Nota
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare ad accedere o modificare le directory.
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare a modificare le directory.
Il test di carico individua il massimo numero di query al secondo (QPS) che l'agente delle app Databricks può sostenere prima del calo delle prestazioni. Questa pagina illustra come eseguire le operazioni seguenti:
- Distribuire una versione fittizia dell'agente per isolare la velocità effettiva dell'infrastruttura dalla latenza LLM.
- Esegui un test di carico da rampa a saturazione con Locust.
- Analizzare i risultati con un dashboard interattivo.
È possibile seguire il percorso assistito dall'intelligenza artificiale usando una competenza Claude Code o configurare ogni passaggio manualmente.
Requisiti
- Un'area di lavoro Azure Databricks con Databricks Apps abilitata.
- Un'app agente distribuita (o pronta per la distribuzione) nelle app Databricks usando OpenAI Agents SDK, LangGraph o un framework personalizzato. Vedere Creare un agente di intelligenza artificiale e distribuirlo in Databricks Apps.
- CLI di Databricks installata e autenticata. Consulta Installare o aggiornare la CLI di Databricks.
- Python 3.10+ con gestione pacchetti
uv. - (Per il percorso assistito dall'intelligenza artificiale) Claude Code installato.
- (Per i test di carico più lunghi di circa 1 ora) Un principale del servizio con credenziali OAuth M2M (
client_ideclient_secret). Consulta Autorizzare l'accesso del principale del servizio ad Azure Databricks con OAuth.- Per i test di carico brevi (meno di circa 1 ora), le credenziali OAuth dell'utente esistente (U2M) di
databricks auth loginfunzionano correttamente. Per i test più lunghi, usare OAuth M2M con un'entità servizio: i token U2M scadono durante le esecuzioni lunghe e causano errori di test intermedi. La creazione di un principale del servizio richiede l'accesso da amministratore dell'area di lavoro.
- Per i test di carico brevi (meno di circa 1 ora), le credenziali OAuth dell'utente esistente (U2M) di
Configurazione assistita dall'intelligenza artificiale (scelta consigliata)
Se si usa Claude Code, la /load-testing competenza automatizza il flusso di lavoro. Legge il codice dell'agente, genera una simulazione, crea script di test di carico e illustra la distribuzione.
Suggerimento
Dite a Claude Code di farlo per voi:
Clone https://github.com/databricks/app-templates and run the /load-testing skill against the {your-template} template.
In alternativa, seguire questa procedura.
Passaggio 1: Clonare un modello di agente
La /load-testing competenza è inclusa nel repository databricks/app-templates , sia come competenza di primo livello agent-load-testing che pre-sincronizzata in ogni singolo modello di agente. Se hai già un progetto da app-templates, hai già la competenza.
Clonare il repository e passare alla directory del modello dell'agente che si desidera sottoporre al test di carico.
git clone https://github.com/databricks/app-templates.git
cd app-templates/{your-template}
Passaggio 2: Esegui la funzione di test di carico
Nel Claude Code, esegui:
/load-testing
L'abilità ti guida interattivamente attraverso i seguenti passaggi. È possibile saltare il mocking per testare il proprio agente reale, oppure evitare la distribuzione nel caso in cui le app siano già in esecuzione.
- Raccolta di parametri: chiede informazioni sullo stato della distribuzione, sulle dimensioni di calcolo, sulle configurazioni del ruolo di lavoro e sulle credenziali OAuth.
-
Creazione di script di test di carico: genera
locustfile.py,run_load_test.pyedashboard_template.pypersonalizzati per il progetto. - Simulazione dell'LLM: crea un client fittizio specifico dell'SDK (OpenAI Agents SDK, LangGraph o personalizzato) che sostituisce le chiamate LLM reali con ritardi di streaming configurabili.
- Distribuzione di app di test: consente di distribuire più configurazioni di app con dimensioni di calcolo e conteggi dei ruoli di lavoro diversi.
- Esecuzione di test: esegue test di carico con l'autenticazione OAuth M2M e la rampa fino alla saturazione.
- Generazione di risultati: produce un dashboard HTML interattivo con QPS, latenza e metriche di errore.
