Nota
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare ad accedere o modificare le directory.
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare a modificare le directory.
Questo articolo offre consigli per la progettazione di tabelle replicate nello schema del pool Synapse SQL. Usare questi consigli per migliorare le prestazioni delle query riducendo lo spostamento dei dati e la complessità delle query.
Prerequisiti
Questo articolo presuppone che si abbia familiarità con i concetti relativi alla distribuzione dei dati e allo spostamento dei dati nel pool SQL. Per altre informazioni, vedere l'articolo sull'architettura .
Come parte della progettazione di tabelle, comprendere il più possibile sui dati e su come vengono eseguite query sui dati. Si considerino ad esempio queste domande:
- Quanto è grande la tabella?
- Con quale frequenza viene aggiornata la tabella?
- Sono presenti tabelle dei fatti e delle dimensioni in un pool SQL?
Che cos'è una tabella replicata?
Una tabella replicata include una copia completa della tabella accessibile in ogni nodo di calcolo. La replica di una tabella rimuove la necessità di trasferire i dati tra i nodi di calcolo prima di un join o un'aggregazione. Poiché la tabella include più copie, le tabelle replicate funzionano meglio quando le dimensioni della tabella sono inferiori a 2 GB compressi. 2 GB non è un limite rigido. Se i dati sono statici e non cambiano, è possibile replicare tabelle di dimensioni maggiori.
Il diagramma seguente illustra una tabella replicata accessibile in ogni nodo di calcolo. Nel pool SQL la tabella replicata viene copiata completamente in un database di distribuzione in ogni nodo di calcolo.

Le tabelle replicate funzionano bene per le tabelle delle dimensioni in uno schema a stella. Le tabelle delle dimensioni vengono in genere unite a tabelle dei fatti, distribuite in modo diverso rispetto alla tabella delle dimensioni. Le dimensioni sono in genere di dimensioni che rendono possibile archiviare e gestire più copie. Le tabelle dimensionali conservano dati descrittivi che cambiano lentamente, come il nome e l'indirizzo del cliente e i dettagli del prodotto. La natura a modifica lenta dei dati comporta una minore manutenzione della tabella replicata.
Prendere in considerazione l'uso di una tabella replicata quando:
- Le dimensioni della tabella su disco sono inferiori a 2 GB, indipendentemente dal numero di righe. Per trovare le dimensioni di una tabella, è possibile usare il comando DBCC PDW_SHOWSPACEUSED :
DBCC PDW_SHOWSPACEUSED('ReplTableCandidate'). - La tabella viene utilizzata nei join che altrimenti richiedono lo spostamento dei dati. Quando si uniscono tabelle non distribuite nella stessa colonna, ad esempio una tabella con distribuzione hash a una tabella round robin, lo spostamento dei dati è necessario per completare la query. Se una delle tabelle è piccola, prendere in considerazione una tabella replicata. È consigliabile usare tabelle replicate anziché tabelle round robin nella maggior parte dei casi. Per visualizzare le operazioni di spostamento dei dati nei piani di query, usare sys.dm_pdw_request_steps. BroadcastMoveOperation è l'operazione di spostamento dei dati tipica che può essere eliminata tramite una tabella replicata.
Le tabelle replicate potrebbero non restituire le migliori prestazioni delle query quando:
- La tabella include operazioni frequenti di inserimento, aggiornamento ed eliminazione. Le operazioni DML (Data Manipulation Language) richiedono una ricompilazione della tabella replicata. La ricostruzione frequente può causare prestazioni più lente.
- Il pool SQL viene ridimensionato di frequente. Il ridimensionamento di un pool SQL modifica il numero di nodi di calcolo, che comporta la ricompilazione della tabella replicata.
- La tabella ha un numero elevato di colonne, ma le operazioni sui dati in genere accedono solo a un numero ridotto di colonne. In questo scenario, invece di replicare l'intera tabella, potrebbe essere più efficace distribuire la tabella e quindi creare un indice nelle colonne a cui si accede di frequente. Quando una query richiede lo spostamento dei dati, il pool SQL sposta solo i dati per le colonne richieste.
Suggerimento
Per altre indicazioni sull'indicizzazione e sulle tabelle replicate, vedere il foglio informativo per il pool SQL dedicato (in precedenza SQL Data Warehouse) in Azure Synapse Analytics.
Usare tabelle replicate con predicati di query semplici
Prima di scegliere di distribuire o replicare una tabella, considerare i tipi di query che si prevede di eseguire sulla tabella. Quando possibile,
- Usare tabelle replicate per le query con predicati di query semplici, ad esempio uguaglianza o disuguaglianza.
- Usare tabelle distribuite per le query con predicati di query complessi, ad esempio LIKE o NOT LIKE.
Le query a elevato utilizzo di CPU eseguono prestazioni ottimali quando il lavoro viene distribuito in tutti i nodi di calcolo. Ad esempio, le query che eseguono calcoli in ogni riga di una tabella offrono prestazioni migliori nelle tabelle distribuite rispetto alle tabelle replicate. Poiché una tabella replicata viene archiviata in modo completo in ogni nodo di calcolo, una query a elevato utilizzo di CPU su una tabella replicata viene eseguita sull'intera tabella in ogni nodo di calcolo. Il calcolo aggiuntivo può rallentare le prestazioni delle query.
