Come gestire la latenza della coda
- 13 minuti
Sono già state illustrate diverse tecniche di ottimizzazione usate nel cloud per ridurre la latenza. Alcune delle misure studiate includono il ridimensionamento delle risorse orizzontalmente o verticalmente e l'uso di un servizio di bilanciamento del carico per instradare le richieste alle risorse disponibili più vicine. Questa pagina illustra in modo più approfondito il motivo per cui, in un data center di grandi dimensioni o in un'applicazione cloud, è importante ridurre al minimo la latenza per tutte le richieste e non solo ottimizzare per il caso generale. Verrà illustrato come anche alcuni outlier ad alta latenza possano ridurre significativamente le prestazioni osservate di un sistema di grandi dimensioni. Questa pagina illustra anche varie tecniche per creare servizi che forniscono risposte prevedibili a bassa latenza, anche se i singoli componenti non garantiscono questo risultato. Si tratta di un problema particolarmente significativo per le applicazioni interattive in cui la latenza desiderata per un'interazione è inferiore a 100 ms.
Che cos'è la latenza della coda?
La maggior parte delle applicazioni cloud sono sistemi distribuiti di grandi dimensioni che spesso si basano sulla parallelizzazione per ridurre la latenza. Una tecnica comune consiste nel distribuire una richiesta ricevuta a un nodo radice (ad esempio, un server front-end) a molti nodi foglia (server di calcolo back-end). Il miglioramento delle prestazioni è determinato dal parallelismo del calcolo distribuito e dal fatto che vengono evitati costi di spostamento dei dati estremamente costosi. È sufficiente spostare il calcolo nella posizione in cui sono archiviati i dati. Naturalmente, ogni nodo foglia gestisce simultaneamente centinaia o persino migliaia di richieste parallele.
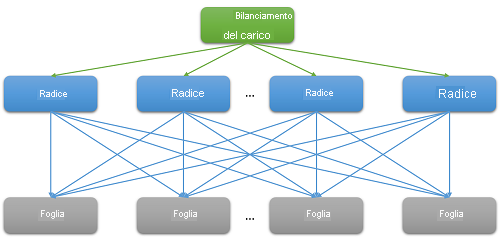
Figura 7: latenza dovuta a scale-out
Si consideri l'esempio di ricerca di un film su Netflix. Quando un utente inizia a digitare nella casella di ricerca, verranno generati diversi eventi paralleli dal server Web radice. Questi eventi includono almeno le richieste seguenti:
- Al motore di completamento automatico, per stimare effettivamente la ricerca eseguita in base alle tendenze passate e al profilo dell'utente.
- Al motore di correzione, che rileva gli errori nella query tipizzata in base a un modello linguistico di adattamento costante.
- Singoli risultati della ricerca per ognuna delle parole componenti di una query con più parole, che devono essere combinate in base alla classificazione e alla pertinenza dei film.
- Ulteriore post-elaborazione e filtro dei risultati per soddisfare le preferenze di "ricerca sicura" dell'utente.
Tali esempi sono estremamente comuni. Una singola richiesta di Facebook è nota per contattare migliaia di server memcached, mentre una singola ricerca Bing spesso contatta oltre diecimila server di indicizzazione.
Ovviamente, la necessità di scalabilità ha portato a un ampio fan-out sul back-end per ogni singola richiesta gestita dal front-end. Per i servizi che devono essere "reattivi" per mantenere la propria base utente, l'euristica mostra che le risposte sono previste entro 100 ms. Con l'aumentare del numero di server necessari per risolvere una query, il tempo complessivo dipende spesso dalla risposta con prestazioni peggiori da un nodo foglia a un nodo radice. Supponendo che tutti i nodi foglia debbano terminare l'esecuzione prima che possa essere restituito un risultato, la latenza complessiva deve essere sempre maggiore della latenza del singolo componente più lento.
Come la maggior parte dei processi stocastici, il tempo di risposta di un singolo nodo foglia può essere espresso come distribuzione. Decenni di esperienza hanno dimostrato che, nel caso generale, la maggior parte delle richieste (>99%) di un sistema cloud ben configurato verrà eseguita estremamente rapidamente. Spesso, tuttavia, in un sistema è presente un numero molto limitato di outlier che vengono eseguiti molto lentamente.

Figura 8: esempio di latenza di coda5
Si consideri un sistema in cui tutti i nodi foglia hanno un tempo medio di risposta di 1 ms, ma esiste una probabilità di 1% che il tempo di risposta sia maggiore di 1.000 ms (un secondo). Se ogni query viene gestita da un solo nodo foglia, anche la probabilità che la query impieghi più di un secondo è dell'1%. Tuttavia, man mano che si aumenta il numero di nodi a 100, la probabilità che la query finisca entro un secondo scende a 36,6%, il che significa che esiste una probabilità di 63,4% che la durata della query venga determinata dalla parte finale (minimo 1%) della distribuzione della latenza.
