Nota
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare ad accedere o modificare le directory.
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare a modificare le directory.
Questo articolo descrive come configurare un cluster Pacemaker di base in Red Hat Enterprise Server (RHEL). Le istruzioni riguardano RHEL 7, RHEL 8 e RHEL 9.
Prerequisiti
Leggere prima di tutto gli articoli e le note SAP seguenti:
Documentazione relativa a RHEL a disponibilità elevata
- Configurazione e gestione di cluster a disponibilità elevata.
- Criteri di supporto per i cluster RHEL a disponibilità elevata - sbd e fence_sbd.
- Criteri di supporto per i cluster RHEL a disponibilità elevata - fence_azure_arm.
- Limitazioni note del watchdog emulato da software.
- Esplorazione dei componenti RHEL a disponibilità elevata - sbd e fence_sbd.
- Indicazioni di progettazione per i cluster RHEL a disponibilità elevata - Considerazioni su sbd.
- Considerazioni sull'adozione di RHEL 8 - Disponibilità elevata e cluster
documentazione RHEL specifica di Azure
Documentazione di RHEL per le offerte SAP
- Criteri di supporto per i cluster RHEL a disponibilità elevata - Gestione di SAP S/4HANA in un cluster.
- Configurazione di SAP S/4HANA ASCS/ERS con il server di accodamento autonomo 2 (ENSA2) in Pacemaker.
- Configurazione della replica di sistema SAP HANA nel cluster Pacemaker.
- Soluzione Red Hat Enterprise Linux con disponibilità elevata per SAP HANA con scalabilità orizzontale e replica del sistema.
Panoramica
Importante
I cluster Pacemaker che si estendono su più reti virtuali/subnet non sono coperti dai criteri di supporto standard.
Sono disponibili due opzioni in Azure per la configurazione dell'isolamento in un cluster pacemaker per RHEL: Azure agente di isolamento, che riavvia un nodo non riuscito tramite le API di Azure oppure è possibile usare il dispositivo SBD.
Importante
In Azure, il cluster RHEL a disponibilità elevata con isolamento basato sull'archiviazione (fence_sbd) usa watchdog emulato dal software. Quando si seleziona SBD come meccanismo di isolamento, è importante rivedere Limitazioni note del watchdog emulato da software e Criteri di supporto per i cluster RHEL a disponibilità elevata - sbd e fence_sbd.
Usare un dispositivo SBD
Note
Il meccanismo di isolamento con SBD è supportato in RHEL 8.8 e versioni successive e in RHEL 9.0 e versioni successive.
Per configurare il dispositivo SBD, è possibile usare una delle due opzioni seguenti:
SBD con server di destinazione iSCSI
Per il dispositivo SBD è necessaria almeno una macchina virtuale (VM) supplementare che possa fungere da server di destinazione iSCSI (Internet Small Computer System Interface) e fornire un dispositivo SBD. Tali server di destinazione iSCSI possono tuttavia essere condivisi con altri cluster Pacemaker. Il vantaggio dei dispositivi SBD è che, se usati a livello locale, non richiedono di apportare alcuna modifica alla modalità di gestione del cluster Pacemaker.
È possibile usare fino a tre dispositivi SBD per un cluster Pacemaker per consentire a un dispositivo SBD di diventare non disponibile (ad esempio, durante l'applicazione di patch del sistema operativo del server di destinazione iSCSI). Per usare più di un dispositivo SBD per Pacemaker, assicurarsi di distribuire più server di destinazione iSCSI e connettere un solo SBD da ogni server di destinazione iSCSI. È consigliabile usare uno o tre dispositivi SBD. Pacemaker non può isolare automaticamente un nodo del cluster se sono configurati solo due dispositivi SBD e uno non è disponibile. Per porre un limite quando un server di destinazione iSCSI è inattivo, è necessario usare tre dispositivi SBD e pertanto tre server di destinazione iSCSI. Questa è la configurazione più resiliente quando si usano SBD.
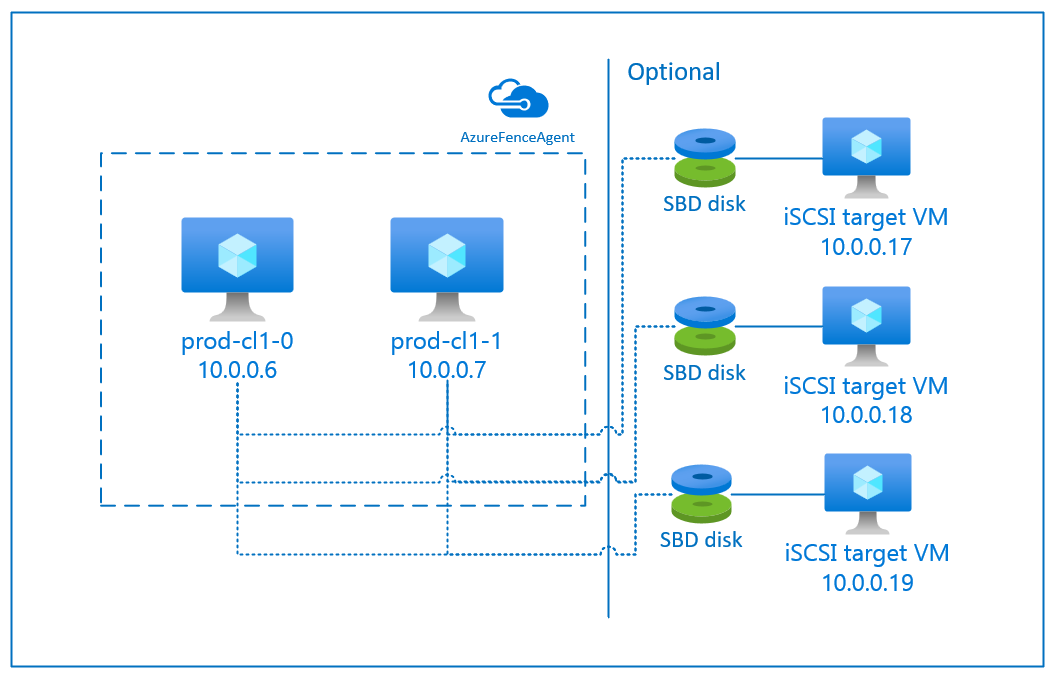
Importante
Quando si prevede di distribuire e configurare nodi del cluster Linux Pacemaker e dispositivi SBD, non consentire al routing tra le proprie macchine virtuali e quelle che ospitano i dispositivi SBD di passare da altri dispositivi, ad esempio un'appliance virtuale di rete.
Gli eventi di manutenzione e altri problemi relativi all'appliance virtuale di rete possono avere un effetto negativo sulla stabilità e sull'affidabilità della configurazione complessiva del cluster. Per altre informazioni, vedere Regole di routing definite dall'utente.
SBD con disco condiviso Azure
Per configurare un dispositivo SBD, è necessario collegare almeno un Azure disco condiviso a tutte le macchine virtuali che fanno parte del cluster pacemaker. Il vantaggio del dispositivo SBD che usa un disco condiviso Azure è che non è necessario distribuire e configurare macchine virtuali aggiuntive.
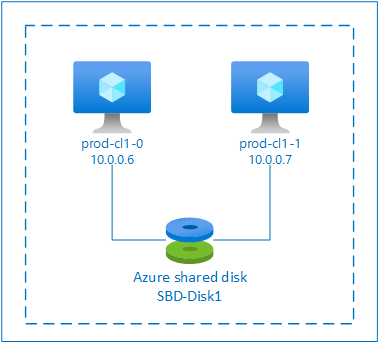
Di seguito sono riportate alcune considerazioni importanti sui dispositivi SBD durante la configurazione tramite Azure disco condiviso:
- Un disco condiviso Azure con SSD Premium è supportato come dispositivo SBD.
