Ridimensionare le risorse
- 11 minuti
Uno dei principali vantaggi del cloud è dato dalla possibilità di ridimensionare le risorse di un sistema su richiesta. L'aumento delle prestazioni (provisioning di risorse più grandi) o del numero di istanze (provisioning di risorse aggiuntive) consente di ridurre il carico su singole risorse diminuendo l'utilizzo per effetto della maggiore capacità o della distribuzione più ampia del carico di lavoro.
Il ridimensionamento può aiutare a migliorare le prestazioni aumentando la velocità effettiva, poiché consente di gestire un numero maggiore di richieste. Questo può essere utile anche per ridurre la latenza durante i picchi di carico, perché in queste circostanze viene inserito in coda un numero inferiore di richieste per singola risorsa. Può inoltre essere utile per migliorare l'affidabilità del sistema riducendo l'utilizzo delle risorse in modo da allontanarsi dal relativo punto di interruzione.
È importante notare che, anche se il cloud consente di effettuare facilmente il provisioning di risorse nuove o migliori, il costo è sempre un fattore da considerare. Pertanto, sebbene sia vantaggioso aumentare le prestazioni o le istanze, è importante riconoscere anche quando è opportuno ridurle per contenere i costi. In un'applicazione a n livelli, è anche essenziale evidenziare dove si trovano i colli di bottiglia e a quale livello intervenire per ridimensionare le risorse, che si tratti del livello dati o del livello server.
Il ridimensionamento delle risorse è facilitato dal bilanciamento del carico (come descritto in precedenza), che consente di mascherare l'aspetto di ridimensionamento di un sistema nascondendolo dietro un endpoint coerente.
Strategie di ridimensionamento
Ridimensionamento orizzontale (aumento e riduzione del numero di istanze)
Il ridimensionamento orizzontale è una strategia in cui, nel tempo, altre risorse possono essere aggiunte al sistema oppure risorse estranee possono rimosse dal sistema. Questo tipo di ridimensionamento è vantaggioso per il livello server, quando il carico del sistema è imprevedibile e fluttua in modo irregolare. La natura del carico fluttuante rende fondamentale il provisioning efficiente della quantità corretta di risorse per gestire il carico in qualsiasi momento.
Alcune considerazioni che rendono impegnativa questa attività includono il tempo di rotazione di un'istanza, il modello di determinazione dei prezzi del provider di servizi cloud e la potenziale perdita di ricavi a seguito di una riduzione della qualità del servizio (QoS), in caso di ritardo nell'aumento del numero di istanze. Si consideri, ad esempio, il modello di carico seguente:
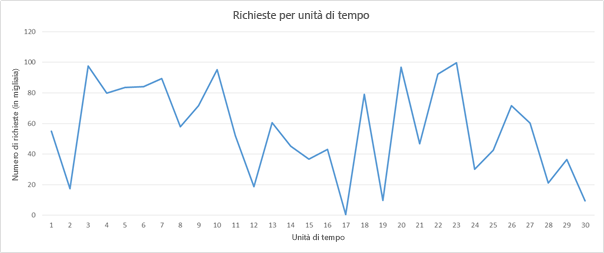
Figura 6: Modello di carico della richiesta di esempio
Si supponga di usare Amazon Web Services. Si supponga inoltre che ogni unità di tempo sia equivalente a 3 ore di tempo effettivo e che sia necessario un server per gestire 5000 richieste. Se si prende in considerazione il carico durante le unità di tempo da 16 a 22, si riscontra un'enorme fluttuazione del carico. È possibile rilevare un calo della domanda intorno all'unità di tempo 16 e iniziare a ridurre il numero di risorse allocate. Poiché si passa da circa 50.000 richieste a quasi 0 richieste nell'arco di 3 ore, in teoria è possibile risparmiare il costo di 10 istanze che sarebbero state attive nell'unità di tempo 16.
Si immagini ora che ogni unità di tempo sia uguale a 20 minuti di tempo effettivo. In tal caso, la disattivazione di tutte le risorse nell'unità di tempo 16 solo per poi creare nuove risorse dopo 20 minuti aumenterà effettivamente i costi anziché il guadagno, perché AWS addebita ogni istanza di calcolo su base oraria.
Oltre alle due considerazioni precedenti, un provider di servizi dovrà valutare le perdite che comporterà la riduzione del livello di qualità del servizio durante l'unità di tempo 20, se ha capacità solo per 90.000 richieste anziché per 100.000.
