Nota
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare ad accedere o modificare le directory.
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare a modificare le directory.
Importante
La scalabilità automatica di Lakebase è la versione più recente di Lakebase, con calcolo autoscalabile, scalabilità fino a zero, ramificazione e ripristino immediato. Per le aree supportate, vedere Disponibilità dell'area. Se sei un utente provisioning di Lakebase, vedere Lakebase provisioning.
Databricks Apps consente di compilare e distribuire applicazioni interattive direttamente nell'area di lavoro Azure Databricks. L'aggiunta di Lakebase come risorsa offre all'app un back-end Postgres completamente gestito. Azure Databricks crea un principale di servizio per l'app, concede un ruolo Postgres corrispondente e inserisce i dettagli della connessione come variabili di ambiente. L'app si connette a un database Postgres completamente gestito senza gestire credenziali o stringhe di connessione.

Questa esercitazione illustra come distribuire un'app modello connessa a un database Lakebase. Al termine, avrai un'app funzionante con dati che puoi esaminare ed eseguire query direttamente da Lakebase e, facoltativamente, registrare in Unity Catalog insieme ai dati della lakehouse.
Prerequisiti
Prima di iniziare, verificare di disporre di quanto segue:
- Accesso all'area di lavoro di Azure Databricks con Lakebase e calcolo senza server abilitato. Se necessario, contattare l'amministratore dell'area di lavoro.
- Autorizzazione per creare risorse di calcolo e app.
Passaggio 1: Effettuare il provisioning di un'istanza di Lakebase
Un progetto Lakebase è un'istanza di Postgres gestita a cui l'app si connette come risorsa. I progetti sono organizzati in rami, ognuno dei quali rappresenta un ambiente di database isolato.
Per creare un progetto Lakebase, vedere Introduzione alla scalabilità automatica di Lakebase. Lakebase crea il progetto con un production ramo e un databricks_postgres database.
Passaggio 2: Creare un'app Databricks
Azure Databricks fornisce tre modelli di app con scalabilità automatica che illustrano l'integrazione di Lakebase usando un'app todos: Dash, Flask e Streamlit. Per creare un'app da un modello:
- Nell'area di lavoro Azure Databricks, fare clic sul selettore delle app
 e selezionare Databricks Apps.
e selezionare Databricks Apps. - Fare clic su + Crea app.
- Selezionare il modello preferito nella scheda Database .
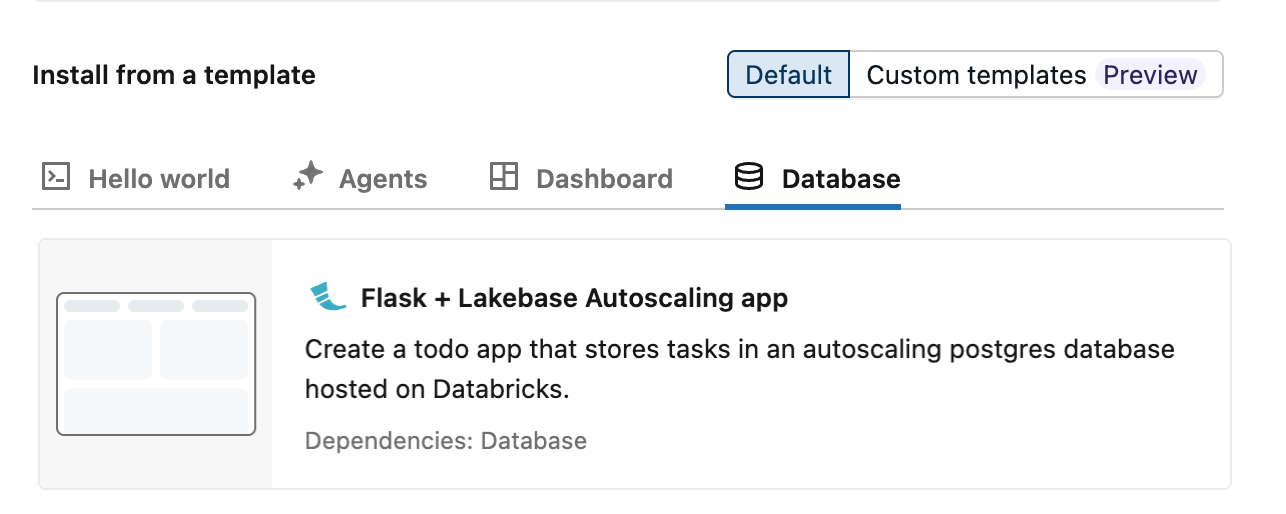
Passaggio 3: Configurare una risorsa di database
L'aggiunta di Lakebase come risorsa crea un'entità servizio con le autorizzazioni di database corrette e inserisce i dettagli della connessione come variabili di ambiente nell'app. In questo modo il modello si connette automaticamente al database, senza stringhe di connessione nel codice.
