Nota
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare ad accedere o modificare le directory.
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare a modificare le directory.
Si applica a:![]() SQL Server 2016 (13.x) e versioni
SQL Server 2016 (13.x) e versioni ![]() successive Azure SQL Database
successive Azure SQL Database![]() AzureSQL Managed Instance
AzureSQL Managed Instance![]() SQL database in Microsoft Fabric
SQL database in Microsoft Fabric
La virtualizzazione dei dati consente di eseguire query di Transact-SQL (T-SQL) su dati esterni senza caricarli nel database. PolyBase è la funzionalità del motore di database che implementa la virtualizzazione dei dati in SQL Server e Azure SQL. Si definisce un'origine dati esterna, un formato di file facoltativo e una tabella esterna e quindi si esegue una query sulla tabella esterna con SELECT come qualsiasi altra tabella.
Questa guida consente di:
- Comprendi quali funzionalità di PolyBase sono supportate dalla tua piattaforma SQL e versione.
- Scegliere tra
OPENROWSET, tabelle esterne eBULK INSERTper l'esecuzione di query o l'inserimento di dati. - Seguire i collegamenti passo passo per gli scenari comuni.
- Esaminare le prestazioni, la risoluzione dei problemi e le procedure consigliate per i carichi di lavoro di produzione.
Casi d'uso comuni
La tabella seguente descrive i possibili scenari di utilizzo.
| Scenario | Utilizzo |
|---|---|
| Esplorazione di file ad hoc | OPENROWSET(BULK ...) |
| Interrogazioni di file riutilizzabili per business intelligence/reportistica | Tabelle esterne su file |
| Query inter-database (SQL Server, Oracle, Teradata, MongoDB, ODBC) | Connettori PolyBase con tabelle esterne |
| Esportazione dei risultati delle query in file |
CREATE EXTERNAL TABLE AS SELECT (CETAS) |
| Inserimento massivo nelle tabelle |
BULK INSERT o OPENROWSET(BULK ...) con INSERT ... SELECT |
Quali funzionalità sono disponibili dove?
La tabella seguente illustra le funzionalità di base di PolyBase e di virtualizzazione dei dati disponibili in ogni piattaforma SQL. Usare questa tabella per determinare le operazioni che è possibile eseguire sulla piattaforma prima di usare le guide dettagliate.
| Feature | SQL Server 2019 | SQL Server 2022 | SQL Server 2025 | Database SQL di Microsoft Azure | Istanza SQL gestita di Azure | Database SQL di Microsoft Fabric |
|---|---|---|---|---|---|---|
| tabelle esterne | Sì | Sì | Sì | Sì | Sì | Sì |
| OPENROWSET (BULK) | Sì 1 | Sì | Sì | Sì | Sì | Sì |
| CETAS (esportazione) | No | Sì | Sì | No | Sì | No |
| File CSV/delimitati | Sì 2 | Sì | Sì | Sì | Sì | Sì |
| File Parquet | No | Sì | Sì | Sì | Sì | Sì |
| Tabelle Delta Lake | No | Sì | Sì | No | No | No |
| Connettersi a un altro SQL Server | Sì | Sì | Sì | No | No | No |
| Connettersi al database SQL di Azure o all'istanza gestita di SQL di Azure | Sì 3 | Sì 3 | Sì 3 | No | No | No |
| Connettersi a Oracle/Teradata/MongoDB | Sì | Sì | Sì | No | No | No |
| Connettersi ad Archiviazione BLOB di Azure | Sì | Sì | Sì | Sì | Sì | No |
| Connettersi ad ADLS Gen2 | No | Sì | Sì | Sì | Sì | No |
| Connettersi all'archiviazione compatibile con S3 | No | Sì | Sì | No | No | No |
| Connettersi a OneLake (Fabric) | No | No | No | No | No | Sì |
| Calcolo *pushdown* | Sì | Sì | Sì | No | No | No |
| Autenticazione dell'identità gestita | No | No | Sì 4 | Sì | Sì | No |
1 SQL Server 2019 (15.x) supporta OPENROWSET(BULK...) per i percorsi di file di rete e locali. In SQL Server 2022 (16.x) e versioni successive supporta OPENROWSET(BULK...) anche la lettura dall'archiviazione cloud con FORMAT = 'PARQUET', FORMAT = DELTAe FORMAT = 'CSV'.
2 Il supporto CSV in SQL Server 2019 (15.x) richiedeva Hadoop. In SQL Server 2022 (16.x) e versioni successive il file CSV è supportato in modo nativo senza Hadoop.
3 Usa il connettore SQL Server (sqlserver://). Le credenziali con ambito database hanno come destinazione l'endpoint SQL di Azure, gli stessi passaggi della connessione a un altro SQL Server.
4 L'autenticazione con Managed Identity è supportata per la connessione a Azure Blob Storage (ABS) e ADLS Gen2. Richiede SQL Server abilitato per Azure Arc o SQL Server in una macchina virtuale di Azure per SQL Server locale. È disponibile in modo nativo nel database SQL di Azure e nell'istanza gestita di SQL di Azure.
Annotazioni
A partire da SQL Server 2025 (17.x) l'esecuzione di query sui file di dati (CSV, Parquet e Delta) nell'Archiviazione BLOB di Azure, ADLS Gen2 o archiviazione compatibile con S3 è una funzionalità nativa del motore e non richiede più l'installazione o l'esecuzione di servizi PolyBase. I connettori RDBMS (SQL Server, Oracle, Teradata, MongoDB, ODBC) richiedono comunque l'installazione e l'esecuzione dei servizi PolyBase. SQL Server 2025 (17.x) aggiunge anche il supporto Linux per questi connettori, che in precedenza erano disponibili solo in Windows.
Interrogare dati esterni
Prima di scegliere uno scenario specifico, comprendere i tre modi per eseguire query sui dati esterni:
| Avvicinarsi | Sintassi | Usare quando | Autenticazione | PolyBase obbligatorio |
|---|---|---|---|---|
| Query OLE DB ad hoc | OPENROWSET(provider, connection, query) |
Si vuole eseguire una query una tantum rapida senza oggetti persistenti oppure è necessaria l'autenticazione dell'ID Entra Di Microsoft | Autenticazione SQL, autenticazione di Windows, ID Microsoft Entra (MSOLEDBSQL) | No |
| Query ad hoc sui file | OPENROWSET(BULK ...) |
Si vogliono esplorare rapidamente i dati dei file o testare gli schemi prima di creare una tabella | Token SAS, chiave di accesso, identità gestita, Microsoft Entra ID | Sì per il database SQL di Azure e l'istanza SQL gestita di Azure No per le istanze di SQL Server |
| Connettori dati persistenti |
CREATE EXTERNAL TABLE con sqlserver://, oracle://, teradata://e così via. |
È necessario l'accesso continuo, la governance, le statistiche e il calcolo pushdown per l'ambiente di produzione. | Solo autenticazione SQL | Sì |
I servizi PolyBase sono necessari per l'accesso ai file cloud in SQL Server 2019 (15.x) e SQL Server 2022 (16.x). SQL Server 2025 (17.x) e versioni successive hanno il supporto nativo per CSV, Parquet e Delta senza PolyBase.
