Nota
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare ad accedere o modificare le directory.
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare a modificare le directory.
Le esperienze di Ingegneria dei dati e Scienza dei dati operano su una piattaforma di calcolo Spark completamente gestita. Per impostazione predefinita, tutti i processi Spark in un'area di lavoro condividono gli stessi pool e le stesse impostazioni delle risorse, ma carichi di lavoro diversi spesso hanno requisiti diversi. Una trasformazione dei dati leggera non richiede la stessa memoria del driver di un processo di Machine Learning su larga scala.
Gli ambienti Fabric consentono di personalizzare la configurazione di calcolo Spark per ogni carico di lavoro, in modo che ogni notebook o definizione del lavoro Spark possa essere eseguito con la giusta versione di runtime, pool e dimensionamento di driver/executor senza modificare le impostazioni predefinite a livello di area di lavoro.
Configurare le impostazioni di calcolo a livello di area di lavoro
Gli amministratori dell'area di lavoro controllano se gli elementi dell'ambiente possono eseguire l'override della configurazione di calcolo predefinita dell'area di lavoro. Mantenere disabilitata la personalizzazione a livello di elemento garantisce un utilizzo coerente delle risorse nell'area di lavoro. L'abilitazione offre ai membri e ai collaboratori la flessibilità necessaria per ottimizzare le risorse di calcolo per i singoli carichi di lavoro.
Nel browser, vai all'area di lavoro Fabric nel portale Fabric.
Selezionare Impostazioni area di lavoro.
Selezionare Ingegneria dati/Scienza e quindi selezionare Impostazioni Spark.
Selezionare la scheda Pool .
Attivare l'opzione Personalizza configurazioni di calcolo per gli elementi su Sì.
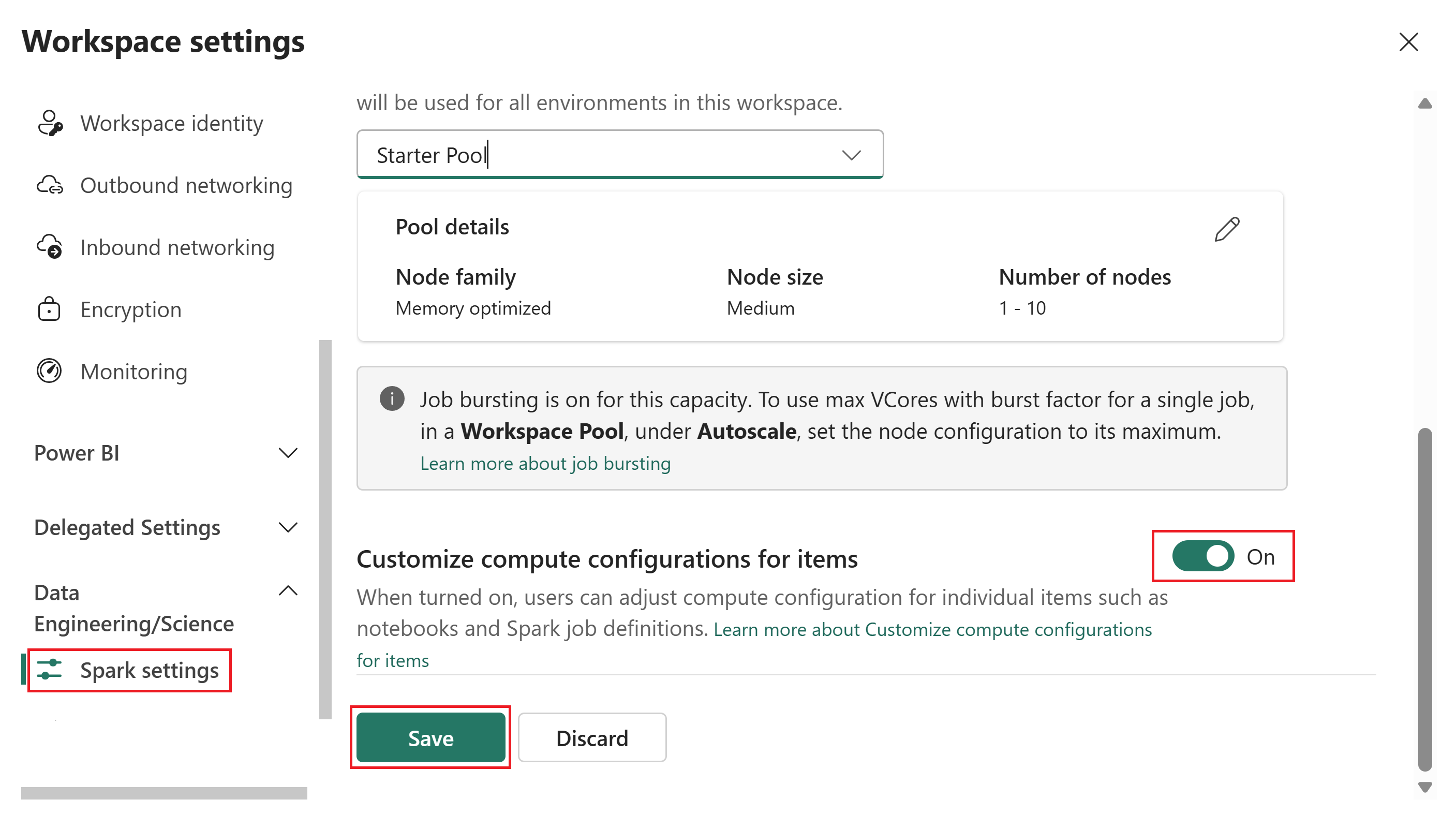
Quando l'interruttore è attivato, i membri e i collaboratori possono modificare le configurazioni di calcolo a livello di sessione in un ambiente fabric. Quando è disattivata, la sezione Calcolo negli elementi dell'ambiente è disabilitata e tutti i processi Spark usano il pool predefinito dell'area di lavoro.
Seleziona Salva.

Configurare il calcolo in un ambiente
