Nota
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare ad accedere o modificare le directory.
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare a modificare le directory.
Questo articolo illustra il funzionamento delle pipeline di integrazione e distribuzione Git per i database con mirroring in Microsoft Fabric. Informazioni su come configurare una connessione al repository, gestire i database con mirroring tramite Git e distribuirli in ambienti diversi.
Integrazione Git con database mirroring
Dalle impostazioni dell'area di lavoro è possibile configurare facilmente una connessione al repository per eseguire il commit e la sincronizzazione delle modifiche. Per configurare la connessione, vedere l'articolo Introduzione all'integrazione con Git .
Dopo la connessione, l'area di lavoro visualizza informazioni sul controllo del codice sorgente che consente di visualizzare il ramo connesso, lo stato di ogni elemento nel ramo e l'ora dell'ultima sincronizzazione.
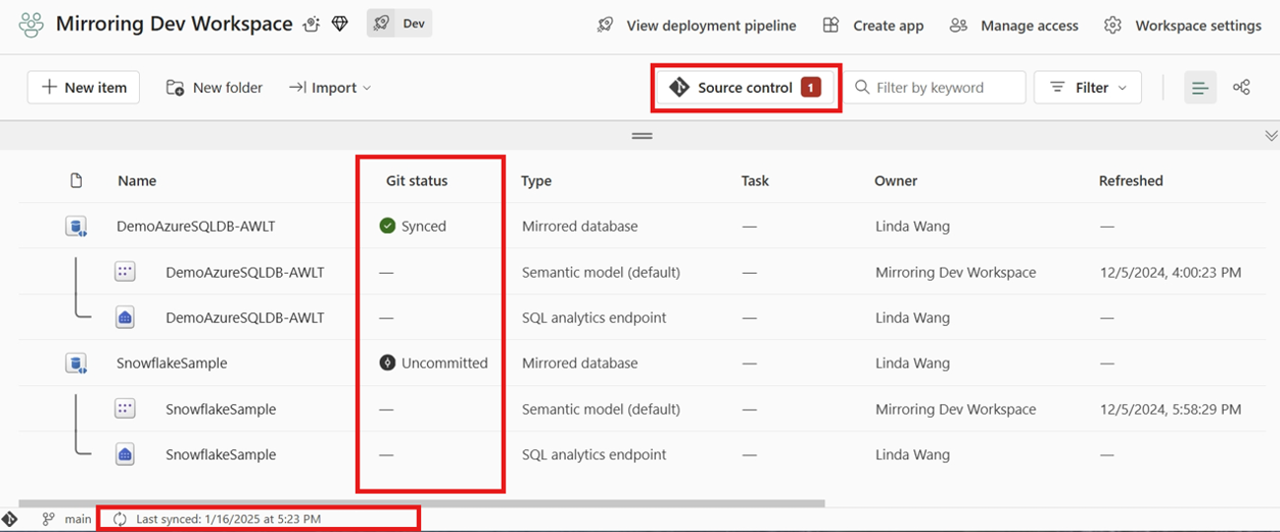
È possibile eseguire il commit delle modifiche del database con mirroring in Git oppure aggiornare l'area di lavoro da Git facendo clic sul controllo Origine.
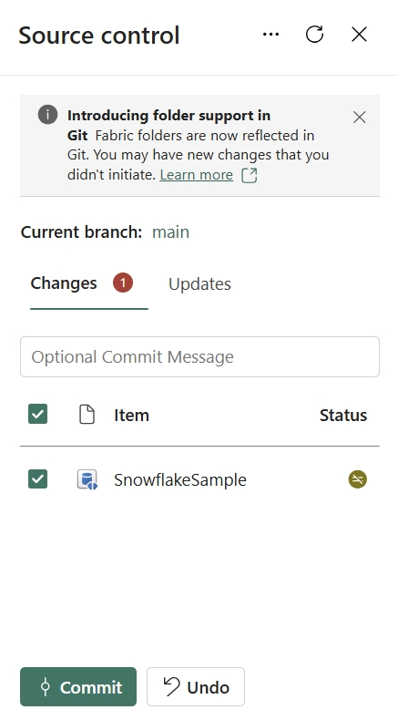
Rappresentazione del database replicato in Git
Quando si esegue il commit dell'elemento del database con mirroring nel repository Git, viene creata una cartella per ogni elemento e denominata {display name}.MirroredDatabase. Contiene due file:
-
mirroring.jsonfile che rappresenta la definizione del database con mirroring. Altre informazioni sulla definizione dell'elemento del database con replica -
.platformfile generato automaticamente dal sistema. Altre informazioni sono disponibili nel file di sistema.