Guida alle decisioni
| Scenario | Raccomandazione |
|---|---|
| È necessaria l'autenticazione di Microsoft Entra ID per SQL remoto o si vuole evitare i servizi PolyBase | Usare OPENROWSET(MSOLEDBSQL, ...) (ad hoc, nessun oggetto permanente) |
| Sono necessarie tabelle persistenti, statistiche o calcoli pushdown nei database remoti. | Usare CREATE EXTERNAL TABLE con i connettori PolyBase (sqlserver://, oracle://, teradata://mongodb://, , odbc://).
OPENROWSET
non supporta i connettori |
| Si sta esplorando un nuovo file o si sta testando uno schema | Usare OPENROWSET(BULK ...) (iterazione veloce, nessun oggetto persistente) |
| Sto inserendo dati da file in una tabella con trasformazioni | Usare INSERT ... SELECT da OPENROWSET(BULK ...) |
| È necessario un accesso condiviso o di governance per molti utenti o applicazioni | Usare CREATE EXTERNAL TABLE in modo che le autorizzazioni e i metadati siano centralizzati |
| Lavoro nel database SQL in Fabric | Usare OPENROWSET(BULK ...) per query ad hoc di OneLake o tabelle esterne per accedere in modo riutilizzabile; per l'archiviazione esterna usare le scorciatoie OneLake |
Scegliere lo scenario
Dopo aver compreso i tre approcci, usare una delle guide seguenti per implementare il caso d'uso specifico.
File di query (Parquet, CSV o Delta)
Se i dati si trovano in file Parquet, CSV o Delta in Archiviazione BLOB di Azure, ADLS Gen2, archiviazione compatibile con S3 o OneLake, seguire una delle guide seguenti:
| Scenario | Guida consigliata | Platforms |
|---|---|---|
| Interrogazione ad hoc veloce su un file Parquet o CSV | Utilizzare il OPENROWSET. Nessuna tabella esterna necessaria |
SQL Server 2022 (16.x) e versioni successive, database SQL di Azure, Istanza gestita di SQL di Azure, database SQL in Fabric |
| Query ripetute su file Parquet con uno schema persistente | Creare una tabella esterna su Parquet | SQL Server 2022 (16.x) e versioni successive, database SQL di Azure, Istanza gestita di SQL di Azure, database SQL in Fabric |
| Interrogare file CSV utilizzando una tabella esterna | Creare una tabella esterna con un formato di file per il testo delimitato | SQL Server 2019 (15.x) e versioni successive, database SQL di Azure, Istanza gestita di SQL di Azure, database SQL in Fabric |
| Eseguire query sulle tabelle Delta Lake | Creare una tabella esterna con FILE_FORMAT = DeltaLakeFileFormat |
SQL Server 2022 (16.x) e versioni successive |
| Esportare i risultati delle query in file Parquet o CSV (CETAS) | Utilizzare CREATE EXTERNAL TABLE AS SELECT. |
SQL Server 2022 (16.x) e versioni successive, Istanza gestita di SQL di Azure |
È anche possibile seguire una di queste esercitazioni dettagliate:
| Tutoriale | Descrizione |
|---|---|
| Introduzione con PolyBase in SQL Server 2022 | Copre OPENROWSET con Parquet e CSV, tabelle esterne e navigazione tra cartelle. |
| Virtualizzare un file Parquet in una risorsa di archiviazione di oggetti compatibile con S3 con PolyBase | Esercitazione per SQL Server 2022 (16.x) e versioni successive. |
| Virtualizzare il file CSV con PolyBase | Esercitazione per SQL Server 2022 (16.x) e versioni successive. |
| Virtualizzare la tabella delta con PolyBase | Esercitazione per SQL Server 2022 (16.x) e versioni successive. |
| Virtualizzazione dei dati con il database SQL di Azure (anteprima) | Guida al database SQL di Azure per Parquet e CSV. |
| Virtualizzazione dei dati con Istanza gestita di SQL di Azure | Guida all'Istanza SQL gestita di Azure per Parquet, CSV e CETAS. |
| Virtualizzazione dei dati in database SQL in Fabric | Guida ai file OneLake per il database SQL in Fabric. |
Connettersi a un'altra istanza di SQL Server, al database SQL di Azure o a Istanza Gestita di SQL
In SQL Server 2019 (15.x) e versioni successive PolyBase può eseguire query sulle tabelle in un'altra istanza di SQL Server, nel database SQL di Azure o in Istanza gestita di SQL di Azure, senza usare server collegati.
Importante
Il sqlserver:// connettore non è supportato nel database SQL in Fabric. I connettori RDBMS PolyBase usano l'autenticazione SQL tramite CREATE DATABASE SCOPED CREDENTIAL e non supportano Microsoft Entra ID, identità gestita o autenticazione del principale del servizio. Poiché il database SQL in Fabric richiede l'autenticazione Di Microsoft Entra, non è possibile connettersi tramite PolyBase.
| Passo | Cosa fare |
|---|---|
| 1. Installare PolyBase | Installare PolyBase in Windows o installare PolyBase in Linux |
| 2. Creare una credenziale |
CREATE DATABASE SCOPED CREDENTIAL con il login di destinazione |
| 3. Creare una fonte dati esterna | CREATE EXTERNAL DATA SOURCE ... WITH (LOCATION = 'sqlserver://<server>') |
| 4. Creare una tabella esterna | CREATE EXTERNAL TABLE ... WITH (LOCATION = '<db>.<schema>.<table>') |
| 5. Interrogazione | SELECT * FROM <external_table> |
Suggerimento
Il connettore SQL Server (sqlserver://) funziona anche per il database SQL di Azure e per Istanza gestita di SQL di Azure. Usare gli stessi passaggi e impostare LOCATION sull'endpoint SQL di Azure ,ad esempio sqlserver://myserver.database.windows.net.
Per una guida dettagliata, vedere Configurare PolyBase per accedere ai dati esterni in SQL Server.