Il ridimensionamento dipende dalle caratteristiche del traffico e dal carico risultante generato in un servizio Web. Se il traffico segue un modello prevedibile (ad esempio, in base al comportamento umano, come lo streaming di film da un servizio Web la sera), il ridimensionamento può essere predittivo per mantenere QoS. Tuttavia, in molti casi, il traffico non può essere stimato e i sistemi di ridimensionamento devono essere reattivi in base a criteri diversi, come illustrato negli esempi precedenti.
Ridimensionamento verticale (aumento e riduzione delle prestazioni)
Alcuni tipi di carico sono più prevedibili di altri per i provider di servizi Internet. Se, ad esempio, in base a modelli cronologici si è conoscenza del fatto che il numero di richieste sarà sempre compreso tra 10.000 e 15.000, è possibile ragionevolmente presupporre che un server in grado di gestire 20.000 richieste sia sufficiente per gli scopi del provider di servizi. È possibile che questi carichi aumentino in futuro, ma, purché aumentino in modo coerente, il servizio può essere spostato in un'istanza più grande che può gestire più richieste. Questa soluzione è adatta per le piccole applicazioni che riscontrano una quantità di traffico limitata.
La sfida che presenta il ridimensionamento verticale è data dalla necessità di un tempo di sostituzione che può essere considerato come tempo di inattività. Ciò è dovuto al fatto che per spostare tutte le operazioni dall'istanza più piccola a un'istanza più grande, anche se il tempo di sostituzione è di pochi minuti, durante questo intervallo la qualità del servizio diminuisce.
Inoltre, la maggior parte dei provider di servizi cloud offre risorse di calcolo per aumentare la potenza di calcolo raddoppiando la potenza di calcolo di una risorsa. Pertanto, la granularità nel ridimensionamento verticale non è così dettagliata rispetto al ridimensionamento orizzontale. Di conseguenza, anche se il carico è prevedibile e in costante aumento di pari passo con la popolarità del servizio, molti provider di servizi optano per il ridimensionamento orizzontale anziché verticale.
Considerazioni sulla ridimensionamento
Monitoraggio
Il monitoraggio è uno degli elementi cruciali per ridimensionare in modo efficace le risorse, poiché consente di ottenere metriche che possono essere usate per interpretare le parti del sistema da ridimensionare e il momento in cui è necessario ridimensionarle. Consente infatti di analizzare i modelli di traffico o l'utilizzo delle risorse in modo da effettuare una valutazione ponderata su quando e come ridimensionare le risorse al fine di ottimizzare la qualità del servizio insieme ai profitti.
Gli aspetti delle risorse che vengono monitorati per attivare il ridimensionamento sono diversi. La metrica più comune è l'utilizzo delle risorse. Un servizio di monitoraggio, ad esempio, può tenere traccia dell'utilizzo della CPU di ogni nodo delle risorse e ridimensionare le risorse se l'utilizzo è troppo elevato o troppo basso. Se, ad esempio, l'utilizzo di ogni risorsa è superiore al 95%, probabilmente è consigliabile aggiungere altre risorse perché il sistema è sottoposto a un carico notevole. I provider di servizi in genere stabiliscono questi punti di attivazione analizzando il punto di rottura dei nodi delle risorse, determinando quando si verificano i primi malfunzionamenti e registrandone il comportamento a diversi livelli di carico. Anche se, per motivi di costi, è importante utilizzare al massimo ogni risorsa, è consigliabile lasciare un certo margine al sistema operativo per l'esecuzione di attività di overhead. Analogamente, se l'utilizzo è notevolmente inferiore, ad esempio del 50%, è possibile che non tutti i nodi delle risorse siano necessari e che si possa eseguire il deprovisioning di alcuni.
Nella pratica, i provider di servizi di solito monitorano una combinazione di diverse metriche di un nodo di risorse per valutare quando ridimensionare le risorse. Tra queste metriche sono inclusi l'utilizzo della CPU, l'utilizzo di memoria, la velocità effettiva e la latenza. In Azure è disponibile Monitoraggio di Azure come servizio aggiuntivo che può monitorare qualsiasi risorsa di Azure e fornire tali metriche.