- I dispositivi SBD che usano un disco condiviso Azure sono supportati in RHEL 8.8 e versioni successive.
- I dispositivi SBD che usano un disco di condivisione Premium Azure sono supportati in archiviazione con ridondanza locale (LRS) e archiviazione con ridondanza di zona (ZRS).
- A seconda del tipo della distribuzione scegliere l'archiviazione ridondante appropriata per un disco condiviso Azure come dispositivo SBD.
- Un dispositivo SBD che utilizza l'archiviazione con ridondanza locale per un disco condiviso Premium di Azure (skuName - Premium_LRS) è supportato solo con la distribuzione regionale, come un set di disponibilità.
- Un dispositivo SBD che utilizza l'archiviazione con ridondanza della zona (ZRS) per un disco condiviso Premium di Azure (skuName - Premium_ZRS) è consigliato con distribuzione zonale, come una zona di disponibilità o un set di scalabilità con FD=1.
- La ZRS per il disco gestito è attualmente disponibile nelle aree geografiche elencate nel documento relativo alla disponibilità a livello di area.
- Il disco condiviso Azure usato per i dispositivi SBD non deve essere di grandi dimensioni. Il valore maxShares determina il numero di nodi del cluster che possono usare il disco condiviso. Ad esempio, è possibile usare le dimensioni del disco P1 o P2 per il dispositivo SBD in un cluster a due nodi come SAP ASCS/ERS o in modalità scale-up per SAP HANA.
- Per la scalabilità orizzontale di HANA con la replica di sistema HANA (HSR) e pacemaker, è possibile usare un disco condiviso Azure per i dispositivi SBD nei cluster con un massimo di cinque nodi per sito di replica a causa del limite corrente di maxShares.
- Non consigliamo di collegare un dispositivo SBD su disco condiviso di Azure tra cluster pacemaker.
- Se si usano più dispositivi SBD su disco condiviso Azure, verificare il limite per un numero massimo di dischi dati che possono essere collegati a una macchina virtuale.
- Per altre informazioni sulle limitazioni per i dischi condivisi Azure, vedere attentamente la sezione "Limitazioni" di Azure documentazione del disco condiviso.
Usare un agente di limitazione di Azure
È possibile configurare l'isolamento usando un agente di isolamento Azure. L'agente di fencing di Azure richiede identità gestite per le macchine virtuali del cluster oppure un principal di servizio o un'identità del sistema gestito (MSI) che gestisce il riavvio dei nodi non riusciti tramite le API di Azure. L'agente di fence di Azure non richiede la distribuzione di macchine virtuali aggiuntive.
SBD con un server di destinazione iSCSI
Per usare un dispositivo SBD che si serve di un server di destinazione iSCSI per l'isolamento, seguire le istruzioni nelle sezioni successive.
Configurare il server di destinazione iSCSI
Prima di tutto è necessario creare le macchine virtuali per la destinazione iSCSI. È possibile condividere i server di destinazione iSCSI con più cluster Pacemaker.
Distribuire le macchine virtuali in esecuzione nella versione del sistema operativo RHEL supportata ed eseguire la connessione tramite SSH. Le macchine virtuali non devono essere di grandi dimensioni. Ad esempio, sono sufficienti modelli Standard_E2s_v3 o Standard_D2s_v3. Assicurarsi di usare l'archiviazione Premium sul disco del sistema operativo.
Non è necessario usare RHEL per SAP a disponibilità elevata e Update Services o RHEL per l'immagine del sistema operativo delle app SAP per il server di destinazione iSCSI. Al loro posto, è possibile usare un'immagine standard del sistema operativo RHEL. Tuttavia, il ciclo di vita del supporto varia tra le diverse versioni del prodotto del sistema operativo.
Eseguire i comandi seguenti in tutte le macchine virtuali di destinazione iSCSI.
Aggiornare RHEL.
sudo yum -y updateNote
Dopo l'upgrade o l'aggiornamento del sistema operativo potrebbe essere necessario riavviare il nodo.
Installare il pacchetto di destinazione iSCSI.
sudo yum install targetcliAvviare e configurare la destinazione in modo da iniziare all'ora di avvio.
sudo systemctl start target sudo systemctl enable targetAprire una porta
3260nel firewallsudo firewall-cmd --add-port=3260/tcp --permanent sudo firewall-cmd --add-port=3260/tcp
Creare un dispositivo iSCSI nel server di destinazione iSCSI
Per creare i dischi iSCSI per i cluster dei sistemi SAP, eseguire i comandi seguenti in ogni macchina virtuale di destinazione iSCSI. L'esempio illustra la creazione di dispositivi SBD per diversi cluster, dimostrando l'uso di un singolo server di destinazione iSCSI per più cluster. Il dispositivo SBD è configurato sul disco del sistema operativo, quindi occorre assicurarsi che lo spazio sia sufficiente.
- ascsnw1: rappresenta il cluster ASCS/ERS di NW1.
- dbhn1: rappresenta il cluster di database di HN1.
- sap-cl1 e sap-cl2: nomi host dei nodi del cluster NW1 ASCS/ERS.
- hn1-db-0 e hn1-db-1: nomi host dei nodi del cluster di database.
Nelle istruzioni seguenti, modificare il comando con nomi host e SID specifici in base alle esigenze.
Creare la cartella radice per tutti i dispositivi SBD.
sudo mkdir /sbdCreare il dispositivo SBD per i server ASCS/ERS del sistema NW1.
sudo targetcli backstores/fileio create sbdascsnw1 /sbd/sbdascsnw1 50M write_back=false sudo targetcli iscsi/ create iqn.2006-04.ascsnw1.local:ascsnw1 sudo targetcli iscsi/iqn.2006-04.ascsnw1.local:ascsnw1/tpg1/luns/ create /backstores/fileio/sbdascsnw1 sudo targetcli iscsi/iqn.2006-04.ascsnw1.local:ascsnw1/tpg1/acls/ create iqn.2006-04.sap-cl1.local:sap-cl1 sudo targetcli iscsi/iqn.2006-04.ascsnw1.local:ascsnw1/tpg1/acls/ create iqn.2006-04.sap-cl2.local:sap-cl2Creare il dispositivo SBD per il cluster del database del sistema HN1.
sudo targetcli backstores/fileio create sbddbhn1 /sbd/sbddbhn1 50M write_back=false sudo targetcli iscsi/ create iqn.2006-04.dbhn1.local:dbhn1 sudo targetcli iscsi/iqn.2006-04.dbhn1.local:dbhn1/tpg1/luns/ create /backstores/fileio/sbddbhn1 sudo targetcli iscsi/iqn.2006-04.dbhn1.local:dbhn1/tpg1/acls/ create iqn.2006-04.hn1-db-0.local:hn1-db-0 sudo targetcli iscsi/iqn.2006-04.dbhn1.local:dbhn1/tpg1/acls/ create iqn.2006-04.hn1-db-1.local:hn1-db-1Salvare la configurazione targetcli.