Dopo che un amministratore dell'area di lavoro abilita la personalizzazione a livello di elemento, è possibile configurare le impostazioni di calcolo all'interno di un elemento dell'ambiente. Ciò include la scelta di un runtime spark, la selezione di un pool e l'ottimizzazione di risorse driver ed executor.
Selezionare un runtime Spark
Aprire l'elemento dell'ambiente.
Nella scheda Home selezionare l'elenco a discesa Runtime e scegliere una versione di runtime.
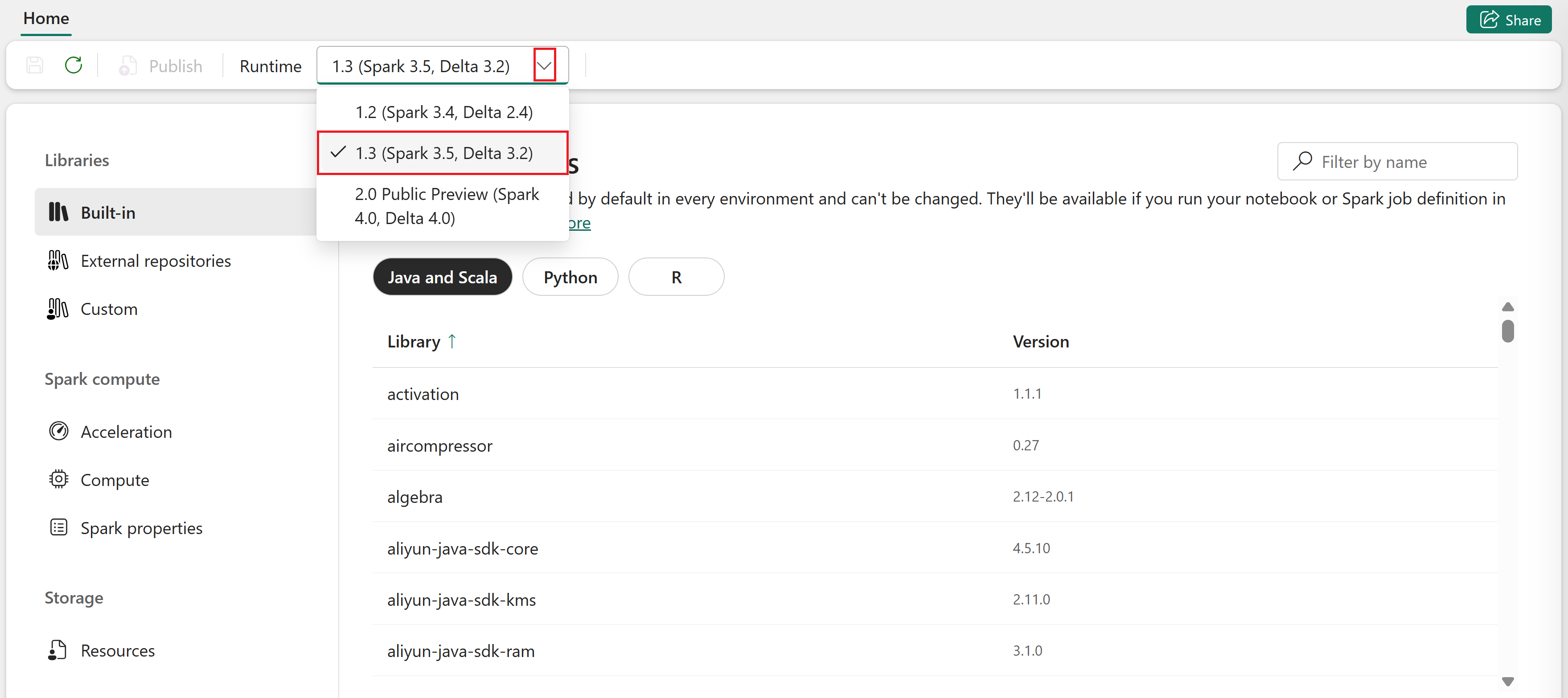

Ogni runtime di Spark ha impostazioni predefinite e pacchetti preinstallati.
Importante
- Le modifiche di runtime non diventano effettive finché non si salva e si pubblica l'ambiente.
- Se le librerie o le impostazioni di calcolo esistenti non sono compatibili con il runtime selezionato, la pubblicazione non riesce. Rimuovere o aggiornare le impostazioni incompatibili e quindi pubblicarla di nuovo.
- Per istruzioni dettagliate sulla pubblicazione, vedere Salvare e pubblicare le modifiche.
Selezionare un pool e ottimizzare le proprietà di calcolo
Aprire l'ambiente e passare alla sezione Calcolo .
Sotto Pool di ambienti, seleziona il pool di avvio o un pool personalizzato creato dall'amministratore dell'area di lavoro.