Connettersi a Oracle, Teradata o MongoDB
SQL Server 2019 (15.x) e versioni successive possono eseguire query su Oracle, Teradata, MongoDB e Cosmos DB tramite connettori ODBC PolyBase.
| L'origine dei dati | Guida | Requisiti |
|---|---|---|
| Oracle | Configurare PolyBase per l'accesso a dati esterni in Oracle | SQL Server 2019 (15.x) e versioni successive; driver client di Oracle |
| Teradata | Configurare PolyBase per l'accesso a dati esterni in Teradata | SQL Server 2019 (15.x) e versioni successive, driver ODBC Teradata |
| MongoDB/Cosmos DB | Configurare PolyBase per l'accesso a dati esterni in MongoDB | SQL Server 2019 (15.x) e versioni successive, driver ODBC MongoDB |
| Qualsiasi origine ODBC | Configurare PolyBase per l'accesso a dati esterni con i tipi generici ODBC | SQL Server 2019 (15.x) e versioni successive (Windows) (Linux a partire da SQL Server 2025 (17.x)) |
Connettersi ad Azure Blob Storage o Azure Data Lake Storage Gen2 (ADLS Gen2)
| Piattaforma SQL | Opzioni di autenticazione | Guida |
|---|---|---|
| SQL Server 2022 (16.x) e versioni successive | Token SAS, chiave di accesso, identità gestita (a partire da SQL Server 2025 (17.x)) | Configurare PolyBase per accedere ai dati esterni in Archiviazione BLOB di Azure |
| SQL Server 2019 (15.x) | Chiave di accesso (tramite connettore Hadoop) | Configurare PolyBase per accedere ai dati esterni in Archiviazione BLOB di Azure |
| Database SQL di Microsoft Azure | Token di Accesso Condiviso, identità gestita, passaggio di Microsoft Entra | Virtualizzazione dei dati con il database SQL di Azure (anteprima) |
| Istanza SQL gestita di Azure | token SAS, identità gestita | Virtualizzazione dei dati con Istanza gestita di SQL di Azure |
In SQL Server 2022 (16.x), i prefissi URI sono stati modificati. Quando si esegue la migrazione da SQL Server 2019 (15.x) o versioni precedenti:
-
Archiviazione BLOB di Azure: Cambia
wasb[s]://inabs:// -
ADLS Gen2: Passare
abfs[s]://aadls://
Per altre informazioni, vedere Configurare PolyBase per accedere ai dati esterni in Archiviazione BLOB di Azure.
Connettersi all'archiviazione di oggetti compatibile con S3
SQL Server 2022 (16.x) e versioni successive supportano l'archiviazione compatibile con S3, ad esempio Amazon S3, MinIO e Ceph.
Per altre informazioni, vedere Configurare PolyBase per accedere ai dati esterni nell'archiviazione oggetti compatibile con S3.
Esportare dati con CREATE EXTERNAL TABLE AS SELECT (CETAS)
CETAS esporta i risultati delle query in file esterni (Parquet o CSV) in Archiviazione BLOB di Azure, ADLS Gen2 o archiviazione compatibile con S3.
| Piattaforma SQL | Supportato | Formati di esportazione | Note |
|---|---|---|---|
| SQL Server 2022 (16.x) e versioni successive | Sì | Parquet, CSV | Richiede la configurazione del server: consentire l'esportazione PolyBase |
| Istanza SQL gestita di Azure | Sì | Parquet, CSV | Disabilitato per impostazione predefinita |
| Database SQL di Microsoft Azure | No | Nessuno | Non disponibile |
| Database SQL su Fabric | No | Nessuno | Non disponibile |
Per la documentazione di riferimento di Transact-SQL, vedere CREATE EXTERNAL TABLE AS SELECT (CETAS).
Esempi di avvio rapido
Esempio 1: query ad hoc in un file Parquet (OPENROWSET)
Nessuna tabella esterna necessaria. Funziona in SQL Server 2022 (16.x) e versioni successive, database SQL di Azure, Istanza gestita di SQL di Azure e database SQL in Fabric.
SELECT TOP 10 *
FROM OPENROWSET (
BULK 'abs://mycontainer@mystorageaccount.blob.core.windows.net/data/sales/*.parquet',
FORMAT = 'PARQUET'
) AS [result];
Esempio 2: Tabella esterna in formato CSV in Azure Blob Storage
Questo esempio funziona su tutte le piattaforme SQL che supportano PolyBase.
Passaggio 1: Creare una chiave master del database (DMK). Questo passaggio è obbligatorio perché le credenziali archiviano un segreto del token SAS. Tuttavia, è possibile eseguire questo passaggio se si usa l'autenticazione di Identità gestita o Microsoft Entra.
CREATE MASTER KEY ENCRYPTION BY PASSWORD = '<strong_password>';Passaggio 2: Creare una credenziale con un token SAS. Omettere l'elemento iniziale
?.CREATE DATABASE SCOPED CREDENTIAL MyStorageCred WITH IDENTITY = 'SHARED ACCESS SIGNATURE', SECRET = '<your_SAS_token>'; -- omit the leading '?'Passaggio 3: Creare un'origine dati esterna.
CREATE EXTERNAL DATA SOURCE MyAzureStorage WITH ( LOCATION = 'abs://mycontainer@mystorageaccount.blob.core.windows.net', CREDENTIAL = MyStorageCred );Passaggio 4: Creare un formato di file per il file CSV.
CREATE EXTERNAL FILE FORMAT CsvFormat WITH ( FORMAT_TYPE = DELIMITEDTEXT, FORMAT_OPTIONS ( FIELD_TERMINATOR = ',', STRING_DELIMITER = '"', FIRST_ROW = 2 ) );Passaggio 5: Creare la tabella esterna.
CREATE EXTERNAL TABLE dbo.SalesExternal ( OrderId INT, OrderDate DATE, Amount DECIMAL (18, 2), Customer NVARCHAR (100) ) WITH ( DATA_SOURCE = MyAzureStorage, LOCATION = '/data/sales/', FILE_FORMAT = CsvFormat );Passaggio 6: Eseguire una query sulla tabella esterna.
SELECT * FROM dbo.SalesExternal WHERE OrderDate >= '2025-01-01';
Esempio 3: Interrogare una tabella in un'altra istanza di SQL Server
Questo esempio funziona in SQL Server 2019 (15.x) e versioni successive.
Passaggio 1: Creare una chiave master del database (obbligatoria perché le credenziali archivia una password).
CREATE MASTER KEY ENCRYPTION BY PASSWORD = '<strong_password>';Passaggio 2: Creare credenziali per l'istanza remota di SQL Server.
CREATE DATABASE SCOPED CREDENTIAL RemoteSqlCred WITH IDENTITY = 'remote_user', SECRET = '<password>';Passaggio 3: Creare l'origine dati esterna.
