzione può causare una soluzione di archiviazione meno affidabile rispetto ai calcoli originali suggeriti. Sfortunatamente, non è possibile fornire informazioni più specifiche su ciò che significa questa istruzione, poiché i calcoli variano notevolmente a seconda dei singoli ambienti, in particolare del carico client. Tuttavia, è consigliabile regolare il ridimensionamento dello spazio di archiviazione dopo aver ottimizzato la RAM.
Considerazioni sulla virtualizzazione per le prestazioni
Analogamente alle sezioni precedenti, l'obiettivo delle prestazioni di virtualizzazione è garantire che l'infrastruttura condivisa possa supportare il carico totale di tutti i consumer. Tenere presente questo obiettivo quando si pianificano gli scenari seguenti:
- Una condivisione CD fisica dello stesso supporto in un'infrastruttura SAN, NAS o iSCSI come altri server o applicazioni.
- Un utente che usa l'accesso pass-through a un'infrastruttura SAN, NAS o iSCSI che condivide il supporto.
- Un utente che usa un file VHD su supporti condivisi localmente o un'infrastruttura SAN, NAS o iSCSI.
Dal punto di vista di un utente guest, dover passare attraverso un host per accedere a qualsiasi archiviazione impatta sulle prestazioni, poiché l'utente deve percorrere più percorsi di codice per ottenere l'accesso. Il test delle prestazioni indica che la virtualizzazione influisce sulla velocità effettiva in base alla quantità di processore usano il sistema host. L'utilizzo del processore influisce sul numero di risorse richieste dall'utente guest dell'host. Questa richiesta contribuisce alle considerazioni di virtualizzazione per l'elaborazione da prendere per le esigenze di elaborazione in scenari virtualizzati. Per altre informazioni, vedere Appendice A.
Inoltre, a complicare ulteriormente la questione, c'è il numero di opzioni di archiviazione disponibili al momento, ciascuna con un impatto prestazionale molto diverso. Queste opzioni includono l'archiviazione pass-through, le schede SCSI e l'IDE. Quando si esegue la migrazione da un ambiente fisico a un ambiente virtuale, è necessario modificare le diverse opzioni di archiviazione per gli utenti guest virtualizzati usando un moltiplicatore di 1,10. Tuttavia, non è necessario prendere in considerazione le modifiche durante il trasferimento tra diversi scenari di archiviazione, come se l'archiviazione sia locale, SAN, NAS o iSCSI è più importante.
Esempio di calcolo della virtualizzazione
Determinazione della quantità di I/O necessaria per un sistema efficiente in condizioni operative normali:
- LogicalDisk(
<NTDS Database Drive>) ÷ Trasferimenti al secondo durante il periodo di picco di 15 minuti - Per determinare la quantità di I/O necessaria per l'archiviazione quando la capacità dell'archiviazione sottostante viene superata:
IOPS necessari = (LogicalDisk(
<NTDS Database Drive>)) ÷ Lettura media disco/sec ÷<Target Avg Disk Read/sec>) × LogicalDisk(<NTDS Database Drive>)\Lettura/sec
| Counter | Value |
|---|---|
Actual LogicalDisk(<NTDS Database Drive>)\Media disco secondi/trasferimento |
0,02 secondi (20 millisecondi) |
Destinazione LogicalDisk(<NTDS Database Drive>)\Media Disco sec/Trasferimento |
0,01 secondi |
| Moltiplicatore per la modifica nell'I/O disponibile | 0,02 ÷ 0,01 = 2 |
| Nome del valore | Value |
|---|---|
LogicalDisk(<NTDS Database Drive>)\Trasferimenti/sec |
400 |
| Moltiplicatore per la modifica nell'I/O disponibile | 2 |
| IOPS totali necessari durante il periodo di picco | 800 |
Per determinare la frequenza con cui è necessario riscaldare la cache:
- Determinare il tempo massimo che si trova accettabile per passare al riscaldamento della cache. Negli scenari tipici, una quantità di tempo accettabile sarebbe il tempo necessario per caricare l'intero database da un disco. Negli scenari in cui la RAM non può caricare l'intero database, usare il tempo necessario per riempire l'intera RAM.
- Determinare le dimensioni del database, escluso lo spazio che non si prevede di usare. Per altre informazioni, vedere Valutazione per l'archiviazione.
- Dividere le dimensioni del database per 8 KB per ottenere il numero totale di operazioni di I/O necessarie per caricare il database.
- Dividere il totale di operazioni di I/O per il numero di secondi nell'intervallo di tempo definito.
Il numero calcolato è un'approssimazione. Non è esatto perché le dimensioni della cache ESE (Extensible Storage Engine) non sono fisse. Per impostazione predefinita, la cache aumenta e si riduce, quindi Active Directory Domain Services potrebbe rimuovere le pagine caricate in precedenza. Una dimensione della cache fissa renderebbe la stima più precisa.
| Punti dati da raccogliere | Values |
|---|---|
| Tempo massimo accettabile per il riscaldamento | 10 minuti (600 secondi) |
| Dimensione del database | 2 GB |
| Passaggio di calcolo | Formula | Result |
|---|---|---|
| Calcolo della dimensione del database in pagine | (2 GB × 1024 × 1024) = Dimensioni del database in KB | 2.097.152 KB |
| Calcolo del numero di pagine nel database | 2.097.152 KB ÷ 8 KB = Numero di pagine | 262.144 pagine |
| Calcolo degli IOPS necessari per riscaldare completamente la cache | 262,144 pagine ÷ 600 secondi = IOPS necessari | 437 operazioni di I/O al secondo |
Processing
Valutazione dell'uso del processore di Active Directory
Per la maggior parte degli ambienti, la gestione della capacità di elaborazione è il componente che merita più attenzione. Quando si valuta la capacità della CPU necessaria per la distribuzione, è consigliabile considerare i due aspetti seguenti:
- Le applicazioni nell'ambiente si comportano come previsto all'interno di un'infrastruttura di servizi condivisi in base ai criteri descritti in Rilevamento delle ricerche costose e inefficienti? In ambienti di dimensioni maggiori, le applicazioni con codice non adeguato possono rendere il carico della CPU volatile, richiedere una quantità eccessiva di tempo di CPU a scapito di altre applicazioni, aumentare le esigenze di capacità e distribuire in modo non uniforme il carico nei controller di dominio.
- Servizi di dominio Active Directory è un ambiente distribuito con molti potenziali client le cui esigenze di elaborazione variano notevolmente. I costi stimati per ogni client possono variare a causa dei modelli di utilizzo e del numero di applicazioni che usano Servizi di dominio Active Directory. Come in Rete, è consigliabile valutare come valutazione della capacità totale necessaria nell'ambiente invece di esaminare ogni client uno alla volta.
Completare la stima dell'archiviazione prima di iniziare a stimare l'utilizzo del processore. Non è possibile eseguire un'ipotesi accurata senza dati validi sul carico del processore. È anche importante assicurarsi che lo spazio di archiviazione non crei colli di bottiglia prima di risolvere i problemi del processore. Quando si rimuovono gli stati di attesa del processore, l'utilizzo della CPU aumenta perché non deve più attendere i dati. Di conseguenza, i contatori delle prestazioni a cui prestare maggiore attenzione sono:
Logical Disk(<NTDS Database Drive>)\Avg Disk sec/ReadProcess(lsass)\ Processor Time
Se il Logical Disk(<NTDS Database Drive>)\Avg Disk sec/Read contatore supera i 10 millisecondi o 15 millisecondi, i dati in Process(lsass)\ Processor Time sono artificialmente bassi e il problema è correlato alle prestazioni di archiviazione. È consigliabile impostare intervalli di campionamento su 15, 30 o 60 minuti per i dati più accurati possibili.
Panoramica dell'elaborazione
Per pianificare la capacità dei controller di dominio, la potenza di elaborazione richiede la massima attenzione e comprensione. Quando si ridimensionano i sistemi per garantire prestazioni massime, c'è sempre un componente che rappresenta il collo di bottiglia e in un controller di dominio di dimensioni appropriate questo componente è il processore.
Come per la sezione dedicata alla rete, dove la richiesta dell'ambiente viene esaminata sito per sito, lo stesso deve essere fatto per la capacità di calcolo richiesta. A differenza della sezione dedicata alla rete, dove le tecnologie di rete disponibili superano di gran lunga la normale richiesta, si presti maggiore attenzione al dimensionamento della capacità della CPU. Come in ogni ambiente di dimensioni anche solo moderate, qualsiasi cosa che superi le poche migliaia di utenti simultanei può comportare un carico notevole sulla CPU.
Sfortunatamente, a causa dell'enorme variabilità delle applicazioni client che usano ACTIVE Directory, una stima generale degli utenti per CPU è inapplicabile per tutti gli ambienti. In particolare, le richieste di calcolo sono soggette al comportamento degli utenti e al profilo delle applicazioni. Pertanto, ogni ambiente deve essere dimensionato individualmente.
Profilo comportamentale del sito di destinazione
Quando si pianifica la capacità per un intero sito, l'obiettivo deve essere una progettazione di capacità N + 1. In questa progettazione, anche se un sistema non riesce durante il periodo di picco, il servizio può continuare a livelli accettabili di qualità. In uno scenario N , il carico in tutte le caselle deve essere inferiore a 80%-100% durante i periodi di picco.
Inoltre, le applicazioni e i client del sito usano la funzione DsGetDcName consigliata per l'individuazione dei controller di dominio. Dovrebbero essere già distribuiti uniformemente con solo picchi temporanei secondari.
Verranno ora esaminati due esempi di ambienti su destinazione e fuori destinazione. In primo luogo, si esaminerà un esempio di ambiente che funziona come previsto e non supera l'obiettivo di pianificazione della capacità.
Per il primo esempio, si stanno facendo i presupposti seguenti:
- Ognuno dei cinque controller di dominio nel sito ha quattro CPU.
- L'utilizzo totale della CPU di destinazione durante l'orario di ufficio è 40% in condizioni operative normali (N + 1) e 60% in caso contrario (N). Durante le ore non lavorative, l'utilizzo della CPU di destinazione è 80% perché si prevede che il software di backup e altri processi di manutenzione usino tutte le risorse disponibili.