sudo targetcli saveconfigVerificare che tutto sia stato configurato correttamente
sudo targetcli ls o- / ......................................................................................................................... [...] o- backstores .............................................................................................................. [...] | o- block .................................................................................................. [Storage Objects: 0] | o- fileio ................................................................................................. [Storage Objects: 2] | | o- sbdascsnw1 ............................................................... [/sbd/sbdascsnw1 (50.0MiB) write-thru activated] | | | o- alua ................................................................................................... [ALUA Groups: 1] | | | o- default_tg_pt_gp ....................................................................... [ALUA state: Active/optimized] | | o- sbddbhn1 ................................................................... [/sbd/sbddbhn1 (50.0MiB) write-thru activated] | | o- alua ................................................................................................... [ALUA Groups: 1] | | o- default_tg_pt_gp ....................................................................... [ALUA state: Active/optimized] | o- pscsi .................................................................................................. [Storage Objects: 0] | o- ramdisk ................................................................................................ [Storage Objects: 0] o- iscsi ............................................................................................................ [Targets: 2] | o- iqn.2006-04.dbhn1.local:dbhn1 ..................................................................................... [TPGs: 1] | | o- tpg1 ............................................................................................... [no-gen-acls, no-auth] | | o- acls .......................................................................................................... [ACLs: 2] | | | o- iqn.2006-04.hn1-db-0.local:hn1-db-0 .................................................................. [Mapped LUNs: 1] | | | | o- mapped_lun0 ............................................................................... [lun0 fileio/sbdhdb (rw)] | | | o- iqn.2006-04.hn1-db-1.local:hn1-db-1 .................................................................. [Mapped LUNs: 1] | | | o- mapped_lun0 ............................................................................... [lun0 fileio/sbdhdb (rw)] | | o- luns .......................................................................................................... [LUNs: 1] | | | o- lun0 ............................................................. [fileio/sbddbhn1 (/sbd/sbddbhn1) (default_tg_pt_gp)] | | o- portals .................................................................................................... [Portals: 1] | | o- 0.0.0.0:3260 ..................................................................................................... [OK] | o- iqn.2006-04.ascsnw1.local:ascsnw1 ................................................................................. [TPGs: 1] | o- tpg1 ............................................................................................... [no-gen-acls, no-auth] | o- acls .......................................................................................................... [ACLs: 2] | | o- iqn.2006-04.sap-cl1.local:sap-cl1 .................................................................... [Mapped LUNs: 1] | | | o- mapped_lun0 ........................................................................... [lun0 fileio/sbdascsers (rw)] | | o- iqn.2006-04.sap-cl2.local:sap-cl2 .................................................................... [Mapped LUNs: 1] | | o- mapped_lun0 ........................................................................... [lun0 fileio/sbdascsers (rw)] | o- luns .......................................................................................................... [LUNs: 1] | | o- lun0 ......................................................... [fileio/sbdascsnw1 (/sbd/sbdascsnw1) (default_tg_pt_gp)] | o- portals .................................................................................................... [Portals: 1] | o- 0.0.0.0:3260 ..................................................................................................... [OK] o- loopback ......................................................................................................... [Targets: 0]
Configurare il dispositivo SBD del server di destinazione iSCSI
[A]: si applica a tutti i nodi. [1]: si applica solo al nodo 1. [2]: si applica solo al nodo 2.
Nei nodi del cluster, connettere e trovare il dispositivo iSCSI creato nella sezione precedente. Eseguire i comandi seguenti nei nodi del nuovo cluster che si intende creare.
[A] Installare o aggiornare le utilità dell'iniziatore iSCSI in tutti i nodi del cluster.
sudo yum install -y iscsi-initiator-utils[A] Installare pacchetti cluster e SBD in tutti i nodi del cluster.
sudo yum install -y pcs pacemaker sbd fence-agents-sbd[A] Abilitare il servizio iSCSI.
sudo systemctl enable iscsid iscsi[1] Modificare il nome dell'iniziatore nel primo nodo del cluster.
sudo vi /etc/iscsi/initiatorname.iscsi # Change the content of the file to match the access control ists (ACLs) you used when you created the iSCSI device on the iSCSI target server (for example, for the ASCS/ERS servers) InitiatorName=iqn.2006-04.sap-cl1.local:sap-cl1[2] Modificare il nome dell'iniziatore nel secondo nodo del cluster.
sudo vi /etc/iscsi/initiatorname.iscsi # Change the content of the file to match the access control ists (ACLs) you used when you created the iSCSI device on the iSCSI target server (for example, for the ASCS/ERS servers) InitiatorName=iqn.2006-04.sap-cl2.local:sap-cl2[A] Riavviare il servizio iSCSI per applicare le modifiche.
sudo systemctl restart iscsid sudo systemctl restart iscsi[A] Connettersi ai dispositivi iSCSI. Nell'esempio seguente, 10.0.0.17 è l'indirizzo IP del server di destinazione iSCSI e 3260 è la porta predefinita. Il nome di destinazione
iqn.2006-04.ascsnw1.local:ascsnw1viene elencato quando si esegue il primo comandoiscsiadm -m discovery.sudo iscsiadm -m discovery --type=st --portal=10.0.0.17:3260 sudo iscsiadm -m node -T iqn.2006-04.ascsnw1.local:ascsnw1 --login --portal=10.0.0.17:3260 sudo iscsiadm -m node -p 10.0.0.17:3260 -T iqn.2006-04.ascsnw1.local:ascsnw1 --op=update --name=node.startup --value=automatic[A] Se si usano più dispositivi SBD, connettersi anche al secondo server di destinazione iSCSI.
sudo iscsiadm -m discovery --type=st --portal=10.0.0.18:3260 sudo iscsiadm -m node -T iqn.2006-04.ascsnw1.local:ascsnw1 --login --portal=10.0.0.18:3260 sudo iscsiadm -m node -p 10.0.0.18:3260 -T iqn.2006-04.ascsnw1.local:ascsnw1 --op=update --name=node.startup --value=automatic[A] Se si usano più dispositivi SBD, connettersi anche al terzo server di destinazione iSCSI.
sudo iscsiadm -m discovery --type=st --portal=10.0.0.19:3260 sudo iscsiadm -m node -T iqn.2006-04.ascsnw1.local:ascsnw1 --login --portal=10.0.0.19:3260 sudo iscsiadm -m node -p 10.0.0.19:3260 -T iqn.2006-04.ascsnw1.local:ascsnw1 --op=update --name=node.startup --value=automatic[A] Assicurarsi che i dispositivi iSCSI siano disponibili e annotare i rispettivi nomi. Nell'esempio seguente vengono individuati tre dispositivi iSCSI connettendo il nodo a tre server di destinazione iSCSI.
lsscsi [0:0:0:0] disk Msft Virtual Disk 1.0 /dev/sde [1:0:0:0] disk Msft Virtual Disk 1.0 /dev/sda [1:0:0:1] disk Msft Virtual Disk 1.0 /dev/sdb [1:0:0:2] disk Msft Virtual Disk 1.0 /dev/sdc [1:0:0:3] disk Msft Virtual Disk 1.0 /dev/sdd [2:0:0:0] disk LIO-ORG sbdascsnw1 4.0 /dev/sdf [3:0:0:0] disk LIO-ORG sbdascsnw1 4.0 /dev/sdh [4:0:0:0] disk LIO-ORG sbdascsnw1 4.0 /dev/sdg[A] Recuperare gli ID dei dispositivi iSCSI.