CREATE EXTERNAL DATA SOURCE RemoteSqlServer WITH ( LOCATION = 'sqlserver://remote-server.contoso.com', PUSHDOWN = ON, CREDENTIAL = RemoteSqlCred );Passaggio 4: Creare la tabella esterna (nome composto in tre parti in
LOCATION).CREATE EXTERNAL TABLE dbo.RemoteCustomers ( CustomerId INT, CustomerName NVARCHAR (200) COLLATE SQL_Latin1_General_CP1_CI_AS ) WITH ( DATA_SOURCE = RemoteSqlServer, LOCATION = 'SalesDB.dbo.Customers' );Passaggio 5: Interrogare i server.
SELECT c.CustomerName, s.Amount FROM dbo.RemoteCustomers AS c INNER JOIN dbo.LocalSales AS s ON c.CustomerId = s.CustomerId;
Esempio 4: Esportare i risultati in Parquet con CETAS
Funziona in SQL Server 2022 (16.x) e versioni successive, Istanza gestita di SQL di Azure.
Passaggio 1: Abilitare CETAS (solo SQL Server).
EXECUTE sp_configure 'allow polybase export', 1; RECONFIGURE;Passaggio 2: Creare credenziali e origine dati (riutilizzare da esempi precedenti).
Passaggio 3: Creare un formato file per esportare in Parquet.
CREATE EXTERNAL FILE FORMAT ParquetFormat WITH ( FORMAT_TYPE = PARQUET );Passaggio 4: Esportare i risultati delle query.
CREATE EXTERNAL TABLE dbo.Sales2025Export WITH ( DATA_SOURCE = MyAzureStorage, LOCATION = '/exports/sales_2025.parquet', FILE_FORMAT = ParquetFormat ) AS SELECT * FROM Sales.Orders WHERE OrderDate >= '2025-01-01';
Blocchi predefiniti T-SQL per PolyBase
Prima di implementare qualsiasi scenario, comprendere gli oggetti T-SQL di base usati da PolyBase e come interagiscono:
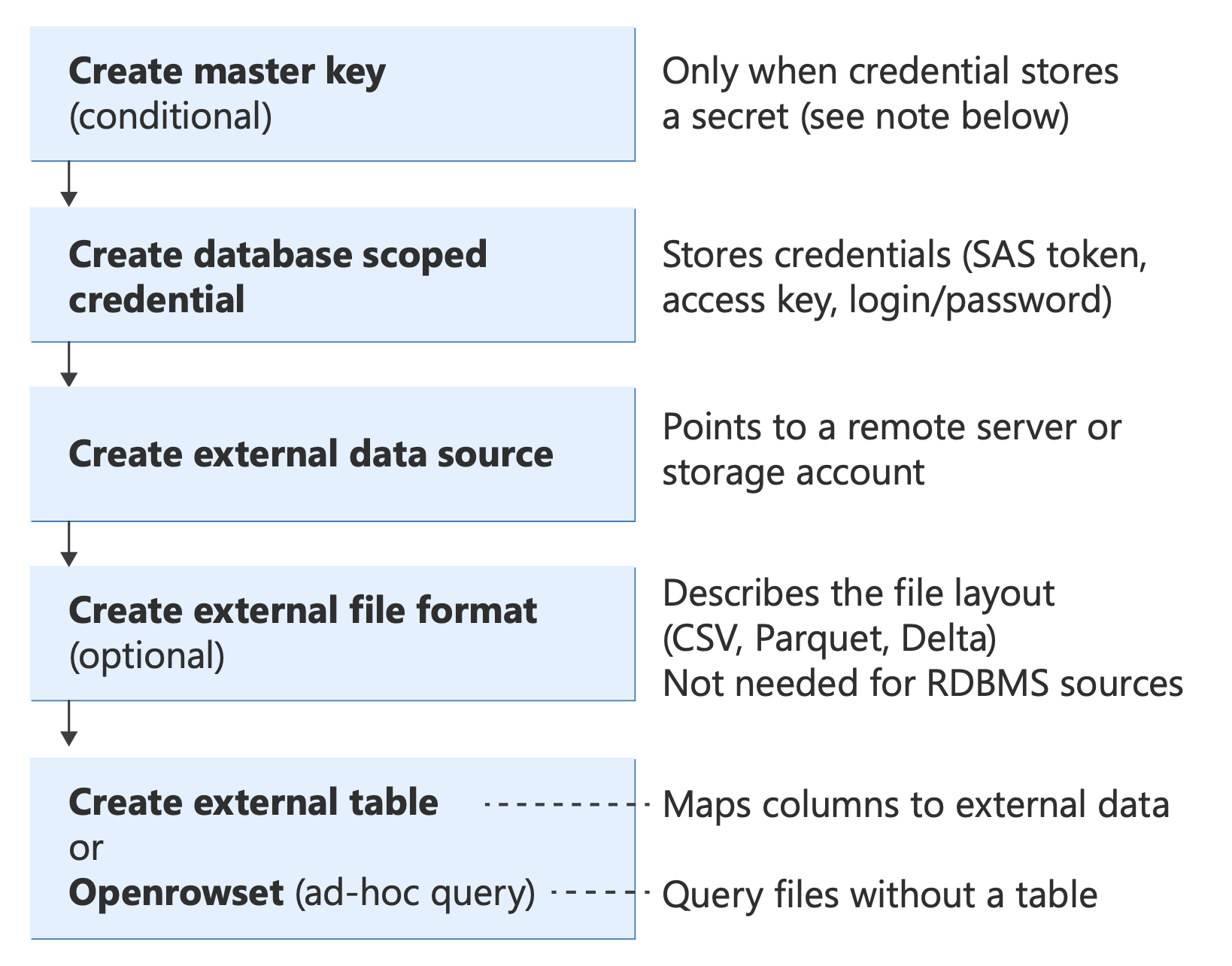
Diagramma che mostra gli oggetti T-SQL PolyBase e le relative relazioni, dall'autenticazione (chiave master del database, credenziali) tramite origini dati e formati di file ai metodi di query (Tabella esterna, OPENROWSET, BULK INSERT, CETAS).
Per informazioni su queste istruzioni T-SQL, vedere:
- CREA ORIGINE DATI ESTERNA
- CREA FORMATO DI FILE ESTERNO
- CREATE EXTERNAL TABLE (Crea tabella esterna)
- OPENROWSET
- CREATE EXTERNAL TABLE AS SELECT (CETAS)
Per informazioni di riferimento complete su Transact-SQL per tutti gli oggetti, vedere Riferimento Transact-SQL PolyBase.
