Nota
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare ad accedere o modificare le directory.
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare a modificare le directory.
Important
Una nuova esperienza di Unity AI Gateway è disponibile nella versione beta. Il nuovo Gateway Unity AI è il piano di controllo aziendale per la gestione degli endpoint LLM e degli agenti di codifica con funzionalità avanzate. Consulta Gateway di intelligenza artificiale Unity per agenti e LLMs.
Questo articolo illustra come configurare Unity AI Gateway in un endpoint di gestione del modello.
Requirements
- Un'area di lavoro di Databricks in un'area in cui è supportata la gestione del modello. Vedere Disponibilità delle funzionalità di gestione dei modelli.
- Endpoint di gestione di un modello. È possibile usare uno degli endpoint con pagamento in base al token preconfigurati nell'area di lavoro oppure eseguire le operazioni seguenti:
- Per creare un endpoint per i modelli esterni, completare i passaggi 1 e 2 di Creare un endpoint di gestione di un modello esterno.
- Per creare un endpoint per il throughput fornito, vedere API del modello di base per il throughput fornito.
- Per creare un endpoint per un modello personalizzato, vedere Creare un endpoint.
Configurare Unity AI Gateway usando l'interfaccia utente
Nella sezione Unity AI Gateway della pagina di creazione dell'endpoint, è possibile configurare singolarmente le funzionalità del Gateway. Consultare Funzionalità supportate per le funzionalità disponibili sugli endpoint di erogazione dei modelli esterni e sugli endpoint con velocità effettiva provisionata.

La tabella seguente riepiloga come configurare Unity AI Gateway durante la creazione dell'endpoint usando l'interfaccia utente di gestione. Se si preferisce eseguire questa operazione a livello di codice, vedere l'esempio notebook.
| Feature | Come abilitare | Details |
|---|---|---|
| Rilevamento dell'utilizzo | Selezionare Abilita rilevamento utilizzo per abilitare il rilevamento e il monitoraggio delle metriche di utilizzo dei dati. |
|