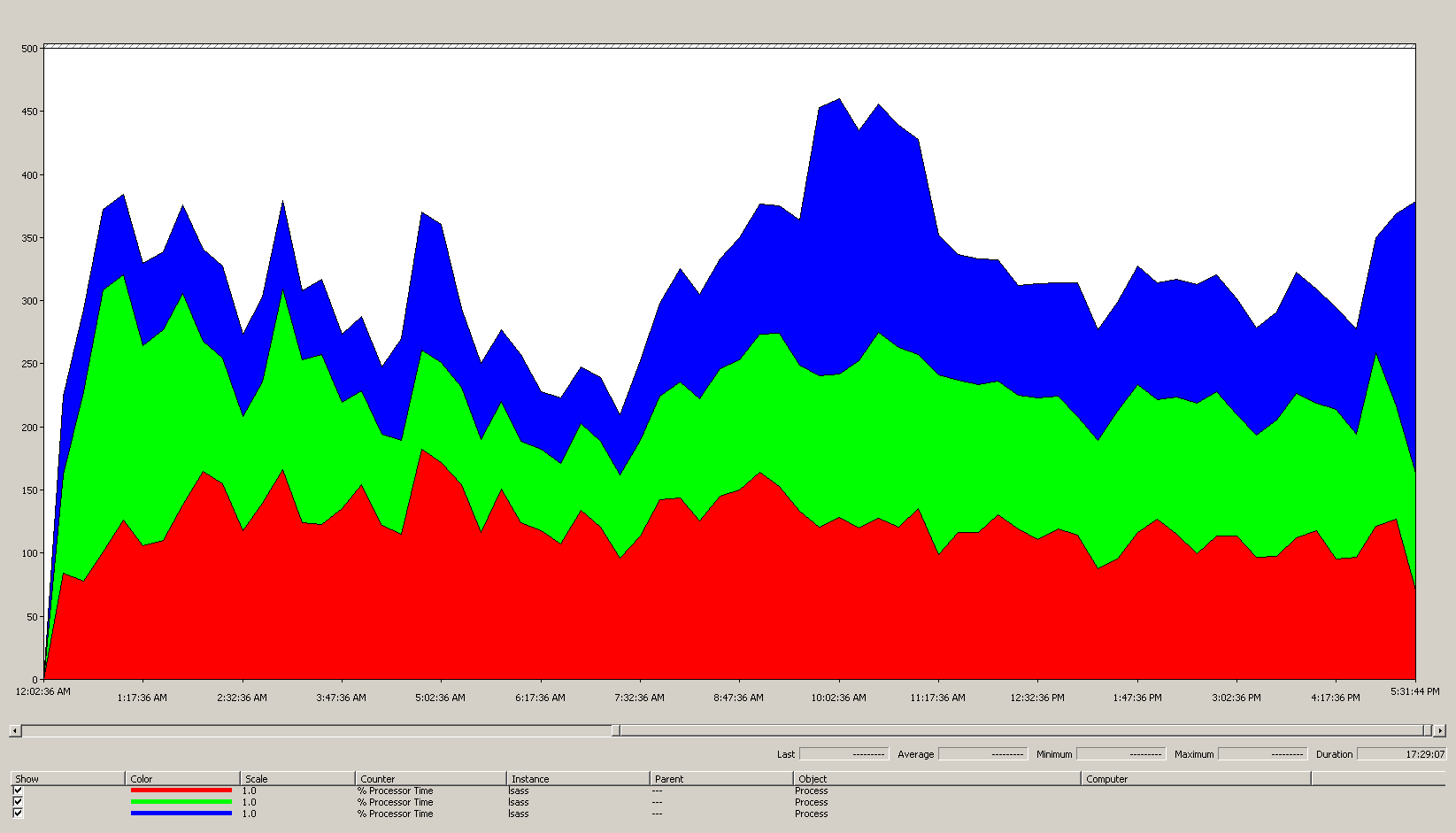
A questo punto, esaminiamo il (Processor Information(_Total)\% Processor Utility) grafico, per ognuno dei controller di dominio, come illustrato nell'immagine seguente.
Una screenshot del grafico dell'utilizzo della CPU per ciascun controller di dominio.
Il carico viene distribuito in modo uniforme, ovvero ciò che ci si aspetta quando i client usano il localizzatore dc e le ricerche scritte correttamente.
In diversi intervalli di cinque minuti, ci sono picchi al 10%, a volte anche al 20%. Tuttavia, a meno che questi picchi non superino la destinazione del piano di capacità, non è necessario esaminarli.
Il periodo di picco per tutti i sistemi è compreso tra le 8:00 e le 9:15. Il giorno lavorativo medio dura dalle 5:00 alle 17:00. Di conseguenza, eventuali picchi casuali di utilizzo della CPU che si verificano tra le 17:00 e le 14:00 sono al di fuori dell'orario di ufficio e pertanto non è necessario includerli nei problemi di pianificazione della capacità.
Durante le ore di minore attività, brevi picchi in un sistema ben gestito provengono in genere da:
- Processi di backup
- Analisi antivirus complete
- Analisi dell'inventario hardware
- Analisi dell'inventario software
- Distribuzioni di software o patch
I picchi all'esterno di queste attività potrebbero indicare un carico anomalo e giustificare un'indagine. Poiché questi picchi si verificano al di fuori dell'orario di ufficio, non vengono conteggiati per superare gli obiettivi di pianificazione della capacità.
Poiché ogni sistema è circa il 40% e tutti hanno lo stesso numero di CPU, se uno di essi passa offline, i sistemi rimanenti vengono eseguiti con una stima del 53%. Il carico 40% del sistema D viene quindi suddiviso uniformemente tra i sistemi rimanenti e aggiunto al carico 40% esistente. Questo presupposto di ridistribuzione lineare non è perfettamente accurato, ma fornisce una precisione sufficiente per la stima.
Si esaminerà quindi un esempio di ambiente che non ha un utilizzo corretto della CPU e supera la destinazione di pianificazione della capacità.
In questo esempio, due controller di dominio funzionano al 40%. Uno diventa offline e il controller di dominio rimanente passa a un valore stimato di 80%. Durante il failover questo carico supera la soglia pianificata di capacità e riduce il margine di riserva al 10%-20% durante i picchi. Ogni picco può ora portare la corrente continua al 90% o anche al 100%, riducendo la reattività.
Calcolo delle richieste della CPU
Il Process\% Processor Time contatore delle prestazioni tiene traccia della quantità totale di tempo trascorso da tutti i thread dell'applicazione nella CPU, quindi divide tale somma per la quantità totale di tempo di sistema passato. Un'applicazione multithread in un sistema multi-CPU può superare il 100% del tempo CPU e interpretare i dati in modo diverso rispetto al contatore Processor Information\% Processor Utility. In pratica, il Process(lsass)\% Processor Time contatore tiene traccia del numero di CPU in esecuzione al 100% del sistema per supportare le richieste di un processo. Ad esempio, se il contatore ha un valore pari al 200%, significa che il sistema richiede due CPU in esecuzione al 100% per supportare il carico completo di Active Directory Domain Services. Anche se una CPU in esecuzione al 100% della capacità è la più conveniente in termini di energia e consumo energetico, un sistema multithread è più reattivo quando il suo sistema non è in esecuzione al 100%. I motivi di questa efficienza sono descritti nell'Appendice A.
Per supportare picchi temporanei nel carico del client, è consigliabile impostare come destinazione un periodo di picco della CPU tra il 40% e il 60% della capacità di sistema. Ad esempio, nel primo esempio nel profilo di comportamento del sito di destinazione, è necessario tra 3.33 CPU (60% target) e 5 CPU (40% target) per supportare il carico di AD DS. È consigliabile aggiungere capacità aggiuntiva in base alle esigenze del sistema operativo e a qualsiasi altro agente richiesto, ad esempio antivirus, backup, monitoraggio e così via. Pianificare di riservare 5-10% della capacità di una CPU per gli agenti dell'infrastruttura (antivirus, backup, monitoraggio). Misura l'utilizzo effettivo degli agenti nel tuo ambiente di lavoro e adattalo in base alle esigenze. Per rivedere l'esempio, è necessario tra il 3,43 (60% di destinazione) e il 5,1 (40% di destinazione) per supportare il carico durante i periodi di picco.
Si esaminerà ora un esempio di calcolo per un processo specifico. In questo caso, verrà esaminato il processo LSASS.
Calcolo dell'utilizzo della CPU per il processo LSASS
In questo esempio, il sistema è uno scenario N + 1 in cui un server trasporta il carico di Servizi di dominio Active Directory mentre è presente un server aggiuntivo per la ridondanza.
Il grafico seguente mostra il tempo del processore per il processo LSASS su tutti i processori per questo scenario di esempio. Questi punti dati provengono dal Process(lsass)\% Processor Time contatore delle prestazioni.
Di seguito è riportato il grafico del tempo del processore LSASS relativo all'ambiente dello scenario:
- Nel sito sono presenti tre controller di dominio.
- Il giorno lavorativo inizia a salire intorno alle 7:00 e poi scende alle 17:00.
- Il periodo più affollato del giorno è dalle 9:30 alle 11:00.
Note
Tutti i dati relativi alle prestazioni sono di tipo cronologico. Il punto dati di picco alle 9:15 indica il carico dalle 9:00 alle 9:15.
- I picchi prima delle 7:00 potrebbero indicare un carico aggiuntivo da fusi orari diversi o attività dell'infrastruttura in background, ad esempio i backup. Tuttavia, poiché questo picco è inferiore al picco di attività alle 9:30, non è una causa di preoccupazione.
Al carico massimo, il processo LSASS utilizza circa 4,85 CPU in esecuzione a 100%, che sarebbe 485% su una singola CPU. Questi risultati suggeriscono che il sito dello scenario necessita di circa 12/25 CPU per gestire Active Directory Domain Services. Quando si porta il 5% consigliato al 10% di capacità aggiuntiva per i processi in background, il server necessita da 12,30 a 12,25 CPU per supportare il carico corrente. Le stime che prevedono una crescita futura rendono questo numero ancora più elevato.
Quando ottimizzare LDAP Weights
Esistono alcuni scenari in cui è consigliabile prendere in considerazione l'ottimizzazione di LdapSrvWeight. Nel contesto della pianificazione della capacità, è consigliabile ottimizzarlo quando le applicazioni, i caricamenti degli utenti o le funzionalità di sistema sottostanti non sono bilanciate in modo uniforme.
Le sezioni seguenti descrivono due scenari di esempio in cui è necessario ottimizzare i pesi LDAP (Lightweight Directory Access Protocol).
Esempio 1: ambiente dell'emulatore PDC
Se si usa un emulatore PDC (Primary Domain Controller), il comportamento dell'utente o dell'applicazione distribuito in modo non uniforme può influire su più ambienti contemporaneamente. L'emulatore PDC ha in genere un carico di CPU superiore rispetto ad altri controller di dominio. Molte operazioni preferiscono o lo contattano sempre, tra cui:
- Strumenti di gestione di Criteri di gruppo (creazione, modifica, collegamento, aggiornamento della console Gestione Criteri di gruppo)
- Verifica del cambio della password/tentativi di autenticazione di secondo livello (verifica della password di backup)
- Operazioni di creazione e manutenzione fiducia
- Gerarchia del servizio ora (sorgente di tempo autorevole nel dominio/foresta)
- Elaborazione del blocco dell'account
- Applicazioni legacy o non configurate correttamente che hanno ancora come destinazione l'emulatore PDC
Monitorare la CPU separatamente e pianificare un margine aggiuntivo se queste attività sono comuni.
È consigliabile ottimizzare l'emulatore PDC solo se esiste una differenza notevole nell'utilizzo della CPU. L'ottimizzazione deve ridurre il carico nell'emulatore PDC e aumentare il carico su altri controller di dominio, consentendo una distribuzione del carico più uniforme.
In questi casi, impostare il valore per LDAPSrvWeight tra 50 e 75 per l'emulatore PDC.
| System | Utilizzo della CPU con impostazioni predefinite | Nuovo LdapSrvWeight | Nuovo utilizzo stimato della CPU |
|---|---|---|---|
| Controller di dominio 1 (emulatore PDC) | 53% | 57 | 40% |
| DC 2 | 33% | 100 | 40% |
| DC 3 | 33% | 100 | 40% |
Il catch è che se il ruolo dell'emulatore PDC viene trasferito o sequestrato, in particolare a un altro controller di dominio nel sito, l'utilizzo della CPU aumenta notevolmente sul nuovo emulatore PDC.
In questo scenario di esempio si presuppone che in base al profilo di comportamento del sito di destinazione che tutti e tre i controller di dominio in questo sito abbiano quattro CPU. In condizioni normali, cosa accadrebbe se uno di questi controller di dominio avesse otto CPU? Ci sarebbero due controller di dominio con un utilizzo del 40% e uno con un utilizzo del 20%. Anche se questa configurazione non è necessariamente negativa, è possibile usare l'ottimizzazione del peso LDAP per bilanciare meglio il carico.