$(.99^{100})$
Se si simula questa operazione per un'ampia gamma di casi, si noterà che, man mano che aumenta il numero di server, l'impatto di una singola query lenta è più pronunciato (si noti che il grafico seguente è in aumento monotonico). Inoltre, poiché la probabilità di questi outlier diminuisce dall'1% allo 0,01%, il sistema è sostanzialmente più basso.
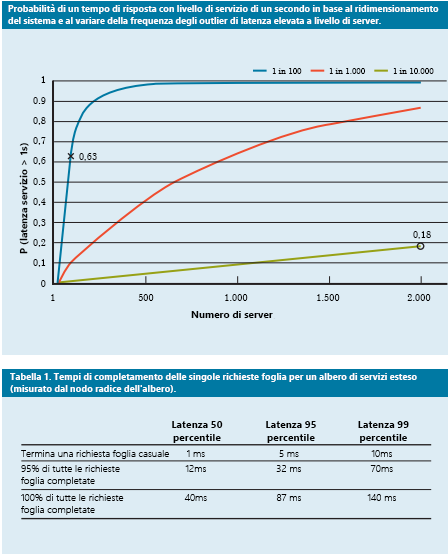
Figura 9: Recente studio della probabilità del tempo di risposta che mostra il 50°, il 95 e il 99° percentile per latenza delle richieste4
Proprio come abbiamo progettato le applicazioni per essere a tolleranza di errore per gestire i problemi di affidabilità delle risorse, dovrebbe essere chiaro perché è importante che le applicazioni siano "a tolleranza di coda". Per poter eseguire questa operazione, è necessario comprendere le origini di queste lunghe variazioni delle prestazioni e identificare le mitigazioni dove possibile e le soluzioni alternative.
Variabilità nel cloud: origini e mitigazioni
Per risolvere la variabilità del tempo di risposta che porta a questo problema di latenza della coda, è necessario comprendere le origini della variabilità delle prestazioni. 1
- Uso di risorse condivise: molte macchine virtuali e applicazioni diverse all'interno di tali macchine virtuali si contendono un pool condiviso di risorse di calcolo. In rari casi, è possibile che questa contesa comporti una bassa latenza per alcune richieste. Per le attività critiche, può essere opportuno usare istanze dedicate ed eseguire periodicamente benchmark quando sono inattive, per assicurarsi che funzioni correttamente.
- Daemon in background e manutenzione: abbiamo già parlato della necessità di processi in background per creare checkpoint, creare backup, aggiornare i log, raccogliere i garbage e gestire la pulizia delle risorse. Tuttavia, questi possono ridurre le prestazioni del sistema durante l'esecuzione. Per attenuare questo problema, è importante sincronizzare le interruzioni dovute ai thread di manutenzione per ridurre al minimo l'impatto sul flusso del traffico. In questo modo tutte le variazioni si verificano in una breve finestra nota anziché casualmente nel corso della durata dell'applicazione.
- Accodamento: un'altra fonte comune di variabilità è la possibilità di burst dei modelli di arrivo del traffico. 1. Questa variabilità è esacerbata se il sistema operativo utilizza un algoritmo di pianificazione diverso da First In, First Out. I sistemi Linux spesso pianificano thread non in ordine per ottimizzare la velocità effettiva complessiva e ottimizzare l'utilizzo del server. Gli studi hanno scoperto che l'uso della pianificazione FIFO nel sistema operativo riduce la latenza della coda a costo di ridurre la velocità effettiva complessiva del sistema.
- All-to-all incast: il modello illustrato nella figura 8 precedente è noto come comunicazione all-to-all. Poiché la maggior parte delle comunicazioni di rete è tramite TCP, questo porta a migliaia di richieste e risposte simultanee tra il server Web front-end e tutti i nodi di elaborazione back-end. Si tratta di un modello di comunicazione particolarmente soggetto a picchi, che spesso genera un tipo speciale di errore di congestione noto come incast TCP.1, 2 A causa della risposta improvvisa e intensa da parte di migliaia di server, molti pacchetti vengono ignorati e ritrasmessi, con una conseguente valanga di traffico di rete per i pacchetti di dati di dimensioni molto ridotte. I data center di grandi dimensioni e le applicazioni cloud spesso devono usare driver di rete personalizzati per regolare dinamicamente la finestra di ricezione TCP e il timer di ritrasmissione. I router possono anche essere configurati per eliminare il traffico che supera una velocità specifica e ridurre le dimensioni dell'invio.
- Gestione della potenza e della temperatura: infine, la variabilità è un prodotto di altre tecniche di riduzione dei costi, ad esempio l'uso di stati inattici o la riduzione della frequenza della CPU. Un processore può spesso impiegare una quantità di tempo non insignificante per tornare attivo dopo uno stato di inattività. La disattivazione di tali ottimizzazioni dei costi comporta un utilizzo e costi più elevati dell'energia, ma una variabilità inferiore. Questo è meno un problema nel cloud pubblico, poiché i modelli di determinazione dei prezzi considerano raramente le metriche di utilizzo interno delle risorse del cliente.
Alcuni esperimenti hanno scoperto che la variabilità di tali sistemi è molto peggiore nel cloud pubblico, 3 in genere a causa di un isolamento imperfetto delle risorse virtuali e del processore condiviso. Ciò è esacerbato se molti processi sensibili alla latenza vengono eseguiti nello stesso nodo fisico dei processi a elevato utilizzo di CPU.