| Registrazione del payload | Selezionare Abilita tabelle di inferenza per registrare automaticamente le richieste e le risposte dall'endpoint nelle tabelle Delta gestite da Unity Catalog. |
|
| Guardrail di intelligenza artificiale | Vedere Configurare guardrail di intelligenza artificiale nell'interfaccia utente. |
|
| Limitazioni di velocità | Selezionare Limiti di frequenza per gestire e specificare il numero di query al minuto (QPM) o token al minuto (TPM) che l'endpoint può supportare.
|
|
| Suddivisione del traffico | Nella sezione Entità servite specificare la percentuale di traffico che si vuole instradare a modelli specifici. Per configurare la suddivisione del traffico nell'endpoint a livello di codice, vedere Gestire più modelli esterni a un endpoint. |
|
| Fallbacks | Selezionare Abilita fallback nella sezione Gateway di intelligenza artificiale per inviare la richiesta ad altri modelli serviti nell'endpoint come fallback. |
|
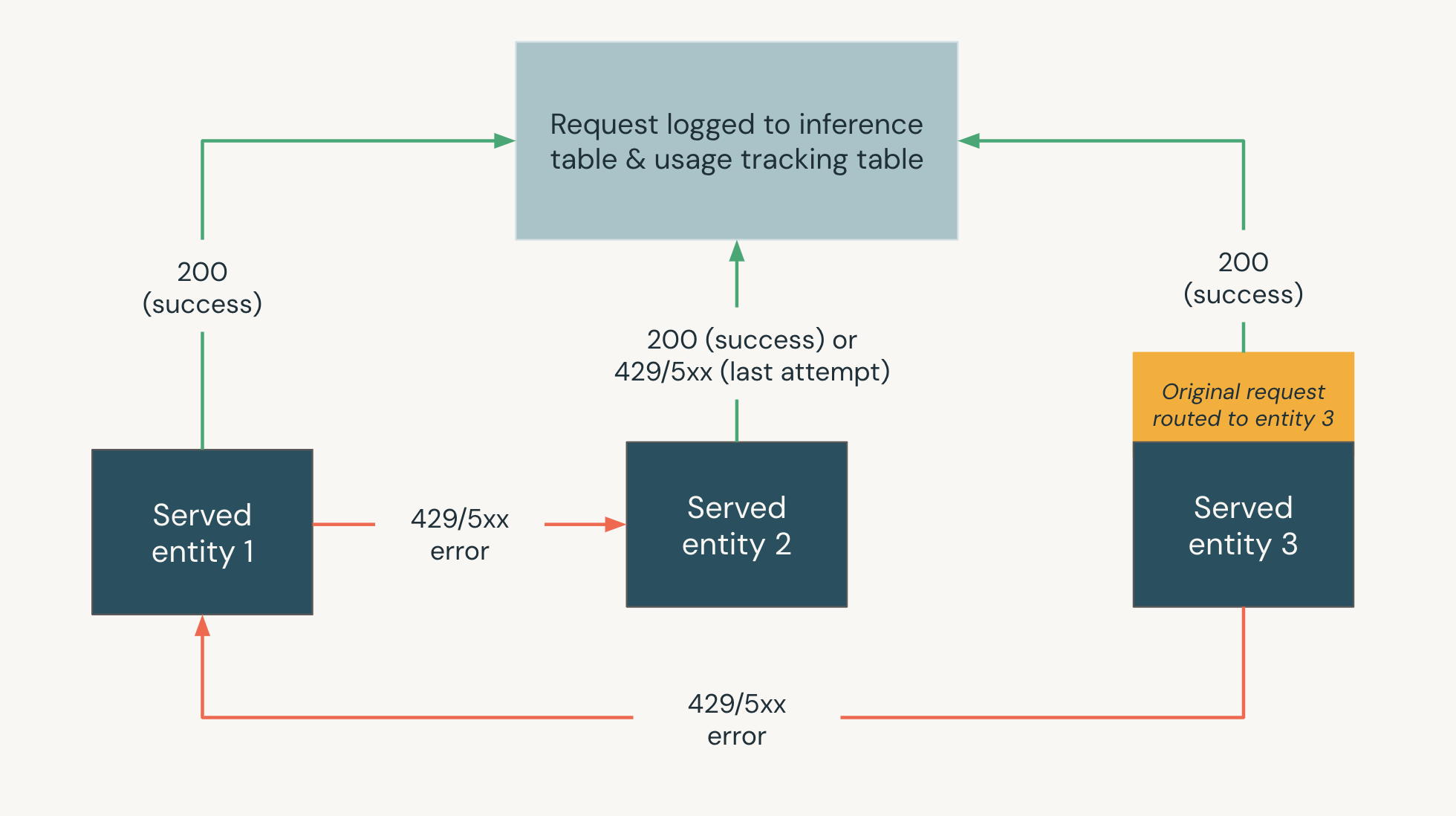
Il diagramma seguente mostra un esempio di fallback in cui,
- Tre entità servite vengono gestite in un endpoint di gestione del modello.
- La richiesta viene originariamente instradata all'entità Serve 3.
- Se la richiesta restituisce una risposta 200, la richiesta ha avuto esito positivo in entità servita 3 e la richiesta e la relativa risposta vengono registrate nelle tabelle di registrazione dell'utilizzo e del payload dell'endpoint.
- Se la richiesta restituisce un errore 429 o 5xx su Entità Servita 3, la richiesta passa all'entità servita successiva nell'endpoint, Entità Servita 1.
- Se la richiesta restituisce un errore 429 o 5xx su entità servita 1, la richiesta passa all'entità servita successiva nell'endpoint, entità servita 2.
- Se la richiesta restituisce un errore 429 o 5xx nell'entità Servita 2, la richiesta ha esito negativo perché si tratta del numero massimo di entità di fallback. La richiesta non riuscita e l'errore di risposta vengono registrati nelle tabelle di rilevamento dell'utilizzo e registrazione del payload.
Configurare i guardrail dell'IA nell'interfaccia utente
Important
Questa funzionalità è in Anteprima Pubblica.