Esempio 2: ambiente con conteggi cpu diversi
Quando si dispone di server con numero di CPU e velocità diversi nello stesso sito, è necessario assicurarsi che siano distribuiti in modo uniforme. Ad esempio, se il sito ha due server a otto core e un server a quattro core, il server a quattro core ha solo la metà della potenza di elaborazione degli altri due server. Se il carico del client viene distribuito uniformemente, significa che il server a quattro core deve funzionare due volte più difficile come i due server a otto core per gestire il carico della CPU. Oltre a questo, se uno dei server a otto core diventa offline, il server a quattro core viene sovraccaricato.
| System | Informazioni sul processore % Utilità processore (_Totale) Utilizzo della CPU con impostazioni predefinite |
Nuovo LdapSrvWeight | Nuovo utilizzo stimato della CPU |
|---|---|---|---|
| 4-CPU, Controller di dominio 1 | 40 | 100 | 30% |
| 4-CPU, Controller di dominio 2 | 40 | 100 | 30% |
| 8-CPU, Controller di dominio 3 | 20 | 200 | 30% |
La pianificazione di uno scenario N + 1 è fondamentale. L'impatto di un controller di dominio che va offline deve essere calcolato per ogni scenario. Nell'esempio precedente il caricamento viene condiviso uniformemente tra tutti i server. In uno scenario N (un server perso), ogni server rimanente rimane a circa 60%. La distribuzione corrente è accettabile perché i rapporti rimangono coerenti. Quando si esamina lo scenario di ottimizzazione dell'emulatore PDC o qualsiasi scenario generale in cui il carico dell'utente o dell'applicazione è sbilanciato, l'effetto è diverso:
| System | Utilizzo Sintonizzato | Nuovo LdapSrvWeight | Stima del nuovo uso |
|---|---|---|---|
| Controller di dominio 1 (emulatore PDC) | 40% | 85 | 47% |
| DC 2 | 40% | 100 | 53% |
| DC 3 | 40% | 100 | 53% |
Considerazioni sulla virtualizzazione per l'elaborazione
Quando si pianifica la capacità per un ambiente virtualizzato, è necessario considerare due livelli: il livello host e il livello guest. A livello di host, è necessario identificare i periodi di picco del ciclo aziendale. Poiché la pianificazione dei thread guest nella CPU per una macchina virtuale è simile al recupero di thread di Active Directory Domain Services sulla CPU per un computer fisico, è comunque consigliabile usare il 40% al 60% dell'host sottostante. A livello di guest, poiché i principi di pianificazione dei thread sottostanti sono invariati, è comunque consigliabile mantenere l'utilizzo della CPU entro l'intervallo compreso tra il 40% e il 60%.
Per una configurazione con mapping diretto (un guest per host), riutilizzare i valori raccolti precedentemente per la pianificazione della capacità. Applicarli direttamente per dimensionare questa implementazione.
In uno scenario di host condiviso, considerare un sovraccarico di efficienza della CPU di circa il 10% causato dalla virtualizzazione. Se il sito necessita di 10 CPU con il 40% di utilizzo di destinazione su hardware fisico, aggiungere un'altra CPU per compensare. Allocare un totale di 11 CPU virtuali (vCPUs) tra i controller di dominio guest N.
Nei siti con distribuzioni miste di server fisici e virtuali, questo sovraccarico di virtualizzazione si applica solo alle macchine virtuali. In una progettazione N + 1, un server fisico a 10 CPU (o mappatura diretta) è approssimativamente equivalente a un data center virtuale con 11 vCPU. L'host necessita anche di altre 11 CPU riservate per la macchina virtuale.
Durante l'analisi e il calcolo del numero di CPU necessarie per supportare il carico di Active Directory Domain Services. Tenere presente che se si prevede di acquistare hardware, i tipi di hardware disponibili sul mercato potrebbero non corrispondere esattamente alle stime. Tuttavia, non si verifica alcun problema quando si usa la virtualizzazione. L'uso delle macchine virtuali riduce il lavoro necessario per aggiungere capacità di calcolo a un sito, perché è possibile aggiungere il numero di CPU con le specifiche esatte desiderate per una macchina virtuale. Tuttavia, la virtualizzazione non elimina la responsabilità di valutare accuratamente la potenza di calcolo necessaria per garantire che l'hardware sottostante sia disponibile quando i guest necessitano di più risorse della CPU. Pianificare sempre in anticipo la crescita.
Esempio di riepilogo del calcolo della virtualizzazione
| System | Cpu di picco |
|---|---|
| DC 1 | 120% |
| DC 2 | 147% |
| DC 3 | 218% |
| Utilizzo totale della CPU | 485% |
| Conteggio dei sistemi di destinazione | Il numero totale di CPU richiede |
|---|---|
| CPU necessaria per raggiungere un obiettivo del 40% durante il picco. | 485% ÷ 0,4 = 12,25 |
Se si proietta una crescita della domanda del 50% nei prossimi tre anni, pianificare 18.375 CPU (12,25 × 1,5) entro tale data. In alternativa, è possibile esaminare la domanda dopo il primo anno, quindi aggiungere capacità aggiuntiva in base ai risultati.
Carico di autenticazione client cross-trust per NTLM
Valutazione del carico di autenticazione client cross-trust
Molti ambienti possono avere uno o più domini connessi da un trust. Le richieste di autenticazione per le identità in altri domini che non usano Kerberos devono attraversare un trust usando un canale sicuro tra due controller di dominio. Il controller di dominio dell'utente contatta un controller di dominio nel dominio di destinazione o quello successivo lungo il percorso di attendibilità verso tale dominio. L'impostazione *MaxConcurrentAPI controlla il numero di chiamate che il controller di dominio può effettuare all'altro controller di dominio nel dominio attendibile. Per garantire che il canale sicuro possa gestire la quantità di carico necessaria per comunicare tra i controller di dominio, è possibile ottimizzare MaxConcurrentAPI o, se ci si trova in una foresta, creare trust di collegamento. Per altre informazioni su come determinare il volume di traffico tra trust, vedere Come eseguire l'ottimizzazione delle prestazioni per l'autenticazione NTLM usando l'impostazione MaxConcurrentApi.
Come per gli scenari precedenti, è necessario raccogliere dati durante i periodi di picco occupati del giorno per renderli utili.
Note
Gli scenari intraforestali e interforesti possono causare l'attraversamento di più trust, il che significa che è necessario ottimizzare durante ogni fase del processo.
Pianificazione della virtualizzazione
Quando si pianifica la capacità per la virtualizzazione, tenere presente alcuni aspetti:
- Molte applicazioni usano l'autenticazione NTLM per impostazione predefinita o in determinate configurazioni.
- Con l'aumentare del numero di client attivi, è quindi necessario che i server applicazioni abbiano una maggiore capacità.
- I client a volte mantengono le sessioni aperte per un periodo di tempo limitato e si riconnettono regolarmente per servizi come la sincronizzazione pull della posta elettronica.
- I server proxy Web che richiedono l'autenticazione per l'accesso a Internet possono causare un carico NTLM elevato.
Queste applicazioni possono creare un carico elevato per l'autenticazione NTLM, che pone uno stress significativo sui controller di dominio, soprattutto quando gli utenti e le risorse si trovano in domini diversi.
Esistono molti approcci che è possibile adottare per gestire il carico tra trust, che spesso è possibile e usare insieme contemporaneamente:
- Ridurre l'autenticazione client tra trust individuando i servizi utilizzati da un utente nel dominio in cui si trovano.
- Aumentare il numero di canali sicuri disponibili. Questi canali sono denominati trust di scorciatoia e sono rilevanti per il traffico all'interno della foresta e tra foreste diverse.
- Ottimizzare le impostazioni predefinite per MaxConcurrentAPI.
Per ottimizzare MaxConcurrentAPI in un server esistente, usare l'equazione seguente:
New_MaxConcurrentApi_setting≥ ( + semaphore_acquiressemaphore_time out) × average_semaphore_hold_time ÷time_collection_length
Per altre informazioni, vedere l'articolo della Knowledge Base 2688798: Come eseguire l'ottimizzazione delle prestazioni per l'autenticazione NTLM usando l'impostazione MaxConcurrentApi.
Considerazioni sulla virtualizzazione
Non sono necessarie considerazioni particolari, perché la virtualizzazione è un'impostazione di ottimizzazione del sistema operativo.
Esempio di calcolo dell'ottimizzazione della virtualizzazione
| Tipo di dati | Value |
|---|---|
| Acquisizioni di Semaphore (minimo) | 6,161 |
| Acquisizioni di Semaphore (massimo) | 6,762 |
| Timeout del semaforo | 0 |
| Tempo medio di attesa di Semaphore | 0.012 |
| Durata della raccolta (secondi) | 1:11 minuti (71 secondi) |
| Formula (da KB 2688798) | ((6762 - 6161) + 0) × 0,012 / |
| Valore minimo per MaxConcurrentAPI | ((6762 - 6161) + 0) × 0,012 ÷ 71 = 0,101 |
Per questo sistema e per questo lasso di tempo, i valori predefiniti sono accettabili.
Monitoraggio della conformità agli obiettivi di pianificazione della capacità
In questo articolo, abbiamo discusso di come la pianificazione e la scalabilità contribuiscano a raggiungere gli obiettivi di utilizzo. La tabella seguente riepiloga le soglie consigliate da monitorare per garantire che i sistemi funzionino come previsto. Tenere presente che queste non sono soglie di prestazioni, ma solo soglie di pianificazione della capacità. Un server che opera in eccesso di queste soglie funziona ancora, ma è necessario verificare che le applicazioni funzionino come previsto prima di iniziare a visualizzare i problemi di prestazioni man mano che la domanda degli utenti aumenta. Se le applicazioni hanno esito positivo, è consigliabile iniziare a valutare gli aggiornamenti hardware o altre modifiche alla configurazione.
| Category | Contatore delle prestazioni | Interval/Sampling | Target | Warning |
|---|---|---|---|---|
| Processor | Processor Information(_Total)\% Processor Utility |
60 min | 40% | 60% |
| RAM (Windows Server 2008 R2 o versioni precedenti) | Memory\Available MB |
< 100 MB | N/A | < 100 MB |
| RAM (Windows Server 2012 e versioni successive) | Memory\Long-Term Average Standby Cache Lifetime(s) |
30 minuti | Deve essere testato | Deve essere testato |
| Network | Network Interface(*)\Bytes Sent/sec
|
30 minuti | 40% | 60% |
| Storage | LogicalDisk((<NTDS Database Drive>))\Avg Disk sec/Read
|
60 min | 10 ms | 15 ms |
| Servizi di Active Directory | Netlogon(*)\Average Semaphore Hold Time |
60 min | 0 | 1 secondo |
Appendice A: criteri di dimensionamento della CPU
Questa appendice illustra i termini e i concetti utili che consentono di stimare le esigenze di dimensionamento della CPU dell'ambiente.
Definizioni: ridimensionamento della CPU
Un processore (microprocessore) è un componente che legge ed esegue le istruzioni del programma.
Un processore multi-core ha più CPU nello stesso circuito integrato.
Un sistema multi-CPU ha più CPU che non si trova nello stesso circuito integrato.
Un processore logico è un processore che ha un solo motore di elaborazione logico dal punto di vista del sistema operativo.
Queste definizioni includono hyperthreading, un core nel processore multi-core o un singolo processore core.
Poiché i sistemi server di oggi hanno più processori, più processori multi-core e hyper-threading, queste definizioni sono generalizzate per coprire entrambi gli scenari. Il termine processore logico viene usato perché rappresenta la prospettiva del sistema operativo e dell'applicazione dei motori di elaborazione disponibili.
Parallelismo a livello di thread
Ogni thread è un'attività indipendente, poiché ogni thread dispone di proprio stack e di istruzioni proprie. Servizi di dominio di Active Directory possono essere scalati efficacemente su più processori logici essendo multithread e permettendo l'ottimizzazione del numero di thread disponibili. Per altre informazioni sull'ottimizzazione dei thread disponibili, seguire le istruzioni in Come visualizzare e impostare i criteri LDAP in Active Directory usando Ntdsutil.exe.
Parallelismo a livello di dati
Il parallelismo a livello di dati è quando un servizio condivide i dati tra più thread per lo stesso processo e la condivisione di molti thread tra più processi. Il processo di Active Directory Domain Services viene conteggiato da solo come servizio che condivide i dati tra più thread per un singolo processo. Tutte le modifiche apportate ai dati vengono riflesse in tutti i thread in esecuzione in tutti i livelli della cache, ogni core e qualsiasi aggiornamento alla memoria condivisa. Le prestazioni possono peggiorare durante le operazioni di scrittura perché tutte le posizioni di memoria si adattano alle modifiche prima che l'elaborazione delle istruzioni possa continuare.