Configurazione manuale
Seguire questa procedura per configurare ed eseguire test di carico senza assistenza per l'intelligenza artificiale.
Passaggio 1: Simulare le chiamate LLM dell'agente (facoltativo)
Saltare questo passaggio se si vogliono risultati end-to-end che includono la latenza reale dell'LLM. Per misurare la velocità effettiva dell'infrastruttura delle Databricks Apps in isolamento, emulare il Large Language Model (LLM) affinché la latenza per richiesta (di solito fra 1 e 30 secondi) non diventi un collo di bottiglia.
Una simulazione restituisce risposte preconfezionate con un ritardo di streaming configurabile, mantenendo la pipeline completa di richiesta/risposta (streaming SSE, dispatch degli strumenti, esecuzione SDK) e sostituendo solo l'LLM. In questo modo viene visualizzato il numero massimo di QPS che la piattaforma Databricks Apps può offrire ed evitare i costi dei token API del modello di base durante i test di carico.
La tempistica fittizia è controllata da due variabili di ambiente:
| Variable | Impostazione predefinita | Description |
|---|---|---|
MOCK_CHUNK_DELAY_MS |
10 |
Ritardo in millisecondi tra blocchi di testo trasmessi |
MOCK_CHUNK_COUNT |
80 |
Numero di blocchi di testo per risposta |
Con le impostazioni predefinite, ogni risposta fittizia richiede circa 800 ms (10 ms x 80 blocchi), notevolmente più veloce rispetto a una risposta LLM reale (3-15 secondi). I numeri di velocità effettiva riflettono quindi la piattaforma, non il modello.
Creare un client fittizio che sostituisce il client LLM reale. Il resto del codice dell'agente rimane invariato e l'approccio dipende dall'SDK. Per OpenAI, consultare l'implementazione di riferimento in databricks/app-templates. Lo stesso modello si adatta ad altri SDK.
OpenAI Agents SDK
Create agent_server/mock_openai_client.py — una MockAsyncOpenAI classe che implementa chat.completions.create() con lo streaming. Restituisce immediatamente i blocchi di chiamata dello strumento (simulando l'LLM che decide di chiamare uno strumento) e, con ritardo configurabile, blocchi di risposta di testo dalle variabili di ambiente MOCK_CHUNK_DELAY_MS e MOCK_CHUNK_COUNT.
Inseriscilo nel tuo agente.
from agent_server.mock_openai_client import MockAsyncOpenAI
from agents import set_default_openai_client, set_default_openai_api
set_default_openai_client(MockAsyncOpenAI())
set_default_openai_api("chat_completions")
Il resto del codice dell'agente (gestori, strumenti, logica di streaming) rimane invariato.
LangGraph
Sostituire il ChatDatabricks modello con un modello fittizio che restituisce oggetti predefiniti AIMessage :
# Before:
# model = ChatDatabricks(endpoint="databricks-claude-sonnet-4")
# After:
from agent_server.mock_llm import MockChatModel
model = MockChatModel()
La simulazione deve restituire AIMessage oggetti con invocazioni di strumenti alla prima chiamata e contenuto di testo nelle chiamate successive, con ritardi configurabili nello streaming.
Agenti personalizzati
Eseguire il wrapping delle chiamate API esterne eseguite dall'agente (LLM, ricerca vettoriale, API degli strumenti) con implementazioni fittizie che restituiscono forme di risposta realistiche con ritardi configurabili.
Passaggio 2: Configurare gli script di test di carico
Creare la directory load-test-scripts/ nel tuo progetto. Il framework di test di carico è costituito da tre script indipendenti dal framework e che funzionano con qualsiasi agente di Databricks Apps.
