Creare servizi cloud a tolleranza di errore
- 13 minuti
Una parte importante della gestione dei data center e dei servizi cloud prevede la progettazione e la gestione di un servizio affidabile basato su parti non affidabili. Nella figura seguente viene illustrata una parte di un training per i nuovi assunti e dovrebbe dare un'idea del numero elevato (e dei tipi) di errori riscontrati regolarmente in un data center di grandi dimensioni.

Figura 2: Problemi di affidabilità rilevati in una presentazione di training
Un errore di un sistema si verifica in seguito a uno stato non valido introdotto nel sistema a causa di un errore. I sistemi sviluppano in genere i tipi di errori seguenti:
- Errori temporanei: errori temporanei nel sistema che si autocorreggono con il tempo.
- Errori permanenti: errori che non consentono il ripristino del sistema e che in genere richiedono la sostituzione di risorse.
- Errori intermittenti: errori che si verificano periodicamente in un sistema.
Gli errori possono influire sulla disponibilità del sistema, riducendo i servizi o le prestazioni delle funzionalità del sistema. Un sistema a tolleranza di errore è in grado di svolgere la propria funzione anche in presenza di errori. Nel cloud, un sistema di questo tipo è spesso considerato come un sistema che fornisce servizi in modo coerente con tempi di inattività inferiori a quelli consentiti dai contratti di servizio.
Perché la tolleranza di errore è importante?
Gli errori nei sistemi cruciali di grandi dimensioni possono comportare perdite economiche significative per tutte le parti interessate. Per loro natura, i sistemi di cloud computing dispongono di un'architettura a più livelli. Pertanto, un errore in un livello delle risorse cloud può generare un errore in altri livelli superiori oppure nascondere l'accesso ai livelli inferiori.
Ad esempio, un errore in qualsiasi componente hardware del sistema può influire sulla normale esecuzione di un'applicazione SaaS (Software as a Service) in esecuzione su una macchina virtuale che utilizza le risorse difettose. Gli errori in un sistema a qualsiasi livello hanno una relazione diretta con i contratti di servizio tra i provider a ogni livello.
Misure proattive
I provider di servizi adottano diverse misure per progettare il sistema in modo da evitare problemi noti o errori prevedibili.
Profilatura e test
I test di carico e stress delle risorse cloud per comprendere le possibili cause degli errori sono fondamentali per assicurare la disponibilità dei servizi. La profilatura di queste metriche contribuisce alla progettazione di un sistema in grado di sostenere correttamente il carico previsto senza alcun comportamento imprevedibile.
Over-provisioning
L'over-provisioning è la pratica di distribuzione delle risorse in volumi di dimensioni superiori rispetto all'utilizzo generale previsto per le risorse in un determinato momento. Nelle situazioni in cui non è possibile stimare le esigenze esatte del sistema, l'over-provisioning delle risorse può costituire una strategia accettabile per gestire picchi imprevisti nei carichi.
Si consideri, ad esempio, una piattaforma di e-commerce con un carico medio costante sui server per tutto l'anno, ma per cui è previsto un rapido picco nel modello di carico durante il periodo natalizio. In questo periodo di picco, è consigliabile effettuare il provisioning di risorse aggiuntive in base ai dati storici relativi all'utilizzo massimo. Un incremento rapido del traffico è in genere difficile da gestire entro breve tempo. Come descritto nelle sezioni successive, il ridimensionamento dinamico comporta un costo in termini di tempo, poiché presuppone l'esecuzione di passaggi specifici per rilevare una modifica nel modello di carico e il provisioning di risorse aggiuntive per gestire il nuovo carico. Entrambi i passaggi richiedono tempo. Questo ritardo nella rettifica può essere sufficiente a sovraccaricare, e addirittura causare un arresto anomalo, del sistema o, nell'ipotesi migliore, peggiorare la qualità del servizio.
L'over-provisioning è anche una tattica adottata per difendersi dagli attacchi DoS (Denial of Service) o DDoS (Distributed DoS), che si verificano quando gli utenti malintenzionati inviano richieste appositamente progettate per sovraccaricare un sistema generando grandi volumi di traffico nel tentativo di causare un guasto del sistema. In qualsiasi attacco, il sistema ha sempre bisogno di tempo per rilevare il problema e adottare misure correttive. Mentre è in corso l'analisi dei modelli di richiesta, il sistema è già sotto attacco e deve essere in grado di gestire l'aumento del traffico fino a quando non è possibile implementare una strategia di mitigazione.
