Nota
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare ad accedere o modificare le directory.
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare a modificare le directory.
Il mirroring del database in Microsoft Fabric è una tecnologia SaaS aziendale basata sul cloud, senza necessità di ETL. Questa guida aiuta a creare un database speculare da Azure Databricks, il quale genera una copia di sola lettura, sincronizzata in modo continuo, dei dati di Azure Databricks in OneLake.
Prerequisiti
- È necessario abilitare l'accesso ai dati esterni nel metastore. Per altre informazioni, vedere Abilitare l'accesso ai dati esterni nel metastore.
- Creare o usare un'area di lavoro di Azure Databricks esistente con Unity Catalog abilitato.
- È necessario avere il
EXTERNAL USE SCHEMAprivilegio per lo schema in Unity Catalog che contiene le tabelle a cui si accede da Fabric. - È necessario usare il modello di autorizzazioni di Fabric per impostare i controlli di accesso per cataloghi, schemi e tabelle in Fabric.
Creare un database rispecchiato su Azure Databricks
Segui questa procedura per creare un nuovo database con mirroring dal catalogo Unity di Azure Databricks.
Navigare verso https://powerbi.com.
Selezionare + Nuovo e quindi catalogo con mirroring di Azure Databricks.

Selezionare una connessione esistente se ne è stata configurata una.
- Se non si dispone di una connessione esistente, creare una nuova connessione e immettere tutti i dettagli. È possibile eseguire l'autenticazione nell'area di lavoro di Azure Databricks usando "Account aziendale" o "Principale del servizio". Per creare una connessione, è necessario essere un utente o un amministratore dell'area di lavoro di Azure Databricks.
- Per accedere agli account Azure Data Lake Storage (ADLS) Gen2 dietro un firewall, è necessario seguire la procedura per abilitare l'accesso alla sicurezza di rete per l'account Azure Data Lake Storage Gen2 più avanti in questo articolo.
Dopo la connessione a un'area di lavoro di Azure Databricks, nella pagina Scegliere tabelle da un catalogo di Databricks è possibile selezionare il catalogo, gli schemi e le tabelle tramite l'elenco inclusione/esclusione a cui si vuole aggiungere e accedere da Microsoft Fabric. Selezionare il catalogo e i relativi schemi e tabelle da aggiungere all'area di lavoro Fabric.
- È possibile visualizzare solo i cataloghi,gli schemi o le tabelle a cui si ha accesso in base ai privilegi concessi in base al modello di privilegio descritto in Privilegi di Catalogo Unity e oggetti a protezione diretta.
- Per impostazione predefinita, la sincronizzazione automatica delle modifiche future del catalogo per lo schema selezionato è abilitata. Per altre informazioni, vedere Mirroring di Azure Databricks Unity Catalog.
- Dopo aver effettuato le selezioni, selezionare Avanti.
Per impostazione predefinita, il nome dell'elemento sarà il nome del catalogo che si sta tentando di aggiungere a Fabric. Nella pagina Rivedi e crea è possibile esaminare i dettagli e, facoltativamente, modificare il nome dell'elemento del database con mirroring, che deve essere univoco nell'area di lavoro. Fare clic su Crea.
Viene creato un elemento del catalogo di Databricks e per ogni tabella viene creato anche un collegamento di tipo Databricks corrispondente.
- Gli schemi che non dispongono di tabelle non vengono visualizzati.
È anche possibile visualizzare un'anteprima dei dati quando si accede a un collegamento selezionando l'endpoint di analisi SQL. Apri l'elemento dell'endpoint di analisi SQL per avviare la pagina dell'Esploratore e dell'Editor di Query. È possibile eseguire query sulle tabelle replicate di Azure Databricks utilizzando T-SQL nel SQL Editor.
Creare scorciatoie Lakehouse per l'elemento del catalogo Databricks
È anche possibile creare scorciatoie da Lakehouse all'elemento del catalogo di Databricks per utilizzare i dati di Lakehouse e impiegare i notebook Spark.
- Prima di tutto, creiamo una lakehouse. Se si dispone già di una lakehouse in questa area di lavoro, è possibile usare una lakehouse esistente.