<project-root>/
agent_server/ # Your existing agent code
load-test-scripts/ # Load testing scripts (create this)
run_load_test.py # CLI orchestrator
locustfile.py # Locust test with SSE streaming + TTFT tracking
dashboard_template.py # Interactive HTML dashboard generator
load-test-runs/ # Results (auto-created per run)
<run-name>/
dashboard.html # Interactive dashboard
test_config.json # Test parameters for reproducibility
<label>/ # Per-config Locust CSV output
Il framework include i file seguenti:
-
locustfile.py: test di carico Locust che inviaPOST /invocationsrichieste constream: true, analizza i flussi SSE, tiene traccia del tempo al primo token (TTFT) come metrica personalizzata, usa lo scambio di token OAuth M2M con l'aggiornamento automatico e implementa un oggettoStepRampShapeche consente agli utenti di passare dastep_sizeamax_usersmantenendo ogni livello perstep_durationsecondi. -
run_load_test.py: agente di orchestrazione dell'interfaccia della riga di comando che testa ogni URL dell'app in sequenza con metriche isolate per ogni configurazione. Gestisce l'aggiornamento del token OAuth, esegue un controllo integrità e un riscaldamento prima di ogni test e salva i risultati inload-test-runs/<run-name>/<label>/. -
dashboard_template.py: genera un dashboard HTML autonomo usando Chart.js con schede KPI, grafici a barre (QPS, latenza, TTFT per configurazione), grafici a linee di avanzamento della rampa QPS e una tabella dei risultati completa. Può essere eseguito autonomo:uv run dashboard_template.py ../load-test-runs/<run-name>/.
Installa le dipendenze
Gli script per il test di carico utilizzano un loro pyproject.toml interno load-test-scripts/ per evitare di interferire con le dipendenze di produzione dell'agente. Creare load-test-scripts/pyproject.toml:
[project]
name = "load-test-scripts"
version = "0.1.0"
requires-python = ">=3.10"
dependencies = [
"locust>=2.32,<2.40",
"urllib3<2.3",
"requests",
]
Annotazioni
Aggiungi locust a <2.40. Le versioni più recenti (>=2.43) hanno un noto RecursionError che interrompe i test di carico lunghi.
Eseguire l'installazione dall'interno della load-test-scripts/ directory:
cd load-test-scripts/
uv sync
Passaggio 3: Distribuire app di test con configurazioni diverse
Distribuire più app Databricks con diverse dimensioni di calcolo e numero di worker per trovare la configurazione ottimale per il tuo carico di lavoro.
Matrice di test consigliata
Le configurazioni seguenti sono incentrate sul punto dolce identificato dai test precedenti. Se si vuole una copertura più ampia, aggiungere una configurazione su entrambi i lati (ad esempio, medium-w1 o large-w12), ma le sei seguenti sono in genere sufficienti.
| Dimensioni di calcolo | Lavoratori | Nome dell'app suggerita |
|---|---|---|
| Medium | 2 | <your-app>-medium-w2 |
| Medium | 3 | <your-app>-medium-w3 |
| Medium | 4 | <your-app>-medium-w4 |
| Grande | 6 | <your-app>-large-w6 |
| Grande | 8 | <your-app>-large-w8 |
| Grande | 10 | <your-app>-large-w10 |
Configurare le dimensioni di calcolo
Usare l'interfaccia della riga di comando di Databricks per impostare le dimensioni di calcolo durante la creazione o l'aggiornamento di un'app:
# Create a new app with Medium compute
databricks apps create <app-name> --compute-size MEDIUM
# Update an existing app to Large compute
databricks apps update <app-name> --compute-size LARGE
Configurare il conteggio dei lavoratori con Pacchetti di Automazione Dichiarativa
start-server (via AgentServer.run()) accetta direttamente un --workers flag. Passare il conteggio dei lavoratori nella matrice command usando una variabile DAB.
variables:
app_name:
default: 'my-agent-medium-w2'
workers:
default: '2'
resources:
apps:
load_test_app:
name: ${var.app_name}
source_code_path: .
config:
command: ['uv', 'run', 'start-server', '--workers', '${var.workers}']
env:
- name: MOCK_CHUNK_DELAY_MS
value: '10'
- name: MOCK_CHUNK_COUNT
value: '80'
targets:
medium-w2:
default: true
variables:
app_name: 'my-agent-medium-w2'
workers: '2'
large-w8:
variables:
app_name: 'my-agent-large-w8'
workers: '8'
Distribuire e verificare
Implementare ogni destinazione con l'interfaccia della riga di comando di Databricks
databricks bundle deploy --target medium-w2
databricks bundle run load_test_app --target medium-w2
Verificare che le app siano attive prima di eseguire test di carico:
databricks apps get <app-name> --output json | jq '{app_status, compute_status, url}'
Annotazioni
Attendere che tutte le app raggiungano ACTIVE lo stato prima di procedere. Le app che sono ancora in fase di avvio producono risultati fuorvianti.