Considerazioni sulla velocità della CPU e su più core
I processori logici più veloci riducono il tempo necessario per completare il lavoro di un singolo thread. L'aggiunta di più processori logici aumenta il numero di thread che possono essere eseguiti in parallelo. Tuttavia, il ridimensionamento non è lineare a causa della latenza di memoria, della contesa di risorse condivise, della sincronizzazione/blocco, dei percorsi del codice seriale e dell'overhead di pianificazione. Di conseguenza, la scalabilità nei sistemi multi-core non è lineare.
L'utilizzo viene ridimensionato in modo non lineare perché interagiscono più vincoli:
- Un singolo thread eseguibile termina prima su un core più veloce; l'aggiunta di più core inattivi non offre alcun vantaggio, a meno che non siano disponibili operazioni parallele eseguibili.
- Quando un thread si blocca a causa di un mancato accesso alla cache o richiede dati dalla memoria principale, non può progredire fino a quando i dati non vengono restituiti. I core più veloci non eliminano la latenza di memoria; potrebbero attendere più tempo rispetto alla frequenza del ciclo.
- Man mano che la concorrenza (thread eseguibili) aumenta, la sincronizzazione, il traffico di coerenza della cache, la contesa sui lock e l'overhead del programmatore consumano una percentuale più elevata dei cicli totali.
- I sistemi più ampi (più socket/core) amplificano gli effetti di latenza per le operazioni che richiedono l'ordinamento globale (ad esempio, la modifica di dati condivisi, i shootdown TLB, gli interrupt tra processori).
- Alcuni percorsi di codice sono seriali (Legge di Amdahl). Una volta che le regioni parallele sono sature, i core aggiuntivi contribuiscono con rendimenti decrescenti.
Pertanto, l'aggiunta di core o della frequenza della CPU migliora il throughput di Active Directory Domain Services solo quando il carico di lavoro computazionale ha sufficiente lavoro eseguibile, parallelizzabile e non è prevalentemente in attesa a causa di accesso alla memoria, all'archiviazione o per contenzione delle risorse.
In sintesi, le domande su se aggiungere più o più processori diventano altamente soggettivi e devono essere considerate caso per caso. Per Servizi di dominio Active Directory in particolare, le esigenze di elaborazione dipendono da fattori ambientali e possono variare da server a server all'interno di un singolo ambiente. Di conseguenza, le sezioni precedenti di questo articolo non hanno investito molto per eseguire calcoli super precisi. Quando si effettuano decisioni di acquisto basate sul budget, è consigliabile ottimizzare prima l'utilizzo del processore al 40% o a qualsiasi numero richiesto dall'ambiente specifico. Se il sistema non è ottimizzato, non si traggono vantaggio tanto dall'acquisto di più processori.
Note
La legge di Amdahl e la legge di Gustafson sono i concetti rilevanti qui.
Tempo di risposta e impatto dei livelli di attività del sistema
La teoria di accodamento è lo studio matematico delle linee di attesa o delle code. Nell'accodamento della teoria del calcolo, la legge sull'utilizzo è rappresentata dall'equazione t:
U k = B ÷ T
Dove U k è la percentuale di utilizzo, B è la quantità di tempo impiegato per essere occupato e T è il tempo totale trascorso osservando il sistema. In un contesto Microsoft, questo significa il numero di thread a intervalli di 100 nanosecondi (ns) in uno stato In esecuzione diviso per il numero di intervalli di 100-n disponibili nell'intervallo di tempo specificato. Questa è la stessa formula che calcola la percentuale di utilizzo del processore visualizzata in Oggetto processore e PERF_100NSEC_TIMER_INV.
La teoria di accodamento fornisce anche la formula: N = U k ÷ (1 - U k) per stimare il numero di elementi in attesa in base all'utilizzo, dove N è la lunghezza della coda. Il grafico di questa equazione in tutti gli intervalli di utilizzo fornisce le stime seguenti della durata della coda per il caricamento del processore in un determinato carico della CPU.
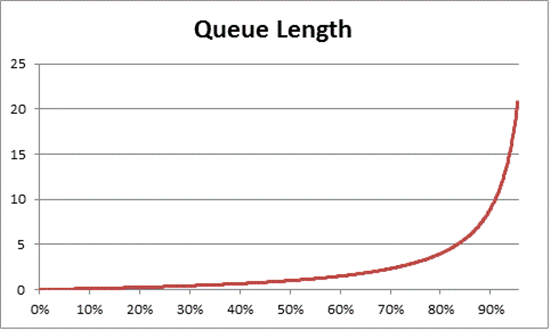
In base a questa stima, è possibile osservare che dopo il 50% del carico della CPU, l'attesa media include in genere un altro elemento nella coda e aumenta rapidamente fino al 70% dell'utilizzo della CPU.
Per comprendere come la teoria dell'accodamento si applica alla distribuzione di Servizi di dominio Active Directory, torniamo alla metafora dell'autostrada usata nella velocità della CPU rispetto alle considerazioni su più core.
I tempi più affollati nel pomeriggio di metà pomeriggio cadrebbero da qualche parte nell'intervallo di capacità del 40% al 70%. C'è abbastanza traffico che la possibilità di scegliere una corsia in cui guidare non è gravemente limitata. Mentre la possibilità di un altro conducente che arriva nel tuo modo è alta, non richiede lo stesso livello di sforzo che avresti bisogno di trovare un divario sicuro tra le altre auto nella corsia come durante l'ora di punta.
Con l'avvicinarsi dell'ora di punta, il sistema stradale si avvicina al 100% di capacità. Cambiare corsie durante l'ora di punta diventa molto impegnativo perché le auto sono così vicine che non hai tanto spazio per manovrare quando cambi corsie. Il comportamento di accodamento spiega il target del 40% della capacità media a lungo termine. Mantenere un utilizzo medio vicino al 40% lascia spazio per brevi picchi (ad esempio, query lente o mal codificate) ed eventi di burst più grandi (ad esempio, l'aumento del mattino dopo un giorno festivo).
L'istruzione precedente considera la percentuale di calcolo del tempo processore come uguale all'equazione della legge sull'utilizzo. Questa versione semplificata è destinata a introdurre il concetto ai nuovi utenti. Tuttavia, per la matematica più avanzata, è possibile usare i riferimenti seguenti come guida:
- Traduzione del PERF_100NSEC_TIMER_INV
- B = Numero di intervalli di 100-ns che il thread inattivo impiega sul processore logico. Modifica nella variabile X nel calcolo PERF_100NSEC_TIMER_INV
- T = numero totale di intervalli di 100-n in un determinato intervallo di tempo. La modifica della variabile Y nel calcolo PERF_100NSEC_TIMER_INV.
- U k = Percentuale di utilizzo del processore logico da parte del thread inattivo o % tempo di inattività.
- Elaborazione dei calcoli:
- U k = 1 – %Tempo del processore
- %Tempo del processore = 1 - U k
- % Tempo processore = 1 – B / T
- %Tempo CPU = 1 – X1 – X0 / Y1 – Y0
Applicazione di questi concetti alla pianificazione della capacità
I calcoli nella sezione precedente probabilmente rendono complesso determinare quanti processori logici siano necessari in un sistema. Di conseguenza, l'approccio al dimensionamento del sistema deve concentrarsi sulla determinazione del massimo utilizzo di destinazione in base al carico corrente, quindi calcolare il numero di processori logici necessari per raggiungere tale destinazione. Inoltre, la stima non deve essere perfettamente esatta. Anche se le velocità del processore logico hanno un impatto significativo sulla sincronizzazione, altre aree possono influire anche sulle prestazioni, ad esempio:
- Efficienza della cache
- Requisiti di coerenza della memoria
- Pianificazione e sincronizzazione dei thread
- Caricamenti client con bilanciamento imperfetto
Poiché la potenza di calcolo è relativamente a basso costo, non vale la pena investire troppo tempo nel calcolo del numero esatto di CPU necessarie.
È anche importante ricordare che la raccomandazione del 40%, in questo caso, non è un requisito obbligatorio. Lo usiamo come un inizio ragionevole per eseguire calcoli. Diversi tipi di utenti di Active Directory richiedono livelli diversi di velocità di risposta. Alcuni ambienti possono avere una media di 80%-90% CPU e comunque soddisfare le aspettative degli utenti se i tempi di attesa delle code non aumentano notevolmente. Considera questo come un'eccezione, convalida con i dati di latenza e monitora attentamente la contesa emergente.
Altre parti del sistema sono più lente della CPU. Ottimizza anche loro. Concentrarsi sull'accesso alla RAM, sull'accesso al disco e sul tempo di risposta alla rete. Per esempio:
Se si aggiungono processori a un sistema in esecuzione con un utilizzo del 90% associato al disco, probabilmente non migliorerà significativamente le prestazioni. Se si esamina in modo più approfondito il sistema, ci sono molti thread che non stanno nemmeno entrare nel processore perché sono in attesa del completamento delle operazioni di I/O.
La risoluzione dei problemi associati a disco può significare che i thread bloccati in precedenza nello stato di attesa si bloccano, creando più concorrenza per il tempo di CPU. Di conseguenza, l'utilizzo di 90% passa a 100%. È necessario ottimizzare entrambi i componenti per ridurre l'utilizzo ai livelli gestibili.
Note
Il
Processor Information(*)\% Processor Utilitycontatore può superare il 100% con sistemi con modalità Turbo. La modalità Turbo consente alla CPU di superare la velocità del processore valutata per brevi periodi. Per altre informazioni, vedere la documentazione e le descrizioni dei contatori dei produttori della CPU.
La discussione sulle considerazioni sull'utilizzo dell'intero sistema comporta anche controller di dominio come guest virtualizzati. Il tempo di risposta e il modo in cui i livelli di attività del sistema influiscono sulle prestazioni si applicano sia all'host che al guest in uno scenario virtualizzato. In un host con un solo guest, un controller di dominio o un sistema ha quasi le stesse prestazioni dell'hardware fisico. L'aggiunta di altri guest agli host aumenta l'utilizzo dell'host sottostante, aumentando anche i tempi di attesa per ottenere l'accesso ai processori. Pertanto, è necessario gestire l'utilizzo del processore logico a livello di host e guest.
Rivisitiamo la metafora dell'autostrada delle sezioni precedenti, solo questa volta stiamo immaginando la macchina virtuale guest come bus express. Gli autobus express, invece degli autobus pubblici o degli autobus scolastici, vanno direttamente alla destinazione del pilota senza fare alcuna sosta.
Si immaginino ora quattro scenari:
- Le ore di punta di un sistema sono come guidare un autobus express a tarda notte. Quando il pilota entra, non ci sono quasi altri passeggeri e la strada è quasi vuota. Poiché l'autobus non deve affrontare il traffico, il viaggio è facile e veloce come se il passeggero avesse raggiunto la destinazione con la propria auto. Tuttavia, il limite di velocità locale può vincolare il tempo di viaggio del pilota.
- Le ore di minore attività quando l'utilizzo della CPU di un sistema è troppo elevato è come una corsa notturna quando la maggior parte delle corsie sulla strada è chiusa. Anche se l'autobus stesso è per lo più vuoto, la strada è ancora congestionata dal traffico a sinistra che si occupa delle corsie limitate. Mentre il pilota è libero di sedersi ovunque vogliano, il loro tempo di viaggio effettivo è determinato dal traffico all'esterno del bus.
- Un sistema con un utilizzo elevato della CPU durante le ore di punta è come un autobus affollato durante l'ora di punta. Non solo il viaggio richiede più tempo, ma l'entrare e scendere dall'autobus è più difficile perché l'autobus è pieno di altri passeggeri. L'aggiunta di più processori logici al sistema guest per tentare di velocizzare i tempi di attesa consiste nel tentare di risolvere il problema del traffico aggiungendo altri autobus. Il problema non è il numero di autobus, ma per quanto tempo il viaggio richiede.