Nel passaggio Configura configurare le impostazioni seguenti.
- Per Risorse dell'app, selezionare il progetto Lakebase, il ramo e il database. I nomi dei rami vengono visualizzati come ID. Per corrispondere gli ID ai nomi, vedere la pagina dei branch del progetto.
- Per Dimensioni di calcolo, selezionare Medio. Questo consente di controllare le risorse di calcolo del server dell'app, separate dalle risorse di calcolo del database Lakebase e che si ridimensionano in maniera indipendente.
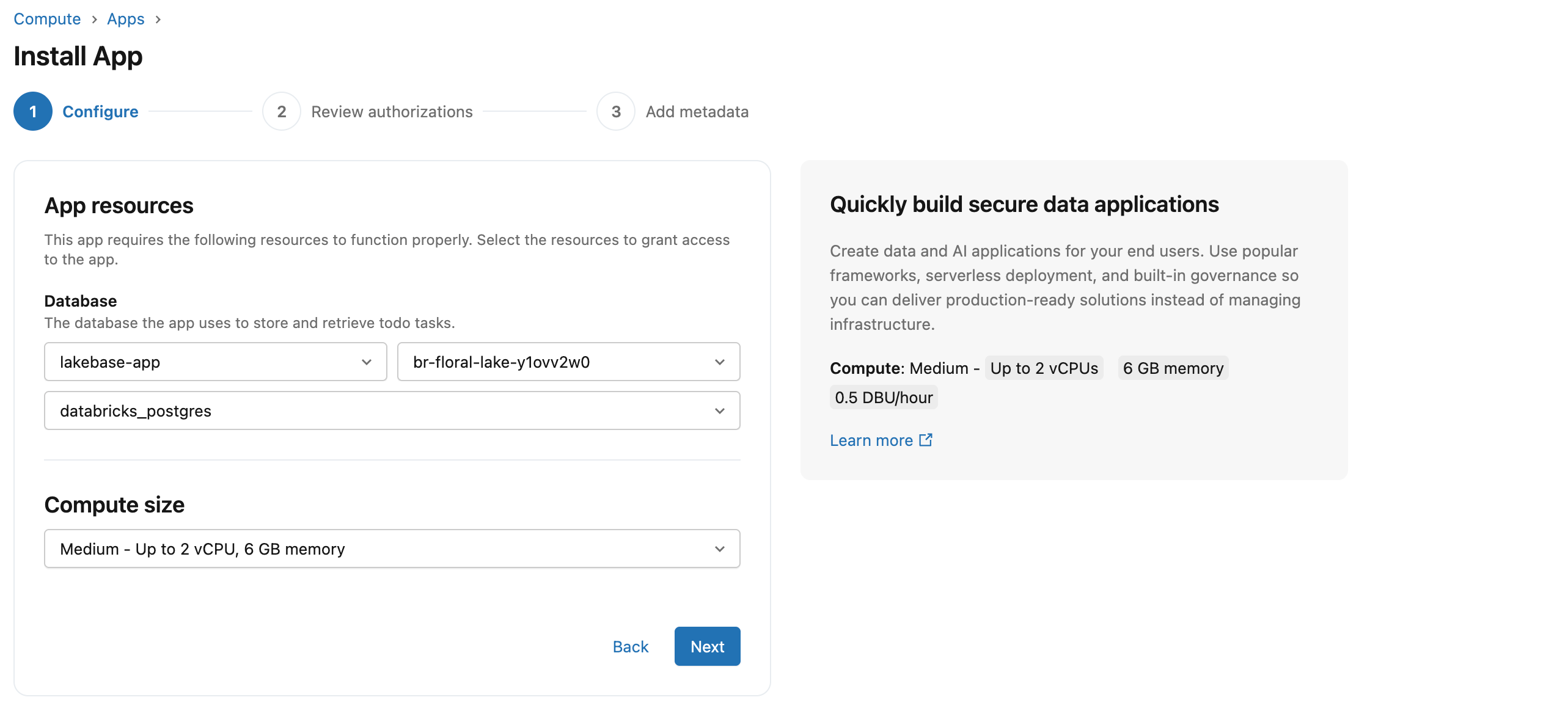
Per altre informazioni, vedere Aggiungere una risorsa Lakebase a un'app Databricks.