Passaggio 4: Eseguire test di carico
Configurare l'autenticazione
Selezionare l'autenticazione in base al tempo previsto per l'esecuzione:
-
Test brevi (inferiore a circa 1 ora): usare le credenziali utente esistenti da
databricks auth login. Non è necessaria alcuna configurazione aggiuntiva. - Test lunghi (più di circa 1 ora, ad esempio esecuzioni notturne): usare OAuth M2M con un'entità servizio. I token U2M scadono e interrompono l'esecuzione del test a metà. La creazione di un principale del servizio richiede l'accesso da amministratore dell'area di lavoro.
Per M2M OAuth, esportare le credenziali del service principal prima di eseguire i test.
export DATABRICKS_HOST=https://your-workspace.cloud.databricks.com
export DATABRICKS_CLIENT_ID=<your-client-id>
export DATABRICKS_CLIENT_SECRET=<your-client-secret>
Riferimento ai parametri
| Parametro | Obbligatorio | Impostazione predefinita | Description |
|---|---|---|---|
--app-url |
Yes | — | URL dell'app da testare (ripetibile) |
--client-id |
Per test lunghi |
DATABRICKS_CLIENT_ID Env |
ID client dell'entità di servizio (OAuth M2M) |
--client-secret |
Per test lunghi |
DATABRICKS_CLIENT_SECRET Env |
Segreto client dell'entità servizio (OAuth M2M) |
--label |
No | Derivata automaticamente dall'URL | Etichetta leggibile per ogni app (ripetibile) |
--compute-size |
No | Rilevato automaticamente o medium |
Tag delle dimensioni di calcolo per app: medium, large (ripetibile) |
--max-users |
No | 300 |
Numero massimo di utenti simulati simultanei |
--step-size |
No | 20 |
Utenti aggiunti per passaggio di rampa |
--step-duration |
No | 30 |
Secondi per passaggio di rampa |
--spawn-rate |
No | 20 |
Frequenza di generazione utente (utenti/sec) |
--run-name |
No | <timestamp> |
Nome per questa esecuzione - risultati salvati in load-test-runs/<run-name>/ |
--dashboard |
No | Disattivato | Generare dashboard HTML interattivo al termine dei test |
Comandi di esempio
Test rapido per singola applicazione (esecuzione breve: utilizza la sessione databricks auth login)
cd load-test-scripts/
uv run run_load_test.py \
--app-url https://my-app.aws.databricksapps.com \
--dashboard --run-name quick-test
La matrice completa tra le 6 configurazioni consigliate (esecuzione estesa — gestione delle credenziali M2M). Passare le bandiere --compute-size nello stesso ordine di --app-url:
uv run run_load_test.py \
--app-url https://my-app-medium-w2.aws.databricksapps.com \
--app-url https://my-app-medium-w3.aws.databricksapps.com \
--app-url https://my-app-medium-w4.aws.databricksapps.com \
--app-url https://my-app-large-w6.aws.databricksapps.com \
--app-url https://my-app-large-w8.aws.databricksapps.com \
--app-url https://my-app-large-w10.aws.databricksapps.com \
--compute-size medium --compute-size medium --compute-size medium \
--compute-size large --compute-size large --compute-size large \
--client-id $DATABRICKS_CLIENT_ID \
--client-secret $DATABRICKS_CLIENT_SECRET \
--dashboard --run-name overnight-sweep
Esecuzioni multiple per coerenza statistica.
for RUN in r1 r2 r3 r4 r5; do
uv run run_load_test.py \
--app-url https://my-app.aws.databricksapps.com \
--client-id $DATABRICKS_CLIENT_ID \
--client-secret $DATABRICKS_CLIENT_SECRET \
--max-users 1000 --step-size 20 --step-duration 10 \
--run-name my_test_${RUN} --dashboard || break
done
Cosa accade durante un'esecuzione
-
Controllo integrità: verifica che i flussi dell'app siano corretti (riceve
[DONE]). - Warmup: invia richieste sequenziali per riscaldare l'app.