- Un sistema con un utilizzo elevato della CPU durante le ore di minore attività è simile a quello stesso autobus affollato su una strada per lo più vuota di notte. Mentre i passeggeri potrebbero avere problemi a trovare posti o salire e scendere dall'autobus, il viaggio è piuttosto tranquillo una volta che l'autobus ha caricato tutti i suoi passeggeri. Questo scenario è l'unico in cui le prestazioni migliorano aggiungendo più autobus.
In base agli esempi precedenti, è possibile notare che esistono molti scenari tra l'0% e il 100% di utilizzo che hanno vari gradi di impatto sulle prestazioni. Inoltre, l'aggiunta di più processori logici non migliora necessariamente le prestazioni al di fuori di scenari specifici. Dovrebbe essere abbastanza semplice applicare questi principi alla destinazione di utilizzo della CPU consigliata al 40% per gli host e i guest.
Appendice B: Considerazioni relative alle diverse velocità del processore
In Elaborazione si presuppone che il processore sia in esecuzione a 100% velocità di clock durante la raccolta dei dati e che tutti i sistemi sostitutivi abbiano la stessa velocità di elaborazione. Nonostante questi presupposti non siano accurati, in particolare per Windows Server 2008 R2 e versioni successive, in cui il piano di risparmio energia predefinito è bilanciato, questi presupposti continuano a funzionare per stime conservatrici. Anche se i potenziali errori potrebbero aumentare, aumenta solo il margine di sicurezza man mano che aumentano le velocità del processore.
- Ad esempio, in uno scenario che richiede 11,25 CPU, se i processori vengono eseguiti a metà velocità durante la raccolta dei dati, la stima più accurata della domanda sarà di 5,125 ÷ 2.
- È impossibile garantire che la velocità del clock raddoppia la quantità di elaborazione che avviene entro il periodo di tempo registrato. La quantità di tempo che i processori impiegano in attesa di RAM o altri componenti rimangono approssimativamente uguali. Pertanto, i processori più veloci potrebbero impiegare una percentuale maggiore di tempo di inattività durante l'attesa che il sistema recuperi i dati. È consigliabile attenersi al denominatore comune più basso, mantenere le stime conservatrici ed evitare di presupporre un confronto lineare tra velocità del processore che potrebbero rendere i risultati imprecisi.
Se le velocità del processore nell'hardware sostitutivo sono inferiori all'hardware corrente, è consigliabile aumentare proporzionalmente la stima del numero di processori necessari. Si esaminerà, ad esempio, uno scenario in cui si calcola che sono necessari 10 processori per sostenere il carico del sito. I processori correnti vengono eseguiti a 3,3 GHz e i processori che si prevede di sostituirli con vengono eseguiti a 2,6 GHz. La sostituzione solo dei 10 processori originali darebbe una diminuzione del 21% della velocità. Per aumentare la velocità, è necessario ottenere almeno 12 processori invece di 10.
Tuttavia, questa variabilità non modifica gli obiettivi di utilizzo del processore di gestione della capacità. La velocità del clock del processore si regola in modo dinamico in base alla domanda di carico, quindi l'esecuzione del sistema con carichi più elevati fa sì che la CPU passi più tempo in uno stato di velocità di clock superiore. L'obiettivo finale è avere la CPU al 40% di utilizzo in uno stato di velocità di clock del 100% durante le ore lavorative di punta. Qualsiasi riduzione delle prestazioni genera risparmio energetico limitando la velocità della CPU durante le fasce orarie di minore utilizzo.
Note
È possibile disattivare la gestione dell'alimentazione nei processori durante la raccolta dei dati impostando la combinazione per il risparmio di energia su Prestazioni elevate. La disattivazione del risparmio energia offre letture più accurate del consumo di CPU nel server di destinazione.
Per modificare le stime per processori diversi, è consigliabile usare il benchmark SPECint_rate2006 di Standard Performance Evaluation Corporation. Per usare questo benchmark:
Vai al sito web della Standard Performance Evaluation Corporation (SPEC).
Selezionare Risultati.
Immettere CPU2006 e selezionare Cerca.
Nel menu a discesa per Configurazioni disponibili selezionare Tutti i CPU2006 SPEC.
Nel campo Cerca richiesta modulo selezionare Semplice, quindi selezionare Vai!.
In Richiesta semplice immettere i criteri di ricerca per il processore di destinazione. Ad esempio, se si sta cercando un processore E5-2630, nel menu a discesa selezionare Processore, quindi immettere il nome del processore nel campo di ricerca. Al termine, selezionare Esegui recupero semplice.
Cercare il server e la configurazione del processore nei risultati della ricerca. Se il motore di ricerca non restituisce una corrispondenza esatta, cercare la corrispondenza più vicina possibile.
Registrare i valori nelle colonne Result e # Cores .
Determinare il modificatore usando questa equazione:
((Valore del punteggio per-core della piattaforma di destinazione) × (MHz per core della piattaforma di base)) ÷ ((Valore del punteggio per-core della piattaforma di base) × (MHz per core della piattaforma di destinazione))
Ecco ad esempio come trovare il modificatore per un processore E5-2630:
(35,83 × 2.000) ÷ (33,75 × 2.300) = 0,92
Moltiplicare il numero di processori che si stimano necessari per questo modificatore.
Per l'esempio di processore E5-2630, 0,92 × 10,3 = 10,35 processori.
Appendice C: Interazione del sistema operativo con l'archiviazione
I concetti di teoria di accodamento illustrati in Tempo di risposta e il modo in cui i livelli di attività del sistema influisce sulle prestazioni si applicano anche all'archiviazione. È necessario avere familiarità con il modo in cui il sistema operativo gestisce le operazioni di I/O per applicare questi concetti in modo efficace. Nei sistemi operativi Windows il sistema crea una coda che contiene le richieste di I/O per ogni disco fisico. Tuttavia, un disco fisico non è necessariamente un singolo disco. Il sistema operativo può anche registrare un'aggregazione di spindles in un controller di matrice o san come disco fisico. I controller di matrice e le reti SAN possono anche aggregare più dischi in un singolo set di matrici, suddividerlo in più partizioni, quindi usare ogni partizione come disco fisico, come illustrato nell'immagine seguente.

In questa illustrazione, i due spindle vengono speculari e suddivisi in aree logiche per l'archiviazione dei dati, con etichetta Data 1 e Data 2. Il sistema operativo registra ognuna di queste aree logiche come dischi fisici separati.
A questo punto è stato spiegato cosa definisce un disco fisico. I termini seguenti consentono di comprendere meglio le informazioni contenute in questa Appendice.
- Uno spindle è il dispositivo installato fisicamente nel server.
- Una matrice è una raccolta di spindle aggregate dal controller.
- Una partizione di matrice è un partizionamento della matrice aggregata.
- Un numero di unità logica (LUN) è una matrice di dispositivi SCSI connessi a un computer. Questo articolo usa questi termini quando si parla di SAN.
- Un disco include qualsiasi spindle o partizione registrata dal sistema operativo come un singolo disco fisico.
- Una partizione è un partizionamento logico di ciò che il sistema operativo registra come disco fisico.
Considerazioni sull'architettura del sistema operativo
Il sistema operativo crea una coda di I/O FIFO (First In, First In, First Out) per ogni disco registrato. Questi dischi possono essere spindles, matrici o partizioni di matrice. Quando si tratta di come il sistema operativo gestisce le operazioni di I/O, le code più attive, meglio. Quando il sistema operativo serializza la coda FIFO, deve elaborare tutte le richieste di I/O FIFO inviate al sottosistema di archiviazione in ordine di arrivo. Mantenendo una coda di I/O separata per ogni spindle o matrice, il sistema operativo impedisce ai dischi di competere per le stesse risorse di I/O scarse e mantiene l'attività isolata solo per i dischi coinvolti. Tuttavia, Windows Server 2008 ha introdotto un'eccezione sotto forma di definizione delle priorità di I/O. Le applicazioni progettate per l'uso di I/O con priorità bassa vengono spostate nella parte posteriore della coda, indipendentemente dal momento in cui il sistema operativo le ha ricevute. Le applicazioni non codificate per l'uso dell'impostazione con priorità bassa vengono invece impostate sulla priorità normale.
Introduzione a semplici sottosistemi di archiviazione
In questa sezione vengono descritti i semplici sottosistemi di archiviazione. Si inizierà con un esempio: un singolo disco rigido all'interno di un computer. Se si suddivide questo sistema nei componenti principali del sottosistema di archiviazione, ecco cosa si ottiene:
- Un HD Ultra Fast SCSI ultra veloce di 10.000 RPM (Ultra Fast SCSI ha una velocità di trasferimento di 20MBps)
- Un bus SCSI (cavo)
- Una scheda SCSI Ultra Fast
- Bus PCI a 32 bit e 33 MHz
Note
Questo esempio non riflette la cache del disco in cui il sistema mantiene in genere i dati di un cilindro. In questo caso, il primo I/O richiede 10 ms e il disco legge l'intero cilindro. Tutte le altre operazioni di I/O sequenziali vengono soddisfatte dalla cache. Di conseguenza, le cache su disco potrebbero migliorare le prestazioni dell'I/O sequenziale.
Dopo aver identificato i componenti, è possibile iniziare a ottenere un'idea della quantità di dati che il sistema può trasmettere e della quantità di I/O che può gestire. La quantità di I/O e la quantità di dati che possono transitare il sistema sono correlate l'una all'altra, ma non allo stesso valore. Questa correlazione dipende dalle dimensioni del blocco e dal fatto che l'I/O del disco sia casuale o sequenziale. Il sistema scrive tutti i dati nel disco come blocco, ma applicazioni diverse possono usare dimensioni di blocco diverse.
A questo punto, analizziamo questi elementi in base al componente.
Tempi di accesso del disco rigido
Il disco rigido medio di 10.000 RPM ha un tempo di ricerca di 7 ms e un tempo di accesso di 3 ms. Il tempo di ricerca è la quantità media di tempo che richiede la testa di lettura o scrittura per spostarsi in una posizione sul piatto. Il tempo di accesso è la quantità media di tempo impiegato per la lettura o la scrittura dei dati sul disco quando si trova nella posizione corretta. Pertanto, il tempo medio per la lettura di un blocco univoco di dati in un HD da 10.000 RPM include sia i tempi di ricerca che di accesso per un totale di circa 10 ms o 0,010 secondi, per blocco di dati.
Quando ogni accesso al disco richiede lo spostamento della testa in una nuova posizione sul disco, il comportamento di lettura o scrittura viene chiamato casuale. Quando tutte le operazioni di I/O sono casuali, un HD da 10.000 RPM può gestire circa 100 operazioni di I/O al secondo (IOPS).