Nella tabella seguente viene illustrato come configurare le protezioni supportate .
| Guardrail | Come abilitare |
|---|---|
| Safety | Selezionare Sicurezza per abilitare le misure di sicurezza per impedire al modello di interagire con contenuto non sicuro e dannoso. |
| Rilevamento delle informazioni personali identificabili | Selezionare Blocca o maschera i dati personali, ad esempio nomi, indirizzi, numeri di carta di credito se tali informazioni vengono rilevate nelle richieste e nelle risposte degli endpoint. In caso contrario, selezionare Nessuno per nessun rilevamento delle informazioni personali. |

schemi della tabella di rilevamento dell'utilizzo
Nelle sezioni seguenti vengono riepilogati gli schemi della tabella di rilevamento dell'utilizzo per le tabelle di sistema system.serving.served_entities e system.serving.endpoint_usage.
schema della tabella di rilevamento dell'utilizzo system.serving.served_entities
La tabella del sistema di rilevamento dell'utilizzo system.serving.served_entities presenta lo schema seguente:
| Nome colonna | Description | Type |
|---|---|---|
served_entity_id |
Identificativo univoco dell'entità servita. | STRING |
account_id |
L'ID cliente per Delta Sharing. | STRING |
workspace_id |
ID dell'area di lavoro del cliente dell'endpoint di servizio. | STRING |
created_by |
Nome dell'autore. Può essere un utente, un principale del servizio o un nome di gruppo. Per gli endpoint con pagamento in base al token, si tratta di System-User |
STRING |
endpoint_name |
Nome dell'endpoint di servizio. | STRING |
endpoint_id |
ID univoco dell'endpoint di servizio. | STRING |
served_entity_name |
Nome dell’entità servita. | STRING |
entity_type |
Tipo dell'entità servita. Può essere FEATURE_SPEC, EXTERNAL_MODEL, FOUNDATION_MODEL o CUSTOM_MODEL |
STRING |
entity_name |
Nome sottostante dell'entità. Diverso da quello served_entity_name che è un nome specificato dall'utente. Ad esempio, entity_name è il nome del modello del catalogo Unity. |
STRING |
entity_version |
Versione dell'entità servita. | STRING |
endpoint_config_version |
Versione della configurazione dell'endpoint. | INT |
task |
Tipo di attività. Può essere llm/v1/chat, llm/v1/completions o llm/v1/embeddings. |
STRING |
external_model_config |
Configurazioni per i modelli esterni. Ad esempio, {Provider: OpenAI} |
STRUCT |
foundation_model_config |
Configurazioni per i modelli di base. Ad esempio, {min_provisioned_throughput: 2200, max_provisioned_throughput: 4400} |
STRUCT |
custom_model_config |
Configurazioni per i modelli personalizzati. Ad esempio, { min_concurrency: 0, max_concurrency: 4, compute_type: CPU } |
STRUCT |
feature_spec_config |
Configurazioni per le specifiche delle funzionalità. Ad esempio, { min_concurrency: 0, max_concurrency: 4, compute_type: CPU } |
STRUCT |
change_time |
Data e ora della modifica per l'entità servita. | TIMESTAMP |
endpoint_delete_time |
Data e ora dell'eliminazione dell'entità. L'endpoint è il contenitore dell'entità servita. Dopo l'eliminazione dell'endpoint, viene eliminata anche l'entità servita. | TIMESTAMP |
schema della tabella di rilevamento dell'utilizzo system.serving.endpoint_usage
La tabella del sistema di rilevamento dell'utilizzo system.serving.endpoint_usage presenta lo schema seguente:
| Nome colonna | Description | Type |
|---|---|---|
account_id |
L'ID del cliente. | STRING |
workspace_id |
ID dell'area di lavoro del cliente dell'endpoint di servizio. | STRING |
client_request_id |
Identificatore di richiesta fornito dall'utente che può essere specificato nel corpo della richiesta di gestione del modello. Per gli endpoint del modello personalizzati, questo non è supportato per le richieste superiori a 4MiB. | STRING |
databricks_request_id |
Un identificatore di richiesta generato da Azure Databricks collegato a tutte le richieste di servizio del modello. | STRING |
requester |
ID dell'utente o dell'entità servizio le cui autorizzazioni vengono usate per la richiesta di chiamata dell'endpoint di servizio. | STRING |
status_code |
Codice di stato HTTP restituito dal modello. | INTEGER |
request_time |
La data e l'ora in cui è stata ricevuta la richiesta. | TIMESTAMP |
input_token_count |
Il numero dei token nell'input. Questo valore sarà 0 per le richieste di modello personalizzate. | LONG |
output_token_count |