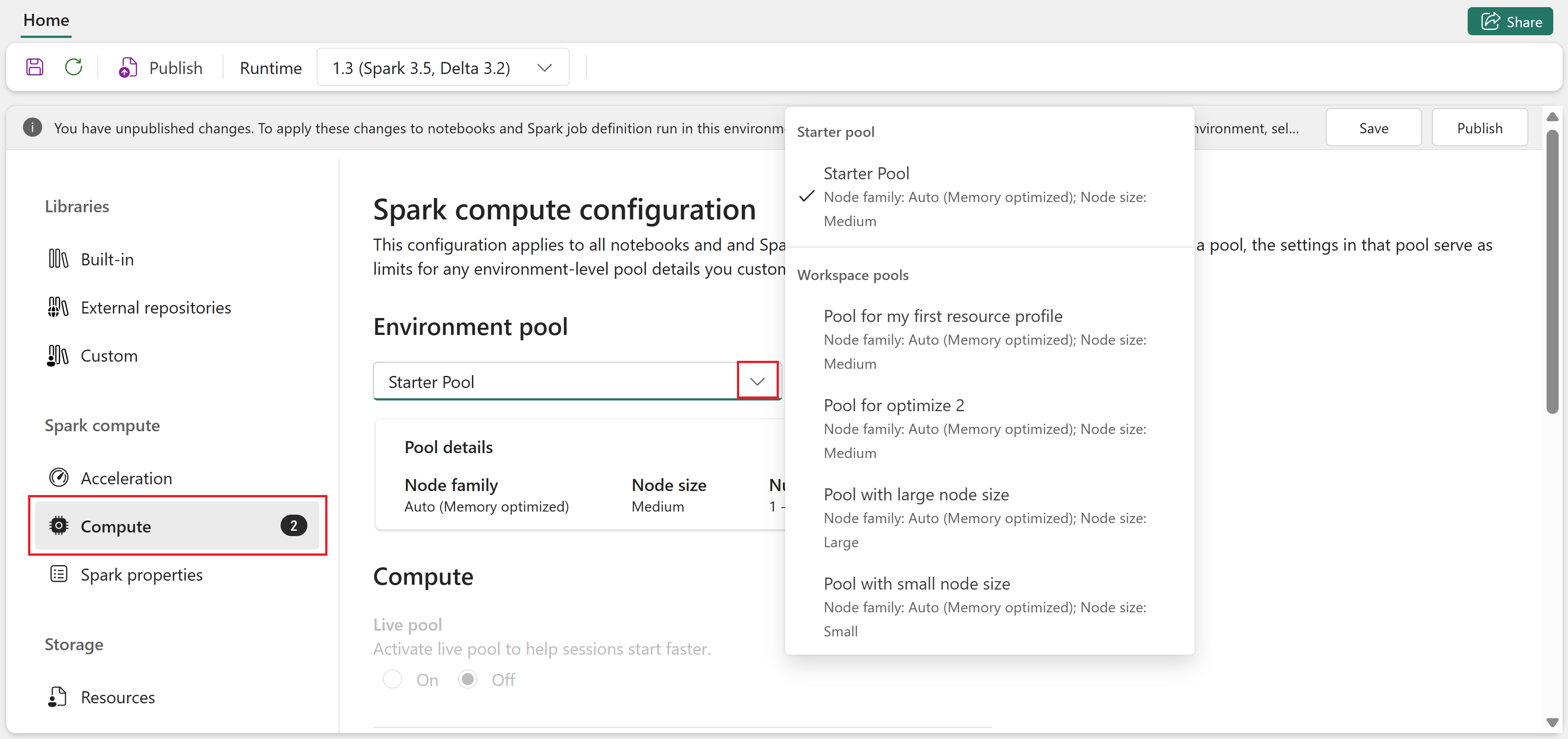
Usare gli elenchi a discesa nella pagina Calcolo per configurare le proprietà Spark a livello di sessione per il pool selezionato. I valori disponibili dipendono dalle dimensioni del nodo del pool.

Proprietà includono:
- Core del driver Spark : numero di core allocati al driver Spark.
- Memoria del driver Spark : quantità di memoria allocata al driver Spark.
- Core dell'executor Spark : numero di core allocati a ogni executor.
- Memoria dell'executor Spark : quantità di memoria allocata a ogni executor.


Per informazioni dettagliate sulle dimensioni del pool disponibili e sui limiti delle risorse, vedere Calcolo Spark in Fabric.
Annotazioni
Le proprietà Spark impostate tramite spark.conf.set non riguardano le impostazioni di calcolo dell'ambiente descritte qui e impostano i parametri a livello dell'applicazione.