Quando tutti gli I/O si verificano da settori adiacenti sul disco rigido, lo chiamiamo I/O sequenziale. L'I/O sequenziale non aggiunge tempo di ricerca aggiuntivo. Al termine del primo I/O, la testa di lettura/scrittura è già posizionata nel blocco di dati successivo. Ad esempio, un HD da 10.000 RPM è in grado di gestire circa 333 I/O al secondo, in base all'equazione seguente:
1000 ms al secondo ÷ 3 ms per I/O
Finora, la velocità di trasferimento del disco rigido non è stata rilevante per il nostro esempio. Indipendentemente dalle dimensioni del disco rigido, la quantità effettiva di operazioni di I/O al secondo che può essere gestita da 10.000 RPM HD è sempre di circa 100 operazioni di I/O sequenziali o 300. Man mano che le dimensioni dei blocchi cambiano in base all'applicazione che scrive nell'unità, cambia anche la quantità di dati estratti per I/O. Ad esempio, se la dimensione del blocco è 8 KB, 100 operazioni di I/O lette o scritte nel disco rigido un totale di 800 KB. Tuttavia, se la dimensione del blocco è 32 KB, 100 I/O leggerà o scriverà 3.200 KB (3,2 MB) sul disco rigido. Se la velocità di trasferimento SCSI supera la quantità totale di dati trasferiti, il recupero di una velocità di trasferimento più veloce non cambia nulla. Per altre informazioni, vedere le tabelle seguenti:
| Description | 7.200 RPM 9 ms tempo di ricerca, 4 ms tempo di accesso | 10.000 RPM 7 ms tempo di ricerca, tempo di accesso 3 ms | 15.000 RPM, tempo di ricerca: 4 ms, tempo di accesso: 2 ms |
|---|---|---|---|
| I/O casuale | 80 | 100 | 150 |
| I/O sequenziale | 250 | 300 | 500 |
| Unità da 10.000 RPM | Dimensione del blocco di 8 KB (Active Directory Jet) |
|---|---|
| I/O casuale | 800 KB/s |
| I/O sequenziale | 2400 KB/s |
Backplane SCSI
Il modo in cui il backplane SCSI, che in questo scenario di esempio è il cavo della barra multifunzione, influisce sulla velocità effettiva del sottosistema di archiviazione dipende dalle dimensioni del blocco. Quanto I/O può gestire l'autobus se l'I/O è in blocchi di 8 KB? In questo scenario, il bus SCSI è 20MBps o 20480KB/s. 20480 KB/s diviso per blocchi da 8 KB produce un massimo di circa 2500 operazioni di I/O al secondo supportate dal bus SCSI.
Note
Le figure nella tabella seguente rappresentano uno scenario di esempio. La maggior parte dei dispositivi di archiviazione collegati attualmente usa PCI Express, che offre una velocità effettiva più elevata.
| I/O supportati dal bus SCSI per dimensione del blocco | Dimensione del blocco di 2 KB | Dimensione blocco di 8 KB (AD Jet) (SQL Server 7.0/SQL Server 2000) |
|---|---|---|
| 20MBps | 10,000 | 2,500 |
| 40MBps | 20,000 | 5,000 |
| 128MBps | 65,536 | 16,384 |
| 320MBps | 160,000 | 40,000 |
Come illustrato nella tabella precedente, nello scenario di esempio, il bus non è mai un collo di bottiglia perché il valore massimo di spindle è 100 I/O, al di sotto di una delle soglie elencate.
Note
In questo scenario si presuppone che il bus SCSI sia efficiente al 100%.
Scheda SCSI
Per determinare la quantità di I/O che il sistema può gestire, è necessario controllare le specifiche del produttore. L'indirizzamento delle richieste di I/O al dispositivo appropriato richiede potenza di elaborazione, quindi la quantità di I/O che il sistema può gestire dipende dall'adattatore SCSI o dal processore del controller di matrice.
In questo scenario di esempio si presuppone che il sistema possa gestire 1.000 operazioni di I/O.
Il bus PCI
Il bus PCI è un componente trascurato. In questo scenario di esempio, il bus PCI non è il collo di bottiglia. Tuttavia, man mano che i sistemi aumentano, potrebbe diventare un collo di bottiglia in futuro.
È possibile vedere quanto un bus PCI può trasferire i dati nello scenario di esempio usando questa equazione:
32 bit ÷ 8 bit per byte × 33 MHz = 133MBps
Pertanto, è possibile presupporre che un bus PCI a 32 bit che opera a 33 Mhz può trasferire 133MBps di dati.
Note
Il risultato di questa equazione rappresenta il limite teorico dei dati trasferiti. In realtà, la maggior parte dei sistemi raggiunge solo circa il 50% del limite massimo. In alcuni scenari di burst, il sistema può raggiungere il 75% del limite per brevi periodi.
Un bus PCI a 66 MHz a 64 bit può supportare un massimo teorico di 528MBps in base a questa equazione:
64 bit ÷ 8 bit per byte × 66Mhz = 528MBps
L'aggiunta di un altro dispositivo ,ad esempio una scheda di rete o un secondo controller SCSI, riduce la larghezza di banda disponibile per il sistema. Tutti i dispositivi nel bus condividono tale larghezza di banda e ogni nuovo dispositivo compete per risorse di elaborazione limitate.
Analisi dei sottosistemi di archiviazione per trovare colli di bottiglia
In questo scenario, lo spindle è il fattore di limitazione della quantità di I/O che è possibile richiedere. Di conseguenza, questo collo di bottiglia limita anche la quantità di dati che il sistema può trasmettere. Poiché l'esempio è uno scenario di Active Directory Domain Services, la quantità di dati trasmessi è di 100 operazioni di I/O casuali al secondo in incrementi di 8 KB, per un totale di 800 KB al secondo quando si accede al database Jet. Per confronto, uno spindle dedicato solo ai file di log può recapitare fino a 300 I/O sequenziali 8 KB al secondo. Uguale a 2.400 KB (2,4 MB) al secondo.
Ora che sono stati analizzati i componenti della configurazione di esempio, si esaminerà una tabella che illustra dove possono verificarsi colli di bottiglia durante l'aggiunta e la modifica dei componenti nel sottosistema di archiviazione.
| Notes | Analisi dei colli di bottiglia | Disk | Bus | Adapter | Bus PCI |
|---|---|---|---|---|---|
| Configurazione del controller di dominio dopo l'aggiunta di un secondo disco. La configurazione del disco costituisce un collo di bottiglia a 800 KB/s. | Aggiungere 1 disco (totale=2) L'I/O è casuale Blocco di dimensione 4 KB 10.000 RPM HD |
200 I/O in totale 800 KB/s totali |
|||
| Dopo aver aggiunto sette dischi, la configurazione del disco rappresenta ancora il collo di bottiglia a 3200 KB/s. | Aggiungere 7 dischi (Totale=8) L'I/O è casuale Dimensione del blocco di 4 KB 10.000 RPM HD |
800 I/O in totale. Totale di 3200 KB/sec |
|||
| Dopo aver modificato l'I/O in sequenza, la scheda di rete diventa il collo di bottiglia perché è limitato a 1000 operazioni di I/O al secondo. | Aggiungere 7 dischi (totale=8) L'I/O è sequenziale Dimensione blocco di 4 KB 10.000 RPM HD |
2.400 I/O sec in lettura/scrittura su disco, controller limitato a 1.000 IOPS | |||
| Dopo aver sostituito la scheda di rete con una scheda SCSI che supporta 10.000 IOPS, il collo di bottiglia ritorna alla configurazione del disco. | Aggiungere 7 dischi (totale=8) L'I/O è casuale Dimensione blocco di 4KB 10.000 RPM HD Aggiornamento dell'adattatore SCSI (ora supporta 10.000 I/O) |
800 I/O in totale. Totale di 3.200 KB/sec |
|||
| Dopo aver aumentato le dimensioni del blocco a 32 KB, il bus diventa il collo di bottiglia perché supporta solo 20 MBps. | Aggiungere 7 dischi (totale=8) L'I/O è casuale Dimensione blocco 32 KB 10.000 RPM HD |
800 I/O in totale. È possibile leggere/scrivere su disco 25.600 KB/s (25MBps). Il bus supporta solo 20MBps |
|||
| Dopo aver aggiornato il bus e aggiunto altri dischi, il disco rimane il collo di bottiglia. | Aggiungere 13 dischi (totale=14) Aggiungere un secondo adattatore SCSI con 14 dischi L'I/O è casuale Dimensione del blocco 4 KB 10.000 RPM HD Aggiornare a Bus SCSI 320MBps |
2800 I/O 11.200 KB/s (10,9MBps) |
|||
| Dopo aver modificato l'I/O in sequenziale, il disco rimane il collo di bottiglia. | Aggiungere 13 dischi (totale=14) Aggiungere una seconda scheda SCSI con 14 dischi L'I/O è sequenziale Dimensione del blocco da 4 KB 10.000 RPM HD Aggiorna al bus SCSI 320MBps |
8 400 I/Os 33.600 KB\s (32,8 MB\s) |
|||
| Dopo aver aggiunto dischi rigidi più veloci, il disco rimane il collo di bottiglia. | Aggiungere 13 dischi (totale=14) Aggiungere un secondo adattatore SCSI con 14 dischi L'I/O è sequenziale Dimensioni blocco da 4 KB 15.000 RPM HD Eseguire l'aggiornamento al bus SCSI 320 MB/s |
14.000 I/O 56.000 KB/s (54,7MBps) |
|||
| Dopo aver aumentato le dimensioni del blocco a 32 KB, il bus PCI diventa il collo di bottiglia. | Aggiungere 13 dischi (totale=14) Aggiungere un secondo adattatore SCSI con 14 dischi L'I/O è sequenziale Dimensioni blocco da 32 KB 15.000 RPM HD Esegui l'aggiornamento al bus SCSI 320 MB/s |
14.000 I/O 448.000 KB/s (437MBps) è il limite di lettura/scrittura per lo spindle. Il bus PCI supporta un massimo teorico di 133MBps (75% efficiente al meglio). |
Introduzione a RAID
Quando si introduce un controller di matrice al sottosistema di archiviazione, non cambia notevolmente la sua natura. Il controller di matrice sostituisce solo l'adattatore SCSI nei calcoli. Tuttavia, il costo di lettura e scrittura dei dati nel disco quando si usano i vari livelli di matrice cambia.
In RAID 0, la scrittura di striping dei dati in tutti i dischi nel set RAID. Durante un'operazione di lettura o scrittura, il sistema esegue il pull dei dati da o li inserisce in ogni disco, aumentando la quantità di dati che il sistema può trasmettere durante questo periodo di tempo specifico. Pertanto, in questo esempio in cui si usano dischi da 10.000 RPM, utilizzando RAID 0 si possono eseguire 100 operazioni di I/O. La quantità totale di I/O supportata dal sistema è N mandrini moltiplicato per 100 I/O al secondo per mandrino, o N mandrini × 100 I/O al secondo per mandrino.

In RAID 1, il sistema esegue il mirror o duplica i dati in una coppia di spindle per la ridondanza. Quando il sistema esegue un'operazione di I/O di lettura, può leggere i dati da entrambi gli spindle nel set. Questo mirroring rende disponibile la capacità di I/O per entrambi i dischi durante un'operazione di lettura. Tuttavia, RAID 1 non offre alcun vantaggio sulle prestazioni delle operazioni di scrittura, perché il sistema deve anche eseguire il mirroring dei dati scritti sulla coppia di spindle. Anche se il mirroring non rende più lunghe le operazioni di scrittura, impedisce al sistema di eseguire più operazioni di lettura contemporaneamente. Pertanto, ogni operazione di I/O di scrittura costa due operazioni di I/O di lettura.
L'equazione seguente calcola il numero di operazioni di I/O in questo scenario:
Lettura di I/O + 2 × Scrittura di I/O = Totale di I/O disponibile consumato
Quando si conosce il rapporto tra letture e scritture e il numero di spindle nella distribuzione, è possibile usare questa equazione per calcolare la quantità di I/O che la matrice può supportare:
Operazioni di I/O al secondo massimo per disco × 2 dischi × [(% letture + % scritture) ÷ (% letture + 2 × scritture%)] = Operazioni di I/O al secondo totali
Uno scenario che usa RAID 1 e RAID 0 si comporta esattamente come RAID 1 nel costo di lettura e scrittura delle operazioni. Tuttavia, l'I/O viene ora eseguito in striping su ciascun set di mirroring. Ciò significa che l'equazione cambia in:
Numero massimo di operazioni di I/O al secondo per spindle × 2 spindles × [(% letture + % scritture) ÷ ( letture% + ×2 scritture%)] = I/O totale
In un insieme RAID 1, quando si esegue lo striping di un numero N di insiemi RAID 1, l'I/O totale che la matrice può elaborare diventa N × I/O per insieme RAID 1.