Ad esempio, questa query ha un predicato complesso. Viene eseguito più velocemente quando i dati si trovano in una tabella distribuita anziché in una tabella replicata. In questo esempio, i dati possono essere distribuiti secondo un meccanismo round robin.
SELECT EnglishProductName
FROM DimProduct
WHERE EnglishDescription LIKE '%frame%comfortable%';
Convertire tabelle "round robin" esistenti in tabelle replicate
Se sono già presenti tabelle round robin, è consigliabile convertirle in tabelle replicate se soddisfano i criteri descritti in questo articolo. Le tabelle replicate migliorano le prestazioni rispetto alle tabelle round robin perché eliminano la necessità di spostamento dei dati. Una tabella round robin richiede sempre lo spostamento dei dati per i join.
In questo esempio viene usato CTAS per modificare la DimSalesTerritory tabella in una tabella replicata. Questo esempio funziona indipendentemente dal fatto che DimSalesTerritory sia distribuito tramite hash o round robin.
CREATE TABLE [dbo].[DimSalesTerritory_REPLICATE]
WITH
(
HEAP,
DISTRIBUTION = REPLICATE
)
AS SELECT * FROM [dbo].[DimSalesTerritory]
OPTION (LABEL = 'CTAS : DimSalesTerritory_REPLICATE')
-- Switch table names
RENAME OBJECT [dbo].[DimSalesTerritory] to [DimSalesTerritory_old];
RENAME OBJECT [dbo].[DimSalesTerritory_REPLICATE] TO [DimSalesTerritory];
DROP TABLE [dbo].[DimSalesTerritory_old];
Esempio di prestazioni delle query per round robin e replicato
Una tabella replicata non richiede lo spostamento dei dati per i join perché l'intera tabella è già presente in ogni nodo di calcolo. Se le tabelle delle dimensioni sono distribuite tramite round robin, un join copia la tabella delle dimensioni completa in ogni nodo di calcolo. Per spostare i dati, il piano di query contiene un'operazione denominata BroadcastMoveOperation. Questo tipo di operazione di spostamento dei dati rallenta le prestazioni delle query ed è eliminato tramite tabelle replicate. Per visualizzare i passaggi del piano di query, usare la vista del catalogo di sistema sys.dm_pdw_request_steps .
Ad esempio, nella seguente query sullo schema AdventureWorks, la tabella FactInternetSales è distribuita tramite hash. Le DimDate tabelle e DimSalesTerritory sono tabelle delle dimensioni più piccole. Questa query restituisce le vendite totali in America del Nord per l'anno fiscale 2004:
SELECT [TotalSalesAmount] = SUM(SalesAmount)
FROM dbo.FactInternetSales s
INNER JOIN dbo.DimDate d
ON d.DateKey = s.OrderDateKey
INNER JOIN dbo.DimSalesTerritory t
ON t.SalesTerritoryKey = s.SalesTerritoryKey
WHERE d.FiscalYear = 2004
AND t.SalesTerritoryGroup = 'North America'
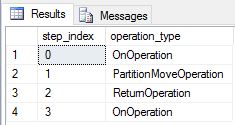
Abbiamo ricreato DimDate e DimSalesTerritory come tabelle round-robin. Di conseguenza, la query ha mostrato il piano di query seguente, che include più operazioni di spostamento broadcast:

Abbiamo ricreato DimDate e DimSalesTerritory come tabelle replicate ed eseguito nuovamente la query. Il piano di query risultante è molto più breve e non contiene alcun movimento di broadcast.
Considerazioni sulle prestazioni per la modifica delle tabelle replicate
Il pool SQL implementa una tabella replicata mantenendo una versione master della tabella. Copia la versione master nel primo database di distribuzione in ogni nodo di calcolo. Quando viene apportata una modifica, la versione master viene aggiornata per prima, quindi le tabelle in ogni nodo di calcolo vengono ricompilate. Una ricompilazione di una tabella replicata include la copia della tabella in ogni nodo di calcolo e quindi la compilazione degli indici. Ad esempio, una tabella replicata in un DW2000c ha cinque copie dei dati. Copia master e copia completa in ogni nodo di calcolo. Tutti i dati vengono archiviati nei database di distribuzione. Il pool SQL usa questo modello per supportare istruzioni di modifica dei dati più veloci e operazioni di ridimensionamento flessibili.
Le ricompilazioni asincrone vengono attivate dalla prima query sulla tabella replicata dopo:
- I dati vengono caricati o modificati
- L'istanza di Synapse SQL viene ridimensionata a un livello diverso
- La definizione di tabella viene aggiornata
Le ricompilazioni non sono richieste dopo:
- Sospendere l'operazione
- Riprendi operazione
La ricompilazione non viene eseguita immediatamente dopo la modifica dei dati. Invece, la ricompilazione viene attivata la prima volta che una query seleziona dalla tabella. La query che ha attivato la ricompilazione legge immediatamente dalla versione master della tabella mentre i dati vengono copiati in modo asincrono in ogni nodo di calcolo. Fino al completamento della copia dei dati, le query successive continueranno a usare la versione master della tabella. Se si verifica un'attività sulla tabella replicata che forza un'altra ricompilazione, la copia dei dati viene invalidata e l'istruzione select successiva attiverà di nuovo la copia dei dati.
