Nota
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare ad accedere o modificare le directory.
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare a modificare le directory.
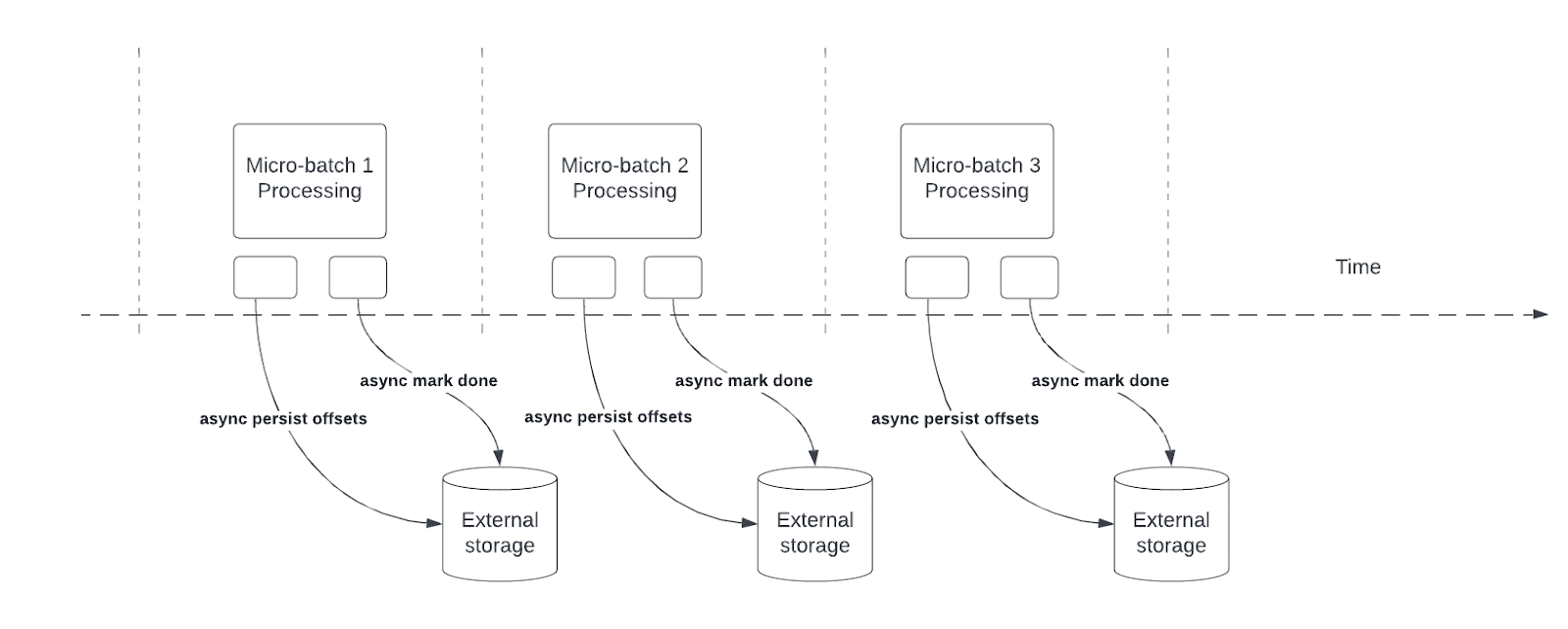
Il rilevamento dello stato asincrono riduce la latenza per le pipeline Structured Streaming consentendo alle query di aggiornare in modo asincrono lo stato di avanzamento del checkpoint ed elaborare i dati in ogni micro-batch.
Durante l'elaborazione delle query, Structured Streaming mantiene e gestisce gli offset per misurare l'avanzamento delle query nel offsetLog e nel commitLog in ogni micro-batch. Senza il tracciamento asincrono dello stato, le operazioni di gestione degli offset influiscono direttamente sulla latenza di elaborazione poiché l'elaborazione dei dati non può continuare fino al completamento di tali operazioni.
Nota
Il monitoraggio del progresso asincrono non è compatibile con i trigger Trigger.once o Trigger.availableNow. Se abilitato, le query Structured Streaming con Trigger.once o Trigger.availableNow falliscono.
Opzioni di configurazione
| Opzione | Predefinito | Descrizione |
|---|---|---|
asyncProgressTrackingEnabled |
false |
Indica se abilitare il monitoraggio dei progressi asincrono. |
asyncProgressTrackingCheckpointIntervalMs |
1000 |
L'intervallo in millisecondi tra le scritture degli offset e i commit di completamento. |
Abilitare il rilevamento dello stato di avanzamento asincrono
Per abilitare il monitoraggio dei progressi asincrono, impostare asyncProgressTrackingEnabled su true.