Il conteggio dei token nell'output. Questo valore sarà 0 per le richieste di modello personalizzate. | LONG |
input_character_count |
Numero di caratteri della stringa di input o della richiesta. Questo valore sarà 0 per le richieste di modello personalizzate. | LONG |
output_character_count |
Numero di caratteri della stringa di output della risposta. Questo valore sarà 0 per le richieste di modello personalizzate. | LONG |
usage_context |
Mappa fornita dall'utente contenente gli identificatori dell'utente finale o dell'applicazione del cliente che effettua la chiamata all'endpoint. Vedere Definire ulteriormente l'utilizzo con usage_context. Per gli endpoint del modello personalizzati, questo non è supportato per le richieste superiori a 4MiB. |
MAP |
request_streaming |
Indica se la richiesta è in modalità streaming. | BOOLEAN |
served_entity_id |
ID univoco utilizzato per effettuare un join con la tabella di dimensioni system.serving.served_entities per cercare informazioni sull'endpoint e sull'entità servita. |
STRING |
Definire ulteriormente l'utilizzo con usage_context
Quando si esegue una query su un modello esterno con il rilevamento dell'utilizzo abilitato, è possibile fornire il usage_context parametro con il tipo Map[String, String]. Il mapping del contesto di utilizzo viene visualizzato nella tabella di rilevamento dell'utilizzo nella colonna usage_context. Le dimensioni della usage_context mappa non possono superare 10 KiB.
{
"messages": [
{
"role": "user",
"content": "What is Databricks?"
}
],
"max_tokens": 128,
"usage_context":
{
"use_case": "external",
"project": "project1",
"priority": "high",
"end_user_to_charge": "abcde12345",
"a_b_test_group": "group_a"
}
}
Se si usa il client Python OpenAI, è possibile specificare il usage_context includendolo nel parametro extra_body.
from openai import OpenAI
client = OpenAI(
api_key="dapi-your-databricks-token",
base_url="https://example.staging.cloud.databricks.com/serving-endpoints"
)
response = client.chat.completions.create(
model="databricks-claude-sonnet-4-5",
messages=[{"role": "user", "content": "What is Databricks?"}],
temperature=0,
extra_body={"usage_context": {"project": "project1"}},
)
answer = response.choices[0].message.content
print("Answer:", answer)
Gli amministratori dell'account possono aggregare righe diverse in base al contesto di utilizzo per ottenere informazioni dettagliate e aggiungere queste informazioni alle informazioni nella tabella di registrazione del payload. Ad esempio, è possibile aggiungere end_user_to_charge a usage_context per tenere traccia dell'attribuzione dei costi per gli utenti finali.
Monitorare l'utilizzo degli endpoint
Per monitorare l'utilizzo degli endpoint, è possibile unire le tabelle di sistema e le tabelle di inferenza per l'endpoint.
Unire tabelle di sistema
Questo esempio si applica agli endpoint esterni, con throughput di provisioning, a pagamento per token e ai modelli personalizzati.
Per unire le endpoint_usage tabelle di sistema e served_entities , usare il codice SQL seguente:
SELECT * FROM system.serving.endpoint_usage as eu
JOIN system.serving.served_entities as se
ON eu.served_entity_id = se.served_entity_id
WHERE created_by = "\<user_email\>";
Aggiornare le funzionalità del gateway di Intelligenza Artificiale Unity sugli endpoint
È possibile aggiornare le funzionalità del gateway di intelligenza artificiale Unity sugli endpoint di servizio modello che in precedenza avevano funzionalità abilitate e su quelli che non le avevano. Gli aggiornamenti alle configurazioni del gateway di intelligenza artificiale unity richiedono circa 20-40 secondi, tuttavia la limitazione della frequenza degli aggiornamenti può richiedere fino a 60 secondi.
Di seguito viene illustrato come aggiornare le funzionalità di Unity AI Gateway in un modello che serve un endpoint utilizzando la Serving UI.
Nella sezione Gateway della pagina endpoint è possibile visualizzare le funzionalità abilitate. Per aggiornare queste funzionalità, fare clic su Modifica Gateway di Intelligenza Artificiale Unity.

Esempio di notebook
Il notebook seguente illustra come abilitare e usare programmaticamente le funzionalità di Databricks Unity AI Gateway per gestire e governare i modelli dai provider. Per informazioni dettagliate sull'API REST, vedere PUT /api/2.0/serving-endpoints/{name}/ai-gateway .