ls -l /dev/disk/by-id/scsi-* | grep -i sdf # lrwxrwxrwx 1 root root 9 Jul 15 20:21 /dev/disk/by-id/scsi-1LIO-ORG_sbdhdb:85d254ed-78e2-4ec4-8b0d-ecac2843e086 -> ../../sdf # lrwxrwxrwx 1 root root 9 Jul 15 20:21 /dev/disk/by-id/scsi-3600140585d254ed78e24ec48b0decac2 -> ../../sdf # lrwxrwxrwx 1 root root 9 Jul 15 20:21 /dev/disk/by-id/scsi-SLIO-ORG_sbdhdb_85d254ed-78e2-4ec4-8b0d-ecac2843e086 -> ../../sdf ls -l /dev/disk/by-id/scsi-* | grep -i sdh # lrwxrwxrwx 1 root root 9 Jul 15 20:21 /dev/disk/by-id/scsi-1LIO-ORG_sbdhdb:87122bfc-8a0b-4006-b538-d0a6d6821f04 -> ../../sdh # lrwxrwxrwx 1 root root 9 Jul 15 20:21 /dev/disk/by-id/scsi-3600140587122bfc8a0b4006b538d0a6d -> ../../sdh # lrwxrwxrwx 1 root root 9 Jul 15 20:21 /dev/disk/by-id/scsi-SLIO-ORG_sbdhdb_87122bfc-8a0b-4006-b538-d0a6d6821f04 -> ../../sdh ls -l /dev/disk/by-id/scsi-* | grep -i sdg # lrwxrwxrwx 1 root root 9 Jul 15 20:21 /dev/disk/by-id/scsi-1LIO-ORG_sbdhdb:d2ddc548-060c-49e7-bb79-2bb653f0f34a -> ../../sdg # lrwxrwxrwx 1 root root 9 Jul 15 20:21 /dev/disk/by-id/scsi-36001405d2ddc548060c49e7bb792bb65 -> ../../sdg # lrwxrwxrwx 1 root root 9 Jul 15 20:21 /dev/disk/by-id/scsi-SLIO-ORG_sbdhdb_d2ddc548-060c-49e7-bb79-2bb653f0f34a -> ../../sdgVengono elencati tre ID dispositivo per ogni dispositivo SBD. È consigliabile usare l'ID che inizia con scsi-3. Nell'esempio precedente, gli ID sono:
- /dev/disk/by-id/scsi-3600140585d254ed78e24ec48b0decac2
- /dev/disk/by-id/scsi-3600140587122bfc8a0b4006b538d0a6d
- /dev/disk/by-id/scsi-36001405d2ddc548060c49e7bb792bb65
[1] Creare il dispositivo SBD.
Usare l'ID del dispositivo iSCSI per creare un nuovo dispositivo SBD nel primo nodo del cluster.
sudo sbd -d /dev/disk/by-id/scsi-3600140585d254ed78e24ec48b0decac2 -1 60 -4 120 createCreare anche il secondo e il terzo dispositivo SBD se si intende usarne più di uno.
sudo sbd -d /dev/disk/by-id/scsi-3600140587122bfc8a0b4006b538d0a6d -1 60 -4 120 create sudo sbd -d /dev/disk/by-id/scsi-36001405d2ddc548060c49e7bb792bb65 -1 60 -4 120 create
[A] Adattare la configurazione di SBD
Aprire il file di configurazione SBD.
sudo vi /etc/sysconfig/sbdModificare la proprietà del dispositivo SBD, abilitare l'integrazione di Pacemaker e modificare la modalità di avvio di SBD.
[...] SBD_DEVICE="/dev/disk/by-id/scsi-3600140585d254ed78e24ec48b0decac2;/dev/disk/by-id/scsi-3600140587122bfc8a0b4006b538d0a6d;/dev/disk/by-id/scsi-36001405d2ddc548060c49e7bb792bb65" [...] SBD_PACEMAKER=yes [...] SBD_STARTMODE=always [...] # # In some cases, a longer delay than the default "msgwait" seconds is needed. So, set a specific delay value, in seconds. See, `man sbd` for more information. SBD_DELAY_START=186 [...]
[A] Eseguire il comando seguente per caricare il modulo
softdog.modprobe softdog[A] Eseguire il comando seguente per assicurarsi che
softdogvenga caricato automaticamente dopo il riavvio di un nodo.echo softdog > /etc/modules-load.d/watchdog.conf systemctl restart systemd-modules-load[A] Quando
SBD_DELAY_STARTè impostato su un valore, ritarda l'avvio del servizio SBD all'avvio. SeTimeoutSecsystemd del servizio SBD mantiene l'impostazione predefinita (90 secondi), il servizio potrebbe raggiungere il timeout prima dell'avvio, quindi è necessario impostare perTimeoutSecun valore maggiore diSBD_DELAY_START.sudo mkdir /etc/systemd/system/sbd.service.d echo -e "[Service]\nTimeoutSec=223" | sudo tee /etc/systemd/system/sbd.service.d/sbd_delay_start.conf sudo systemctl daemon-reload systemctl show sbd | grep -i timeout # TimeoutStartUSec=3min 43s # TimeoutStopUSec=3min 43s # TimeoutAbortUSec=3min 43s
SBD con un disco Azure condiviso
Questa sezione si applica solo se si vuole usare un dispositivo SBD con un disco condiviso Azure.
Configurare Azure disco condiviso con PowerShell
Per creare e collegare un disco condiviso Azure con PowerShell, eseguire le istruzioni seguenti. Per distribuire le risorse usando il Azure CLI o il portale di Azure, è anche possibile fare riferimento a Deploy a ZRS disk.
$ResourceGroup = "MyResourceGroup"
$Location = "MyAzureRegion"
$DiskSizeInGB = 4
$DiskName = "SBD-disk1"
$ShareNodes = 2
$LRSSkuName = "Premium_LRS"
$ZRSSkuName = "Premium_ZRS"
$vmNames = @("prod-cl1-0", "prod-cl1-1") # VMs to attach the disk
# ZRS Azure shared disk: Configure an Azure shared disk with ZRS for a premium shared disk
$zrsDiskConfig = New-AzDiskConfig -Location $Location -SkuName $ZRSSkuName -CreateOption Empty -DiskSizeGB $DiskSizeInGB -MaxSharesCount $ShareNodes
$zrsDataDisk = New-AzDisk -ResourceGroupName $ResourceGroup -DiskName $DiskName -Disk $zrsDiskConfig
# Attach ZRS disk to cluster VMs
foreach ($vmName in $vmNames) {
$vm = Get-AzVM -ResourceGroupName $resourceGroup -Name $vmName
Add-AzVMDataDisk -VM $vm -Name $diskName -CreateOption Attach -ManagedDiskId $zrsDataDisk.Id -Lun 0
Update-AzVM -VM $vm -ResourceGroupName $resourceGroup -Verbose
}
# LRS Azure shared disk: Configure an Azure shared disk with LRS for a premium shared disk
$lrsDiskConfig = New-AzDiskConfig -Location $Location -SkuName $LRSSkuName -CreateOption Empty -DiskSizeGB $DiskSizeInGB -MaxSharesCount $ShareNodes
$lrsDataDisk = New-AzDisk -ResourceGroupName $ResourceGroup -DiskName $DiskName -Disk $lrsDiskConfig
# Attach LRS disk to cluster VMs
foreach ($vmName in $vmNames) {
$vm = Get-AzVM -ResourceGroupName $resourceGroup -Name $vmName
Add-AzVMDataDisk -VM $vm -Name $diskName -CreateOption Attach -ManagedDiskId $lrsDataDisk.Id -Lun 0
Update-AzVM -VM $vm -ResourceGroupName $resourceGroup -Verbose
}
Configurare un dispositivo SBD su disco condiviso Azure
[A] Installare pacchetti cluster e SBD in tutti i nodi del cluster.