Usare gli indici in modo conservativo
Le procedure di indicizzazione standard si applicano alle tabelle replicate. Il pool SQL ricompila ogni indice di tabella replicato come parte della ricompilazione. Usare gli indici solo quando il miglioramento delle prestazioni supera il costo della ricompilazione degli indici.
Caricamento dei dati batch
Quando si caricano dati in tabelle replicate, provare a ridurre al minimo le ricompilazione raggruppando i carichi. Eseguire tutti i caricamenti in batch prima di eseguire istruzioni di selezione.
Ad esempio, questo schema di carico carica i dati da quattro origini e avvia quattro ricompilazioni.
- Caricare dalla sorgente 1.
- L'istruzione Select attiva la ricompilazione 1.
- Caricare dall'origine 2.
- L'istruzione SELECT innesca la ricompilazione 2.
- Caricare dall'origine 3.
- Select statement innesca la ricompilazione 3.
- Caricare dall'origine 4.
- L'istruzione SELECT attiva la ricompilazione 4.
Ad esempio, questo modello di carico carica i dati da quattro origini, ma richiama solo una ricompilazione.
- Caricare dalla fonte 1.
- Caricare dall'origine 2.
- Caricare dall'origine 3.
- Caricare dall'origine 4.
- L'istruzione SELECT attiva la ricompilazione.
Ricompilare una tabella replicata dopo un caricamento batch
Per garantire tempi di esecuzione coerenti delle query, è consigliabile forzare la compilazione delle tabelle replicate dopo un caricamento batch. In caso contrario, la prima query userà comunque lo spostamento dei dati per completare la query.
L'operazione 'Build Replicated Table Cache' può essere eseguita contemporaneamente fino a due operazioni. Ad esempio, se si tenta di ricompilare la cache per cinque tabelle, il sistema utilizzerà un staticrc20 (che non può essere modificato) per compilare simultaneamente due tabelle al momento. Pertanto, è consigliabile evitare di usare tabelle replicate di grandi dimensioni superiori a 2 GB, in quanto ciò potrebbe rallentare la ricompilazione della cache tra i nodi e aumentare il tempo complessivo.
Questa query usa la DMV sys.pdw_replicated_table_cache_state per elencare le tabelle replicate modificate, ma non ricompilate.
SELECT SchemaName = SCHEMA_NAME(t.schema_id)
, [ReplicatedTable] = t.[name]
, [RebuildStatement] = 'SELECT TOP 1 * FROM ' + '[' + SCHEMA_NAME(t.schema_id) + '].[' + t.[name] +']'
FROM sys.tables t
JOIN sys.pdw_replicated_table_cache_state c
ON c.object_id = t.object_id
JOIN sys.pdw_table_distribution_properties p
ON p.object_id = t.object_id
WHERE c.[state] = 'NotReady'
AND p.[distribution_policy_desc] = 'REPLICATE'
Per attivare una ricompilazione, eseguire l'istruzione seguente in ogni tabella nell'output precedente.
SELECT TOP 1 * FROM [ReplicatedTable]
Annotazioni
Se si prevede di ricompilare le statistiche della tabella replicata non memorizzata nella cache, assicurarsi di aggiornare le statistiche prima di attivare la cache. L'aggiornamento delle statistiche invaliderà la cache, quindi la sequenza è importante.
Esempio: iniziare con UPDATE STATISTICS, quindi attivare la ricompilazione della cache. Negli esempi seguenti, l'esempio corretto aggiorna le statistiche e quindi attiva la ricompilazione della cache.
-- Incorrect sequence. Ensure that the rebuild operation is the last statement within the batch.
BEGIN
SELECT TOP 1 * FROM [ReplicatedTable]
UPDATE STATISTICS [ReplicatedTable]
END
-- Correct sequence. Ensure that the rebuild operation is the last statement within the batch.
BEGIN
UPDATE STATISTICS [ReplicatedTable]
SELECT TOP 1 * FROM [ReplicatedTable]
END
Per monitorare il processo di ricompilazione, è possibile usare sys.dm_pdw_exec_requests, dove command inizierà con "BuildReplicatedTableCache". Per esempio:
-- Monitor Build Replicated Cache
SELECT *
FROM sys.dm_pdw_exec_requests
WHERE command like 'BuildReplicatedTableCache%'
Suggerimento
Le query sulle dimensioni delle tabelle possono essere usate per verificare quali tabelle hanno un criterio di distribuzione replicato e che sono maggiori di 2 GB.
Passaggi successivi
Per creare una tabella replicata, usare una di queste istruzioni:
Per una panoramica delle tabelle distribuite, vedere Tabelle distribuite.