- Selezionare l'area di lavoro nel menu di navigazione.
- Selezionare + Nuovo>lakehouse.
- Specificare un nome per il lakehouse nel campo Nome e selezionare Crea.
- Nella visualizzazione Explorer del tuo lakehouse, nel menu Carica dati nel tuo lakehouse , in Carica dati nel tuo lakehouse, selezionare il pulsante Nuovo collegamento.
- Selezionare Microsoft OneLake. Selezionare un catalogo. Si tratta dell'elemento di dati creato nei passaggi precedenti. Quindi seleziona Avanti.
- Selezionare le tabelle all'interno dello schema e selezionare Avanti.
- Fare clic su Crea.
- Le scorciatoie sono ora disponibili nel Lakehouse da usare con gli altri dati Lakehouse. È anche possibile usare Notebook e Spark per eseguire l'elaborazione dei dati sui dati per queste tabelle del catalogo aggiunte dall'area di lavoro di Azure Databricks.
Creazione di un modello semantico
È possibile creare un modello semantico di Power BI basato sull'elemento duplicato e aggiungere/rimuovere manualmente tabelle. Per altre informazioni sulla creazione e la gestione di modelli semantici, vedere Creare un modello semantico di Power BI.
Per un'esperienza ottimale, è consigliabile usare Microsoft Edge Browser per le attività di modellazione semantica.
Gestire le relazioni tra modelli semantici
Dopo aver creato un nuovo modello semantico basato sul database duplicato,
- Seleziona Modello di Layout da Esplora risorse nell'area di lavoro.
- Dopo aver selezionato i layout del modello, viene visualizzato un grafico delle tabelle incluse come parte del modello semantico.
- Per creare relazioni tra tabelle, trascinare un nome di colonna da una tabella a un altro nome di colonna di un'altra tabella. Viene visualizzata una finestra popup per identificare la relazione e la cardinalità per le tabelle.
Abilitare l'accesso alla sicurezza di rete per l'account Azure Data Lake Storage Gen2
Questa sezione illustra come configurare la sicurezza di rete per l'account Azure Data Lake Storage (ADLS) Gen2, quando è configurato un firewall di Archiviazione di Azure .
Prerequisiti
Creare o usare un'area di lavoro di Azure Databricks esistente con Unity Catalog abilitato.
Quando ADLS Gen2 è protetto da un firewall Archiviazione di Azure, Fabric usa l'identità dell'area di lavoro per accedere al firewall. Anche se Service Principal è selezionato per l'autenticazione ADLS nella scheda Network Security, l'identità dell'area di lavoro deve essere autorizzata nel firewall dell'account di archiviazione di Azure.
- L'identità dell'area di lavoro viene usata per l'accesso al firewall di archiviazione. Un'entità servizio o OAuth viene usata per l'autenticazione di Databricks e l'autorizzazione del catalogo Unity.
- Per abilitare il tipo di autenticazione dell'identità dell'area di lavoro (scelta consigliata), l'area di lavoro Fabric deve essere associata a qualsiasi capacità F. Per creare un'identità dell'area di lavoro, vedere Eseguire l'autenticazione con l'identità dell'area di lavoro.
Questa sezione descrive come raggiungere un account di archiviazione di Azure Data Lake Storage (ADLS) Gen2 dietro un firewall di Archiviazione di Azure. L'archiviazione dell'area di lavoro di Azure Databricks non è supportata dietro un firewall di Archiviazione di Azure.
Un catalogo deve essere associato a un singolo account di archiviazione.
Abilitare l'accesso alla sicurezza di rete
Quando si crea un nuovo catalogo con mirroring di Azure Databricks, nel passaggio Scegli dati selezionare la scheda Sicurezza di rete.