sudo yum install -y pcs pacemaker sbd fence-agents-sbd[A] Assicurarsi che il disco collegato sia disponibile.
lsblk # NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINT # sda 8:0 0 4G 0 disk # sdb 8:16 0 64G 0 disk # ├─sdb1 8:17 0 500M 0 part /boot # ├─sdb2 8:18 0 63G 0 part # │ ├─rootvg-tmplv 253:0 0 2G 0 lvm /tmp # │ ├─rootvg-usrlv 253:1 0 10G 0 lvm /usr # │ ├─rootvg-homelv 253:2 0 1G 0 lvm /home # │ ├─rootvg-varlv 253:3 0 8G 0 lvm /var # │ └─rootvg-rootlv 253:4 0 2G 0 lvm / # ├─sdb14 8:30 0 4M 0 part # └─sdb15 8:31 0 495M 0 part /boot/efi # sr0 11:0 1 1024M 0 rom lsscsi # [0:0:0:0] disk Msft Virtual Disk 1.0 /dev/sdb # [0:0:0:2] cd/dvd Msft Virtual DVD-ROM 1.0 /dev/sr0 # [1:0:0:0] disk Msft Virtual Disk 1.0 /dev/sda # [1:0:0:1] disk Msft Virtual Disk 1.0 /dev/sdc[A] Recuperare l'ID dispositivo del disco condiviso collegato.
ls -l /dev/disk/by-id/scsi-* | grep -i sda # lrwxrwxrwx 1 root root 9 Jul 15 22:24 /dev/disk/by-id/scsi-14d534654202020200792c2f5cc7ef14b8a7355cb3cef0107 -> ../../sda # lrwxrwxrwx 1 root root 9 Jul 15 22:24 /dev/disk/by-id/scsi-3600224800792c2f5cc7e55cb3cef0107 -> ../../sdaQuesto è l'ID dispositivo dell'elenco di comandi per il disco condiviso collegato. È consigliabile usare l'ID che inizia con scsi-3. In questo esempio, l'ID è /dev/disk/by-id/scsi-3600224800792c2f5cc7e55cb3cef0107.
[1] Creare il dispositivo SBD
# Use the device ID from step 3 to create the new SBD device on the first cluster node sudo sbd -d /dev/disk/by-id/scsi-3600224800792c2f5cc7e55cb3cef0107 -1 60 -4 120 create[A] Adattare la configurazione di SBD
Aprire il file di configurazione SBD.
sudo vi /etc/sysconfig/sbdModificare la proprietà del dispositivo SBD, abilitare l'integrazione con Pacemaker, modificare la modalità di avvio di SBD e regolare il valore di SBD_DELAY_START.
[...] SBD_DEVICE="/dev/disk/by-id/scsi-3600224800792c2f5cc7e55cb3cef0107" [...] SBD_PACEMAKER=yes [...] SBD_STARTMODE=always [...] # In some cases, a longer delay than the default "msgwait" seconds is needed. So, set a specific delay value, in seconds. See, `man sbd` for more information. SBD_DELAY_START=186 [...]
[A] Eseguire il comando seguente per caricare il modulo
softdog.modprobe softdog[A] Eseguire il comando seguente per assicurarsi che
softdogvenga caricato automaticamente dopo il riavvio di un nodo.echo softdog > /etc/modules-load.d/watchdog.conf systemctl restart systemd-modules-load[A] Quando
SBD_DELAY_STARTè impostato su un valore, ritarda l'avvio del servizio SBD all'avvio. SeTimeoutSecsystemd del servizio SBD mantiene l'impostazione predefinita (90 secondi), il servizio potrebbe raggiungere il timeout prima dell'avvio, quindi è necessario impostare perTimeoutSecun valore maggiore diSBD_DELAY_START.sudo mkdir /etc/systemd/system/sbd.service.d echo -e "[Service]\nTimeoutSec=223" | sudo tee /etc/systemd/system/sbd.service.d/sbd_delay_start.conf sudo systemctl daemon-reload systemctl show sbd | grep -i timeout # TimeoutStartUSec=3min 43s # TimeoutStopUSec=3min 43s # TimeoutAbortUSec=3min 43s
Configurazione dell'agente fence Azure
Il dispositivo di isolamento utilizza un'identità gestita per le risorse di Azure o un'entità servizio per l'autorizzazione in Azure. A seconda del metodo di gestione delle identità, seguire le procedure appropriate:
Configurare la gestione delle identità
Usare l'identità gestita o l'entità servizio.
Per creare un'identità gestita (MSI), creare un'identità gestita assegnata dal sistema per ogni macchina virtuale nel cluster. Se esiste già, viene usata l'identità gestita assegnata dal sistema. Al momento, non usare identità gestite assegnate dall'utente con Pacemaker. Un dispositivo di isolamento, basato sull'identità gestita, è supportato in RHEL 7.9 e RHEL 8.x/RHEL 9.x/RHEL 10.x.
Creare un ruolo personalizzato per l'agente di isolamento
Sia l'identità gestita che l'entità servizio non dispongono delle autorizzazioni per accedere alle risorse Azure per impostazione predefinita. È necessario concedere all'identità gestita o all'entità servizio le autorizzazioni per avviare e arrestare (spegnere) tutte le macchine virtuali del cluster. Se il ruolo personalizzato non è già stato creato, è possibile crearlo usando PowerShell o Azure CLI.
Per il file di input usare il contenuto seguente. È necessario adattare il contenuto alle sottoscrizioni, ovvero sostituire
xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxxxeyyyyyyyy-yyyy-yyyy-yyyy-yyyyyyyyyyyycon gli ID della sottoscrizione. Se si dispone di una sola sottoscrizione, rimuovere la seconda voce inAssignableScopes.{ "Name": "Linux Fence Agent Role", "description": "Allows to power-off and start virtual machines", "assignableScopes": [ "/subscriptions/xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxxx", "/subscriptions/yyyyyyyy-yyyy-yyyy-yyyy-yyyyyyyyyyyy" ], "actions": [ "Microsoft.Compute/*/read", "Microsoft.Compute/virtualMachines/powerOff/action", "Microsoft.Compute/virtualMachines/start/action" ], "notActions": [], "dataActions": [], "notDataActions": [] }Assegnare il ruolo personalizzato
Usare l'identità gestita o l'entità servizio.
Assegnare il ruolo personalizzato
Linux Fence Agent Rolecreato nell'ultima sezione a ogni identità gestita delle macchine virtuali del cluster. Ogni identità gestita assegnata dal sistema della macchina virtuale richiede il ruolo assegnato per ogni risorsa della macchina virtuale del cluster. Per altre informazioni, vedere Assegnare a una risorsa l'accesso a un'identità gestita usando il portale di Azure. Verificare che l'assegnazione di ruolo dell'identità gestita di ogni macchina virtuale contenga tutte le macchine virtuali del cluster.Importante
Tenere presente che l'assegnazione e la rimozione dell'autorizzazione con identità gestite possono essere ritardate fino a quando non sono effettive.
Installazione del cluster
Le differenze nei comandi o nella configurazione tra RHEL 7 e RHEL 8/RHEL 9 sono contrassegnate nel documento.