Vivere con variabilità: soluzioni di progettazione
Molte delle fonti di variabilità sopra non hanno soluzioni infallibili. Di conseguenza, invece di tentare di risolvere tutte le origini che gonfiano la coda di latenza, le applicazioni cloud devono essere progettate per essere a tolleranza di coda. Questo, naturalmente, è simile al modo in cui si progettano applicazioni a tolleranza di errore perché non è possibile sperare di correggere tutti i possibili errori. Alcune delle tecniche comuni per gestire questa variabilità sono:
- Risultati "abbastanza buoni": spesso, quando il sistema è in attesa di ricevere risultati da migliaia di nodi, l'importanza di qualsiasi singolo risultato può essere considerata piuttosto bassa. Di conseguenza, molte applicazioni possono scegliere di rispondere semplicemente agli utenti con risultati che arrivano all'interno di una determinata finestra di latenza breve e rimuovere il resto.
- Canaries: un'altra alternativa che viene spesso usata per percorsi di codice rari consiste nel testare una richiesta su un piccolo subset di nodi foglia per verificare se causa un arresto anomalo o un errore che può influire sull'intero sistema. La query di tipo fan-out completa viene generata solo se il canary test non provoca un errore. Questo è simile all'invio di un canarino (uccello) in una miniera di carbone per verificare se è sicuro per gli esseri umani.
- Prova e controlli di stato indotti dalla latenza: naturalmente, la maggior parte delle richieste a un sistema è troppo comune per essere testata usando un valore canary. È più probabile che tali richieste abbiano una lunga coda in caso di prestazioni ridotte di uno dei nodi foglia. Per contrastare questo problema, il sistema deve monitorare periodicamente l'integrità e la latenza di ogni nodo foglia e non instradare le richieste ai nodi che mostrano prestazioni ridotte (a causa di manutenzione o errori).
- QoS differenziale: è possibile creare classi di servizio separate per le richieste interattive, consentendo loro di assumere la priorità in qualsiasi coda. Le applicazioni senza distinzione tra latenza possono tollerare tempi di attesa più lunghi per le operazioni.
- Hedging delle richieste: si tratta di una soluzione semplice per ridurre l'impatto della variabilità inoltrando la stessa richiesta a più repliche e usando la prima risposta che arriva. Naturalmente, questo può raddoppiare o triplicare la quantità di risorse necessarie. Per ridurre il numero di richieste con copertura, la seconda richiesta può essere inviata solo se la prima risposta è stata in sospeso per un valore maggiore del 95° percentile della latenza prevista per tale richiesta. Ciò fa sì che il carico aggiuntivo sia solo di circa 5%, ma riduce significativamente la coda di latenza (nel caso tipico illustrato nella figura 9, dove la latenza del 95° percentile è molto inferiore rispetto alla latenza del 99° percentile).
- Esecuzione speculativa e replica selettiva: le attività nei nodi particolarmente occupati possono essere avviate speculativamente in altri nodi foglia sottoutilizzati. Ciò è particolarmente efficace se un errore in un determinato nodo causa l'overload.
- Soluzioni basate sull'esperienza utente: infine, il ritardo può essere nascosto in modo intelligente all'utente tramite un'interfaccia utente ben progettata che riduce la sensazione di ritardo riscontrato da un utente umano. Le tecniche per eseguire questa operazione possono includere l'uso di animazioni, la visualizzazione dei risultati iniziali o l'interazione dell'utente inviando messaggi pertinenti.
Usando queste tecniche, è possibile migliorare significativamente l'esperienza degli utenti finali di un'applicazione cloud per risolvere il problema peculiare di una coda lunga.
Riferimenti
- Li, J., Sharma, N. K., Ports, D. R., & Gribble, S. D. (2014). Tales of the Tail: Hardware, OS, and Application-Level Sources of Tail Latency dagli Atti del Simposio ACM sul Cloud Computing, ACM
- Wu, Haitao e Feng, Hubqian e Guo, Chuxiong e Zhang, Yongguang (2013). ICTCP: Incast Congestion Control for TCP in Data-Center Networks, IEEE/ACM Transactions on Networking (TON), IEEE Press
- Xu, Yunjing e Musgrave, Zachary e Noble, Brian e Bailey, Michael (2013). Bobtail: Avoiding Long Tails in the Cloud, Decima conferenza USENIX sulla progettazione e l'implementazione di sistemi in rete, USENIX Association
- Dean, Jeffrey e Barroso, Luiz André (2013). The tail at scale, Comunicazioni di ACM, ACM
- Tene, Gil (2014). [Comprendere la latenza - Alcune lezioni e strumenti chiave](https://www.infoq.com/presentations/latency-lessons-tools/, QCon London
Verificare le proprie conoscenze
Commenti e suggerimenti
Questa pagina è stata utile?
No
Serve aiuto con questo argomento?
Provare a usare Ask Learn per chiarire o guidare l'utente in questo argomento?