Passaggio 4: Esaminare le autorizzazioni
Ogni app Databricks viene eseguita come propria entità servizio, un'identità dedicata separata da qualsiasi singolo utente. Quando si connette Lakebase come risorsa, Azure Databricks crea un ruolo Postgres corrispondente per quel principale del servizio e gli concede l'accesso completo al database. Non è necessaria alcuna configurazione manuale del ruolo.

Passaggio 5: Assegnare un nome all'app e installare
Lakebase usa il nome dell'app per generare un nome di schema nel formato {app-name}_schema_{service-principal-id} (trattini rimossi dall'ID). Non è possibile modificare il nome dell'app dopo la creazione, ma è possibile rinominare lo schema in un secondo momento. Per impostazione predefinita, il modello è lakebase-autoscaling-app.
Fare clic su Crea app per creare l'app.
Passaggio 6: Distribuire l'app
Dopo aver creato l'app, il calcolo viene avviato automaticamente e l'app viene distribuita in circa 2-3 minuti senza ulteriori azioni. Quando lo stato dell'app è In esecuzione, fare clic sull'URL accanto per aprire l'app.

Passaggio 7: Verificare l'integrazione
Aggiungere alcuni todos nell'app. Nel progetto Lakebase aprire Tabelle e selezionare la tabella todos nello schema dell'app. Il principale del servizio dell'app ha scritto quelle righe utilizzando i dettagli della connessione iniettati nel passaggio 3.

Per eseguire query sui dati direttamente, usare l'editor SQL nel progetto Lakebase. Poiché Lakebase viene ridimensionato a zero quando è inattivo, la prima query dopo una pausa prolungata potrebbe richiedere alcuni secondi prima di rispondere. Per altre opzioni di connessione, vedere Connettersi al database.
Passaggio 8: Eseguire query tramite il catalogo Unity (facoltativo)
Per impostazione predefinita, i dati Lakebase dell'app sono accessibili direttamente tramite le connessioni Postgres. La registrazione in Unity Catalog consente di eseguire query insieme ai dati lakehouse usando databricks SQL standard. È quindi possibile unire le tabelle transazionali dell'app con le tabelle Delta nella stessa query.
Per eseguire la registrazione, aprire Esplora cataloghi e creare un nuovo catalogo. Selezionare Lakebase Postgres come tipo di catalogo, scegliere Scalabilità automatica e selezionare lo stesso progetto e ramo dell'app. Per informazioni dettagliate, vedere Registrare il database in Unity Catalog .
Si noti che i nomi degli schemi in Unity Catalog mantengono i trattini dal nome dell'app. I nomi del catalogo e dello schema richiedono la delimitazione con backtick.
SELECT * FROM `your-catalog-name`.`lakebase-autoscaling-app_schema_aeb6ff9198ff4752af7dfc6d4cf570d0`.todos;