[A] Installare il componente aggiuntivo RHEL a disponibilità elevata.
sudo yum install -y pcs pacemaker nmap-ncat[A] In RHEL 9.x, installare gli agenti di risorse per la distribuzione cloud.
sudo yum install -y resource-agents-cloud[A] Installare il pacchetto fence-agents se si usa un dispositivo di isolamento basato su Azure agente di isolamento.
sudo yum install -y fence-agents-azure-armImportante
È consigliabile usare le versioni seguenti del "fence agent" di Azure (o versioni successive) per i clienti che vogliono utilizzare le identità gestite per le risorse di Azure anziché i nomi principali del servizio per il "fence agent":
- RHEL 8.4: fence-agents-4.2.1-54.el8.
- RHEL 8.2: fence-agents-4.2.1-41.el8_2.4
- RHEL 8.1: fence-agents-4.2.1-30.el8_1.4
- RHEL 7.9: fence-agents-4.2.1-41.el7_9.4.
Importante
In RHEL 9 è consigliabile usare le versioni del pacchetto seguenti (o versioni successive) per evitare problemi con l'agente di isolamento Azure:
- fence-agents-4.10.0-20.el9_0.7
- fence-agents-common-4.10.0-20.el9_0.6
- ha-cloud-support-4.10.0-20.el9_0.6.x86_64.rpm
Controllare la versione dell'agente di isolamento di Azure. Se necessario, aggiornarlo alla versione minima richiesta o successiva.
# Check the version of the Azure Fence Agent sudo yum info fence-agents-azure-armImportante
Se è necessario aggiornare l'agente di isolamento Azure e, se si usa un ruolo personalizzato, assicurarsi di aggiornare il ruolo personalizzato per includere l'azione powerOff. Per altre informazioni, vedere Creare un ruolo personalizzato per l'agente di isolamento.
[A] Configurare la risoluzione dei nomi host.
È possibile usare un server DNS o modificare il file
/etc/hostsin tutti i nodi. In questo esempio viene illustrato come usare il file/etc/hosts. Sostituire l'indirizzo IP e il nome host nei comandi seguenti.Importante
Se si usano nomi host nella configurazione del cluster, è fondamentale avere una risoluzione affidabile dei nomi host. La comunicazione del cluster ha esito negativo se i nomi non sono disponibili, il che può causare ritardi di failover del cluster.
Il vantaggio dell'uso di
/etc/hostsè che il cluster diventa indipendente dal DNS, che potrebbe essere anche un singolo punto di errore.sudo vi /etc/hostsInserire le righe seguenti prima di
/etc/hosts. Modificare l'indirizzo IP e il nome host in base all'ambiente.# IP address of the first cluster node 10.0.0.6 prod-cl1-0 # IP address of the second cluster node 10.0.0.7 prod-cl1-1[A] Modificare la password di
haclusterin modo da usare la stessa password.sudo passwd hacluster[A] Aggiungere regole di firewall per Pacemaker.
Aggiungere le seguenti regole del firewall per tutte le comunicazioni del cluster tra i nodi del cluster.
sudo firewall-cmd --add-service=high-availability --permanent sudo firewall-cmd --add-service=high-availability[A] Abilitare i servizi cluster di base.
Eseguire i comandi seguenti per abilitare il servizio Pacemaker e avviarlo.
sudo systemctl start pcsd.service sudo systemctl enable pcsd.service[1] Creare un cluster Pacemaker.
Eseguire i comandi seguenti per autenticare i nodi e creare il cluster. Impostare il token su 30000 per consentire la manutenzione con mantenimento della memoria. Per altre informazioni, vedere questo articolo per Linux.
Se si sta creando un cluster in RHEL 7.x, usare i comandi seguenti:
sudo pcs cluster auth prod-cl1-0 prod-cl1-1 -u hacluster sudo pcs cluster setup --name nw1-azr prod-cl1-0 prod-cl1-1 --token 30000 sudo pcs cluster start --allSe si sta creando un cluster in RHEL 8.x/RHEL 9.x/RHEL 10.x, usare i comandi seguenti:
sudo pcs host auth prod-cl1-0 prod-cl1-1 -u hacluster sudo pcs cluster setup nw1-azr prod-cl1-0 prod-cl1-1 totem token=30000 sudo pcs cluster start --allVerificare lo stato del cluster eseguendo il comando seguente:
# Run the following command until the status of both nodes is online sudo pcs status # Cluster name: nw1-azr # WARNING: no stonith devices and stonith-enabled is not false # Stack: corosync # Current DC: prod-cl1-1 (version 1.1.18-11.el7_5.3-2b07d5c5a9) - partition with quorum # Last updated: Fri Aug 17 09:18:24 2018 # Last change: Fri Aug 17 09:17:46 2018 by hacluster via crmd on prod-cl1-1 # # 2 nodes configured # 0 resources configured # # Online: [ prod-cl1-0 prod-cl1-1 ] # # No resources # # Daemon Status: # corosync: active/disabled # pacemaker: active/disabled # pcsd: active/enabled[A] Impostare i voti previsti.
# Check the quorum votes pcs quorum status # If the quorum votes are not set to 2, execute the next command sudo pcs quorum expected-votes 2Suggerimento
Se si sta creando un cluster multinodo, ovvero un cluster con più di due nodi, non impostare i voti su 2.
[1] Consenti azioni di isolamento simultanee.
sudo pcs property set concurrent-fencing=true
Creare un dispositivo di isolamento nel cluster Pacemaker
Suggerimento
- Per evitare corse di isolamento all'interno di un cluster Pacemaker a due nodi, è possibile configurare la proprietà del cluster
priority-fencing-delay. Questa proprietà introduce un ulteriore ritardo nell'isolamento di un nodo con priorità totale più elevata quando si verifica uno scenario split-brain. Per altre informazioni, vedere Pacemaker può isolare il nodo del cluster con il minor numero di risorse in esecuzione? - La proprietà
priority-fencing-delayè applicabile per Pacemaker versione 2.0.4-6.el8 o successiva e in un cluster a due nodi. Se si configura la proprietà del clusterpriority-fencing-delay, non è necessario impostare la proprietàpcmk_delay_max. Tuttavia, se la versione di Pacemaker è minore di 2.0.4-6.el8, è necessario impostare la proprietàpcmk_delay_max. - Per istruzioni su come impostare la proprietà del cluster
priority-fencing-delay, vedere i rispettivi documenti SAP ASCS/ERS e Disponibilità elevata per la scalabilità verticale SAP HANA
In base al meccanismo di isolamento selezionato, seguire una sola sezione per istruzioni pertinenti: SBD come dispositivo di isolamento o Agente di limitazione di Azure come dispositivo di isolamento.
SBD come dispositivo di isolamento
[A] Abilitare il servizio SBD
sudo systemctl enable sbd[1] Per il dispositivo SBD configurato usando server di destinazione iSCSI o Azure disco condiviso, eseguire i comandi seguenti.
sudo pcs property set stonith-timeout=210 sudo pcs property set stonith-enabled=true # Replace the device IDs with your device ID. pcs stonith create sbd fence_sbd \ devices=/dev/disk/by-id/scsi-3600140585d254ed78e24ec48b0decac2,/dev/disk/by-id/scsi-3600140587122bfc8a0b4006b538d0a6d,/dev/disk/by-id/scsi-36001405d2ddc548060c49e7bb792bb65 \ op monitor interval=600 timeout=15[1] Riavviare il cluster
sudo pcs cluster stop --all # It would take time to start the cluster as "SBD_DELAY_START" is set to "yes" sudo pcs cluster start --allNote
Se si riscontra l'errore seguente durante l'avvio del cluster Pacemaker, è possibile ignorare il messaggio. In alternativa, è possibile avviare il cluster usando il comando
pcs cluster start --all --request-timeout 140.Errore: impossibile avviare tutti i nodi node1/node2: impossibile connettersi a node1/node2, verificare se pcsd è in esecuzione o provare a impostare un timeout maggiore con l'opzione
--request-timeout(operazione scaduta dopo 60.000 millisecondi con 0 byte ricevuti)
Agente di limitazione di Azure come dispositivo di isolamento
[1] Dopo aver assegnato ruoli a entrambi i nodi del cluster, è possibile configurare i dispositivi di isolamento nel cluster.
sudo pcs property set stonith-timeout=900 sudo pcs property set stonith-enabled=true[1] Eseguire il comando appropriato a seconda che si usi un'identità gestita o un'entità servizio per l'agente di limitazione di Azure.