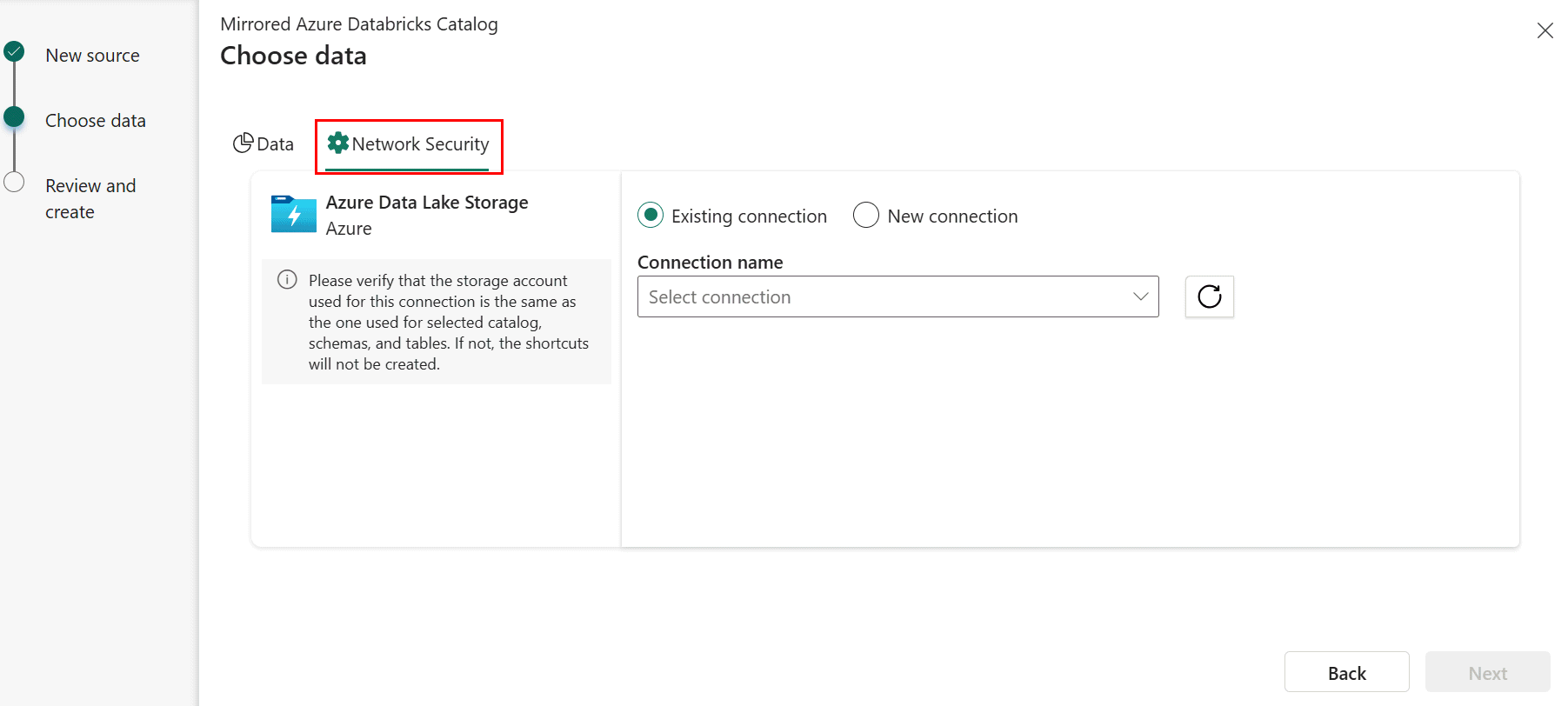
Selezionare una connessione esistente all'account di archiviazione se ne è stata configurata una.
- Se non si dispone di una connessione ADLS esistente, creare una nuova connessione.
-
L'URL dell'endpoint di archiviazione è il punto in cui vengono archiviati i dati del catalogo selezionato. L'endpoint deve essere la cartella specifica in cui sono archiviati i dati, anziché specificare l'endpoint a livello di account di archiviazione. Ad esempio, specificare
https://<storage account>.dfs.core.windows.net/container1/folder1anzichéhttps://<storage account>.dfs.core.windows.net/. - Specificare le credenziali di connessione. I tipi di autenticazione supportati sono account aziendale, principale del servizio e identità dell'area di lavoro (scelta consigliata).