Replica
È possibile duplicare i componenti di sistema critici usando componenti hardware e software aggiuntivi per gestire in modo invisibile gli errori in determinate parti del sistema senza che sia interessato l'intero sistema. La replica prevede due strategie di base:
- Replica attiva, in cui tutte le risorse replicate sono attive simultaneamente, rispondono a tutte le richieste e le elaborano. Ciò significa che, per qualsiasi richiesta client, tutte le risorse ricevono la stessa richiesta, tutte le risorse rispondono alla stessa richiesta e l'ordine delle richieste mantiene lo stato in tutte le risorse.
- Replica passiva, in cui solo l'unità primaria elabora le richieste e le unità secondarie mantengono semplicemente lo stato e subentrano in caso di errore dell'unità primaria. Il client è solo in contatto con la risorsa primaria, che inoltra il cambiamento di stato a tutte le risorse secondarie. Lo svantaggio della replica passiva è dato dalla possibilità che, nel passaggio dall'istanza primaria a quella secondaria, alcune richieste vengano annullate o si verifichi un peggioramento della qualità del servizio.
Esiste anche una strategia ibrida, denominata semiattiva, che è molto simile alla strategia attiva. La differenza è data dal fatto che solo l'output della risorsa primaria è esposto al client. Gli output delle risorse secondarie vengono eliminati e registrati e sono pronti per il cambio non appena si verifica un errore della risorsa primaria. La figura seguente illustra le differenze tra le strategie di replica.
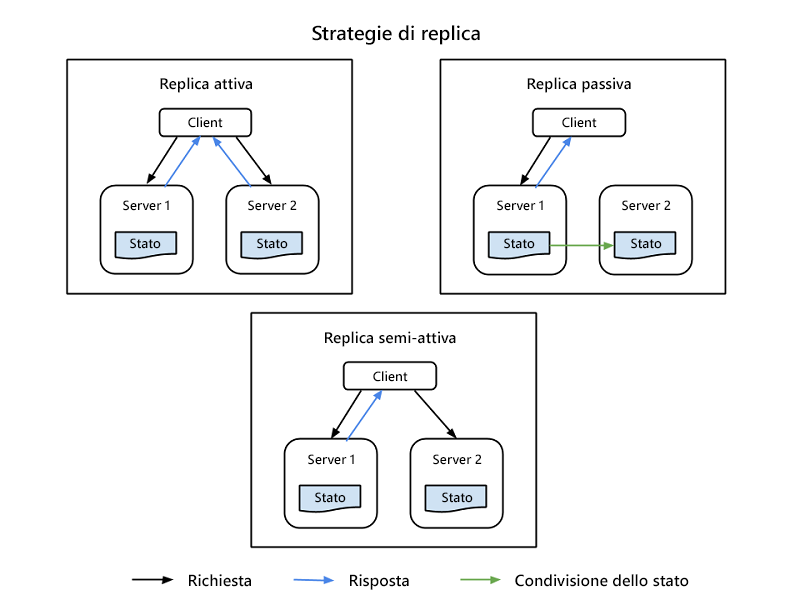
Figura 3: Strategie di replica
Un fattore importante da considerare nella replica consiste nel numero di risorse secondarie da usare. Sebbene questo aspetto può variare da un'applicazione all'altra in base alla criticità del sistema, esistono 3 livelli formali di replica:
- N+1: ciò significa fondamentalmente che, per un'applicazione che necessita di N nodi per funzionare correttamente, viene eseguito il provisioning di una risorsa aggiuntiva da usare come alternativa.
- 2N: a questo livello, per ogni nodo necessario per il normale funzionamento dell'applicazione, viene eseguito il provisioning di un nodo aggiuntivo da usare come alternativa.
- 2N+1: a questo livello, per ogni nodo necessario per il normale funzionamento dell'applicazione, viene eseguito il provisioning di un nodo aggiuntivo e di un ulteriore nodo globale da usare come alternativa.
Misure reattive
Oltre alle misure predittive, i sistemi possono adottare misure reattive e gestire gli errori come e quando si verificano:
Controlli e monitoraggio
Tutte le risorse vengono monitorate costantemente per verificare eventuali comportamenti imprevedibili o la perdita di risorse. In base alle informazioni di monitoraggio, vengono progettate strategie di ripristino o di riconfigurazione per riavviare le risorse o attivarne di nuove. Il monitoraggio può essere utile per l'identificazione degli errori nei sistemi. Gli errori che compromettono la disponibilità di un servizio sono detti errori di arresto anomalo, mentre quelli che determinano un comportamento irregolare o errato nel sistema sono detti errori bizantini.
Sono disponibili diverse tattiche di monitoraggio che vengono usate per controllare gli errori di arresto anomalo all'interno di un sistema. Due di queste tattiche sono:
- Ping Echo: il servizio di monitoraggio chiede a ogni risorsa di comunicare il proprio stato, concedendo un intervallo di tempo per rispondere.
- Heartbeat: ogni istanza comunica il proprio stato al servizio di monitoraggio a intervalli regolari, senza trigger.