Importante
Verificare la mappatura dei tipi di dati per il formato file esterno. Quando si crea un formato di file esterno o si eseguono query su OPENROWSET, PolyBase esegue automaticamente il mapping dei tipi di dati di origine (Parquet, CSV, Delta, Oracle, Teradata, MongoDB) ai tipi di dati di SQL Server. I tipi non corrispondenti possono causare troncamenti silenziosi, perdita di precisione o errori nelle query. Ad esempio, un file Parquet DECIMAL(38,18) viene mappato su DECIMAL(18,0). Esaminare le tabelle di mappatura prima di definire colonne di tabella esterne o clausola WITH. Per informazioni di riferimento complete, vedere Mapping dei tipi con PolyBase.
Quando è necessario CREATE MASTER KEY?
Viene creata una chiave master del database usando la sintassi CREATE MASTER KEY. La DMK crittografa i segreti archiviati all'interno delle credenziali con ambito nel database. È obbligatorio solo quando la credenziale contiene un valore segreto, ovvero quando archivia una password, un token o una chiave di accesso.
DMK è obbligatorio (le credenziali memorizzano un segreto):
Tipo di autenticazione Valore della proprietà IDENTITYHa un segreto DMK Token di firma di accesso condiviso 'SHARED ACCESS SIGNATURE'Sì Obbligatorio Chiave di accesso S3 'S3 ACCESS KEY'Sì Obbligatorio Accesso SQL/autenticazione di base '<username>'Sì Obbligatorio Chiave di accesso dell'account di archiviazione '<storage_account_name>'Sì Obbligatorio DMK non è obbligatorio (nessun segreto archiviato):
Tipo di autenticazione Valore della proprietà IDENTITYHa un segreto DMK Identità gestita 'Managed Identity'No Non obbligatorio Microsoft Entra ID 'User Identity'oppure'Managed Identity'No Non obbligatorio
Suggerimento
Se non è presente alcun segreto nell'istruzione CREATE DATABASE SCOPED CREDENTIAL , non è necessario un DMK. Identità gestita e microsoft Entra ID delegano l'attendibilità alla piattaforma. Il database non archivia password o token.
Esempi:
In questa query di esempio, la DMK è obbligatoria (la credenziale archivia un token SAS).
CREATE MASTER KEY ENCRYPTION BY PASSWORD = '<strong_password>';
CREATE DATABASE SCOPED CREDENTIAL SasCred
WITH IDENTITY = 'SHARED ACCESS SIGNATURE',
SECRET = '<your_SAS_token>';
In questa query di esempio la DMK non è necessaria (Identità gestita, nessun segreto).
CREATE DATABASE SCOPED CREDENTIAL ManagedIdentityCred
WITH IDENTITY = 'Managed Identity';
In questa query di esempio, la DMK non è necessaria (pass-through di Microsoft Entra, nessun segreto).
CREATE DATABASE SCOPED CREDENTIAL EntraIdCred
WITH IDENTITY = 'User Identity';
Accesso remoto ai dati con OPENROWSET e tabelle esterne
SQL Server offre tre approcci distinti per eseguire query sui dati remoti. È possibile scegliere l'approccio corretto quando si conoscono le differenze nella sintassi, nell'autenticazione e nell'architettura.
| Avvicinarsi | Sintassi | Si connette a | Autenticazione | Servizi PolyBase | Platforms |
|---|---|---|---|---|---|
| Query OLE DB | OPENROWSET(provider, connection, query) |
Qualsiasi origine OLE DB tramite MSOLEDBSQL, SQLOLEDB o altri provider | Autenticazione SQL, autenticazione di Windows, ID Microsoft Entra (MSOLEDBSQL) | No | SQL Server (tutte le versioni supportate) |
| Query di file | OPENROWSET(BULK ...) |
File su disco locale, rete o cloud (BLOB di Azure, ADLS, S3, OneLake) | token SAS, chiave di accesso, identità gestita, Microsoft Entra ID | Sì per il cloud*; No per il locale | SQL Server 2005; SQL Server 2022 (16.x) e versioni successive (cloud); Azure SQL |
| Connettori PolyBase |
CREATE EXTERNAL TABLE con CREATE EXTERNAL DATA SOURCE, sqlserver://, oracle://, teradata://, mongodb://, odbc:// |
Sql Server remoto, Oracle, Teradata, MongoDB, origini ODBC | Solo autenticazione SQL | Sì | SQL Server 2019 (15.x) e versioni successive (Windows); SQL Server 2025 (17.x) e versioni successive (Linux) |
I servizi PolyBase sono necessari per l'accesso ai file cloud in SQL Server 2019 (15.x) e SQL Server 2022 (16.x). SQL Server 2025 (17.x) e versioni successive hanno supporto per i file cloud nativi e non richiedono più PolyBase per CSV, Parquet o Delta.
Quando usare ogni approccio
Usare OLE DB OPENROWSET per:
- Query ad hoc rapide e monouso senza creare oggetti persistenti
- Microsoft Entra ID o autenticazione dell'identità gestita (tramite MSOLEDBSQL)
- Evitare dipendenze del servizio PolyBase
- Connessione a qualsiasi origine dati con un provider OLE DB
Usare File OPENROWSET(BULK) per:
- Esplorazione di file ad hoc e individuazione dello schema
- Trasformazioni rapide e anteprime prima di applicare una definizione di tabella
- Trasformazioni inline delle colonne flessibili (conversione, filtraggio, colonne calcolate)
- Dati che non cambiano di frequente e non richiedono metadati persistenti
Usare i connettori PolyBase con CREATE EXTERNAL TABLE per:
- Definizioni di tabella persistenti riutilizzabili a cui accedono più utenti o applicazioni
- Carichi di lavoro di produzione che richiedono statistiche e ottimizzazione del piano di query
- Spostamento dei calcoli verso origini remote (filtri spinti in Oracle, SQL Server e così via)
- Governance e sicurezza condivise (dopo la creazione, gli utenti necessitano solo dell'autorizzazione
SELECT) - Quando si dispone dell'autenticazione SQL disponibile per l'origine remota
OPENROWSET (OLE DB): query remote ad hoc (nessun servizio PolyBase richiesto)
Il formato OLE DB di OPENROWSET si connette a un'origine dati remota tramite un provider OLE DB, esegue una query pass-through e restituisce i risultati come set di righe. Si tratta di un'alternativa monouso ad hoc a un server collegato. Non vengono creati metadati persistenti. Questa sintassi non richiede servizi PolyBase e non supporta file cloud o origini dati esterne.
Questa query di esempio si connette a un server SQL remoto tramite OLE DB (non PolyBase).