Annotazioni
Solo l'elemento di database replicato è tenuto traccia in Git. Gli endpoint di analisi SQL, le visualizzazioni e altri elementi secondari non vengono rilevati.
Database con mirroring nelle pipeline di distribuzione
È possibile usare la pipeline di distribuzione fabric per distribuire il database con mirroring in ambienti diversi, ad esempio sviluppo, test e produzione. È anche possibile usare le regole di distribuzione per personalizzare i database di origine per il mirroring.
Per distribuire il database con mirroring usando la pipeline di distribuzione, seguire questa procedura:
Creare una pipeline di distribuzione, vedere Introduzione alle pipeline di distribuzione.
Assegnare le aree di lavoro a fasi diverse in base agli obiettivi di distribuzione.
Selezionare, visualizzare e confrontare gli elementi, incluso il database con mirroring tra diverse fasi.
Selezionare Distribuisci per distribuire il database con mirroring tra le fasi. È possibile che venga visualizzato un avviso che indica che l'elemento (endpoint di analisi SQL) non è supportato, ignora e continua

(Facoltativo) Per eseguire il mirroring di un database di origine diverso dalla fase precedente, selezionare Regole di distribuzione per creare regole di distribuzione per un processo di distribuzione. L'elemento delle regole di distribuzione si trova nella fase di destinazione del processo di distribuzione.

Fabric supporta la parametrizzazione del database di origine per ogni elemento del database con mirroring durante la distribuzione con regole di distribuzione. Selezionare il database replicato corrispondente -> Regole origine dati -> + Aggiungi regola, immettere l'ID di connessione di destinazione e, se applicabile, il database in base al tipo di database di origine. È possibile trovare l'ID connessione da Gestisci connessioni e gateway -> trovare la connessione creata dall'elenco -> Impostazioni -> campo ID connessione.
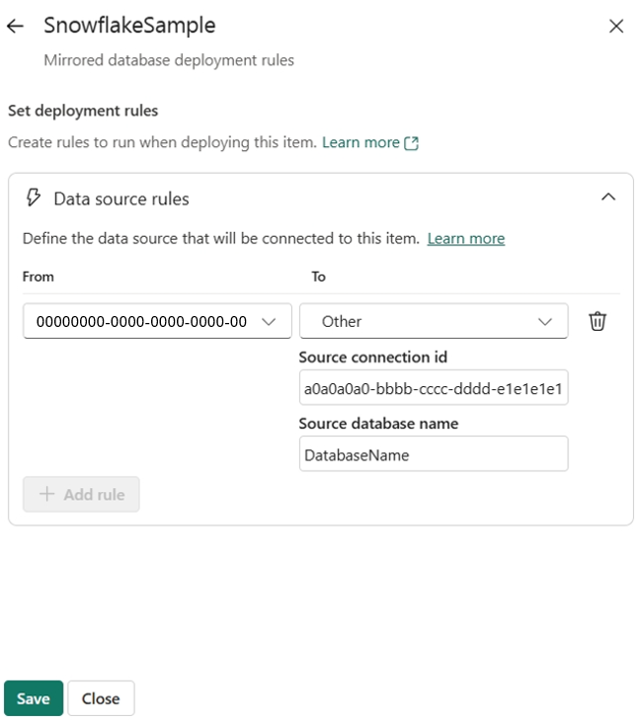
Dopo aver creato le regole di distribuzione, distribuire i database mirroring con le regole appena create dalla fase di origine alla fase di destinazione in cui sono create. Le regole non diventano effettive finché non si distribuisce il database con mirroring dall'origine alla fase di destinazione.
Monitorare lo stato della distribuzione dalla cronologia della distribuzione.
Importante
Il database con mirroring non viene avviato dopo la distribuzione. È necessario avviarlo manualmente o tramite l'API.
Importante
Per eseguire il mirroring dei dati dal database SQL di Azure, Istanza gestita di SQL di Azure, Database di Azure per PostgreSQL o SQL Server 2025, è necessario eseguire le operazioni seguenti prima di avviare il mirroring:
- Abilita l'identità gestita del server logico di Azure SQL, Istanza gestita di Azure SQL, Database di Azure per PostgreSQL, Database di Azure per MySQL o SQL Server 2025.
- Concedere all'identità gestita l'autorizzazione Lettura e Scrittura per il database replicato. Attualmente è necessario eseguire questa operazione nel portale di Fabric. In alternativa, è possibile concedere il ruolo di identità gestita dell'area di lavoro usando l'API di assegnazione ruolo area di lavoro.
Annotazioni
Attualmente, gli elementi figlio come le viste create non vengono distribuiti in più fasi.