Note
Quando si usa Azure per enti governativi, è necessario specificare l'opzione
cloud=durante la configurazione dell'agente di fence. Ad esempio,cloud=usgovper il cloud del governo degli Stati Uniti Azure. Per informazioni dettagliate sulle politiche di supporto di RedHat nel cloud Azure Government Cloud, vedere Politiche di supporto per i cluster ad alta disponibilità RHEL - Macchine virtuali Microsoft Azure come membri del cluster.Suggerimento
L'opzione
pcmk_host_mapè only necessaria nel comando se i nomi host RHEL e i nomi delle macchine virtuali Azure non sono identici. Specificare il mapping nel formato nome host:vm-name. Per altre informazioni, vedere Quale formato usare per specificare i mapping dei nodi ai dispositivi di isolamento in pcmk_host_map?Per RHEL 7.x, usare il comando seguente per configurare il dispositivo di isolamento:
sudo pcs stonith create rsc_st_azure fence_azure_arm msi=true resourceGroup="resource group" \ subscriptionId="subscription id" pcmk_host_map="prod-cl1-0:prod-cl1-0-vm-name;prod-cl1-1:prod-cl1-1-vm-name" \ power_timeout=240 pcmk_reboot_timeout=900 pcmk_monitor_timeout=120 pcmk_monitor_retries=4 pcmk_action_limit=3 pcmk_delay_max=15 \ meta failure-timeout=120s \ op monitor interval=3600Per RHEL 8.x/9.x/10.x, usare il comando seguente per configurare il dispositivo di isolamento:
# Run following command if you are setting up fence agent on (two-node cluster and pacemaker version greater than 2.0.4-6.el8) OR (HANA scale out) sudo pcs stonith create rsc_st_azure fence_azure_arm msi=true resourceGroup="resource group" \ subscriptionId="subscription id" pcmk_host_map="prod-cl1-0:prod-cl1-0-vm-name;prod-cl1-1:prod-cl1-1-vm-name" \ power_timeout=240 pcmk_reboot_timeout=900 pcmk_monitor_timeout=120 pcmk_monitor_retries=4 pcmk_action_limit=3 \ meta failure-timeout=120s \ op monitor interval=3600 # Run following command if you are setting up fence agent on (two-node cluster and pacemaker version less than 2.0.4-6.el8) sudo pcs stonith create rsc_st_azure fence_azure_arm msi=true resourceGroup="resource group" \ subscriptionId="subscription id" pcmk_host_map="prod-cl1-0:prod-cl1-0-vm-name;prod-cl1-1:prod-cl1-1-vm-name" \ power_timeout=240 pcmk_reboot_timeout=900 pcmk_monitor_timeout=120 pcmk_monitor_retries=4 pcmk_action_limit=3 pcmk_delay_max=15 \ meta failure-timeout=120s \ op monitor interval=3600
Se si usa un dispositivo di isolamento basato sulla configurazione dell'entità servizio, leggere Modificare da SPN a MSI per i cluster Pacemaker usando l'isolamento di Azure per scoprire come passare alla configurazione dell'identità gestita.
Le operazioni di monitoraggio e isolamento vengono deserializzate. Di conseguenza, in caso di simultaneità tra un evento di isolamento e un'operazione di monitoraggio più lunga, non si verifica alcun ritardo per il failover del cluster perché l'operazione di monitoraggio è già in esecuzione.
Suggerimento
L'Azure fence agent richiede la connettività in uscita agli endpoint pubblici. Per altre informazioni e per le possibili soluzioni, vedere Connettività dell'endpoint pubblico per le macchine virtuali che usano il servizio di bilanciamento del carico interno standard.
Configurare Pacemaker per gli eventi pianificati Azure
Azure offre eventi pianificati. Gli eventi pianificati vengono inviati tramite il servizio metadati e lasciano all'applicazione il tempo di prepararsi per tali eventi.
L'agente di risorse azure-events-az monitora gli eventi Azure pianificati. Se vengono rilevati eventi e l'agente di risorse determina che è disponibile un altro nodo del cluster, imposta un attributo #health-azure di integrità a livello di nodo su -1000000.
Quando questo speciale attributo di integrità del cluster è impostato per un nodo, il nodo viene considerato non integro dal cluster e tutte le risorse vengono migrate dal nodo interessato. Il vincolo di localizzazione garantisce che le risorse il cui nome inizia con "health-" vengano escluse, poiché l'agente deve essere eseguito in questo stato di errore. Quando il nodo del cluster interessato è libero di eseguire risorse cluster, l'evento pianificato può eseguire l'azione, ad esempio il riavvio, senza rischi per l'esecuzione delle risorse.
L'#heath-azureattributo viene ripristinato su 0 all'avvio di pacemaker, una volta elaborati tutti gli eventi, contrassegnando nuovamente il nodo come sano.
[A] Assicurarsi che il pacchetto per l'agente
azure-events-azsia già installato e aggiornato.RHEL 8.x: sudo dnf info resource-agents RHEL 9.x: sudo dnf info resource-agents-cloudRequisiti minimi per la versione:
- RHEL 8.4:
resource-agents-4.1.1-90.13 - RHEL 8.6:
resource-agents-4.9.0-16.9 - RHEL 8.8:
resource-agents-4.9.0-40.1 - RHEL 9.0:
resource-agents-cloud-4.10.0-9.6 - RHEL 9.2 e versioni successive:
resource-agents-cloud-4.10.0-34.1
- RHEL 8.4:
[1] Configurare le risorse in Pacemaker.
#Place the cluster in maintenance mode sudo pcs property set maintenance-mode=true[1] Impostare la strategia e il vincolo del nodo di integrità del cluster Pacemaker.
sudo pcs property set node-health-strategy=custom # For RHEL 8.x/9.x sudo pcs constraint location 'regexp%!health-.*' \ rule score-attribute='#health-azure' \ defined '#uname' # For RHEL 10.x sudo pcs constraint location 'regexp%!health-.*' \ rule score-attribute='#health-azure' \ "defined #uname"Importante
Non definire altre risorse nel cluster a partire da
health-oltre alle risorse descritte nei passaggi successivi.[1] Impostare il valore iniziale degli attributi del cluster. Eseguire per ogni nodo del cluster e per ambienti con scalabilità orizzontale, inclusa la macchina virtuale di maggioranza.
sudo crm_attribute --node prod-cl1-0 --name '#health-azure' --update 0 sudo crm_attribute --node prod-cl1-1 --name '#health-azure' --update 0[1] Configurare le risorse in Pacemaker. Assicurarsi che le risorse inizino con
health-azure.sudo pcs resource create health-azure-events \ ocf:heartbeat:azure-events-az \ meta failure-timeout=120s \ op monitor interval=10s timeout=240s \ op start timeout=10s start-delay=90s # For RHEL 8.x/9.x sudo pcs resource clone health-azure-events allow-unhealthy-nodes=true # For RHEL 10.x sudo pcs resource clone health-azure-events meta allow-unhealthy-nodes=trueDisconnettere il cluster Pacemaker dalla modalità di manutenzione.
sudo pcs property set maintenance-mode=falseCancellare eventuali errori durante l'abilitazione e verificare che le risorse
health-azure-eventssiano state avviate correttamente in tutti i nodi del cluster.sudo pcs resource cleanupL'esecuzione della prima query per gli eventi pianificati può richiedere fino a due minuti. I test pacemaker con eventi pianificati possono usare azioni di riavvio o ridistribuzione per le macchine virtuali del cluster. Per altre informazioni, vedere Eventi pianificati.
