Nota
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare ad accedere o modificare le directory.
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare a modificare le directory.
Microsoft Fabric è una soluzione completa di analisi per le aziende che copre tutto il necessario, da spostamento dati ad analisi in tempo reale e business intelligence. Offre una suite completa di servizi, tra cui Data Lake, ingegneria dei dati e integrazione dati, tutto in un'unica posizione. Per altre informazioni, vedere Che cos'è Microsoft Fabric?
Questa esercitazione illustra uno scenario end-to-end dall'acquisizione dei dati all'utilizzo dei dati. Consente di creare una conoscenza di base di Fabric, incluse le diverse esperienze e il modo in cui si integrano, nonché le esperienze di professional e citizen developer fornite con l'uso di questa piattaforma. Questa esercitazione non è progettata per essere un'architettura di riferimento, un elenco completo di funzionalità o un consiglio di procedure consigliate specifiche.
Scenario end-to-end del Lakehouse
Tradizionalmente, le organizzazioni hanno creato data warehouse moderni per le loro esigenze di analisi di dati strutturatli e transazionali. E data lakehouse per le esigenze di analisi dei dati big data (semi-strutturati/non strutturati). Questi due sistemi erano eseguiti in parallelo, creando silo, duplicazione dei dati e aumento del costo totale di proprietà.
Fabric con l'unificazione dell'archivio dati e della standardizzazione nel formato Delta Lake consente di eliminare i silo, rimuovere la duplicazione dei dati e ridurre drasticamente il costo totale di proprietà.
Grazie alla flessibilità offerta da Fabric, è possibile implementare architetture lakehouse o data warehouse oppure combinarle insieme per ottenere il meglio di entrambe con un'implementazione semplice. In questa esercitazione si esaminerà un esempio di organizzazione di vendita al dettaglio e si creerà il relativo lakehouse dall'inizio alla fine. Usa l'architettura medallion in cui il livello bronzo ha i dati non elaborati, il livello argento ha i dati convalidati e deduplicati e il livello oro ha dati estremamente raffinati. È possibile adottare lo stesso approccio per implementare un lakehouse per qualsiasi organizzazione di qualsiasi settore.
Questa esercitazione illustra in che modo uno sviluppatore della società fittizia Wide World Importers nel dominio della vendita al dettaglio completa i passaggi seguenti:
Accedere all'account Power BI e iscriversi per ottenere la versione di valutazione di Microsoft Fabric gratuita. Se non si ha una licenza di Power BI, registrarsi per ottenere una licenza gratuita di Fabric e quindi iniziare la prova gratuita di Fabric.
Creare e implementare un lakehouse end-to-end per la tua organizzazione:
- Creare un'area di lavoro di Fabric.
- Creare un lakehouse.
- Inserire i dati, trasformare i dati e caricarli nel lakehouse. È anche possibile esplorare OneLake, con un'unica copia dei dati utilizzata sia in modalità lakehouse sia in modalità endpoint di Analisi SQL.
- Connettersi al lakehouse usando l'endpoint di analisi SQL e creare un modello semantico e creare un report per analizzare i dati di vendita in dimensioni diverse.
- Facoltativamente, è possibile orchestrare e pianificare il flusso di inserimento e trasformazione dei dati con una pipeline. Le pipeline includono attività incentrate su Lakehouse, ad esempio l'attività di Manutenzione Lakehouse (per automatizzare la manutenzione della tabella Delta con OPTIMIZE e VACUUM) e l'attività Aggiorna endpoint SQL (per mantenere sincronizzato l'endpoint di analisi SQL dopo il caricamento dei dati). Il generatore di espressioni della pipeline include anche l'assistenza di Copilot per la creazione di espressioni più rapide e più accurate. Per dettagli, vedere Lakehouse Maintenance activity.
Pulire le risorse eliminando l'area di lavoro e altri elementi.
Architettura
L'immagine seguente mostra l'architettura end-to-end del Lakehouse. I componenti coinvolti sono descritti nell’elenco seguente.

Origini dati: Fabric semplifica la connessione a Servizi dati di Azure, oltre ad altre piattaforme basate sul cloud e origini dati locali, per semplificare l'inserimento dei dati.