-
Incremento fino a saturazione: aumenta gli utenti simultanei ogni
step_durationsecondi. - Rilevamento della saturazione: quando QPS si stabilizza nonostante l'aggiunta di altri utenti, è stato raggiunto il limite di throughput.
Durata stimata
Ogni app sottoposta a test viene eseguita attraverso la propria rampa, quindi il tempo di esecuzione totale viene ridimensionato con il numero di configurazioni nella matrice. Usare la formula seguente per pianificare la finestra di esecuzione.
Durata per app: (max_users / step_size) * step_duration secondi.
Con le impostazioni predefinite (--max-users 300 --step-size 20 --step-duration 30):
- 15 passaggi x 30 secondi = circa 7,5 minuti per app
- Per la matrice a 6 configurazioni consigliata: circa 45 minuti per esecuzione
Passaggio 5: Visualizzare e interpretare i risultati
Aprire il dashboard:
open load-test-runs/<run-name>/dashboard.html(Facoltativo) Rigenerare il dashboard dai dati esistenti, ad esempio dopo l'aggiornamento del modello:
cd load-test-scripts/ uv run dashboard_template.py ../load-test-runs/<run-name>/
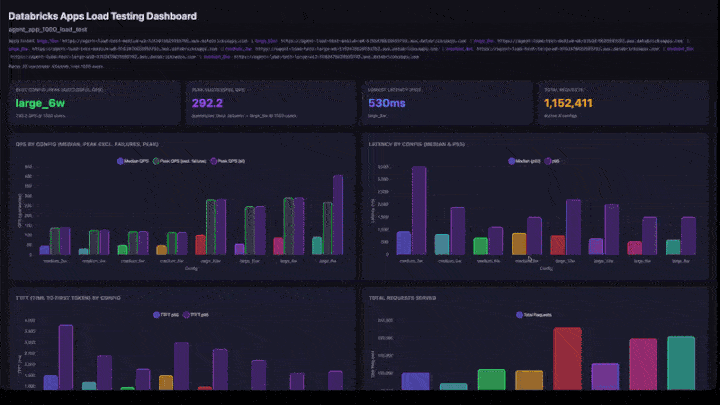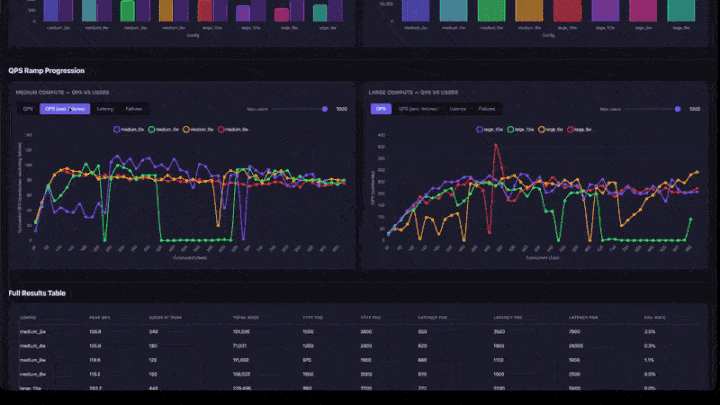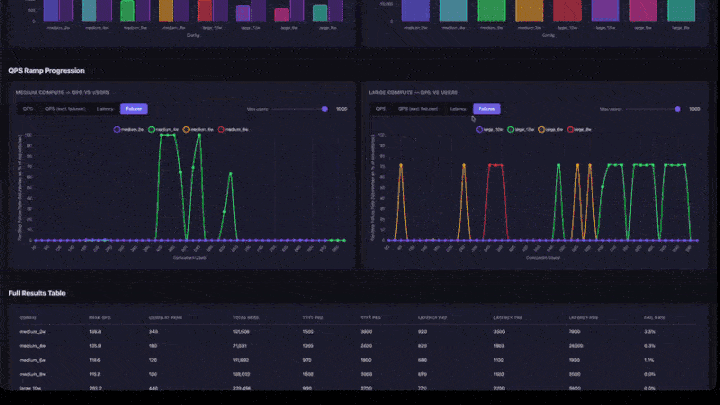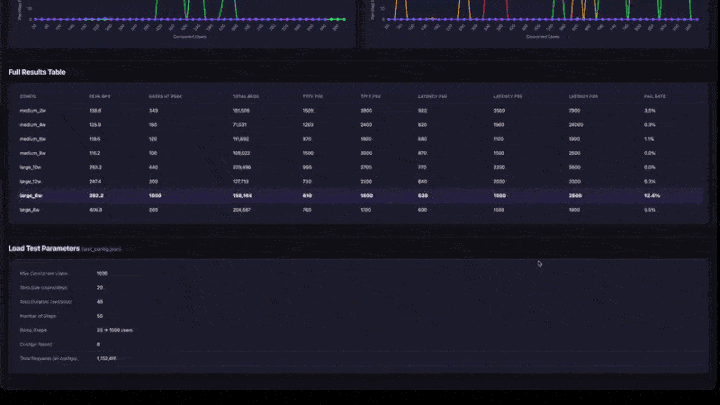
Sezioni del dashboard
Il dashboard interattivo include:
- Schede KPI: configurazione ottimale (in base al picco di QPS riuscito), picco complessivo di QPS, latenza più bassa e richieste totali gestite.