Configurazione facoltativa dell'isolamento
Suggerimento
Questa sezione è applicabile solo se si vuole configurare il dispositivo di isolamento speciale fence_kdump.
Se è necessario raccogliere informazioni di diagnostica all'interno della macchina virtuale, potrebbe essere utile configurare un altro dispositivo di isolamento in base all'agente di isolamento fence_kdump. L'agente fence_kdump riesce a rilevare il ripristino da un arresto anomalo del sistema kdump di un nodo e può consentire il completamento del servizio di ripristino dall'arresto anomalo del sistema prima che vengano richiamati altri metodi di isolamento. Si noti che fence_kdump non è una sostituzione per i meccanismi di isolamento tradizionali, ad esempio SBD o Azure agente di isolamento, quando si usano macchine virtuali Azure.
Importante
Tenere presente che quando fence_kdump è configurato come dispositivo di isolamento di primo livello, introduce ritardi nelle operazioni di isolamento e, rispettivamente, nel failover delle risorse dell'applicazione.
Se viene rilevato un dump di arresto anomalo del sistema, l'isolamento viene ritardato fino al completamento del servizio di ripristino a seguito dell'arresto anomalo del sistema. Se il nodo con errore non è raggiungibile o se non risponde, l'isolamento viene ritardato per un intervallo di tempo determinato, secondo il numero configurato di iterazioni e il timeout fence_kdump. Per altre informazioni, vedere Come si configura fence_kdump in un cluster Red Hat Pacemaker?
Potrebbe essere necessario adattare il timeout fence_kdump proposto all'ambiente specifico.
È consigliabile configurare fence_kdump fencing solo quando necessario per raccogliere la diagnostica all'interno della macchina virtuale e sempre in combinazione con metodi di fencing tradizionali, ad esempio SBD o agente di fencing Azure.
I seguenti articoli della Knowledge Base di Red Hat contengono informazioni importanti sulla configurazione dell'isolamento fence_kdump:
- Consulta Come si configura fence_kdump in un cluster di Red Hat Pacemaker?
- Vedere Come configurare/gestire i livelli di isolamento in un cluster RHEL con Pacemaker.
- Vedere Errore di fence_kdump con "timeout dopo X secondi" in un cluster RHEL 6 o 7 a disponibilità elevata con kexec-tools precedenti alla versione 2.0.14.
- Per informazioni su come modificare il timeout predefinito, vedere Come si configura kdump per l'uso con il componente aggiuntivo a disponibilità elevata RHEL 6, 7, 8?
- Per informazioni su come ridurre il ritardo del failover quando si usa
fence_kdump, consultare Si può ridurre il ritardo previsto del failover quando si aggiunge la configurazione di fence_kdump?
Eseguire i passaggi facoltativi seguenti per aggiungere fence_kdump come configurazione di isolamento di primo livello, oltre alla configurazione dell'agente di isolamento Azure.
[A] Verificare che
kdumpsia attivo e configurato.systemctl is-active kdump # Expected result # active[A] Installare l'agente di isolamento
fence_kdump.yum install fence-agents-kdump[1] Creare un dispositivo di isolamento
fence_kdumpnel cluster.pcs stonith create rsc_st_kdump fence_kdump pcmk_reboot_action="off" pcmk_host_list="prod-cl1-0 prod-cl1-1" timeout=30[1] Configurare i livelli di isolamento in modo che il meccanismo di isolamento
fence_kdumpvenga attivato per primo.pcs stonith create rsc_st_kdump fence_kdump pcmk_reboot_action="off" pcmk_host_list="prod-cl1-0 prod-cl1-1" pcs stonith level add 1 prod-cl1-0 rsc_st_kdump pcs stonith level add 1 prod-cl1-1 rsc_st_kdump # Replace <stonith-resource-name> to the resource name of the STONITH resource configured in your pacemaker cluster (example based on above configuration - sbd or rsc_st_azure) pcs stonith level add 2 prod-cl1-0 <stonith-resource-name> pcs stonith level add 2 prod-cl1-1 <stonith-resource-name> # Check the fencing level configuration pcs stonith level # Example output # Target: prod-cl1-0 # Level 1 - rsc_st_kdump # Level 2 - <stonith-resource-name> # Target: prod-cl1-1 # Level 1 - rsc_st_kdump # Level 2 - <stonith-resource-name>[A] Consentire le porte necessarie per
fence_kdumpattraverso il firewall.firewall-cmd --add-port=7410/udp firewall-cmd --add-port=7410/udp --permanent[A] Eseguire la configurazione di
fence_kdump_nodesin/etc/kdump.confper evitare chefence_kdumpabbia esito negativo con un timeout per alcune versioni dikexec-tools. Per altre informazioni, vedere Timeout di fence_kdump timeout quando fence_kdump_nodes non è specificato con kexec-tools 2.0.15 o versioni successive e Errore di fence_kdump con "timeout dopo X secondi" in un cluster RHEL 6 o 7 a disponibilità elevata con versioni kexec-tools precedenti alla 2.0.14. Di seguito è illustrata la configurazione di esempio per un cluster a due nodi. Dopo aver apportato una modifica in/etc/kdump.conf, l'immagine kdump deve essere rigenerata. Per rigenerarla, riavviare il serviziokdump.vi /etc/kdump.conf # On node prod-cl1-0 make sure the following line is added fence_kdump_nodes prod-cl1-1 # On node prod-cl1-1 make sure the following line is added fence_kdump_nodes prod-cl1-0 # Restart the service on each node systemctl restart kdump[A] Assicurarsi che il file di immagine
initramfscontenga i filefence_kdumpehosts. Per altre informazioni, vedere Come si configura fence_kdump in un cluster Red Hat Pacemaker?lsinitrd /boot/initramfs-$(uname -r)kdump.img | egrep "fence|hosts" # Example output # -rw-r--r-- 1 root root 208 Jun 7 21:42 etc/hosts # -rwxr-xr-x 1 root root 15560 Jun 17 14:59 usr/libexec/fence_kdump_sendTestare la configurazione arrestando un nodo in modo anomalo. Per altre informazioni, vedere Come si configura fence_kdump in un cluster Red Hat Pacemaker?
Importante
Se il cluster è già in uso produttivo, pianificare il test di conseguenza perché l'arresto anomalo di un nodo ha un impatto sull'applicazione.
echo c > /proc/sysrq-trigger
Passaggi successivi
- Consulta pianificazione e implementazione di Azure Virtual Machines per SAP.
- Vedere distribuzione Azure Virtual Machines per SAP.
- Consulta Distribuzione DBMS di macchine virtuali Azure per SAP.
- Per informazioni su come stabilire la disponibilità elevata e pianificare il ripristino di emergenza di SAP HANA nelle macchine virtuali Azure, vedere
High Availability of SAP HANA on Azure Virtual Machines (Disponibilità elevata di SAP HANA in Azure Virtual Machines