Python
stream = (spark.readStream
.format("kafka")
.option("kafka.bootstrap.servers", "host1:port1,host2:port2")
.option("subscribe", "in")
.load()
)
query = (stream.writeStream
.format("kafka")
.option("topic", "out")
.option("checkpointLocation", "/tmp/checkpoint")
.option("asyncProgressTrackingEnabled", "true")
.start()
)
Scala
val stream = spark.readStream
.format("kafka")
.option("kafka.bootstrap.servers", "host1:port1,host2:port2")
.option("subscribe", "in")
.load()
val query = stream.writeStream
.format("kafka")
.option("topic", "out")
.option("checkpointLocation", "/tmp/checkpoint")
.option("asyncProgressTrackingEnabled", "true")
.start()
Migliorare la velocità effettiva con la frequenza di checkpoint
La frequenza predefinita del checkpoint di 1000 millisecondi offre una buona efficienza per la maggior parte delle query. Quando le operazioni di gestione degli offset si verificano più velocemente di quanto il monitoraggio del progresso asincrono possa elaborarle, si accumula un arretrato di operazioni di gestione degli offset. Per evitare che il backlog aumenti ulteriormente, il rilevamento dello stato asincrono può rallentare o bloccare l'elaborazione dei dati, potenzialmente erodendo i benefici previsti della latenza.
In questo scenario Databricks consiglia di aumentare l'intervallo di checkpoint:
Python
query = (stream.writeStream
.format("kafka")
.option("topic", "out")
.option("checkpointLocation", "/tmp/checkpoint")
.option("asyncProgressTrackingEnabled", "true")
.option("asyncProgressTrackingCheckpointIntervalMs", "5000")
.start()
)
Scala
val query = stream.writeStream
.format("kafka")
.option("topic", "out")
.option("checkpointLocation", "/tmp/checkpoint")
.option("asyncProgressTrackingEnabled", "true")
.option("asyncProgressTrackingCheckpointIntervalMs", "5000")
.start()
Nota
Il tempo di recupero dai guasti aumenta con l'intervallo di checkpoint. In caso di errore, una pipeline deve rielaborare tutti i dati a partire dall'ultimo checkpoint riuscito. Prima di apportare questa modifica nell'ambiente di produzione, prendere in considerazione il compromesso tra una latenza inferiore durante l'elaborazione regolare rispetto al tempo di ripristino in caso di errore.
Disattivare il rilevamento dello stato di avanzamento asincrono
Quando il monitoraggio asincrono del progresso è abilitato, il flusso non garantisce l'avanzamento del checkpoint per ogni batch. È necessario eseguire un controllo del progresso prima di disattivare questa funzionalità.
Per disattivare, seguire questa procedura:
Elaborare almeno due micro batch con
asyncProgressTrackingEnabledimpostato sutrueeasyncProgressTrackingCheckpointIntervalMsimpostato su0:Python
query = (stream.writeStream .format("kafka") .option("topic", "out") .option("checkpointLocation", "/tmp/checkpoint") .option("asyncProgressTrackingEnabled", "true") .option("asyncProgressTrackingCheckpointIntervalMs", "0") .start() )Scala
val query = stream.writeStream .format("kafka") .option("topic", "out") .option("checkpointLocation", "/tmp/checkpoint") .option("asyncProgressTrackingEnabled", "true") .option("asyncProgressTrackingCheckpointIntervalMs", "0") .start()Fermare la query
Python
query.stop()Scala
query.stop()Disattivare il monitoraggio del progresso asincrono e riavviare la query:
Python
query = (stream.writeStream .format("kafka") .option("topic", "out") .option("checkpointLocation", "/tmp/checkpoint") .option("asyncProgressTrackingEnabled", "false") .start() )Scala
val query = stream.writeStream .format("kafka") .option("topic", "out") .option("checkpointLocation", "/tmp/checkpoint") .option("asyncProgressTrackingEnabled", "false") .start()
Se si disattiva il rilevamento dello stato asincrono senza seguire i passaggi precedenti, è possibile che venga visualizzato l'errore seguente:
java.lang.IllegalStateException: batch x doesn't exist
Nei log del driver potrebbe essere visualizzato l'errore seguente:
The offset log for batch x doesn't exist, which is required to restart the query from the latest batch x from the offset log. Please ensure there are two subsequent offset logs available for the latest batch via manually deleting the offset file(s). Please also ensure the latest batch for commit log is equal or one batch earlier than the latest batch for offset log.
Limitations
- Per i sink Kafka, il rilevamento asincrono del progresso supporta solo le pipeline senza stato.
- Il tracciamento del progresso asincrono non assicura un'elaborazione end-to-end esattamente una volta perché gli intervalli di offset per un batch possono cambiare in caso di guasto. Alcuni sink, ad esempio Kafka, non forniscono mai garanzie di tipo exactly-once.