- QPS per configurazione: grafico a barre raggruppate che mostra QPS mediano, QPS di picco esclusi gli errori e picco QPS side-by-side per ogni configurazione.
- Latenza per configurazione: barre raggruppate che mostrano la latenza p50 e p95.
- TTFT by Config: tempo al primo token (p50 e p95).
- Totale richieste servite: numero di richieste per ogni configurazione.
- QPS Ramp Progression: grafici a linee con schede per QPS, QPS (esclusi gli errori), latenza e errori. Include un cursore massimo utenti per ingrandire gli intervalli di utenti simultanei inferiori. I grafici sono raggruppati in base alla dimensione del calcolo (medie e grandi affiancate).
- Tabella risultati completi: tutte le configurazioni con il picco di QPS, gli utenti al picco, i percentili di latenza e la frequenza di errore.
- Parametri di test: riepilogo della configurazione per la riproducibilità.
Come interpretare i risultati
- QPS di picco: il numero massimo di QPS raggiunto in qualsiasi passaggio di rampa. Si tratta del limite massimo di velocità effettiva per tale configurazione.
- Utenti al picco: il numero di utenti simultanei quando è stato raggiunto il picco di QPS. L'aggiunta di altri utenti oltre questo punto non aumenta la velocità effettiva.
- Frequenza errori: deve essere 0% o molto bassa. Una frequenza di errore elevata indica che l'app viene sovraccaricata a quel livello di concorrenza.
- Grafico di rampa QPS: cercare dove la linea si appiattisce. Questo è il punto di saturazione: l'aggiunta di altri utenti non aumenterà la velocità effettiva.
Troubleshooting
| Emetti | Soluzione |
|---|---|
| Token di autenticazione scaduto durante il test | Per i test più lunghi di circa 1 ora, passare da U2M a M2M OAuth passando --client-id e --client-secret |
| Controllo integrità non riuscito | Verificare che l'app sia ATTIVA: databricks apps get <name> --output json |
| 0 QPS o nessun risultato | Verificare la presenza di load-test-runs/<run-name>/<label>/locust_output.log errori |
| QPS basso nonostante il numero elevato di utenti | L'app è satura. Provare più risorse o una maggiore capacità di calcolo. |
| Frequenza di errori elevata | L'app è sovraccarica. Ridurre --max-users o aumentare i ruoli di lavoro/calcolo. |
| Il dashboard non mostra dati di rampa | Verificare che results_stats_history.csv esista in ogni sottodirectory dei risultati |
Passaggi successivi
- Testare con chiamate LLM reali: saltare la fase di simulazione e distribuire l'agente effettivo per misurare la latenza end-to-end, incluso il tempo di risposta dell'LLM.
- Ottimizzare il numero di ruoli di lavoro: usare i risultati della matrice di test per trovare il numero di ruoli di lavoro ottimale per le dimensioni di calcolo.
- Esercitazione: Valutare e migliorare un'applicazione GenAI per misurare l'accuratezza , la pertinenza e la sicurezza insieme alla velocità effettiva.