Assenza di stato
Un design di servizio senza stato si adatta particolarmente a un'architettura scalabile. Un servizio senza stato significa essenzialmente che la richiesta del client contiene tutte le informazioni necessarie perché il server possa gestirla. Il server non archivia informazioni relative al client nell'istanza e nemmeno informazioni relative alla sessione nell'istanza del server.
L'uso di un servizio senza stato consente di commutare le risorse in base alle esigenze, senza bisogno di alcuna configurazione per mantenere il contesto (stato) della connessione client per le richieste successive. Se il servizio è con stato, il ridimensionamento delle risorse richiede una strategia per il trasferimento del contesto dalla configurazione dei nodi esistente alla nuova configurazione. Si noti che esistono tecniche per l'implementazione di servizi con stato, ad esempio mantenere una cache di rete con Memcached in modo da poter condividere il contesto tra i server.
Definire le risorse da ridimensionare
A seconda della natura del servizio, è necessario ridimensionare risorse diverse in base ai requisiti. Per il livello server, quando i carichi di lavoro aumentano, a seconda del tipo di applicazione, può aumentare la contesa di risorse per CPU, memoria, larghezza di banda di rete o tutte queste risorse. Il monitoraggio del traffico consente di identificare la risorsa che sta per essere vincolata e di ridimensionare in modo appropriato la risorsa specifica. I provider di servizi cloud non forniscono necessariamente la granularità di scalabilità necessaria per ridimensionare solo le risorse di calcolo o di memoria, ma forniscono tipi diversi di istanze di calcolo che soddisfano in modo specifico i carichi di lavoro a elevato utilizzo di calcolo o di memoria. Quindi, ad esempio, per un'applicazione che deve gestire carichi di lavoro a utilizzo intensivo di memoria, è consigliabile aumentare le prestazioni delle risorse nelle istanze ottimizzate per la memoria. Per le applicazioni che devono gestire un numero elevato di richieste che non richiedono necessariamente un utilizzo intensivo delle risorse di calcolo e di memoria, il ridimensionamento orizzontale di più istanze di calcolo standard potrebbe costituire una strategia migliore.
Aumentare le risorse hardware non è sempre la soluzione migliore per migliorare le prestazioni di un servizio. L'aumento dell'efficienza degli algoritmi usati dal servizio può anche contribuire a ridurre la contesa di risorse e migliorare l'utilizzo, eliminando la necessità di ridimensionare le risorse fisiche.
Ridimensionare il livello dati
Nelle applicazioni orientate ai dati, che prevedono un numero elevato di letture e scritture (o entrambe) in un database o un sistema di archiviazione, il tempo di round trip per ogni richiesta è spesso limitato dai tempi di lettura e scrittura del disco rigido. Le istanze più grandi offrono prestazioni di I/O superiori per le operazioni di lettura e scrittura, che possono migliorare i tempi di ricerca sul disco rigido e, di conseguenza, possono determinare un notevole miglioramento della latenza del servizio. La presenza di più istanze di dati nel livello dati può migliorare l'affidabilità e la disponibilità dell'applicazione fornendo ridondanze di failover. La replica dei dati tra più istanze presenta vantaggi aggiuntivi nella riduzione della latenza di rete se il client viene servito da un data center fisicamente più vicino. Il partizionamento orizzontale dei dati tra più risorse è un'altra strategia di ridimensionamento orizzontale dei dati in cui, anziché essere semplicemente replicati tra più istanze, i dati vengono suddivisi in partizioni e archiviati in più server di dati.
La sfida aggiuntiva quando si tratta di ridimensionare il livello dati è che mantenere la coerenza (un'operazione di lettura in tutte le repliche è la stessa), la disponibilità (letture e scritture hanno sempre esito positivo) e la tolleranza di partizione (le proprietà garantite nel sistema vengono mantenute quando gli errori impediscono la comunicazione tra nodi). Questo è spesso definito teorema CAP. In base a questo teorema, un sistema di database distribuito può difficilmente fornire simultaneamente tutte e tre le proprietà e di conseguenza può offrire al massimo una combinazione di due delle proprietà. Altre informazioni sulle strategie di ridimensionamento del database e sul teorema CAP saranno disponibili nei moduli successivi.
Verifica delle conoscenze
Commenti e suggerimenti
Questa pagina è stata utile?
No
Serve aiuto con questo argomento?
Provare a usare Ask Learn per chiarire o guidare l'utente in questo argomento?