SELECT *
FROM OPENROWSET (
'MSOLEDBSQL',
'Server=remote-server;Database=AdventureWorks;Trusted_Connection=yes;',
'SELECT TOP 10 * FROM AdventureWorks.Sales.SalesOrderHeader'
);
OPENROWSET(BULK) - Interrogazioni basate su file (PolyBase)
Il BULK formato di OPENROWSET legge i dati direttamente dai file. In SQL Server 2019 (15.x) e versioni precedenti legge da percorsi di file LOCALI o UNC e richiede un file di formato. In SQL Server 2022 (16.x) e versioni successive è possibile leggere dall'archiviazione cloud usando i DATA_SOURCE parametri e FORMAT . Questo approccio è la versione integrata di PolyBase usata per la virtualizzazione dei dati.
Nel contesto di PolyBase e della virtualizzazione dei dati, quando si fa riferimento a OPENROWSET, questa guida fa riferimento alla sintassi OPENROWSET(BULK ...) con una clausola FORMAT per eseguire query su file esterni.
Esempi:
L'esempio di query legge un file Parquet da Azure Blob Storage (SQL Server 2022 e versioni successive).
SELECT TOP 10 *
FROM OPENROWSET (
BULK 'data/sales/*.parquet',
DATA_SOURCE = 'MyAzureStorage',
FORMAT = 'PARQUET'
) AS [result];
Questa query di esempio legge un file Parquet con un percorso inline (database SQL di Azure, Istanza gestita di SQL di Azure).
SELECT TOP 10 *
FROM OPENROWSET (
BULK 'abs://mycontainer@mystorageaccount.blob.core.windows.net/data/sales/*.parquet',
FORMAT = 'PARQUET'
) AS [result];
Quando usare OPENROWSET e tabelle esterne
Sia OPENROWSET(BULK ...) sia le tabelle esterne consentono di eseguire query su dati esterni con T-SQL, ma sono progettate per casi d'uso diversi. La tabella seguente riepiloga le differenze principali per decidere quale approccio si adatta allo scenario.
| Capability | OPENROWSET(BULK ...) |
Tabella esterna |
|---|---|---|
| Purpose | Esplorazione ad hoc e query una tantum | Definizione di tabella persistente riutilizzabile |
| Metadati archiviati nel database | No. Nessun elemento viene salvato dopo l'esecuzione della query | Sì. La definizione della tabella, l'origine dati e il formato di file vengono archiviati come oggetti di database |
| Definizione dello schema | Dedotto automaticamente dal file (Parquet) o specificato in linea con una clausola WITH |
Definito in modo esplicito nell'istruzione CREATE EXTERNAL TABLE |
| Autorizzazioni | Richiede ADMINISTER BULK OPERATIONS o ADMINISTER DATABASE BULK OPERATIONS |
Una volta creata, l'autorizzazione standard SELECT per la tabella è sufficiente |
| Colonne calcolate | Sì. Aggiungere espressioni e colonne calcolate nell'elenco SELECT . Le funzioni di metadati come filename() e filepath() sono disponibili solo qui. |
No. Elenco di colonne fisse; eseguire trasformazioni in una vista o nella query che legge la tabella esterna |
| Statistica | Azure SQL: statistiche manuali a colonna singola tramite sys.sp_create_openrowset_statistics; SQL Server 2022 (16.x) e versioni successive: creazione automatica delle statistiche sui predicati (nessuna statistica manuale in SQL Server). Vedere statistiche manuali di OPENROWSET. |
Supporto completo CREATE STATISTICS in tutte le piattaforme, oltre alla creazione automatica in SQL Server 2022 (16.x) e versioni successive. Vedere Creare statistiche manuali della tabella esterna. |
| Pushdown | Supporto limitato. Il motore potrebbe trasferire i filtri fino all'analisi dei file, ma non c'è alcun trasferimento nelle origini remote di database RDBMS. | Sì. Supporta il calcolo pushdown per i connettori RDBMS (SQL Server, Oracle, Teradata, MongoDB) |
| migliore per | Esplorazione dei dati, individuazione dello schema, creazione di prototipi di query, caricamenti di dati monouso, trasformazioni flessibili | Carichi di lavoro di produzione, query ripetute, accesso condiviso tra utenti, dashboard e report |
Usare OPENROWSET quando è necessaria flessibilità
Usare OPENROWSET per esplorare un file, testare schemi diversi o aggiungere colonne e trasformazioni calcolate senza creare oggetti persistenti. Ad esempio, è possibile estrarre il percorso del file come colonna, eseguire il cast dei tipi di dati inline o filtrare le espressioni calcolate in una singola query.
Questa query di esempio include colonne calcolate e trasformazioni:
SELECT result.filename() AS [FileName],
result.filepath(1) AS [Year],
result.filepath(2) AS [Month],
CAST (OrderDate AS DATE) AS OrderDate,
Amount,
OrderDate
FROM OPENROWSET (
BULK 'abs://mycontainer@mystorageaccount.blob.core.windows.net/data/sales/*/*/*/*.parquet',
FORMAT = 'PARQUET'
) AS result
WHERE result.filepath(1) = '2025';
Suggerimento
Le funzioni filepath() e filename() sono disponibili nel database SQL di Azure, in Istanza gestita di Azure SQL e in SQL Server 2022 (16.x) e versioni successive. Consentono di filtrare in base alle parti del percorso del file (eliminazione della partizione) ed esporre il nome del file di origine come colonna, che non è direttamente possibile con le tabelle esterne.
Utilizzare tabelle esterne quando è necessaria la persistenza e la governance
Usare tabelle esterne quando più utenti o applicazioni devono eseguire ripetutamente query negli stessi dati esterni. Definire lo schema, l'origine dati e le credenziali una sola volta e archiviarli nel database. I consumatori necessitano SELECT solo dell'autorizzazione sulla tabella.
Le tabelle esterne supportano anche le statistiche usate da Query Optimizer per creare piani di esecuzione migliori. È possibile creare le statistiche manualmente o consentire al motore di crearle automaticamente (SQL Server 2022 (16.x) e versioni successive.
Questa query di esempio crea statistiche su una tabella esterna per piani di query migliori.
CREATE STATISTICS Stats_OrderDate
ON dbo.SalesExternal(OrderDate)
WITH FULLSCAN;
Per altre informazioni sulle statistiche per entrambi gli approcci, vedere Considerazioni sulle prestazioni di PolyBase - Statistiche.
BULK INSERT e OPENROWSET(BULK): quale è consigliabile usare?