Nel portale di Azure fornire i diritti di accesso all'account di archiviazione in base al tipo di autenticazione selezionato nel passaggio precedente. Vai all'account di archiviazione nel portale di Azure. Selezionare Controllo di accesso (IAM). Selezionare +Aggiungi e Aggiungi assegnazione di ruolo. Per altre informazioni, vedere Assegnare ruoli di Azure tramite il portale di Azure.
- Se hai specificato l'account di archiviazione come parte della connessione, l'oggetto di autenticazione scelto deve possedere il ruolo di Lettore dati BLOB di archiviazione su tale account di archiviazione.
- Se è stato specificato un contenitore specifico come parte della connessione, l'oggetto di autenticazione scelto deve avere il ruolo Lettore dati BLOB di archiviazione nel contenitore.
- Se è stata specificata una cartella specifica all'interno di un contenitore (scelta consigliata), è necessario che l'oggetto di autenticazione read (R) e Execute (E) sia a livello di cartella. Se si usa l'entità servizio o l'identità dell'area di lavoro come tipo di autenticazione, è necessario concedere all'entità servizio o all'identità dell'area di lavoro le autorizzazioni Execute per la cartella radice del contenitore e per ogni cartella nella gerarchia di cartelle che portano alla cartella specificata.
Per altre informazioni e procedure per concedere l'accesso ADLS, vedere Controllo di accesso ADLS.
Abilitare l'accesso all'area di lavoro attendibile per accedere agli account Azure Data Lake Storage (ADLS) Gen2 abilitati per il firewall in modo sicuro. L'accesso all'area di lavoro attendibile richiede la creazione di una connessione diretta all'account di archiviazione ADLS che può essere usato indipendentemente dalla connessione all'area di lavoro di Azure Databricks. Per ulteriori informazioni, consultare le basi di dati con mirroring di Secure Fabric di Azure Databricks.
Viene creato un collegamento alle tabelle del catalogo Unity per le tabelle il cui nome dell'account di archiviazione corrisponde all'account di archiviazione specificato nella connessione ADLS. Per le tabelle il cui nome dell'account di archiviazione non corrisponde all'account di archiviazione specificato nella connessione ADLS, i collegamenti per tali tabelle non verranno creati.
Importante
Se si prevede di usare la connessione ADLS all'esterno degli scenari degli elementi del catalogo Mirrored Azure Databricks, è necessario assegnare anche il ruolo Storage Blob Delegator di archiviazione nell'account di archiviazione.
Abilitare la sicurezza di OneLake nell'elemento Databricks con mirroring
Eseguire il mapping dei criteri di Unity Catalog (UC) alla sicurezza di Microsoft OneLake seguendo questa procedura:
- Sincronizzare il gruppo Entra e applicare le autorizzazioni in Unity Catalog. In Azure Databricks usare Automatic Identity Management per sincronizzare un gruppo microsoft Entra ID e concedergli i privilegi necessari per il catalogo Unity, ad esempio USE, BROWSE, SELECT nel catalogo o nelle tabelle pertinenti.
- Assegnare un ruolo di accesso ai dati OneLake. Nell'area di lavoro Fabric, creare un ruolo di accesso ai dati per i dati appena specchiati. Aggiungere lo stesso gruppo Entra a questo ruolo e concedere i diritti di lettura ai collegamenti OneLake corrispondenti alle tabelle di Azure Databricks. È possibile iniziare subito a usare la sicurezza a livello di tabella nel pulsante Gestisci sicurezza OneLake sulla barra multifunzione. Assicurarsi di mantenere sincronizzate le configurazioni di accesso man mano che le strutture e le autorizzazioni del catalogo si evolvono. Per altre informazioni, vedere il modello di controllo di accesso ai dati OneLake (anteprima).
Contenuti correlati
- Proteggere i database con mirroring di Fabric da Azure Databricks
- Blog: Proteggere i dati di Azure Databricks replicati in Fabric con la sicurezza di OneLake
- Limitazioni nei database replicati di Microsoft Fabric da Azure Databricks
- Domande frequenti per i database a specchio da Azure Databricks in Microsoft Fabric
- Mirroring del catalogo Unity di Azure Databricks
- Controllare l'accesso esterno ai dati in Unity Catalog