N × {Numero massimo di operazioni di I/O al secondo per spindle × 2 spindle × [(% letture + % scritture) ÷ ( letture% + 2 × scritture%)]} = Totale operazioni di I/O al secondo
A volte chiamiamo RAID 5 N + 1 RAID perché il sistema esegue lo striping dei dati tra n spindle e scrive informazioni sulla parità nello spindle + 1 . Tuttavia, RAID 5 usa più risorse quando si esegue un I/O di scrittura rispetto a RAID 1 o RAID 1 + 0. RAID 5 esegue il processo seguente ogni volta che il sistema operativo invia un I/O di scrittura alla matrice:
- Leggere i dati precedenti.
- Leggete la vecchia parità.
- Scrivere i nuovi dati.
- Scrivere la nuova parità.
Ogni richiesta di I/O di scrittura inviata dal sistema operativo al controller di matrice richiede il completamento di quattro operazioni di I/O. Di conseguenza, le richieste di scrittura RAID N + 1 richiedono quattro volte di più del tempo impiegato da un'I/O di lettura per completarsi. In altre parole, per determinare il numero di richieste di I/O dal sistema operativo si traduce nel numero di richieste ottenute dagli spindle, usare questa equazione:
Lettura I/O + 4 × Scrittura I/O = Totale I/O
Per RAID 1, dopo aver appreso il rapporto di lettura/scrittura e il numero di spindle, è possibile usare l'equazione seguente per stimare il totale di I/O supportato per la matrice:
Operazioni di I/O al secondo per spindle × (spindles - 1) × [(% letture + ) ÷ ( letture% + 4 × scritture%)] = Operazioni di I/O al secondo totali
Note
Il risultato dell'equazione precedente non include l'unità persa alla parità.
Introduzione alle reti SAN
Quando si introduce una rete SAN (Storage Area Network) nell'ambiente, non influisce sui principi di pianificazione descritti nelle sezioni precedenti. Tuttavia, è necessario tenere conto che il san può modificare il comportamento di I/O per tutti i sistemi connessi. Una SAN aumenta la ridondanza rispetto all'archiviazione interna o all'archiviazione collegata direttamente. È comunque necessario pianificare la tolleranza di errore. Si supponga che uno o più percorsi, controller o scaffali possano fallire senza superare l'utilizzo obiettivo del resto. Inoltre, man mano che si introducono altri componenti al sistema, è anche necessario considerare queste nuove parti nei calcoli.
A questo punto, suddividere una san nei relativi componenti:
- Disco rigido SCSI o Fibre Channel
- Backplane del canale dell'unità di archiviazione
- Le unità di archiviazione stesse
- Modulo controller di archiviazione
- Uno o più commutatori SAN
- Uno o più adattatori bus host (HBA)
- Bus di interconnessione dei componenti periferici (PCI)
Quando si progetta un sistema per la ridondanza, è necessario includere componenti aggiuntivi per garantire che il sistema continui a funzionare durante uno scenario di crisi in cui uno o più componenti originali smettono di funzionare. Tuttavia, quando si pianifica la capacità, è necessario escludere i componenti ridondanti dalle risorse disponibili per ottenere una stima accurata della capacità di base del sistema, in quanto questi componenti non vengono in genere online a meno che non si verifichi un'emergenza. Ad esempio, se la rete SAN ha due moduli controller, è necessario usarne una solo quando si calcola la velocità effettiva totale di I/O disponibile, perché l'altra non verrà attivata a meno che il modulo originale non si arresti. Non è inoltre consigliabile portare il commutatore SAN ridondante, l'unità di archiviazione o gli spindle nei calcoli di I/O.
Inoltre, poiché la pianificazione della capacità considera solo i periodi di picco di utilizzo, non è consigliabile considerare i componenti ridondanti nelle risorse disponibili. Il picco di utilizzo non deve superare l'80% di saturazione del sistema per supportare picchi o altri comportamenti insoliti del sistema.
Quando si analizza il comportamento del disco rigido SCSI o Fibre Channel, è consigliabile analizzarlo in base ai principi descritti nelle sezioni precedenti. Nonostante ogni protocollo abbia i propri vantaggi e svantaggi, la cosa principale che limita le prestazioni per ogni disco è le limitazioni meccaniche del disco rigido.
Quando si analizza il canale nell'unità di archiviazione, è consigliabile adottare lo stesso approccio, quando si calcola il numero di risorse disponibili nel bus SCSI: dividere la larghezza di banda per le dimensioni del blocco. Ad esempio, se l'unità di archiviazione ha sei canali che supportano una velocità di trasferimento massima di 20MBps, la quantità totale di I/O disponibili e il trasferimento dati è 100MBps. Sei canali a 20MBps danno ognuno un valore teorico di 120MBps. La velocità effettiva pianificata è massima a 100MBps (progettazione N+1). Se un canale ha esito negativo, i cinque rimanenti (5 × 20MBps) forniscono comunque i 100MBps necessari. In questo esempio si presuppone anche che il sistema distribuisca in modo uniforme il carico e la tolleranza di errore in tutti i canali.
Se è possibile trasformare l'esempio precedente in un profilo di I/O dipende dal comportamento dell'applicazione. Per I/O Jet di Active Directory, il valore massimo sarà di circa 12.500 I/O al secondo o 100MBps ÷ 8 KB per I/O.
Per comprendere la velocità effettiva supportata dai moduli controller, è anche necessario ottenere le specifiche del produttore. In questo esempio, la SAN dispone di due moduli controller che supportano 7.500 I/O ciascuno. Se non si usa la ridondanza, la velocità effettiva totale del sistema sarà di 15.000 operazioni di I/O al secondo. Tuttavia, in uno scenario in cui è necessaria la ridondanza, è necessario calcolare la velocità effettiva massima in base ai limiti di un solo controller, ovvero 7.500 operazioni di I/O al secondo. Supponendo che le dimensioni del blocco siano pari a 4 KB, questa soglia è ben inferiore al massimo di 12.500 operazioni di I/O al secondo che i canali di archiviazione possono supportare ed è quindi il collo di bottiglia nell'analisi. Tuttavia, ai fini della pianificazione, il numero massimo di I/O desiderato da pianificare è 10.400 I/O.
Quando i dati lasciano il modulo controller, trasmette una connessione Fibre Channel valutata a 1GBps o 128MBps. Poiché questa quantità supera la larghezza di banda totale di 100MBps in tutti i canali, non creerà colli di bottiglia nel sistema. Solo uno dei due percorsi Fibre Channel trasporta il traffico durante il normale funzionamento; l'altro percorso è riservato per la ridondanza. Se il percorso attivo ha esito negativo, il percorso di standby assume il controllo. Ha una capacità sufficiente per gestire il caricamento completo dei dati.
I dati transitano quindi un commutatore SAN sulla sua strada verso il server. L'opzione limita la quantità di operazioni di I/O che può gestire perché deve elaborare la richiesta in ingresso e quindi inoltrarla alla porta appropriata. Tuttavia, è possibile sapere solo qual è il limite di commutazione se si esaminano le specifiche del produttore. Ad esempio, se il sistema dispone di due commutatori e ogni commutatore può gestire 10.000 operazioni di I/O al secondo, la velocità effettiva totale è di 20.000 operazioni di I/O al secondo. In base alle regole di tolleranza di errore, se un commutatore smette di funzionare, la velocità effettiva totale del sistema è pari a 10.000 operazioni di I/O al secondo. Pertanto, durante le circostanze normali, non è consigliabile usare più dell'80% o 8.000 operazioni di I/O.
Infine, l'HBA installata nel server limita anche la quantità di I/O che può gestire. Installare più HBA per la ridondanza. Quando si calcola la capacità, escludere l'HBA ridondante. Pianificare come se un HBA sia offline (N - 1) e le dimensioni totali di I/O disponibili su uno o più HBA attivi rimanenti.
Considerazioni sulla memorizzazione nella cache
Le cache sono uno dei componenti che possono influire significativamente sulle prestazioni complessive ovunque nel sistema di archiviazione. Tuttavia, un'analisi dettagliata degli algoritmi di memorizzazione nella cache esula dall'ambito di questo articolo. Ecco invece un rapido elenco di elementi che è necessario conoscere sulla memorizzazione nella cache nei sottosistemi del disco.
- La memorizzazione nella cache migliora le operazioni di I/O sequenziali sostenute perché memorizza nel buffer molte operazioni di scrittura più piccole in blocchi di I/O più grandi. Le operazioni vengono inoltre scaricate nella memoria in pochi blocchi di grandi dimensioni anziché in molti blocchi di piccole dimensioni. Questa ottimizzazione riduce le operazioni di I/O casuali e sequenziali totali, rendendo disponibili più risorse per altre operazioni di I/O.
- La memorizzazione nella cache non migliora la velocità effettiva di I/O di scrittura sostenuta nel sottosistema di archiviazione perché memorizza solo i buffer di scrittura fino a quando non sono disponibili spindle per il commit dei dati. Quando tutte le operazioni di I/O disponibili dagli spindle sono sature dai dati per lunghi periodi di tempo, la cache alla fine si riempie. Per svuotare la cache, è necessario fornire un numero sufficiente di operazioni di I/O per cancellare la cache fornendo spindle aggiuntive o dando tempo sufficiente tra i burst per il sistema.
- Le cache più grandi consentono di memorizzare più dati nel buffer, il che significa che la cache può gestire periodi di saturazione più lunghi.
- Nei sottosistemi di archiviazione tipici, il sistema operativo ha migliorato le prestazioni di scrittura con le cache, perché il sistema deve solo scrivere i dati nella cache. Tuttavia, quando il supporto sottostante è saturo con le operazioni di I/O, la cache riempie e le prestazioni di scrittura tornano alla velocità normale del disco.
- Quando si memorizzano nella cache le operazioni di I/O in lettura, la cache è più utile quando si archiviano i dati in sequenza sulla scrivania e si consente la lettura della cache. La lettura anticipata è quando la cache può passare immediatamente al settore successivo come se il prossimo settore contenga i dati richiesti dal sistema.
- Quando l'I/O di lettura è casuale, la memorizzazione nella cache nel controller dell'unità non aumenta la quantità di dati che il disco può leggere. Se la dimensione della cache basata sul sistema operativo o sull'applicazione è superiore alla dimensione della cache basata su hardware, i tentativi di migliorare la velocità di lettura del disco non cambiano nulla.
- In Active Directory la cache è limitata solo dalla quantità di RAM che il sistema contiene.
Considerazioni sull'unità SSD
Le unità SSD (Solid State Drive) sono fondamentalmente diverse rispetto ai dischi rigidi basati su spindle. Le unità SSD possono gestire volumi più elevati di I/O con una latenza inferiore. Anche se le unità SSD possono essere costose in base al costo per gigabyte, sono a basso costo per I/O. La pianificazione della capacità con unità SSD pone ancora le stesse domande di base degli spindles: quante operazioni di I/O al secondo possono gestire e qual è la latenza di tali operazioni di I/O al secondo?
Ecco alcuni aspetti da considerare quando si pianificano unità SSD:
- Le operazioni di I/O al secondo e la latenza sono soggette alle progettazioni dei produttori. In alcuni casi, alcune progettazioni SSD possono comportare prestazioni peggiori rispetto alle tecnologie basate su spindle. Convalidare le specifiche del fornitore per ogni modello SSD o spindle; le prestazioni e la latenza variano in base alla progettazione. Non trattare tutte le unità SSD o tutti i dischi rotanti come uguali. Confrontare IOPS, latenza, durata, comportamento della profondità della coda e funzionalità del firmware per modello.
- I tipi di operazioni di I/O al secondo possono avere valori diversi a seconda che siano letti o scritti. I servizi di Active Directory Domain Services sono prevalentemente basati sulla lettura e pertanto sono meno interessati dalla tecnologia di scrittura usata rispetto ad altri scenari dell'applicazione.
- La resistenza alla scrittura è il presupposto che le celle SSD abbiano una durata limitata e alla fine si esauriscono dopo averle usate molto. Per le unità di database, un profilo di I/O di lettura prevalentemente estende la resistenza di scrittura delle celle fino al punto in cui non è necessario preoccuparsi della resistenza alla scrittura.