Il monitoraggio degli errori bizantini dipende in genere dalle proprietà del servizio fornito. I sistemi di monitoraggio possono controllare le metriche di base, ad esempio la latenza, l'utilizzo della CPU e l'utilizzo della memoria, rispetto ai valori previsti per determinare se la qualità del servizio è peggiorata. Inoltre, i log di supervisione specifici dell'applicazione vengono in genere conservati in ogni punto di esecuzione importante del servizio e analizzati periodicamente per verificare che il servizio funzioni correttamente in qualsiasi momento (o se sono stati introdotti errori nel sistema).
Checkpoint e riavvio
Diversi modelli di programmazione nel cloud implementano strategie di checkpoint, in cui lo stato viene salvato in corrispondenza di diverse fasi di esecuzione per consentire il ripristino fino all'ultimo checkpoint salvato. Nelle applicazioni di analisi dei dati vengono spesso eseguite attività distribuite parallele a esecuzione prolungata che vengono eseguite su terabyte di set di dati per l'estrazione di informazioni. Poiché queste attività vengono eseguite in diversi blocchi di piccole dimensioni, ogni passaggio nell'esecuzione del programma può salvare lo stato complessivo di esecuzione come checkpoint. In corrispondenza dei punti di errore in cui i singoli nodi non sono in grado di completare il lavoro, l'esecuzione può essere riavviata da un checkpoint precedente. Il problema principale durante l'identificazione dei checkpoint validi per il rollback è dato dal caso in cui le informazioni sono condivise da processi paralleli. Un errore in uno dei processi può causare un rollback a catena in un altro processo, perché i checkpoint creati in tale processo possono essere il risultato di un errore nei dati condivisi dal processo in cui si è verificato un errore. Nei moduli successivi verranno fornite altre informazioni sulla tolleranza di errore per i modelli di programmazione.
Case study relativi ai test di resilienza
I servizi cloud devono avere caratteristiche di ridondanza e tolleranza di errore, poiché nessun singolo componente di un ampio sistema distribuito può garantire il 100% di disponibilità o di tempo di attività.
Tutti gli errori (inclusi quelli delle dipendenze nello stesso nodo, nel rack, nel data center o nelle distribuzioni con ridondanza geografica) devono essere gestiti normalmente senza influire sull'intero sistema. Il test della capacità del sistema di gestire gli errori irreversibili è importante, poiché talvolta anche alcuni secondi di tempo di inattività o di riduzione del servizio possono causare ingenti perdite di introiti.
Il test degli errori con traffico reale deve essere eseguito regolarmente in modo che il sistema sia dotato di protezione avanzata e possa far fronte un'eventuale interruzione non pianificata. Esistono diversi sistemi creati per testare la resilienza. Un gruppo di test di questo tipo è Simian Army creato da Netflix.
Simian Army è costituito da servizi (noti come Monkey) nel cloud per la generazione di diversi tipi di errori, il rilevamento di condizioni anomale e il test della capacità del sistema di sopravvivere a tali condizioni. L'obiettivo è quello di garantire la sicurezza e la disponibilità elevata del cloud. Di seguito sono riportati alcuni servizi Monkey inclusi in Simian Army:
- Chaos Monkey: uno strumento che seleziona in modo casuale un'istanza di produzione e la disabilita per assicurarsi che il cloud sopravviva ai tipi comuni di errore senza alcun impatto sul cliente. Netflix descrive Chaos Monkey come "L'idea di liberare una scimmia selvaggia con un'arma nel data center (o area cloud) per abbattere in modo casuale istanze e morsicare e distruggere cavi, continuando al tempo stesso a fornire servizi ai clienti senza interruzioni". Questo tipo di test con monitoraggio dettagliato può esporre diversi tipi di vulnerabilità nel sistema e può consentire di definire strategie di ripristino automatico basate sui risultati.
- Latency Monkey: un servizio che induce ritardi nelle comunicazioni RESTful di client e server diversi, simulando riduzione delle prestazioni e tempi di inattività del servizio.
- Doctor Monkey: un servizio che trova le istanze che presentano comportamenti non integri (ad esempio, il carico della CPU) e le rimuove. Consente ai proprietari del servizio di individuare la causa del problema e infine di terminare l'istanza.
- Chaos Gorilla: un servizio che consente di simulare la perdita di un'intera zona di disponibilità AWS. Viene usato per verificare che i servizi siano in grado di ribilanciare automaticamente la funzionalità tra le zone rimanenti senza alcun intervento manuale o impatto visibile all'utente.
Verificare le conoscenze
Commenti e suggerimenti
Questa pagina è stata utile?
No
Serve aiuto con questo argomento?
Provare a usare Ask Learn per chiarire o guidare l'utente in questo argomento?