Inserimento: è possibile creare rapidamente informazioni dettagliate per l'organizzazione usando più di 200 connettori nativi. Questi connettori sono integrati nella pipeline di Fabric e utilizzano una trasformazione dati intuitiva e user-friendly, che funziona tramite trascinamento e rilascio all'interno del flusso di dati. Inoltre, con la funzionalità Collegamento in Fabric è possibile connettersi ai dati esistenti senza doverli copiare o spostare. I collegamenti a OneLake possono anche fare riferimento a prodotti di dati tra tenant tramite la condivisione dei dati esterni di OneLake, consentendo di accedere ai dati operativi live e governati senza copiare o compilare pipeline ETL. Fabric include anche lettori di file vettorializzati ad alte prestazioni per formati comuni, ad esempio CSV (con supporto JSON in arrivo) per ridurre la latenza di inserimento.
Trasformazione e archiviazione: Fabric si standardizza sul formato Delta Lake. Ciò implica che tutti i motori di Fabric possono accedere e manipolare lo stesso set di dati archiviato in OneLake senza duplicare i dati. Il modello di governance unificato di OneLake garantisce che i dati a cui si accede tramite collegamenti partecipino agli stessi criteri di sicurezza e conformità dei dati archiviati in locale, fornendo una singola versione di verità nell'intera organizzazione. Questo sistema di archiviazione offre la flessibilità che consente di creare un "lakehouse" usando un'architettura medaglione o una rete di dati, a seconda dei requisiti dell'organizzazione. È possibile scegliere tra un'esperienza con poco codice o senza codice per la trasformazione dei dati, usando pipeline/flussi di dati o notebook/Spark per un'esperienza Code First. Le tabelle Lakehouse supportano anche ottimizzazioni delle prestazioni, ad esempio l'ordinamento Z e il clustering liquid, per migliorare le prestazioni delle query e gestire il layout dei dati su larga scala. Inoltre, le viste materializzate del lago sono disponibili per precomputare e memorizzare nella cache i risultati sui dati lakehouse, velocizzando le analisi ripetute. L'operazionalizzazione può includere la manutenzione automatica delle tabelle Lakehouse Delta tramite l'attività di manutenzione Lakehouse nelle pipeline e l'attivazione di un aggiornamento dell'endpoint di analisi SQL come parte dei passaggi successivi al caricamento. Per informazioni dettagliate, vedere il passaggio facoltativo di orchestrazione della pipeline nella panoramica dello scenario precedente.
Utilizzo: Power BI può usare i dati del lakehouse per la creazione di report e la visualizzazione. Ogni Lakehouse ha un endpoint TDS predefinito, l'endpoint di analisi SQL, per semplificare la connettività e l'esecuzione di query sui dati nelle tabelle Lakehouse da altri strumenti di creazione report. L'orchestrazione della pipeline può includere un passaggio per aggiornare l'endpoint di analisi SQL lakehouse per assicurarsi che lo schema e i metadati siano aggiornati per gli strumenti di creazione di report dopo il caricamento dei dati. Per informazioni dettagliate, vedere il passaggio facoltativo di orchestrazione della pipeline nella panoramica dello scenario precedente.
Tramite la condivisione dei dati tra tenant, i report, i modelli semantici e i carichi di lavoro di intelligenza artificiale/data science possono anche usare dati OneLake condivisi attraverso i limiti dell'organizzazione, consentendo la collaborazione senza duplicazione dei dati.
Set di dati di esempio
Questa esercitazione usa il database di esempio Wide World Importers (WWI) importato nella lakehouse nell'esercitazione successiva. Per lo scenario end-to-end lakehouse, il set di dati include dati sufficienti per esplorare le funzionalità di scalabilità e prestazioni della piattaforma Fabric.
Wide World Importers (WWI) è un importatore e distributore all'ingrosso di articoli di moda operante nell'area della Baia di San Francisco. Essendo WWI un rivenditore all'ingrosso, i suoi clienti sono prevalentemente aziende che rivendono ai singoli. WWI vende ai clienti della rivendita al dettaglio in tutti il Stati Uniti, tra cui negozi specializzati, supermercati, negozi di informatica, negozi di souvenir e alcuni privati. WWI vende anche ad altri rivenditori all'ingrosso tramite una rete di agenti che promuovono i prodotti per suo conto. Per altre informazioni sul profilo e sulle operazioni aziendali, vedere Database di esempio Wide World Importers per Microsoft SQL.
In generale, i dati vengono portati da sistemi transazionali o applicazioni aziendali specifiche in un lakehouse. Tuttavia, per semplicità in questa esercitazione, si usa il modello dimensionale fornito da WWI come origine dati iniziale. I dati vengono acquisiti in un "lakehouse" e trasformati attraverso diverse fasi (Bronzo, Argento e Oro) di un'architettura medallion.