Summary
La contesa di archiviazione condivisa si verifica quando più carichi di lavoro indipendenti competono per operazioni di I/O limitate al secondo (IOPS) e larghezza di banda sullo stesso supporto o interconnessione sottostante. Le origini di contese tipiche includono:
- Diversi server che usano lo stesso LUN SAN
- Più macchine virtuali i cui dischi virtuali risiedono nello stesso volume NAS
- Host che accedono a destinazioni iSCSI comuni su un'infrastruttura condivisa
Quando un carico di lavoro genera un numero elevato di operazioni di I/O elevate, ad esempio backup, analisi antivirus complete, enumerazioni di directory di grandi dimensioni o attività di esportazione o importazione in blocco, la latenza media e finale per le operazioni di lettura e scrittura aumenta per tutti i consumer di tale risorsa condivisa. La latenza elevata riduce direttamente la reattività di Active Directory Domain Services se NTDS.dit o le operazioni di I/O del log devono attendere nelle code dei dispositivi.
Flusso di lavoro di correzione consigliato:
it-IT: Misura: raccogliere
LogicalDisk(<NTDS Database Drive>)\Avg Disk sec/Read,Avg Disk sec/Write,Reads/sec,Writes/sece statistiche dell'array di archiviazione (profondità della coda, utilizzo del controller) a intervalli di 15-60 minuti che coprono le finestre di picco e manutenzione.Attributo: identificare il carico di lavoro che causa picchi di latenza (correlazione con finestre di backup, analisi antivirus, processi batch o attività adiacenti della macchina virtuale). Usare metriche per‑LUN / per‑VM, dove disponibili.
Classificare il tipo di problema:
- Saturazione della capacità (IOPS o throughput costantemente in prossimità delle specifiche del dispositivo/controller e latenza in aumento).
- Interferenza burst (brevi attività ad alta intensità che aumentano la latenza di coda ma non l'utilizzo medio).
- Punto di scelta dell'infrastruttura (HBA sovrascritto, commutatore, failover del percorso che riduce le corsie disponibili, driver/firmware obsoleto, criteri multipath non allineati).
Agire:
- Ribilancia o isola carichi di lavoro pesanti su LUN, volumi o livelli di archiviazione separati.
- Sfalsare o riprogrammare i backup, le analisi antivirus complete e la deframmentazione al di fuori dei periodi di autenticazione/query di picco di Active Directory Domain Services.
- Aggiungere o aggiornare i componenti di archiviazione quando l'utilizzo prolungato rimane elevato.
- Verificare che i driver/firmware e il software multipath siano aggiornati e configurati correttamente.
- Dimensionare correttamente la RAM in modo che i dati con accesso frequente risiedano in memoria, riducendo la pressione di lettura sulla memoria di archiviazione.
Convalida: verificare che la latenza post-modifica torni alla destinazione (ad esempio, 2-6 ms SSD/NVMe, 4-12 ms spindle) e che la profondità massima della coda rimanga entro limiti accettabili.
Potenziali punti di choke che simulano o esacerbato la contesa di archiviazione includono commutatori sovrascritti o schede bus host che condividono corsie.
Controllare e escludere questi dischi prima di aggiungere altri dischi o spostarsi su supporti più veloci.
Associare sempre i dati di latenza con la lunghezza della coda e l'utilizzo del dispositivo/controller per determinare se ottimizzare, riprogrammare o aumentare il numero di istanze.
Criteri chiave di successo:
- Mantenuti
Avg Disk sec/ReadeAvg Disk sec/Writeall'interno della fascia di latenza di destinazione durante il picco del carico di Active Directory Domain Services. - Non ci sono periodi prolungati in cui l'IOPS si appiattisce e la latenza aumenta. Se osservato questo potrebbe indicare la saturazione.
- Le attività di manutenzione pesante vengono eseguite durante le finestre di manutenzione definite senza spingere la latenza di produzione al di sopra delle soglie.
Se non si raggiungono gli obiettivi dopo la pianificazione e le modifiche alla configurazione, passare all'espansione della capacità o alla migrazione a livelli di storage ad alte prestazioni.
Appendice D: Risoluzione dei problemi di archiviazione in ambienti in cui più RAM non è un'opzione
Molte raccomandazioni di archiviazione prima dell'archiviazione virtualizzata hanno servito due scopi:
- Isolamento di I/O per impedire problemi di prestazioni nello spindle del sistema operativo di influire sulle prestazioni per i profili di database e I/O.
- Sfruttando il miglioramento delle prestazioni, i dischi rigidi e le cache basati su spindle possono offrire al sistema quando vengono usati con i file di log sequenziali di I/O di Servizi di dominio Active Directory. L'isolamento di operazioni di I/O sequenziali in un'unità fisica separata può anche aumentare la velocità effettiva.
Con le nuove opzioni di archiviazione, molti presupposti fondamentali dietro le raccomandazioni precedenti per l'archiviazione non sono più vere. Scenari di archiviazione virtualizzati, ad esempio iSCSI, SAN, NAS e file di immagine del disco virtuale, spesso condividono supporti di archiviazione sottostanti tra più host. L'archiviazione condivisa nega i presupposti che è necessario isolare le operazioni di I/O e ottimizzare le operazioni di I/O sequenziali. Ora altri host che accedono ai supporti condivisi possono ridurre la velocità di risposta al controller di dominio.
Quando si pianifica la capacità per le prestazioni di archiviazione, tenere presente quanto segue:
- Stato cache a freddo
- Stato cache ad accesso frequente
- Backup e ripristino
Lo stato della cache a freddo è quando si riavvia inizialmente il controller di dominio o si riavvia il servizio Active Directory, quindi non sono presenti dati di Active Directory nella RAM. Uno stato di cache calda è una condizione in cui il controller di dominio opera in uno stato costante e ha memorizzato il database nella cache. In termini di progettazione delle prestazioni, il riscaldamento di una cache a freddo è come uno sprint, mentre l'esecuzione di un server con una cache completamente riscaldata è come una maratona. La definizione di questi stati e i diversi profili di prestazioni che determinano è importante, perché è necessario considerarli entrambi durante la stima della capacità. Ad esempio, solo perché la RAM è sufficiente per memorizzare nella cache l'intero database durante uno stato della cache ad accesso frequente non consente di ottimizzare le prestazioni durante lo stato della cache a freddo.
Per entrambi gli scenari di cache, la cosa più importante è il modo in cui l'archiviazione veloce può spostare i dati da disco a memoria. Quando si riscalda la cache, le prestazioni nel tempo migliorano man mano che le query riutilizzano i dati, aumenta la frequenza di riscontri della cache e la frequenza di passaggio al disco per recuperare i dati diminuisce. Di conseguenza, anche le prestazioni negative influiscono sulla necessità di passare al disco. Eventuali riduzioni delle prestazioni sono temporanee e in genere si allontanano quando la cache raggiunge lo stato di riscaldamento e le dimensioni massime consentite dal sistema.
È possibile misurare la velocità con cui il sistema può ottenere i dati dal disco misurando le operazioni di I/O al secondo disponibili in Active Directory. Il numero di operazioni di I/O al secondo disponibili è soggetto anche al numero di operazioni di I/O al secondo disponibili nell'archiviazione sottostante. È anche consigliabile pianificare alcuni stati eccezionali, ad esempio:
- Riscaldamento della cache dopo un riavvio
- Operazioni di backup
- Operazioni di ripristino
Considera questi come stati eccezionali. Eseguirli durante le ore di minore attività. La durata e l'impatto dipendono dal carico corrente del controller di dominio, quindi non viene applicata alcuna regola di ridimensionamento universale oltre la pianificazione al di fuori dei periodi di picco.
Nella maggior parte degli scenari, Servizi di dominio Active Directory è prevalentemente di I/O in lettura con un rapporto tra il 90% di lettura e il 10% di scrittura. L'I/O di lettura è il collo di bottiglia tipico per l'esperienza utente, mentre l'I/O di scrittura è il collo di bottiglia che degrada le prestazioni di scrittura. Le cache tendono a offrire un vantaggio minimo per la lettura di I/O perché le operazioni di I/O per il NTDS.dit file sono principalmente casuali. Pertanto, la priorità principale consiste nel configurare correttamente l'archiviazione del profilo di I/O di lettura.
In condizioni operative normali, l'obiettivo di pianificazione dell'archiviazione è ridurre al minimo i tempi di attesa per il ripristino delle richieste da Servizi di dominio Active Directory al disco. Il numero di operazioni di I/O in sospeso e in sospeso deve essere minore o uguale al numero di percorsi nel disco. Per gli scenari di monitoraggio delle prestazioni, in genere è consigliabile che il LogicalDisk((<NTDS Database Drive>))\Avg Disk sec/Read contatore sia inferiore a 20 ms. Impostare la soglia operativa vicina alla latenza di archiviazione nativa. Obiettivo 2-6 ms, scegliendo l'estremità inferiore per i supporti più veloci (NVMe/SSD) e l'estremità superiore per i livelli più lenti.
Il grafico a linee seguente mostra la misurazione della latenza del disco all'interno di un sistema di archiviazione.

Analizziamo questo grafico a linee:
- L'area a sinistra del grafico cerchiata in verde mostra che la latenza è coerente a 10 ms man mano che il carico aumenta da 800 operazioni di I/O al secondo a 2.400 operazioni di I/O al secondo. Questa baseline di latenza è influenzata dal tipo di soluzione di archiviazione usata.
- L'area sul lato destro del grafico cerchiata in maroon mostra la velocità effettiva del sistema tra la linea di base e la fine della raccolta dei dati. La velocità effettiva stessa non cambia, ma la latenza aumenta. Questa area mostra cosa accade quando il volume della richiesta supera il limite fisico del sistema di archiviazione. Le richieste rimangono nella coda più a lungo prima che il disco le serva.
A questo punto, si esaminerà ciò che questi dati ci indicano.
Prima di tutto, si supponga che un utente che esegue query sull'appartenenza a un gruppo di grandi dimensioni richieda che il sistema legga 1 MB di dati dal disco. È possibile valutare la quantità di operazioni di I/O necessarie e il tempo necessario per le operazioni con questi valori:
- Le dimensioni di ogni pagina del database di Active Directory sono pari a 8 KB.
- Il numero minimo di pagine che il sistema deve leggere è 128.
- Pertanto, nell'area di base del diagramma, il sistema deve richiedere almeno 1,28 secondi per caricare i dati dal disco e restituirli al client. Al segno dei 20 ms, dove il throughput supera il valore massimo consigliato, il processo richiede 2,5 secondi.
In base a questi numeri, è possibile calcolare la velocità di riscaldamento della cache usando questa equazione:
2.400 IOPS × 8 KB per I/O
Dopo aver eseguito questo calcolo, è possibile dire che la frequenza di riscaldamento della cache in questo scenario è di 20MBps. In altre parole, il sistema carica circa 1 GB di database nella RAM ogni 53 secondi.
Note
È normale che la latenza venga aumentata per brevi periodi, mentre i componenti vengono letti o scritti in modo aggressivo sul disco. Ad esempio, la latenza aumenta quando il sistema esegue il backup o Active Directory Domain Services esegue Garbage Collection. È consigliabile fornire spazio aggiuntivo per questi eventi periodici oltre alle stime di utilizzo originali. L'obiettivo è fornire una velocità effettiva sufficiente per soddisfare questi picchi senza influire sul funzionamento complessivo.
Esiste un limite fisico alla velocità di riscaldamento della cache in base al modo in cui si progetta il sistema di archiviazione. L'unica cosa che può riscaldare la cache fino alla frequenza con cui l'archiviazione sottostante può soddisfare sono le richieste client in ingresso. L'esecuzione di script per provare a preavvisare la cache durante le ore di punta è in competizione con richieste client reali, aumenta il carico complessivo, carica i dati non rilevanti per le richieste client e riduce le prestazioni. È consigliabile evitare di usare misure artificiali per riscaldare la cache.