Sia BULK INSERT che OPENROWSET(BULK ...) importano dati da file in SQL Server utilizzando lo stesso motore di caricamento massivo sottostante. Tuttavia, differiscono nella sintassi, nella flessibilità e nelle operazioni che è possibile eseguire con i risultati. Nella tabella seguente sono riepilogate le differenze principali:
Annotazioni
BULK INSERT non è disponibile nel database SQL in Fabric. Per Fabric, usare OPENROWSET(BULK ...) contro OneLake.
| Capability | BULK INSERT |
OPENROWSET(BULK ...) |
|---|---|---|
| Scopo di base | Carica i dati da un file direttamente in una tabella di destinazione | Restituisce un set di righe utilizzato in un'istruzione SELECT o INSERT ... SELECT |
| Modello di utilizzo | Istruzione autonoma: BULK INSERT <table> FROM '<file>' |
Deve essere usato all'interno di una query: SELECT * FROM OPENROWSET(BULK ...) o INSERT INTO <table> SELECT * FROM OPENROWSET(BULK ...) |
| Richiede una tabella di destinazione? | Sì. Scrive sempre direttamente in una tabella | No. È possibile SELECT senza inserirlo in alcuna posizione oppure inserirlo in qualsiasi tabella o tabella temporanea. |
| Trasformazioni delle colonne durante il caricamento | Supporto limitato. I dati passano dal file alla tabella così com'è (mapping controllato dal file di formato o dall'ordine delle colonne) | Supporto completo. È possibile aggiungere espressioni, CASTfiltri WHERE , JOIN altre tabelle e colonne calcolate nell'ambiente circostante SELECT |
| Suggerimenti per la tabella | La WITH clausola include il supporto per BATCHSIZE, CHECK_CONSTRAINTSFIRE_TRIGGERS, KEEPIDENTITY, , KEEPNULLS, TABLOCKe altro ancora |
Supporta hint sulla tabella tramite la sintassi INSERT ... SELECT * FROM OPENROWSET(BULK ...) WITH (TABLOCK, IGNORE_CONSTRAINTS, ...) |
| Importazione a singolo valore di Grandi Oggetti (LOB) | Non supportato | Sì. Supporta SINGLE_BLOB, SINGLE_CLOB, SINGLE_NCLOB per importare un intero file come un valore varbinary(max), varchar(max)o nvarchar(max) |
| Formattare i file | Sì. Supportato tramite (XML e non XML) | Sì. Supportato (XML e non XML) |
| Accesso ai file cloud (Archiviazione BLOB di Azure, ADLS Gen2, S3) | Sì. Supportato tramite DATA_SOURCE il parametro (SQL Server 2017 (14.x) e versioni successive, Azure SQL) |
Sì. Supportato tramite DATA_SOURCE parametro o URL inline con FORMAT clausola (SQL Server 2022 (16.x) e versioni successive, Azure SQL) |
| File Parquet o Delta | Non supportato. Solo testo CSV/delimitato | Sì. Supportato con FORMAT = 'PARQUET' o FORMAT = 'DELTA' (SQL Server 2022 (16.x) e versioni successive, Azure SQL |
| Autorizzazione richiesta |
ADMINISTER BULK OPERATIONS o ADMINISTER DATABASE BULK OPERATIONS, più INSERT nella tabella di destinazione |
ADMINISTER BULK OPERATIONS oppure ADMINISTER DATABASE BULK OPERATIONS |
| Registrazione minima | Sì. Supportato nei modelli di recupero con registrazione minima o registrazione delle operazioni bulk con TABLOCK |
Sì. Supportato quando usato con INSERT ... SELECT e TABLOCK |
Quando scegliere "BULK INSERT"
Usare BULK INSERT quando si dispone di un caricamento semplice da file a tabella e non è necessario trasformare, filtrare o unire i dati durante l'importazione. Usa una sintassi più semplice per csv o altri file delimitati:
Questa query di esempio carica un file CSV da Archiviazione BLOB di Azure direttamente in una tabella.
BULK INSERT Sales.Invoices
FROM 'invoices/inv-2025-01.csv'
WITH (
DATA_SOURCE = 'MyAzureBlobStorage',
FORMAT = 'CSV',
FIRSTROW = 2,
FIELDTERMINATOR = ',',
ROWTERMINATOR = '\n'
);
Questa query di esempio carica un file locale con un file di formato per il mapping delle colonne.
BULK INSERT dbo.Products
FROM 'C:\Data\products.csv'
WITH (
FORMATFILE = 'C:\Data\products.fmt',
FIRSTROW = 2,
TABLOCK
);
Quando scegliere OPENROWSET(BULK)
Usare OPENROWSET(BULK ...) quando sono necessarie una o più delle condizioni seguenti:
- Eseguire query oppure visualizzare in anteprima i dati dei file senza creare una tabella.
- Trasformare, filtrare o unire dati durante l'importazione.
-
Carica file Parquet o Delta (solo
OPENROWSETsupporta questi formati). -
Importare un intero file come singolo valore LOB (
SINGLE_BLOB,SINGLE_CLOB,SINGLE_NCLOB).
Questa query di esempio visualizza in anteprima un file CSV da Azure Blob Storage senza inserire i dati in nessun posto.
SELECT TOP 10 *
FROM OPENROWSET (
BULK 'invoices/inv-2025-01.csv',
DATA_SOURCE = 'MyAzureBlobStorage',
FORMAT = 'CSV',
FIRSTROW = 2,
FIELDTERMINATOR = ','
) AS src;
In questa query di esempio vengono inseriti dati con trasformazione e filtro.
INSERT INTO Sales.Invoices (InvoiceDate, Amount, Customer)
SELECT CAST (InvoiceDate AS DATE),
Amount * 1.1, -- Apply a 10% markup
UPPER(Customer)
FROM OPENROWSET (
BULK 'invoices/inv-2025-01.csv',
DATA_SOURCE = 'MyAzureBlobStorage',
FORMAT = 'CSV',
FIRSTROW = 2
) WITH (
InvoiceDate VARCHAR (10),
Amount DECIMAL (18, 2),
Customer VARCHAR (100)
) AS src
WHERE Amount IS NOT NULL;
Questa query di esempio carica un file Parquet (non possibile con BULK INSERT).
INSERT INTO Sales.Invoices
SELECT *
FROM OPENROWSET (
BULK 'data/invoices/*.parquet',
DATA_SOURCE = 'MyAzureStorage',
FORMAT = 'PARQUET') AS src;
Questa query di esempio importa un intero file XML come singolo valore varbinary(max).
INSERT INTO dbo.XmlDocuments (DocContent)
SELECT BulkColumn
FROM OPENROWSET (
BULK 'C:\Data\catalog.xml',
SINGLE_BLOB
) AS x;
Suggerimento
Un approccio consiste nell'iniziare con OPENROWSET(BULK ...) in un SELECT per esplorare e convalidare i dati dei file, quindi passare a BULK INSERT per il carico di produzione finale, se non sono necessarie trasformazioni. Se hai bisogno del supporto Parquet o Delta o del filtro in-linea, resta con OPENROWSET.