Modello di dati
Mentre il modello dimensionale WWI contiene numerose tabelle dei fatti, questa esercitazione usa la tabella dei fatti Sale e le relative dimensioni correlate. Nell'esempio seguente è illustrato il modello dati di WWI:

Dati e flusso di trasformazione
Come descritto in precedenza, questa esercitazione utilizza i dati di esempio del set di dati campione Wide World Importers (WWI) per costruire un lakehouse completo. In questa implementazione, i dati di esempio vengono archiviati in un account di archiviazione dati di Azure in formato file Parquet per tutte le tabelle. Tuttavia, in scenari reali, genrealmente i dati provengono da varie origini e sono in formati diversi.
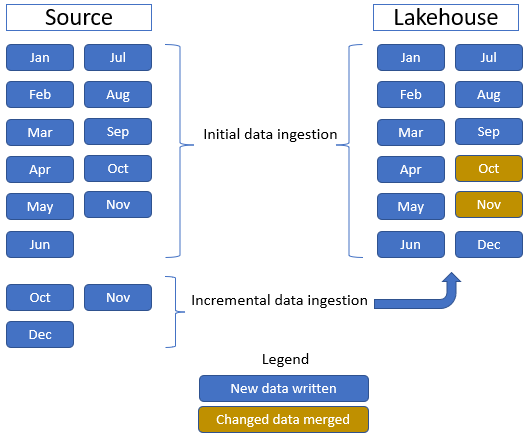
L'immagine seguente mostra l'origine, la destinazione e la trasformazione dei dati:

Origine dati: i dati di origine sono in formato di file Parquet e in una struttura non partizionata. Vengono archiviati in una cartella per ogni tabella. In questa esercitazione configuri una pipeline per acquisire i dati cronologici completi o una tantum nel lakehouse.
In questa esercitazione si usa la tabella di fatti Sale, che contiene una cartella principale con dati cronologici per 11 mesi (con una sottocartella per ogni mese) e un'altra cartella contenente dati incrementali per tre mesi (una sottocartella per ogni mese). Durante l'inserimento iniziale dei dati, vengono inseriti 11 mesi di dati nella tabella lakehouse. Quando arrivano i dati incrementali, i dati aggiornati di ottobre e novembre vengono uniti ai dati esistenti e i nuovi dati di dicembre vengono scritti nella tabella lakehouse, come illustrato nell'immagine seguente:
Lakehouse: in questa esercitazione si crea un lakehouse, si inseriscono i dati nella sezione File del lakehouse e quindi si creano tabelle Delta Lake nella sezione Tabelle del lakehouse.
Trasformazione: per la preparazione e la trasformazione dei dati, questo tutorial illustra due diversi approcci: notebook e Spark per un'esperienza code-first e pipeline e flussi di dati per un'esperienza a basso codice o senza codice. Il runtime più recente di Fabric include un motore di esecuzione nativo che offre miglioramenti significativi delle prestazioni rispetto a Spark open source per i carichi di lavoro di notebook e job Spark. Il generatore di espressioni della pipeline include l'assistenza di Copilot per facilitare la creazione di espressioni e la costruzione della logica della pipeline, garantendo una generazione di espressioni più rapida e accurata.
Utilizzo: Power BI può usare i dati dal lakehouse per la creazione di report e la visualizzazione. Ogni lakehouse ha un endpoint TDS integrato chiamato endpoint di analisi SQL per semplificare la connettività e l'esecuzione di query sui dati nelle tabelle del lakehouse da altri strumenti di reportistica. È anche possibile usare Direct Lake su OneLake per consentire a Power BI di eseguire query direttamente sulle tabelle lakehouse senza importare o un ciclo di aggiornamento del modello semantico dedicato. Inoltre, è possibile rendere disponibili i dati agli strumenti di creazione report non Microsoft usando l'endpoint di analisi TDS/SQL per connettersi ed eseguire query SQL per l'analisi.
Per carichi di lavoro specifici di Spark SQL, i client compatibili con ODBC possono connettersi usando il Microsoft ODBC Driver per Microsoft Fabric Data Engineering (Preview) con autenticazione Microsoft Entra ID (interattiva, interfaccia della riga di comando di Azure, principal di servizio, certificato o token di accesso).