Per altre informazioni, vedere le guide correlate seguenti:
- Usare BULK INSERT o OPENROWSET(BULK...) per importare dati in SQL Server: guida dettagliata affiancata con considerazioni sulla sicurezza.
-
Importazione ed esportazione bulk di dati (SQL Server): panoramica di tutti i metodi di spostamento dei dati in blocco (bcp,
BULK INSERT,OPENROWSET). - BULK INSERT (Transact-SQL): riferimento T-SQL completo.
- OPENROWSET BULK (Transact-SQL): riferimento T-SQL completo.
- Esempi di accesso massivo ai dati in Archiviazione BLOB di Azure: esempi affiancati che utilizzano entrambi i metodi con Archiviazione BLOB di Azure.
-
Importazione bulk di dati di oggetti di grandi dimensioni con il provider di set di righe bulk OPENROWSET (SQL Server):
SINGLE_BLOB,SINGLE_CLOBedSINGLE_NCLOBesempi. - Usare un file di formato per importare in blocco i dati (SQL Server): formattare l'utilizzo dei file con entrambi i metodi.
Funzioni di metadati utili
Quando si eseguono query su file esterni con OPENROWSET o tabelle esterne, è possibile usare diverse funzioni e procedure predefinite per esaminare i metadati dei file, individuare gli schemi e implementare query a conoscenza delle partizioni.
filepath() e filename()
Le filepath() funzioni e filename() restituiscono parti del percorso del file o del nome file per ogni riga nel set di risultati. Sono particolarmente utili per:
Eliminazione delle partizioni: filtra i segmenti di cartella (ad esempio, le partizioni anno/mese/giorno) in modo che il motore legga solo i file corrispondenti invece di analizzare tutti gli elementi.
Esposizione dei metadati di origine: includere il nome o il percorso del file di origine come colonna nei risultati della query, utile per il controllo o il debug.
| Funzione | Restituzioni | Esempio |
|---|---|---|
filename() |
Nome file (incluso l'estensione) del file di origine per ogni riga | sales_2025_01.parquet |
filepath(N) |
Il Nesimo segmento di cartella dal carattere jolly (*) nel percorso BULK, dove N inizia da 1 |
Per il percorso sales/2025/01/*.parquet, filepath(1) restituisce 2025, filepath(2) restituisce 01 |
Si applica a: Database SQL di Azure, Istanza gestita di SQL di Azure, SQL Server 2022 (16.x) e versioni successive, database SQL in Fabric.
Questa query di esempio usa filepath() per l'eliminazione delle partizioni e filename() per identificare i file di origine. Legge solo i file nella /2025/ cartella e legge solo i file nella /06/ sottocartella.
SELECT result.filename() AS SourceFile,
result.filepath(1) AS [Year],
result.filepath(2) AS [Month],
*
FROM OPENROWSET (
BULK 'abs://mycontainer@mystorageaccount.blob.core.windows.net/data/sales/*/*/*.parquet',
FORMAT = 'PARQUET'
) AS result
WHERE result.filepath(1) = '2025'
AND result.filepath(2) = '06';
Suggerimento
Inserire filepath() i filtri nella clausola WHERE anziché in una sottoquery o in un CTE. Quando il filtro si trova nella WHERE clausola , il motore può eseguire l'eliminazione della partizione a livello di analisi dei file, riducendo in modo significativo le operazioni di I/O.
sp_describe_first_result_set - Individuare i tipi di colonna OPENROWSET
Il motore deduce automaticamente i tipi di dati delle colonne quando si usano file Parquet (OPENROWSET) attraverso l'inferenza dello schema. I tipi dedotti potrebbero essere più grandi del necessario. Ad esempio, le colonne di caratteri vengono spesso dedotti come varchar(8000) perché i metadati Parquet non includono una lunghezza massima. Questa scelta può ridurre le prestazioni e consumare più memoria.
Usare sp_describe_first_result_set per esaminare lo schema dedotto prima di finalizzare la query. Dopo aver visualizzato i tipi dedotti, specificare i tipi più stretti in una WITH clausola per migliorare le prestazioni.
Passaggio 1: Esaminare lo schema dedotto.
EXECUTE sp_describe_first_result_set N' SELECT * FROM OPENROWSET( BULK ''abs://mycontainer@mystorageaccount.blob.core.windows.net/data/sales/*.parquet'', FORMAT = ''PARQUET'' ) AS result';L'output mostra il nome di ogni colonna, il tipo di dati dedotto, la lunghezza massima, la precisione e la scala. Se vedi varchar(8000) dove sarebbe sufficiente un varchar(100), sovrascriverlo:
Passaggio 2: Usare tipi espliciti per ottenere prestazioni migliori.
SELECT TOP 100 * FROM OPENROWSET ( BULK 'abs://mycontainer@mystorageaccount.blob.core.windows.net/data/sales/*.parquet', FORMAT = 'PARQUET' ) WITH ( OrderId INT, OrderDate DATE, Amount DECIMAL (18, 2), Customer VARCHAR (100) -- much narrower than the inferred varchar(8000) ) AS result;
L'inferenza dello schema funziona solo con i file Parquet. Per i file CSV, specificare sempre le definizioni di colonna in una WITH clausola (per OPENROWSET) o nell'istruzione CREATE EXTERNAL TABLE .
sp_describe_first_result_set è una procedura generale di SQL Server e SQL di Azure, ma è particolarmente utile per OPENROWSET le query. Per maggiori informazioni, vedi sp_describe_first_result_set.
Prestazioni, risoluzione dei problemi e procedure consigliate
Dopo aver implementato la virtualizzazione dei dati, usare queste guide per ottimizzare le prestazioni, diagnosticare i problemi e garantire la conformità alla produzione:
| Area | Articolo | dettagli |
|---|---|---|
| Prestazioni di PolyBase | Considerazioni sulle prestazioni in PolyBase per SQL Server | Statistiche, pushdown, parallelismo e gestione della memoria |
| Calcolo *pushdown* | Calcoli di pushdown in PolyBase | Specifica quali operazioni eseguono il push sull'origine remota |
| Come stabilire se si è verificato il pushdown | Come stabilire se si è verificato un pushdown esterno | Piani di query e DMV |
| Risoluzione dei problemi | Monitorare e risolvere i problemi di PolyBase | Errori comuni e soluzioni |
| Connettività Kerberos | Risolvere i problemi di connettività di PolyBase Kerberos | |
| Domande frequenti | Domande frequenti su PolyBase | |
| Errori e soluzioni | Errori di PolyBase e possibili soluzioni |